
全文2.5K字,建议阅读时间5分钟。
尽管决策树在机器学习中的使用已经存在了一段时间,但该技术仍然强大且受欢迎。本指南首先提供对该方法的介绍性知识,然后向您展示如何构建决策树,计算重要的分析参数以及绘制结果树。

决策树是我学到的流行且功能强大的机器学习算法之一。这是一种非参数监督学习方法,可用于分类和回归任务。目的是创建一个模型,该模型通过学习从数据特征推断出的简单决策规则来预测目标变量的值。对于分类模型,目标值本质上是离散的,而对于回归模型,目标值由连续值表示。与黑盒算法(例如神经网络)不同, 决策树 比较容易理解,因为它共享内部决策逻辑(您将在下一节中找到详细信息)。
尽管许多数据科学家认为这是一种旧方法,但由于过度拟合的问题,他们可能对其准确性有所怀疑,但最近的基于树的模型(例如,随机森林(装袋法),梯度增强(提升方法) )和XGBoost(增强方法)建立在决策树算法的顶部。因此,决策树 背后的概念和算法 非常值得理解!
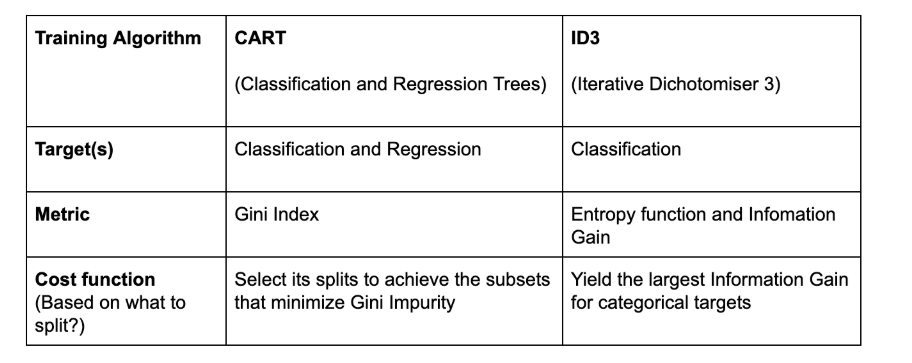
决策树算法有4种流行类型: ID3, CART(分类树和回归树), 卡方和 方差减少。
在此文章中,我将仅关注分类树以及ID3和CART的说明。
想象一下,您每个星期日都打网球,并且每次都邀请您最好的朋友克莱尔(Clare)陪伴您。克莱尔有时会加入,但有时不会。对她而言,这取决于许多因素,例如天气,温度,湿度和风。我想使用下面的数据集来预测克莱尔是否会和我一起打网球。一种直观的方法是通过决策树。
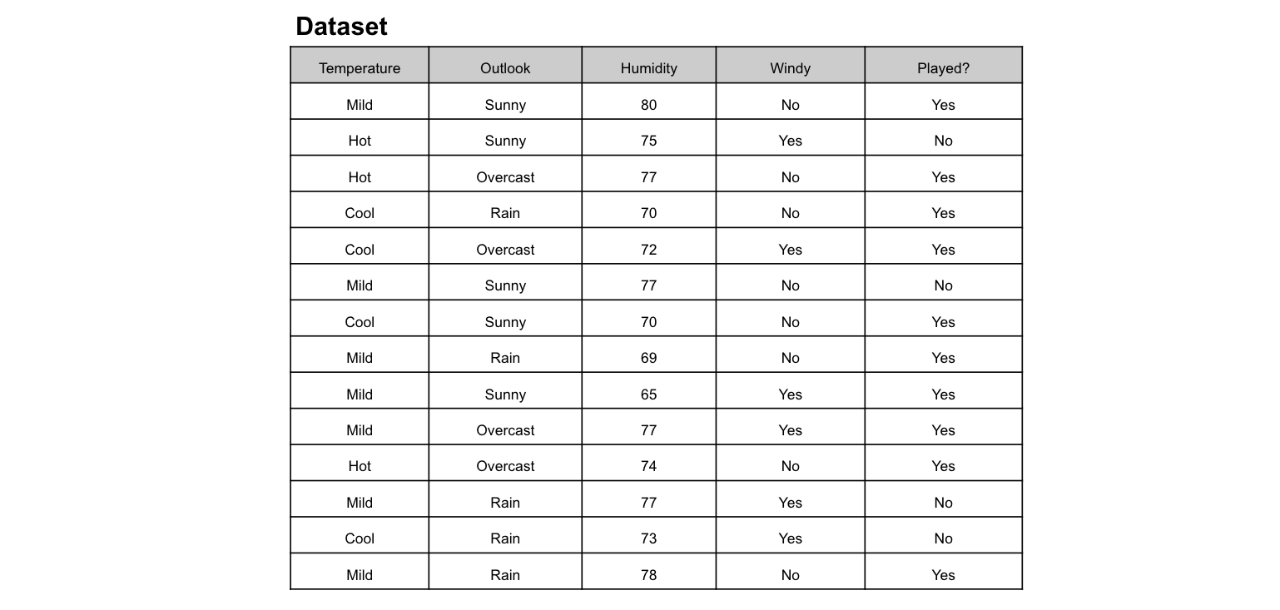
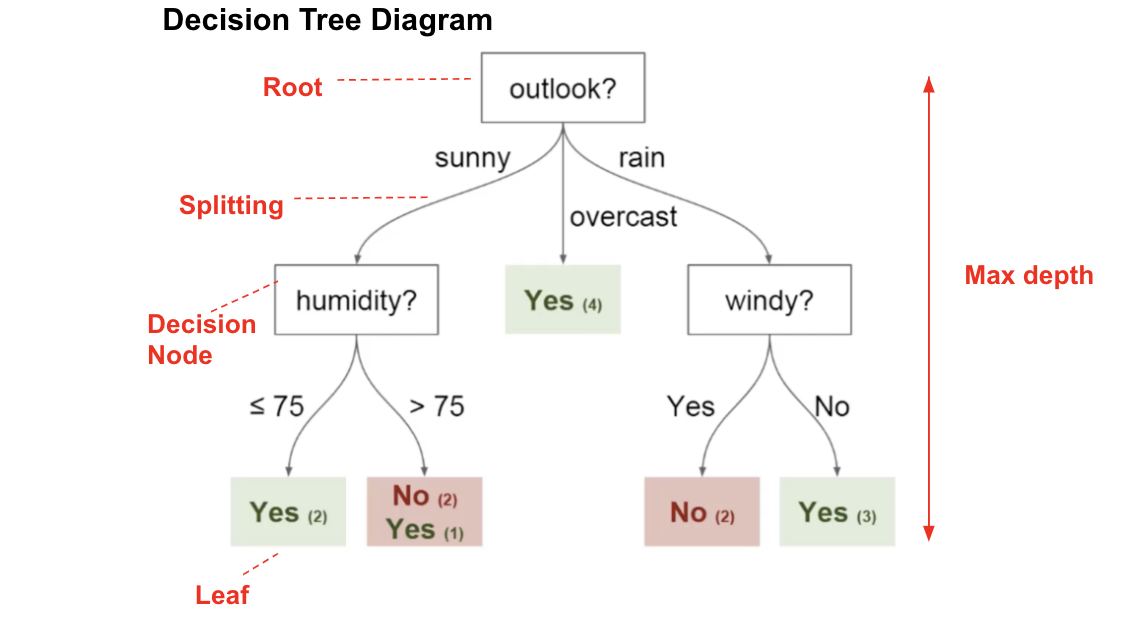
在此 决策树 图中,我们具有:
- 根节点:决定整个总体或样本数据的第一个拆分应进一步分为两个或更多同构集合。在我们的例子中,是Outlook节点。
- 拆分:这是将一个节点分为两个或多个子节点的过程。
- 决策节点:该节点决定是否/何时将一个子节点拆分为其他子节点。在这里,我们有Outlook节点,Humidity节点和Windy节点。
- 叶子:预测结果(分类或连续值)的终端节点。有色节点(即“是”和“否”节点)是叶子。
问题:基于哪个属性(功能)进行拆分?最佳分割是什么?答:使用具有最高的属性 信息增益 或 基尼增益
ID3(迭代二分法)
ID3决策树算法使用信息增益来确定分裂点。为了衡量我们获得了多少信息,我们可以使用 熵 来计算样本的同质性。
问题:什么是“熵”?它的功能是什么?
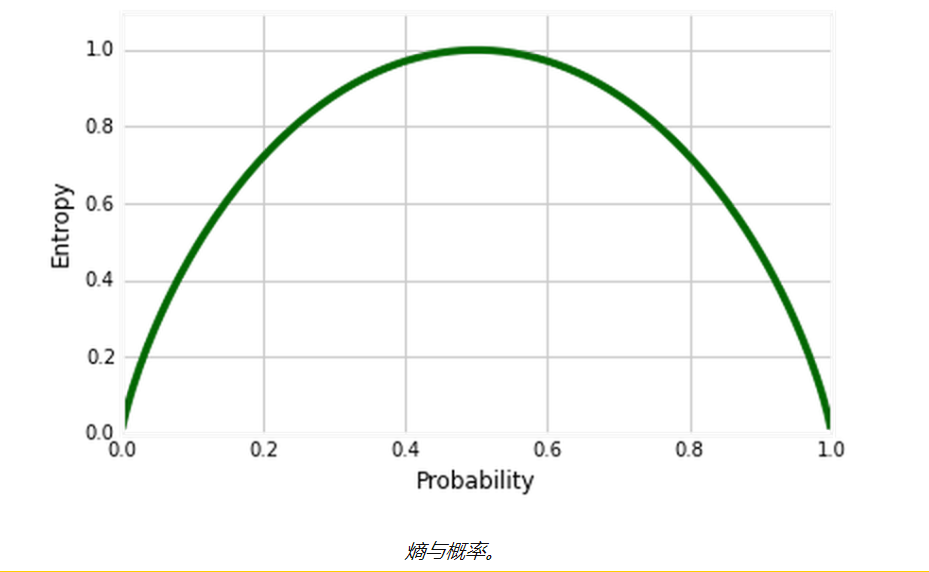
答:这是对数据集中不确定性量的度量。 熵控制决策树如何决定拆分数据。它实际上影响决策树如何 绘制边界。
熵方程:
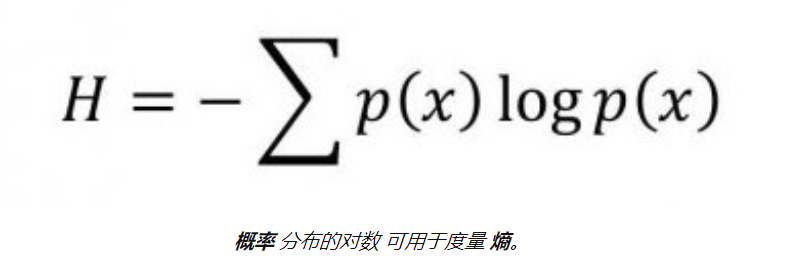
定义:决策树中的熵代表同质性。
如果样本是完全均匀的,则熵为0(概率= 0或1),并且如果样本均匀地分布在各个类别中,则其熵为1(概率= 0.5)。
下一步是进行拆分,以最大程度地减少熵。我们使用 信息增益 来确定最佳拆分。
让我向您展示在打网球的情况下如何逐步计算信息增益。在这里,我仅向您展示如何计算Outlook的信息增益和熵。
步骤1:计算一个属性的熵—预测:克莱尔将打网球/克莱尔将不打网球
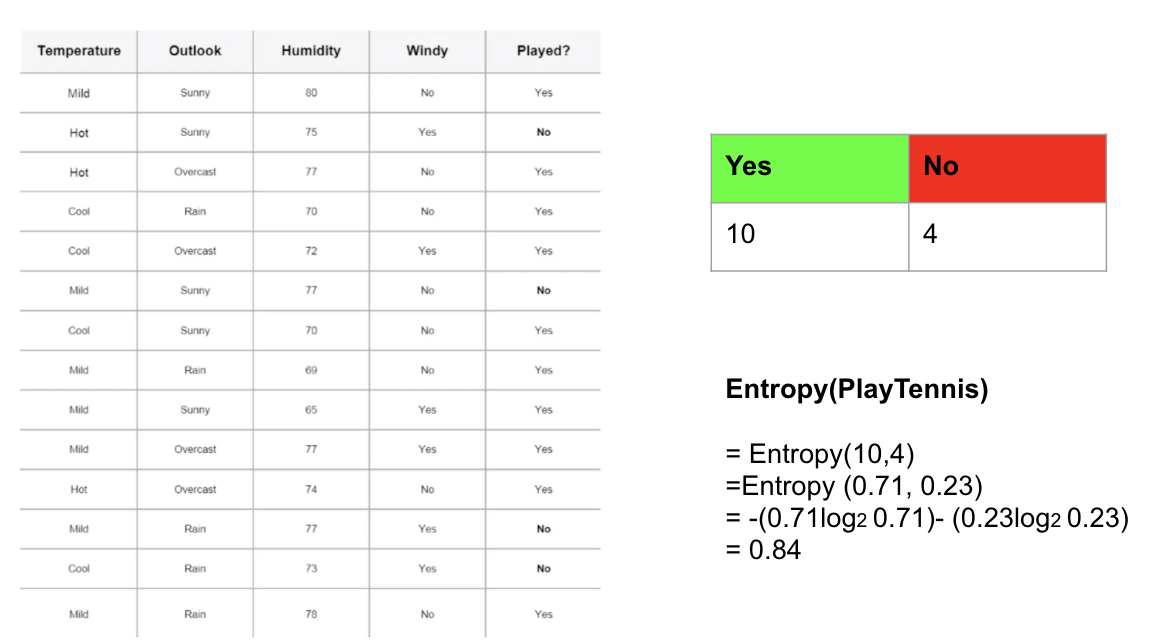
在此示例中,我将使用此列联表来计算目标变量的熵:已播放?(是/否)。有14个观测值(10个“是”和4个“否”)。'是'的概率(p)为0.71428(10/14),'否'的概率为0.28571(4/14)。然后,您可以使用上面的公式计算目标变量的熵。
步骤2:使用列联表计算每个特征的熵
为了说明这一点,我以Outlook为例,说明如何计算其熵。共有14个观测值。汇总各行,我们可以看到其中5个属于Sunny,4个属于阴雨,还有5个属于Rainy。因此,我们可以找到晴天,阴天和多雨的概率,然后使用上述公式逐一计算它们的熵。计算步骤如下所示。
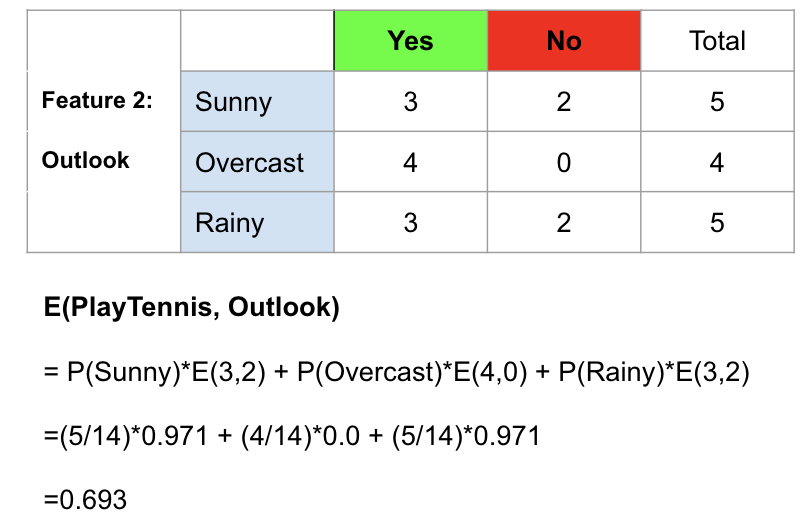
计算特征2(Outlook)的熵的示例。
定义:信息增益 是节点分裂时熵值的减少或增加。
信息增益方程式:
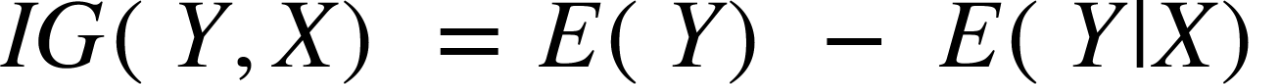
X在Y上获得的信息

sklearn.tree。DecisionTreeClassifier: “熵”表示获取信息
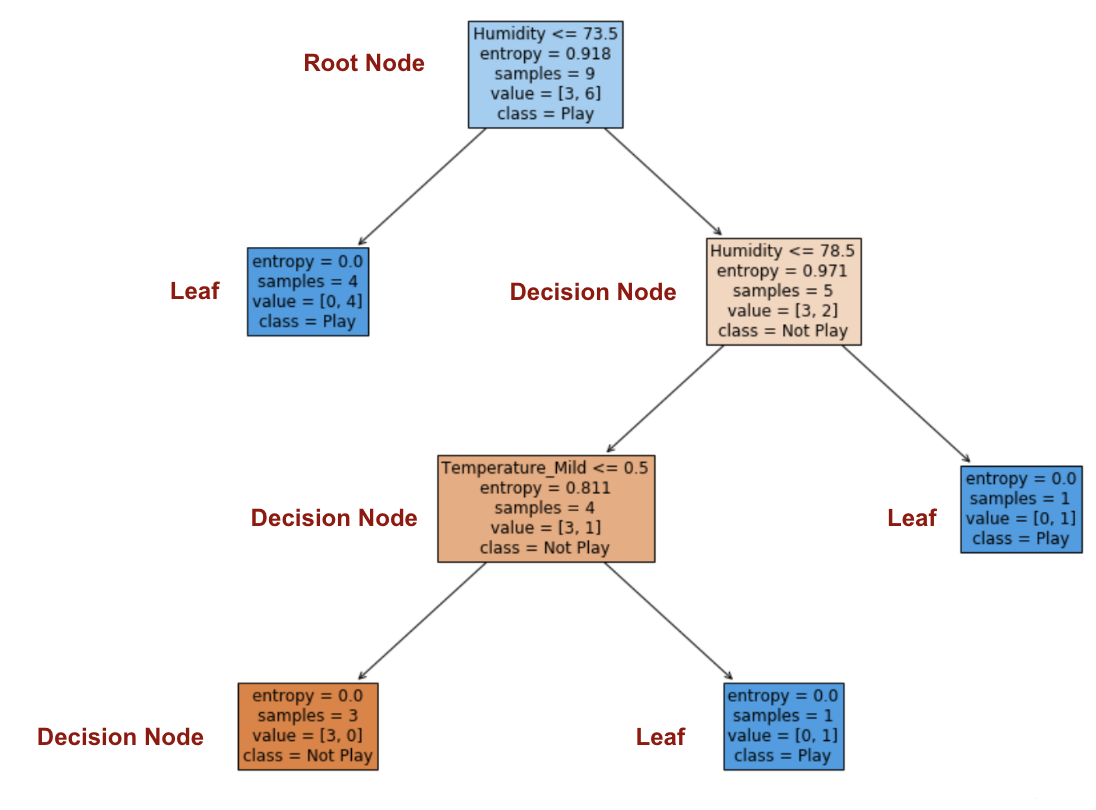
为了可视化如何使用信息增益构建决策树 ,我仅应用了sklearn.tree。DecisionTreeClassifier 生成图。
步骤3:选择信息增益最大的属性 作为根节点
“湿度”的信息增益最高,为0.918。湿度是根节点。
步骤4: 熵为0的分支是叶节点,而熵大于0的分支需要进一步拆分。
步骤5:以ID3算法递归地增长节点,直到对所有数据进行分类。
您可能听说过C4.5算法,对ID3的改进使用了“ 增益比” 作为信息增益的扩展。使用增益比的优点是通过使用Split Info标准化信息增益来处理偏差问题。在这里我不会详细介绍C4.5。有关更多信息,请在此处签出 (DataCamp)。
CART(分类和回归树)
CART的另一种决策树算法使用 Gini方法 创建分割点,包括Gini索引(Gini杂质)和Gini增益。
基尼系数的定义:通过随机选择标签将错误的标签分配给样品的概率,也用于测量树中特征的重要性。
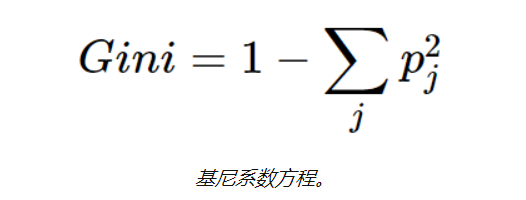

在为每个属性计算Gini增益后,创建sklearn.tree。DecisionTreeClassifier 将选择具有最大Gini增益的属性 作为根节点。 甲 以0基尼分支是叶节点,而具有基尼分支大于0需要进一步分裂。递归地增长节点,直到对所有数据进行分类为止(请参见下面的详细信息)。
如前所述,CART还可以使用不同的分割标准来处理回归问题:确定分割点的均方误差(MSE)。回归树的输出变量是数字变量,输入变量允许连续变量和分类变量混合使用。您可以通过DataCamp查看有关回归树的更多信息 。
大!您现在应该了解如何计算熵,信息增益,基尼系数和基尼增益!
问题:那么……我应该使用哪个?基尼系数还是熵?答:通常,结果应该是相同的……我个人更喜欢基尼指数,因为它不涉及计算量更大的 日志 。但是为什么不都尝试。
让我以表格形式总结一下!
使用Scikit Learn构建决策树
Scikit Learn 是针对Python编程语言的免费软件机器学习库。
步骤1:导入数据

步骤2:将分类变量转换为虚拟变量/指标变量
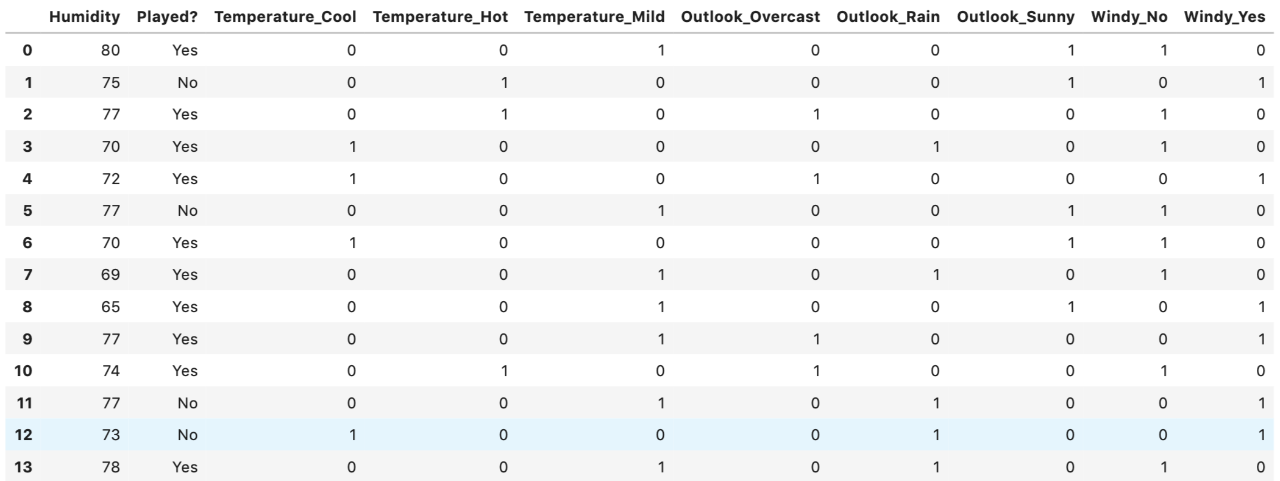
“温度”,“ Outlook”和“风”的类别变量都转换为虚拟变量。
步骤3:将训练集和测试集分开

第4步:通过Sklean导入决策树分类器

步骤5:可视化决策树图

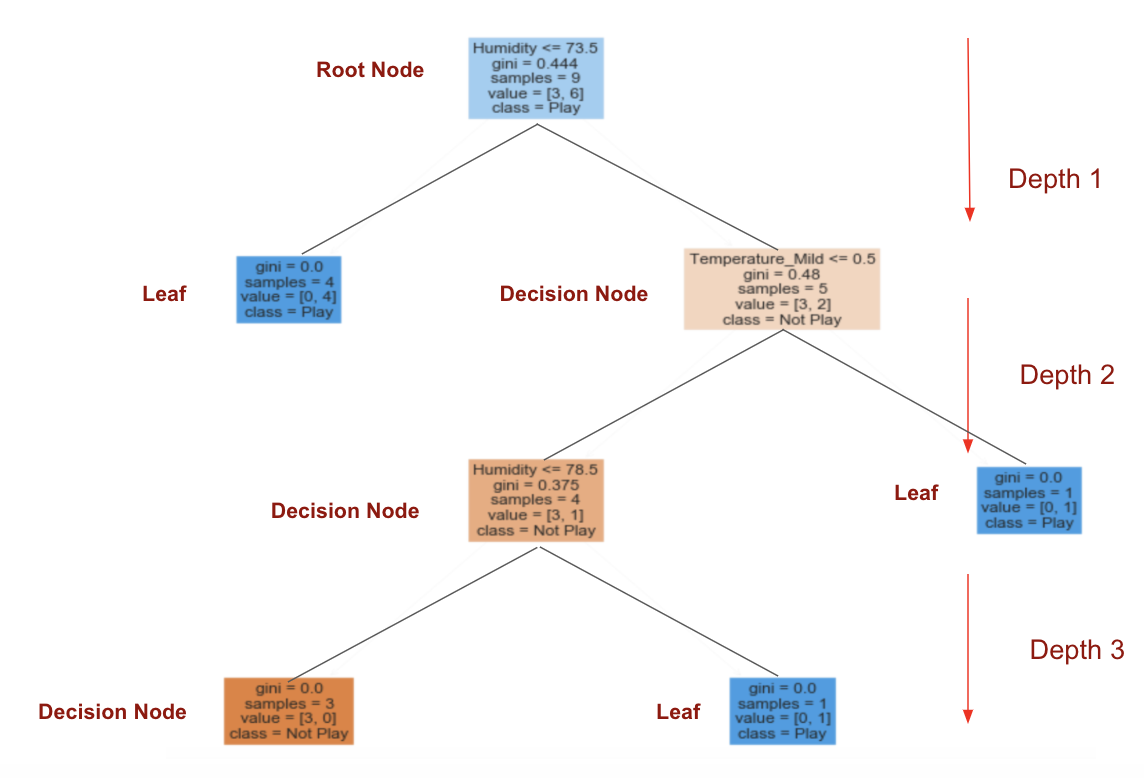
有关代码和数据集,请点击此处查看。

为了提高模型性能(超参数优化),应调整超参数。有关更多详细信息,请在 此处查看。
决策树的主要缺点是过拟合,尤其是当树特别深时。幸运的是,最近的基于树的模型(包括随机森林和XGBoost)建立在决策树算法的顶部,并且它们通常具有强大的建模技术,并且比单个决策树更具动态性,因此性能更好。因此,了解背后的概念和算法 决策树 完全是构建学习数据科学和机器学习打下良好的基础超级有用。
- -
总结:现在您应该知道
- 如何构造决策树
- 如何计算“熵”和“信息增益”
- 如何计算“基尼系数”和“基尼系数”
- 最佳分割是什么?
- 如何在Python中绘制决策树图

看完别走还有惊喜!
我精心整理了计算机/Python/机器学习/深度学习相关的2TB视频课与书籍,价值1W元。关注微信公众号“计算机与AI”,点击下方菜单即可获取网盘链接。

