
文章转载于:知乎
作者:凯恩博
五一假期参加了华为和机器之心共同办的MindSpore学习的系列活动。
因此有机会申请试用到华为云中ModelArts Ascend 910做模型训练。
据工作人员讲可以试用大约一周的时间~ 还不错
由于华为此前的宣传中一再强调A910的模型训练性能,因而拿到A910试用资格后,迫不及待地做了一系列的模型对比实验。看看到底A910表现如何。
为了选择MindSpore在A910和GPU下同时兼容的模型,以及数据集适中大小,这里选择ResNet50+CIFAR10。
可惜的是当前A910没有适配的PyTorch版本,这里的对比实验是不严谨的横向对比,仅仅用来直观感受其性能吧。
实验配置
- Dataset: CIFAR10
- Model: ResNet50
- Batch size: 32
- Learning rate: init: 0.01, end: 0.00001, max: 0.1, warmup: 5, lr\_decay\_mode: poly
- Optimizer: Momentum(momentum=0.9, weight\_decay=1e-4)
- Loss func: SoftmaxCrossEntropyWithLogits
对比实验包括:
在如下环境下的train,10 epoch,不包括eval。
- 华为A910 + MindSpore 0.1 (ModelArts目前仅有0.1版)
- 英伟达2080Ti + MindSpore 0.2
- 英伟达2080Ti/P100/T4 + PyTorch 1.5
A910 + MindSpore 0.1
硬件来源ModelArts华为云昇腾集群,单卡
[Modelarts Service Log]2020-05-03 06:59:11,635 - INFO - Slogd startup
[Modelarts Service Log]2020-05-03 06:59:11,637 - INFO - FMK of device1 startup
INFO:root:Using MoXing-v1.16.1-
INFO:root:Using OBS-Python-SDK-3.1.2
Download data.
Create train and evaluate dataset.
Create dataset success.
Start run training, total epoch: 10.
epoch 1 cost time = 107.66270112991333, train step num: 1562, one step time: 68.92618510237729 ms, train samples per second of cluster: 464.3
epoch: 1 step: 1562, loss is 2.0400805
epoch 2 cost time = 30.637421369552612, train step num: 1562, one step time: 19.614226228906922 ms, train samples per second of cluster: 1631.5
epoch: 2 step: 1562, loss is 2.098766
epoch 3 cost time = 30.637131452560425, train step num: 1562, one step time: 19.614040622637916 ms, train samples per second of cluster: 1631.5
epoch: 3 step: 1562, loss is 1.8149554
epoch 4 cost time = 30.652636766433716, train step num: 1562, one step time: 19.623967200021585 ms, train samples per second of cluster: 1630.7
epoch: 4 step: 1562, loss is 1.8619552
epoch 5 cost time = 30.621018171310425, train step num: 1562, one step time: 19.60372482158158 ms, train samples per second of cluster: 1632.3
epoch: 5 step: 1562, loss is 2.5536947
epoch 6 cost time = 30.627925395965576, train step num: 1562, one step time: 19.6081468604133 ms, train samples per second of cluster: 1632.0
epoch: 6 step: 1562, loss is 1.8282737
epoch 7 cost time = 30.6348295211792, train step num: 1562, one step time: 19.612566914967477 ms, train samples per second of cluster: 1631.6
epoch: 7 step: 1562, loss is 1.7311925
epoch 8 cost time = 30.63702702522278, train step num: 1562, one step time: 19.61397376774826 ms, train samples per second of cluster: 1631.5
epoch: 8 step: 1562, loss is 1.5312912
epoch 9 cost time = 30.64574098587036, train step num: 1562, one step time: 19.61955248775311 ms, train samples per second of cluster: 1631.0
epoch: 9 step: 1562, loss is 1.3909853
epoch 10 cost time = 30.644134283065796, train step num: 1562, one step time: 19.618523868800125 ms, train samples per second of cluster: 1631.1
epoch: 10 step: 1562, loss is 1.0322676基本上在A910上的训练速度大约是 1630 张图片/秒。
GTX 2080Ti + MindSpore 0.2
硬件来源矩池云,单卡
和A910平台的MindSpore训练代码配置上稍微有些不同,因为目前MindSpore对于GPU设备尚不支持loop\_sink,需要设置为False。
context.set_context(enable_loop_sink=False)结果同在A910上自然没法比(其实是差非常多)。基本在 230张/秒的训练速度。
# 每200个iteration print一次
epoch 1 cost time = 36.767 one step time: 183.83, train samples/s: 174.1
epoch 1 cost time = 29.160 one step time: 145.80, train samples/s: 219.5
epoch 1 cost time = 29.187 one step time: 145.93, train samples/s: 219.3
epoch 1 cost time = 28.979 one step time: 144.89, train samples/s: 220.8
epoch 1 cost time = 28.987 one step time: 144.93, train samples/s: 220.8
epoch 1 cost time = 28.902 one step time: 144.51, train samples/s: 221.4
epoch 1 cost time = 28.859 one step time: 144.29, train samples/s: 221.8
epoch 2 cost time = 29.052 one step time: 145.2, train samples/s: 220.3
epoch 2 cost time = 28.920 one step time: 144.60, train samples/s: 221.3
epoch 2 cost time = 29.112 one step time: 145.56, train samples/s: 219.8
epoch 2 cost time = 29.118 one step time: 145.59, train samples/s: 219.8
epoch 2 cost time = 29.106 one step time: 145.53, train samples/s: 219.9
epoch 2 cost time = 29.048 one step time: 145.2, train samples/s: 220.3
epoch 2 cost time = 27.57 one step time: 137.85, train samples/s: 232.1
epoch 2 cost time = 27.6 one step time: 138., train samples/s: 231.6
epoch 3 cost time = 27.648 one step time: 138.24, train samples/s: 231.5
epoch 3 cost time = 27.546 one step time: 137.73, train samples/s: 232.3
epoch 3 cost time = 27.409 one step time: 137.04, train samples/s: 233.5
epoch 3 cost time = 27.35 one step time: 136.7, train samples/s: 233.9
epoch 3 cost time = 27.41 one step time: 137.09, train samples/s: 233.4
epoch 3 cost time = 27.40 one step time: 137.01, train samples/s: 233.6
epoch 3 cost time = 27.278 one step time: 136.39, train samples/s: 234.6
epoch 3 cost time = 27.29 one step time: 136.4, train samples/s: 234.5
epoch 4 cost time = 27.277 one step time: 136.38, train samples/s: 234.6
epoch 4 cost time = 27.27 one step time: 136.36, train samples/s: 234.7
epoch 4 cost time = 27.33 one step time: 136.66, train samples/s: 234.1
epoch 4 cost time = 27.330 one step time: 136.65, train samples/s: 234.2
epoch 4 cost time = 27.462 one step time: 137.31, train samples/s: 233.0
epoch 4 cost time = 27.233 one step time: 136.16, train samples/s: 235.0
epoch 4 cost time = 27.542 one step time: 137.7, train samples/s: 232.4
epoch 4 cost time = 27.459 one step time: 137.29, train samples/s: 233.1
epoch 5 cost time = 27.284 one step time: 136.4, train samples/s: 234.6
...GTX 2080Ti + PyTorch 1.5
硬件来源矩池云,单卡
虽然上面看到2080Ti + MindSpore表现的一般般。
但当我们换用PyTorch 1.5时,发现推理速度可以达到 约840 ~ 850张/秒。
可见MindSpore当前在GPU下的性能未能很好的发挥。其实这也好理解,当前MindSpore才开源一个多月,华为MindSpore Team的工作重心多半是在对A910的支持上,对GPU的优化还需要时间。
epoch: 0, time: 59.38535284996033, 841.9584560914737 images/sec
epoch: 1, time: 59.88723134994507, 834.9025138235224 images/sec
epoch: 2, time: 58.60565137863159, 853.1600421428072 images/sec
epoch: 3, time: 60.722407817840576, 823.4192581755582 images/sec
epoch: 4, time: 59.398728370666504, 841.7688622555096 images/sec
epoch: 5, time: 57.40373611450195, 871.0234452382352 images/sec
epoch: 6, time: 58.88580918312073, 849.1010091159995 images/sec
epoch: 7, time: 59.288349628448486, 843.3360063712815 images/sec
epoch: 8, time: 58.900673389434814, 848.8867295185906 images/sec
epoch: 9, time: 58.6528799533844, 852.4730591189817 images/sec这里还有一个小小的插曲,第一次做这个实验时,环境中的PyTorch是1.2,训练速度仅是升级PyTorch 1.5后的 77%:
epoch: 0, time: 75.62278366088867, 661.1764018660356 images/sec
epoch: 1, time: 75.28524422645569, 664.140769067595 images/sec
epoch: 2, time: 75.68567728996277, 660.6269744861075 images/sec
epoch: 3, time: 76.24357485771179, 655.7929647621011 images/sec
epoch: 4, time: 76.67036390304565, 652.1424635890348 images/sec
epoch: 5, time: 75.36379647254944, 663.4485301999354 images/sec
epoch: 6, time: 76.37205100059509, 654.6897634006241 images/sec
epoch: 7, time: 76.13714075088501, 656.7097149549684 images/sec
epoch: 8, time: 74.63874101638794, 669.8934001180677 images/sec
epoch: 9, time: 75.37042999267578, 663.3901386108427 images/sec由此看来,还是要经常升级PyTorch啊~
Tesla P100 + PyTorch 1.5
硬件来源华为ModelArts Notebook(当前提供单任务1小时的试用,可续),单卡
大约 790张/秒
epoch: 0, time: 63.36981773376465, 789.0191543561762 images/sec
epoch: 1, time: 62.97652459144592, 793.9466384398017 images/sec
epoch: 2, time: 63.09738540649414, 792.4258616721363 images/sec
epoch: 3, time: 63.07587289810181, 792.6961245669054 images/sec
epoch: 4, time: 63.424623250961304, 788.3373591697633 images/sec
epoch: 5, time: 63.103607416152954, 792.3477285579278 images/sec
epoch: 6, time: 63.47292637825012, 787.73743157891 images/sec
epoch: 7, time: 63.04208755493164, 793.1209441063094 images/sec
epoch: 8, time: 63.53010869026184, 787.0284032374748 images/sec
epoch: 9, time: 63.33588719367981, 789.441850669922 images/secTesla T4 + PyTorch 1.5
硬件来源Google Colab,单卡
差不多740 - 750 张/秒,稍逊于P100
epoch: 0, time: 67.75457763671875, 737.9575187980084 images/sec
epoch: 1, time: 67.86454939842224, 736.76168843998 images/sec
epoch: 2, time: 67.7728979587555, 737.7580346413469 images/sec
epoch: 3, time: 67.1821916103363, 744.2448482479583 images/sec
epoch: 4, time: 66.74327516555786, 749.1391436211982 images/sec
epoch: 5, time: 66.77364683151245, 748.7984013538037 images/sec
epoch: 6, time: 66.86375832557678, 747.7892546293491 images/sec
epoch: 7, time: 67.04962396621704, 745.7163372786774 images/sec
epoch: 8, time: 66.8210072517395, 748.2676789296436 images/sec
epoch: 9, time: 66.56065726280212, 751.1945052252788 images/sec综合对比
当然,综合的训练速度不仅仅取决于GPU/NPU这些芯片,也取决于CPU的负载、IO、内存等因素。这里由于硬件的限制,没法做那么严格的比较,暂且以最终测量的训练速度来呈现。
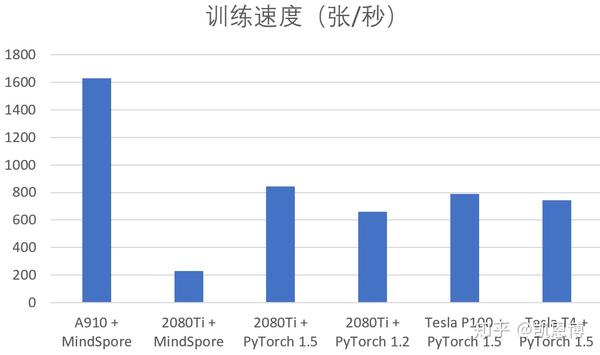
根据这些的数据,A910在训练速度约是2080Ti的1.93倍。
由于没找到V100这样的配置,这次没办法实际测试其训练的FPS了。不过可以参考https://zhuanlan.zhihu.com/p/46779820 里对2080Ti及V100的评测。按照2080Ti在32位精度下是V100 80%性能估算,A910的训练速度性能至少是V100的1.5倍左右/以上。
看这些数据,A910的性能确实强大,也没有辜负对它的期待。
华为作为国内第一家做AI训练芯片的企业,确实让人服气。祝贺昇腾A910芯片,也希望MindSpore可以对GPU的支持越来越好,打造世界一流的AI训练框架。
附录:
设置环境
矩池云的容器可以选择已经装好MindSpore的镜像文件。包括Jupyter环境等等都是设置好的。当然,也可以自己创建Python虚拟环境后通过pip安装MindSpore,注意,这里需要CUDA10.1:
text
conda create -n mindspore python=3.7.5 -y
conda activate mindspore
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/0.2.0-alpha/MindSpore/gpu/cuda-10.1/mindspore_gpu-0.2.0-cp37-cp37m-linux_x86_64.whl
# 测试安装
python
>>> import mindspore as ms
>>> ms.__version__
'0.2.0'训练ResNet 50 with CIFAR10
MindSpore已经可以支持到Lenet、Alexnet、ResNet50这几个网络在GPU模型下的训练。当然,所有的模型都支持在昇腾芯片的训练。
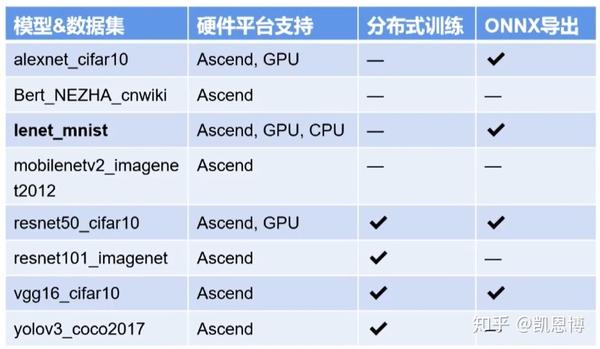
官方文档里有完整的ResNet训练example,基本是可以毫无压力的运行。
如果测试安装时遇到cuda相关error,记得需要export CUDA路径:
text
export LD_LIBRARY_PATH=/usr/local/cuda/lib64- The End -
推荐阅读
更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

