
背景
2020年以来由于特殊的国际环境的影响下,原本在 AI边缘计算 占有绝对优势的海思平台 Hi35xx 系列 SoC 最终一货难求,导致国内其他 AI SoC 平台如同雨后春笋般激增。无论是真正的自主研发,还是套壳NVDLA,或直接购买已有 NPU IP,只要能解决行业刚需问题,就是一颗优秀的 AI SoC。本文主要介绍国内优秀的 NPU IP 供应商——芯原微电子(VeriSilicon)最近开源的 TIM-VX 项目,以及 Tengine 适配 TIM-VX 加速器的初步进展。
VeriSilicon
TIM-VX
TIM-VX 的全称是 Tensor Interface Module for OpenVX,是 VeriSilicon 提供的用于在支持 OpenVX 的其自研 ML 加速器 IP 上实现深度学习神经网络模型部署。它可以做为 Android NN、TensorFlow-Lite、MLIR、TVM、Tengine 等 Runtime Inference Framework 的 Backend 模块。
主要特性:
- 支持超过130种算子,提供量化、浮点格式支持;
- 通过简单易用的 API 来实现 Tensor 和 Operator 的创建;
- 灵活的计算图构建;
- 内置自定义层扩展;
- 丰富的调试函数接口;
- 提供 X86 平台 Simulator 功能。
什么是 OpenVX
OpenVX™ 是 Khronos 组织提出的一种计算机视觉应用程序跨平台加速标准。OpenVX 给对性能和功耗敏感的计算机视觉处理应用提供软件编程接口,特别是在嵌入式和实时的应用案例中,例如人脸、身体和手势跟踪、智能视频监控、先进的驾驶辅助系统(ADAS)、对象和场景重建、增强现实、视觉检测、机器人等应用。
下图是 OpenVX 的成员合照

关于 OpenVX 更加详细的介绍及最新版本动态可以直接关注 Khronos OpenVX 的版块
https://www.khronos.org/openvx/www.khronos.org
Tengine 适配 TIM-VX
最近一年,由于通过对 Tengine 代码的重构(Tengine Lite)已实现良好的前后端分离、异构切图、混合精度计算的功能。
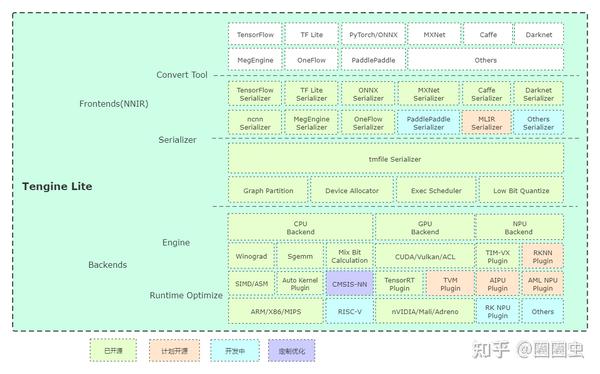
tengine architecture 2021-02-08
因此在适配 TIM-VX 后端的时候并没有较大的 gap。启用 TIM-VX 后端模式时,加载 Tengine 专有的网络模型存储文件 tmfile 后,框架自动对原始计算图按照 TIM-VX 已配置支持的算子列表进行子图(Subgraph)切割。
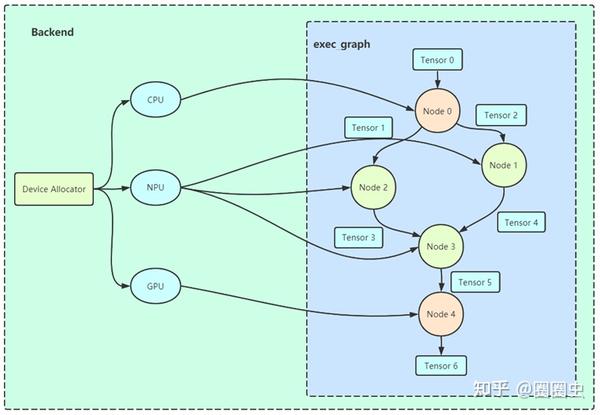
Graph Partition
同时 Tengine 由于支持多种量化方案(Int8、UInt8、Per-Layer、Per-Channel),当然也无缝支持 TIM-VX 私有的量化策略。所以原理上可以继承 Tengine Quantization Tool 优秀的 PTQ 精度调优成果。
项目进展
Tengine 的小伙伴赶在2021年春节前,已基于 Khadas VIM3 和 x86\_64 simulator 完成 Tengine with TIM-VX PoC 功能发布。

Khadas VIM3
具体使用指南请参考:
https://github.com/OAID/Tengine/blob/tengine-lite/doc/npu\_tim-vx\_user\_manual.mdgithub.com
后续计划
后续 Tengine 的小伙伴将在开源社区协同 TIM-VX 的工程师持续开展合作,支持更多的硬件设备和适配更广泛的网络模型。团队的大目标是通过 Tengine 的开源项目希望能给对 AI SoC 芯片感兴趣的伙伴提供一种通用、可靠的参考设计,赋能行业创造出更多有价值、有趣的 AIoT 产品。欢迎其他 NPU 厂家加入我们的开源项目~
插个楼,Tengine 已支持 NV GPU 各平台,欢迎试用。
Tengine在GPU上支持CUDA/TensorRT加速啦
传送门
https://github.com/OAID/Tenginegithub.com
VIM3 | Khadas丨中文站www.khadas.cn!
https://github.com/VeriSilicon/TIM-VXgithub.com
相关链接传送门
我是圈圈虫,一个热爱技术的中年大叔。快加入 OPEN AI LAB 开发者技术 QQ 群(829565581)来找我吧!溜了~~
入群秘令:CNN
更多Tengine相关内容请关注Tengine-边缘AI推理框架专栏。

