
文章转载于:知乎
作者:金雪锋
背景
本文是AI框架分析专栏的第三篇,总体目录参见:
AI框架的演进趋势和MindSpore的构想:https://zhuanlan.zhihu.com/p/225392622
这次文章顺序并没有按照原来规划的目录来写,原因是前期在分布式并行这一块分析的素材多一些,工作量小一点,所以就偷懒先写分布式并行这个主题。
AI框架的分布式并行能力
在AI框架的总体发展趋势的文章中提到,随着GPT-3这些超大模型的出现,AI框架面临着性能墙、效率墙以及精度墙等多重挑战,这里涉及很多技术,包括:
- 约束内存管理:通过内存复用技术,尽可能的放下大的模型,这里又分两类情况,一类是静态的,即在编译时刻,把内存编排好;另外一类是动态的,运行时刻进行内存的分配和复用。
- 重计算:通过时间换空间,把原来需要保存的中间结果丢弃到,节省内存,在需要使用的时候通过计算图重新计算获得;
- Host-Device的并行:当Device放不下整个模型或者模型的某一层(如,Wide Deep的Embedding层),可以考虑使用Host的内存来存放整个模型,Device有点类似Host的缓存,这里Host到Device的数据交换就非常关键。
- 模型并行:Host-Device并行模式能支持的模型大小还是会受限于单机的内存大小,另外对性能影响比较大;解决单机内存受限的问题,可以采用PS Server的方式;但是要同时解决内存容量和性能的问题,则需要采用模型并行。模型并行又有两种方式,一种按照模型的Layer来切分,一般采用pipeline来实现并行;另外一种是按照tensor来切分。
- 混合并行:许多场景可能需要数据并行、按Tensor切分的模型并行以及pipeline并行一起来进行。
- 跨迭代的并行:主要是考虑Step于Step之间的并行
- 异构并行运行时:除了上述的分布式并行的策略和机制外,每个节点还需提供一个支持异构(CPU/GPU/NPU)、异步并发、多种执行模式(单算子/子图)的运行时。
- 数据处理的并行加速:以前在ResNet50性能调优时发现,当单Step跑到17~18ms的时候,host数据处理的时间就跟不上了,此时数据处理加速的引擎就比较重要。
- 自动并行:模型并行/混合并行策略如果让算法工程师来手工确定的,这个门槛就会很高,既要懂算法,又要懂系统;自动并行就是提供算法工程师一套自动化或者半自动化的接口和机制,方便他们高效地制定混合并行/模型并行策略
- 弹性分布式训练:在云这样的动态资源环境中,在训练节点动态伸缩的情况下,保证训练收敛的速度和精度稳定。
- 面向大BatchSize的优化器:面向大规模模型训练天生就是一个大Batchsize的训练,我们需要一个更合适的优化器实现训练中更快的收敛,达到精度要求。
看上去,AI框架分布式并行的内容非常广,一篇文章也写不完,准备在这一块也做个小的系列,本次重点介绍混合并行和自动并行相关的技术.
混合并行/自动并行产生的背景
需要用到混合并行的模型往往都是大模型,目前业界主流训练卡的内存是32GB,而大模型在训练过程中所需要的内存远超32GB,必须通过模型并行把模型切分到多个设备上以达到可运行。如何切分模型,如何保持模型切分后的高性能,则是模型并行的难点。
场景
- 超大规模图像分类与识别
这类网络往往有一个超大FC层以及loss层。在人脸识别和超大规模图像分类领域,分类数可能高达千万,FC层参数量能到达到10B级别。这类网络即使在数万分类这种场景,模型并行相对数据并行来说性能也能更优,因为数据并行通信的是参数梯度,通信数据量等于参数量,而模型并行通信的是feature map,这类网络feature map的数据量远小于参数的数据量,进而在通信上能够性能更优。
- 高分辨率3D图像处理
例如医疗领域的3维CT图像处理,典型网络是Unet-3D。这类场景,输入图像往往有亿级像素,模型的Feature Map非常大,叠加上比较深的网络结构,模型大也往往是数百GB;
- NLP领域
NLP领域,目前基于Transformer结构的网络是SOTA方法,最典型网络的大网络有GPT2/3、Google翻译、FaceBook翻译等模型。基于Transformer结构的网络,从bert的340M个参数,transformer-xl 800M参数,gpt-2 1542M参数,NVIDIA megatron有8B参数、GPT-3的175B参数。往往更大的网络,就需要用更大的数据来喂,训练这类网络,就需要使用数据并行叠加模型并行的方式,同时处理大规模数据集及大规模参数。
- 推荐网络 Wide&Deep/DeepFM/DCN等
在推荐领域,特征数量是百亿甚至千亿的规模,会有超大Embedding层,内存开销远超单卡内存,就必须使用模型并行把Embedding参数切分到集群。
总的来说,不同场景的模型,结构各有不同,如下图所示,不同结构的模型,需要不同的并行策略,才能实现性能的最优。图中方块的大小表示layer的内存开销。
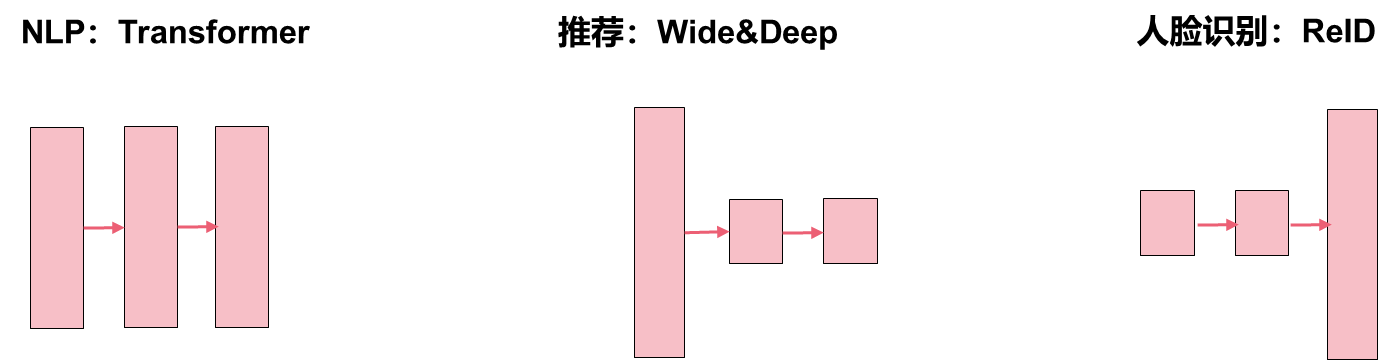
Transformer一般会采用数据并行叠加模型并行的策略;推荐一般会采用模型并行转数据并行的策略;ReID一般会采用数据并行转模型并行的策略;
混合并行的难点
混合并行不同于数据并行,有非常多维度的并行选择。现在主流框架做法都是通过手动切分的方式来做模型并行,手动切分模型难度非常大,对开发者的要求非常高,需要专家经验。混合并行,有以下几个主要难点:
- 模型切分难,不同维度的模型切分会引入不同的通信量,性能不同,要从海量切分策略中分析出一个性能较好的策略,难度高,需要专家经验;要考虑内存上限让切分后的子模型能够在卡中运行;要考虑切分后各子模型的计算量,保持计算相对均衡,从而避免性能短板。
- 需要理解底层硬件网络组网的拓扑,节点内和节点间的设备分布方式,把子模型间通信量多的放到节点内,通信量小的放到节点间,以提高网络的利用效率。一般来讲,集群网络有三层,服务器内多卡间互联、机柜内服务器间互联及机柜间互联,带宽和时延依次降低。
- 在编码方面,手动模型并行,用户需要显式地写很多设备绑定以及通信代码,比较繁复,并行逻辑与算法逻辑耦合在一起,加重了算法科学家的开发工做量。我们希望算法科学家能专注于算法逻辑的实现,而不需要关注并行的细节。
业界技术
分布式训练常用的训练模式有Parameter Server和集合通信模式来交互梯度或activation。所谓集合通信模式是指,模型切分后,通过集合通信原语来实现不同模型切片之间的数据交互。
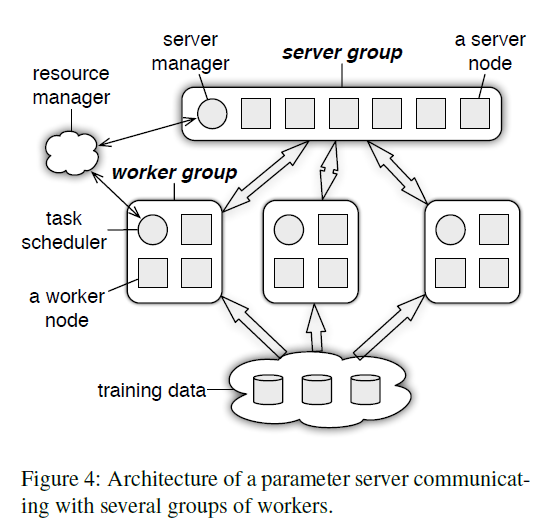
集合通信原语主要有Broadcast、AllGather、AllReduce、ReduceScatter,此外AlltoAll和点到点通信Send/Recv也逐步有应用场景。
在手动并行方面,业界有TensorFlow-Gpipe、以及基于PyTorch的Megatron和DeepSpeed,这种面向特定领域的手动并行库。
在自动并行方面,学术界有很多相关工作,典型代表有OptCNN/FlexFlow/ToFu等[6][7][8],MindSpore在实现的时候也参考了这些论文。之后工业界也有一些开源实现,除MindSpore以外,主要有Mesh-Tensorflow、Tensorflow-XLA、OneFlow。
自动并行可以分成两层,我们称为半自动和全自动两层。半自动这层,主要是提供一套算子切分及图切分的框架,让开发人员做混合并行更加简单;全自动这层是在此基础上,构建了一套基于Cost Model的策略搜索算法,帮助用户找到切分策略。从业界开源实现上看,大家主要还是聚焦在半自动并行上,MindSpore除了实现了半自动行外,也在全自动上做了探索。
总的来说,手动混合并行库大都是在Python层实现封装,而自动并行的发展趋势我们认为需要在图编译阶段实现,兼容现有接口。
MindSpore设计思考
MindSpore目前是基于集合通信的模式来实现并行,NN算法分布式并行可以抽象成这样一个问题:把计算图和Tensor切分到集群执行,并行能保持高性能。
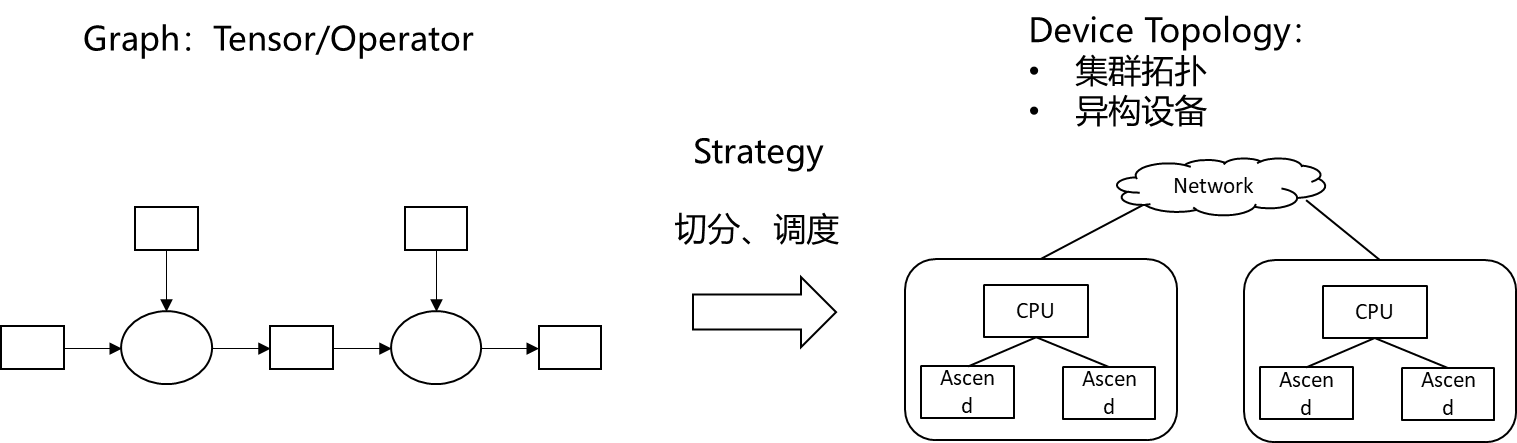
在介绍自动并行之前,我们重新从Tensor切分角度看数据并行、模型并行和混合并行。如下图所示[11],数据并行就是在输入数据Tensor的batch维度切分,模型并行就是对模型参数Tensor的切分,而混合并行就是对输入数据Tensor和模型参数Tensor同时切分。所以,自动并行的核心就是实现一套tensor自动切分的框架。
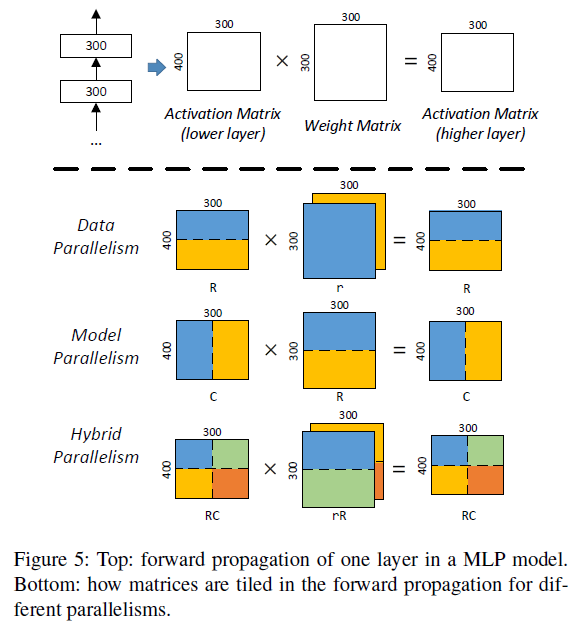
设计目标
MindSpore自动并行的目标是构建一种易用高效的的分布式并行训练模式,融合了数据并行、模型并行和混合并行,让算法人员不再需要关注算法模型到底需要用哪种模式训练。主要目标是:
- 简化分布式并行编程,串行代码实现分布式训练,对用户屏蔽并行细节,并且保持高性能;
- 计算逻辑上保持和单卡串行流程一致;
- 实现上统一数据并行和模型并行,一套框架支持多种并行模式;
- 结合集群拓扑优化性能;
实现上,就像前面介绍一下,MindSpore的自动并行分成两层,半自动和全自动。半自动这层,主要是在图编译阶段实现了一套算子切分及图切分的框架,把模型切片和设备进行调度绑定。在API这层,把并行逻辑和算法逻辑解耦,变成了一些配置。自动这层是在此基础上,构建了一套Cost Model,能够了基于数据量、模型参数量、网络集群拓扑带宽等信息的代价模型,通过一套策略搜索算法,计算是性能最优的切分策略。这样用户就不需要感知切分策略。
关键概念
在自动并行中,有两个关键的建模,分布式Tensor Layout和Tensor Redistribution。Tensor Layout表示tensor切分后,tensor切片在集群分布情况。Tensor Redistribution表示两种Tensor Layout之间的转换。模型切分流程如下图所示,首先对每个算子的输入tensor按策略进行切分,生成算子输入的tensor layout,然后根据算子的数学定义,推导出输出tensor layout;然后再检查前一个算子输出tensor layout和下一个算子的输入tensor layout,如果两种不同,则会插入一个tensor redistribution。
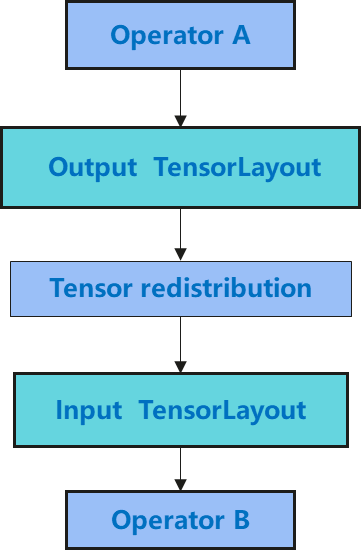
分布式Tensor Layout
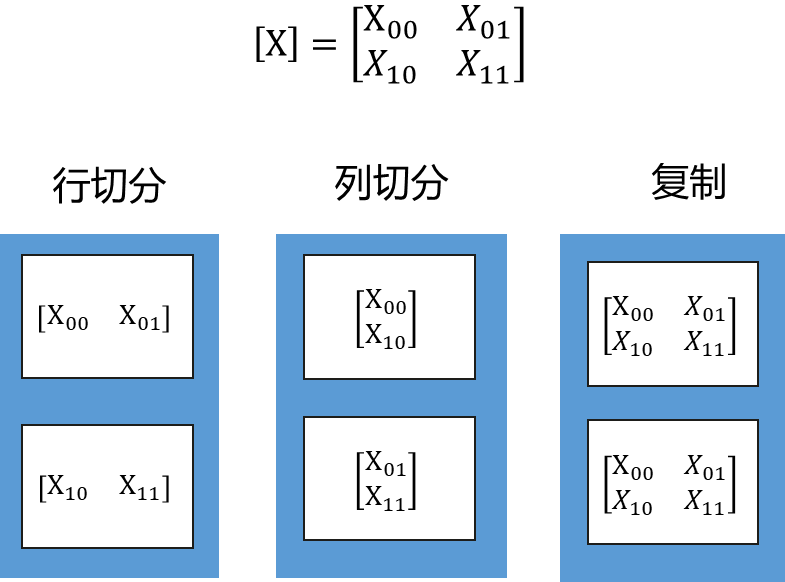
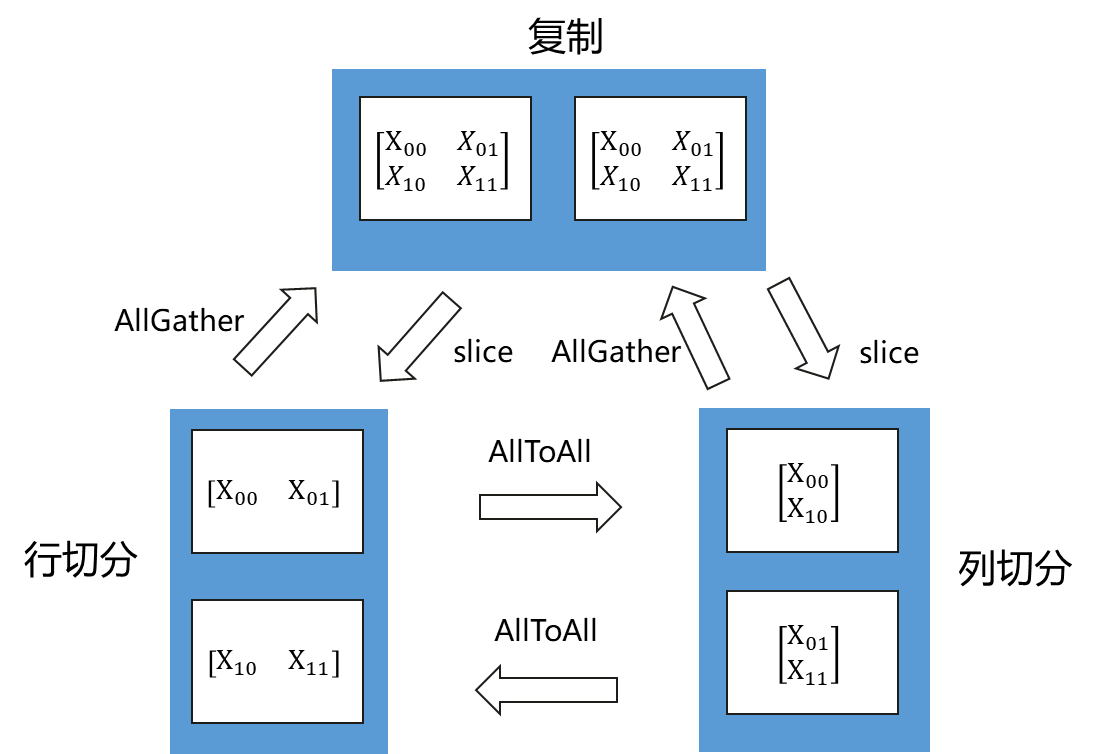
分布式Tensor Layout表示一个完整Tensor怎么切分到集群。Tensor可以各维度切分到集群,也可以在集群上复制。一个二维矩阵,切分到两个节点,有三种Tensor Layout,行切分、列切分及复制,如下图所示。
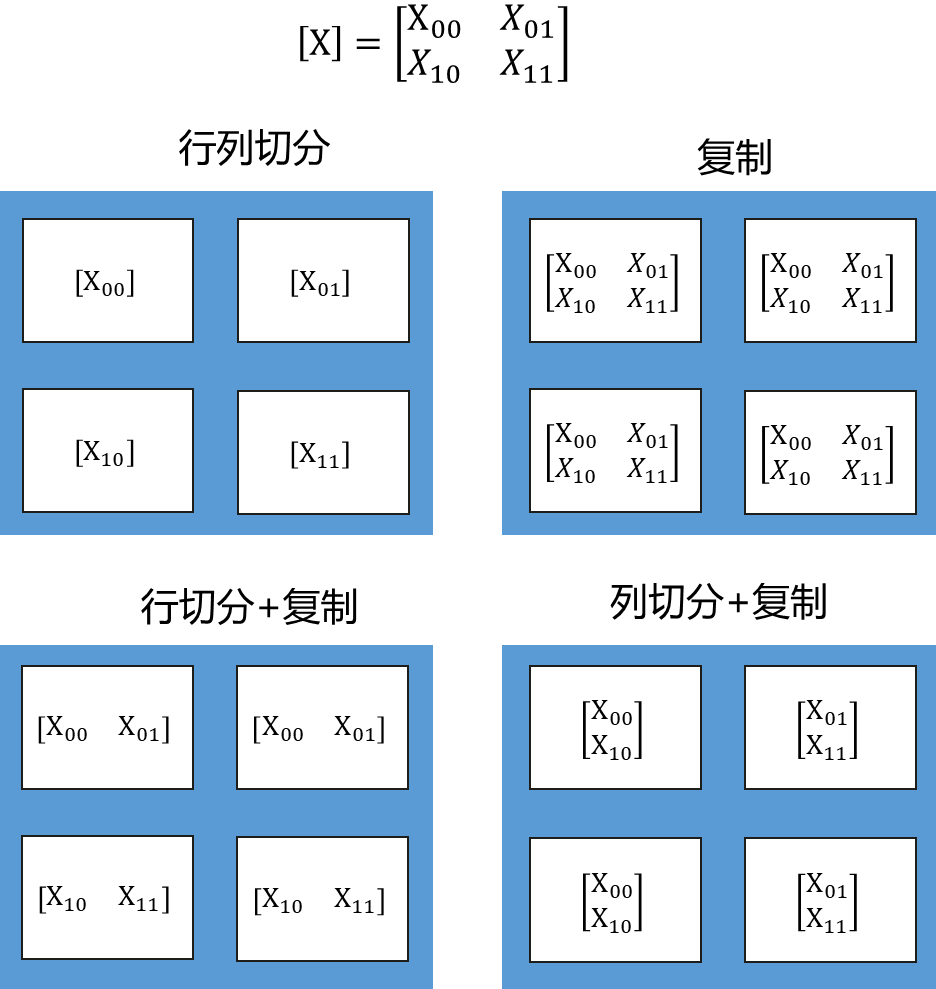
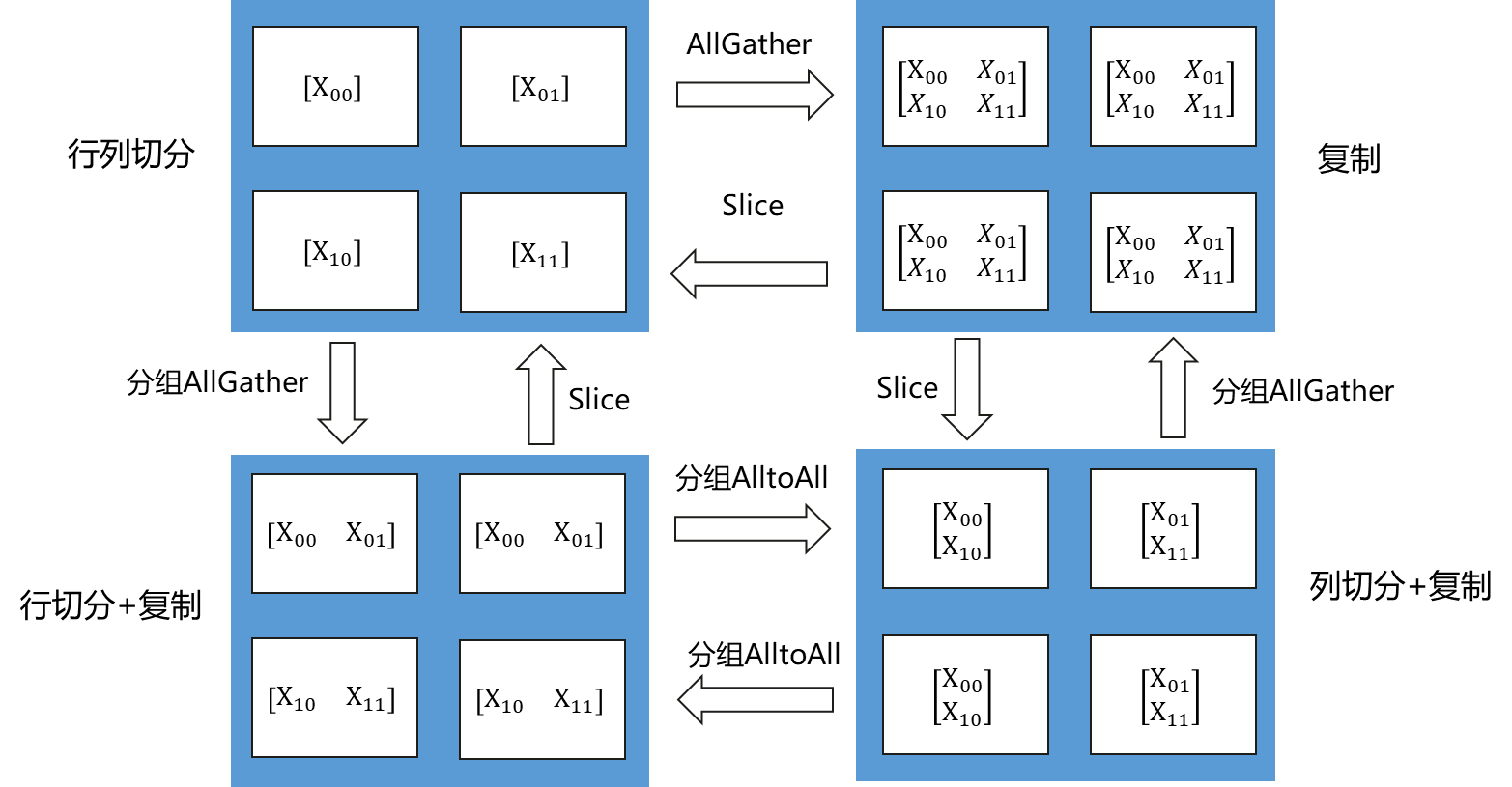
下图是一个更复杂的例子,是二维矩阵切分到4个节点。有四种Tensor Layout,行列同时切分、复制、行切分+复制、列切分+复制。由于执行时间是计算时间+通信时间,完全切分虽然计算时间更短,但是通信时间会比较长,有些场景下,不切满性能会更好,虽然计算时间更长,但是通信时间小,总的执行时间就会相对较小。
分布式Tensor Redistribution
Tensor Redistribution是不同Tensor Layout之间的转换,tensor在集群上从一种排列转成另外一种排列。在MindSpore自动并行流程中,每个算子都是独立建模,前一个算子输出的TenorLayout和下一个算子输入的TensorLayout可能会不同,编译阶段会自动插入Tensor Redistribution来调整输入输出关系。MindSpore分布式通信类MPI原语,所以这些重排操作,都会被分解成“集合通信+split+concat”的算子组合。下面两张图说明了几种Tensor Redistribution的操作。
Tensor切分到两个节点的重排
Tensor切分到四个节点的重排
混合并行样例
下面我们以两个矩阵乘法切分到4张卡上并行执行为例来讲解半自动并行。
- 数据并行转模型并行:
第一个矩阵乘法,X在行上面切4份,W不切分,所以W是在集群上复制。而第二个矩阵乘法左矩阵不切分即在集群复制,右矩阵在列上切4份。假设tensor X的第0维是batch维,W和V是模型的参数,这个例子就是数据并行转模型并行。这个是人脸识别或图像分类场景最常用的一种并行模式。
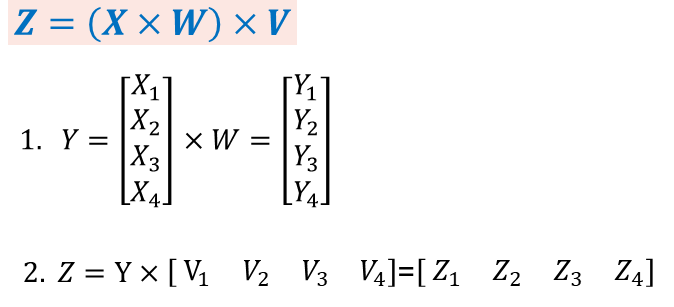
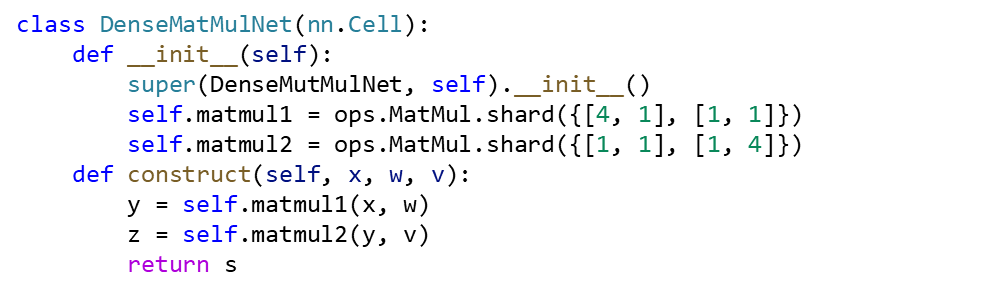
样例代码如下,用户只需要在MatMul算子初始化的时候配置shard策略,即能实现上述公式所描述的并行切分方式。Shard的配置有点类似transpose算子的方式,第一个中括号内的数据配置表示是的算子的第一个输入tensor的切分,第二个中括号内的配置表示算子的第二个输入tesnor的切分。数值个数对应的就是tensor的维度,这个例子是一个二维矩阵例子,所以都是两个配置。
在这种并行模式下,由于第一个算子输出的TensorLayout是第0维切分到集群,而第二个算子输入是要求tensor在集群上是复制的。所以在图编译阶段,会自动识别两个算子之间TensorLayout的不同,自动推导出tensor重排布的算法,自动在图中插入。而这个例子所需要的tensor重排就是一个AllGather算子(注:MindSpore AllGather算子会自动把多个输入tensor在第0维合并成一个大的tensor)。
此外,每个tensor切分会被绑定到哪个设备执行,也是由图编译阶段决定的。整体策略是尽可能把模型切分到服务器内,把数据并行维度切分到服务器间。主要是由于数据并行的通信可以与反向计算overlap起来,对网络带宽的需求相对模型并行小。这样能进一步提升模型切分后的执行性能。
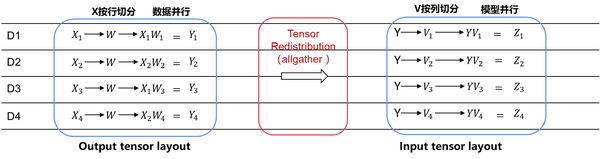
- 模型并行转数据并行:
X/Y/W/V的定义通上个例子,那这个例子就是一个模型并行转数据并行的样例。第一个矩阵乘法W切分,是模型并行。第二个矩阵乘法,V不切分,Y在batch维切分,是数据并行。这类并行模式是推荐算最常用的模式。

编码如下,代码保持了和串行类似,和上个样例对比起来,就是shard配置的策略有不同。

这个样例缩所触发的tensor重排就是一个AllToAll集合通信。
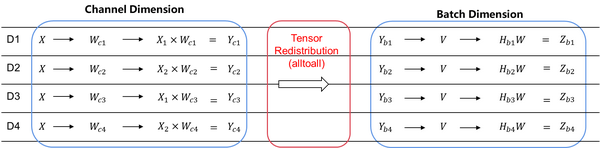
- 数据并行叠加模型并行:
X/Y/W/V的定义通上个例子,那这个例子就是一个数据并行叠加模型并行的样例。第一个矩阵乘法X、Y、W和V都切分,是数据并行叠加模型并行。是Transformer这类网络的一个典型并行方式。
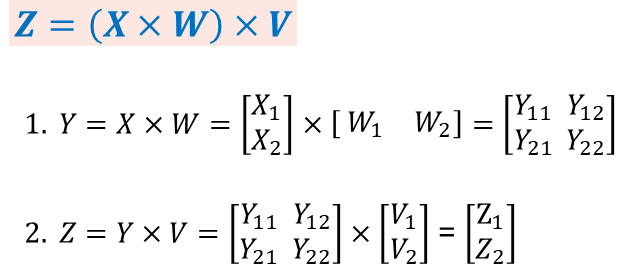
编码如下,代码保持了和串行类似,和上个样例对比起来,就是shard配置的策略有不同。

如下图所示,这个样例里,第一个算子的输出TensorLayout和第二算子需要的输入TensorLayout相同,所以就不需要加入tensor重排。而第二个矩阵乘法有在相关维度进行切分,即左矩阵的列和右矩阵的行。在相关维度切分后,从数学上需要引入一个求和操作,对应到分布式上,这个求和操作就是AllReduce Sum。
这个相关维度的切分规则,同样可以引申到其他有类似reduce操作的算子。MindSpore自动并行,在分布式算子的实现层面会自动对有相关维切分的算子插入AllReduce操作。

反向梯度AllReduce并行执行及融合
在深度学习算法中,batch维度和其他tensor维度是一个正交关系,正向batch维切分后,反向会通过AllReduce做一次梯度规约,而这次梯度AllReduce和反向计算是不相关的,可以和反向计算并行执行。同时为了提高通信效率,我们会把多个参数的AllReduce操作合并成一个。这个特性在Horovod中有比较好的实现,是通过动态运行实现的。而MindSpore是在图编译阶段实现,这样在运行阶段就不会引入额外的开销。实现后的效果如下图:

由于数据并行的这个特性,所以数据并行对网络带宽的要求相对模型并行来说小,这个在做手动并行以及自动并行的cost model中,要重点关注的。而业界早期的论文,大都没有引入这个并行维度的考虑,使得搜索出策略并不是最优的。
Optimizer模型并行
Optimizer模型并行在微软Zero及Google这两篇论文里[13][14]有比价完整的描述。MindSpore自动并行切tensor的功能,扩展到Optimizer子图,就等价于实现了Optimizer模型并行。实现方式如下图,在数据并行组中,把参数在第0维切分,在图编译节点会在正向计算时插入AllGather算子,把参数搜集到一起再进行计算,而反向则是通过自动微分的方式,在梯度同步时自动插入ReduceScatter算子,使得每个节点拿到一个规约后的梯度切片,经过Optimzier只更新对应的参数切片。
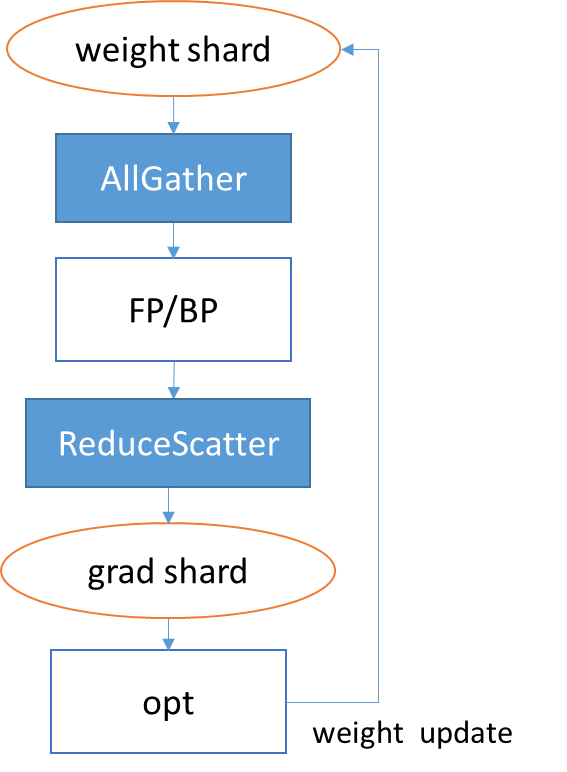
同时,为了更高利用网络通信能力,类似数据并行中的通信融合,我们同样会对正向AllGather进行和反向梯度的ReduceScatter进行融合。

Cost Model与自动策略搜索
最优策略搜索是个NP难问题,如何在较短时间内搜索出性能较优的策略,以及怎么构建出一个相对准确的Cost Model,是策略生成的难点。通过自动策略生成,用户就可以不需要配置并行策略,可以真正实现自动并行。
Cost Model
在自动策略搜索中,我们的目标是在每台设备内存约束的条件下,找到使得迭代时间最短的切分策略。因此,我们需要预估切分到每台设备上的计算图在训练过程中的内存使用峰值和迭代时间。这个是一个NP难问题。目标函数是,在一个内存上限值下,求T的最小值;


Cost Model分成两层,硬件无关和硬件相关,计算和通信数据量和硬件无关,计算通信系数和硬件相关。
策略搜索
由于我们考虑的是细粒度算子的并行策略,我们也为每个算子和“边”建立一套cost model,用来刻画其内存使用和贡献的迭代时间。其中“边”的耗时主要由tensor重排布决定。在刻画算子的时间消耗时,我们将其分解为正向计算时间、正向通信时间、反向计算时间和反向通信时间。整体计算图的时间即为所有算子点和边执行时间总和。
如何在静态编译时,而不使用profiling的前提下获得耗时信息呢?这里我们用到了近似:因为我们可以获得每个算子的shape信息,也能知道需要通信的数据量和数据类型,所以我们用一个线性函数来刻画一次训练迭代的时间:即将需要参与计算的数据量和通信的数据量作为输入,该线性函数返回一个数值,我们将其称为“迭代时间”。该“迭代时间”用作评判并行策略优劣的指标。算法流程入下图所示。
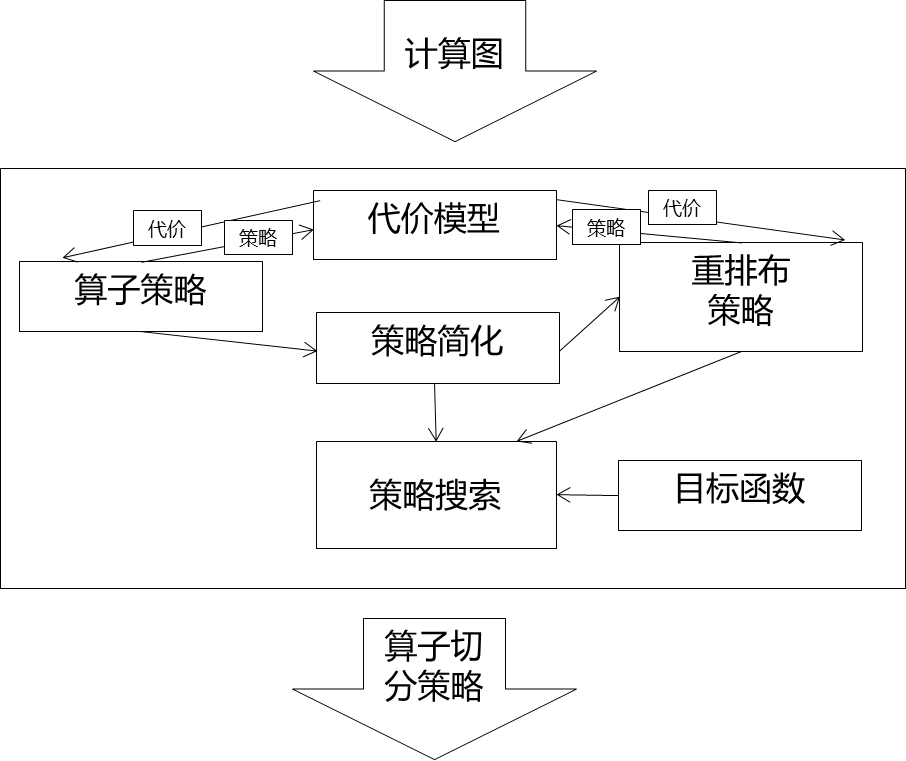
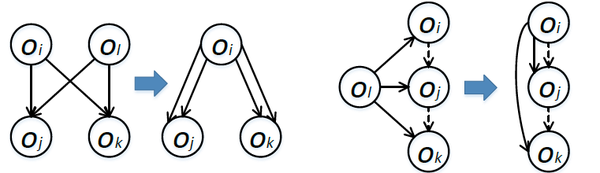
在算法实现上,我们以动态规划算法[6, 8, 12]为基础,扩展了其功能,提升了其运行速度。在功能方面,考虑到复杂的神经网络模型的图结构的复杂性,定义了新的图收缩(如下图)操作,以支持这些复杂图的策略搜索。在扩展后的算法中,我们支持了任意multi-source multi-target DAG的策略搜索。
在性能方面,当计算图的节点数量巨大或者可用设备数量巨大时,会导致策略空间爆炸,难以在可控时间内搜索出策略。究其根源,是因为单个算子的合法策略太多导致的。因此,我们在不损失太多精度的前提下,舍弃掉一些算子的可用策略,以此来控制每个算子的策略数量。这样使得算法运行时间大大加快,并且返回的策略有理论性能保证。
最后感谢苏博提供的素材!
MindSpore官网:https://www.mindspore.cn/
MindSpore论坛:https://bbs.huaweicloud.com/forum/forum-1076-1.html
代码仓地址:
Gitee-https://gitee.com/MindSpore/MindSpore
GitHub-https://github.com/MindSpore-ai/MindSpore
官方QQ群: 871543426
参考文献
[1] Ken Kennedy and Ulrich Kremer. Automatic data layout for distributed-memory machines. TOPLAS 1998.
[2] Jingke Li and Marina Chen. The data alignment phase in compiling programs for distributed-memory machines. JPDC 1991.
[3] Chien-Chin Huang, Qi Chen, Zhaoguo Wang, Russell Power, Jorge Ortiz, Jinyang Li, and Zhen Xiao. Spartan: A distributed array framework with smart tiling. USENIX ATC 2015.
[4] Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, and zhifeng Chen. GPipe:
Efficient Training of Giant Neural Networks using Pipeline Parallelism. NeurIPS 2019.
[5] Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. GShard: Scaling Giant
Models with Conditional Computation and Automatic Sharding. arXiv 2020.
[6] Zhihao Jia, Sina Lin, Charles R. Qi, and Alex Aiken. Exploring Hidden Dimensions in Accelerating Convolutional Neural Networks. ICML 2018.
[7] Zhihao Jia, Matei Zaharia, and Alex Aiken. Beyond Data and Model Parallelism for Deep Neural Networks. MLSys 2019.
[8] Minjie Wang, Chien-chin Huang, and Jinyang Li. Supporting Very Large Models Using Automatic Dataflow Graph Partitioning. EuroSys 2019.
[9] Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. PipeDream: Generalized
Pipeline Parallelism for DNN Training. SOSP 2019.
[10] Jakub Tarnawski, Amar Phanishayee, Nikhil R. Devanur, Divya Mahajan, and Fanny Nina Paravecino. Efficient Algorithms for Device Placement of DNN Graph Operators. NeurIPS 2020.
[11] Minjie Wang Chien-chin Huang Jinyang Li. Unifying Data, Model and Hybrid Parallelism
in Deep Learning via Tensor Tiling
[12] Zhenkun Cai, Kaihao Ma, Xiao Yan, Yidi Wu, Yuzhen Huang, James Cheng, Teng Su, Fan Yu. TensorOpt: Exploring the Tradeoffs in Distributed DNN Training with Auto-Parallelism
[13] Samyam Rajbhandari, Je Rasley, Olatunji Ruwase, Yuxiong He. ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
[14] Yuanzhong Xu HyoukJoong Lee Dehao Chen Hongjun Choi Blake Hechtman Shibo Wang. Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training
[15] Le Hou1;2 Youlong Cheng1\_ Noam Shazeer1 Niki Parmar1 Yeqing Li anagiotis Korfiatis3 Travis M. Drucker4 Daniel J. Blezek3 Xiaodan Song. High Resolution Medical Image Analysis with Spatial partioning
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

