
文章转载于:知乎
作者:金雪锋
本文是AI框架分析专栏的第五篇,总体目录参见:
AI框架的演进趋势和MindSpore的构想:
数据处理其实在AI的训练和推理中占了很大的比重,但是业界在这一块的分析比较少,本文期望通过MindSpore实践给大家一些参考。
AI框架中的数据处理
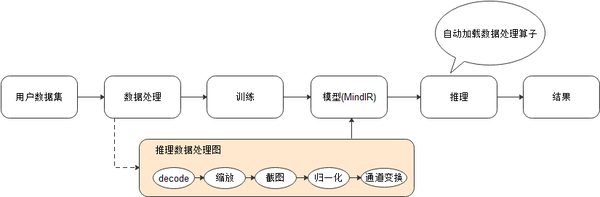
在构建深度学习模型时,数据处理是我们最先面临的挑战。任务开始之前,由于数据量受限,或者为了得到更好的结果,通常需要进行数据增强操作,来获得能使网络受益的数据输入。典型的训练数据处理流程如下图所示:

加载:指从各种异构存储中将训练数据加载到内存中,加载时涉及数据的访问、解析等处理;
Shuffle:训练一般是多个epoch,通过shuffle打乱数据集不同epoch的数据排序,防止训练过拟合。如果数据集支持随机访问,则只需按不同顺序随机选择数据就可以非常有效地进行混洗shuffle。如果数据集不支持随机访问(或仅部分随机访问像多个文件对象),那么一个子集的数据可以加载到一个特殊的混洗缓冲区shuffle buffer中。
map:完成训练数据的处理,包括图像类数据增强、Text类分词等处理。其中,数据增强是一种创造有着不同方向的“新”数据的方法,一是从有限数据中生成“更多数据”,二是防止过拟合。
batch:训练时一般都是使用mini-batch的方式,即一个批次训练少量数据;batch算子负责构造一个批次的数据发送给训练;
repeat:可以通过repeat的方式增加训练的总数据量;一次repeat就是加载一遍整个训练集。
模型在进行推理时,同样会涉及到数据处理,典型的过程如下图所示:
**

**
推理过程的数据处理,将一张图片进行解码、缩放、中心截图、归一化、通道变换等操作后,送入模型中进行推理并得到结果。与训练相比,推理时的数据转换基本一致,不同的是推理时一般加载单样本进行处理,而非数据集。
本文将重点分析AI框架在数据处理时面临的挑战以及MindSpore的解决思路。
难点与挑战
2.1 数据处理的高效性
当前各AI框架的数据处理主要利用CPU运算,训练则利用GPU/AI芯片,两者是并行的。理想情况下,应该在每轮迭代开始前,就准备好完成增强之后的数据,保持训练过程持续地进行。然而在实际的训练中,很多时候数据处理成为了阻碍性能提升的瓶颈:或是因为从存储中读取数据的速度不足(I/O bound),或是因为数据增强操作效率过低(CPU bound)。
根据黄氏定律,GPU/AI芯片的算力每一年会提升一倍,相比于即将失效的摩尔定律,AI芯片的算力提升速度会远大于CPU。模型迭代计算效率的不断提升,对数据处理也提出了更高的要求:数据处理过程必须足够高效,才能够避免GPU/AI芯片因为等待训练数据而空闲。
2.2 数据处理的灵活性
数据处理的灵活性挑战主要体现在以下两个方面:
- 数据集种类繁多,难以统一
目前已知常用的开源数据集有几百种,每种由不同的组织/机构来产生,有各自的格式与组织方式。根据深度学习任务的不同,每种类型的输入也有自身的特点。以图像为例,其包含类型、长、宽、大小等属性信息,每张训练图像被标记成某一个类别,这些图像及其对应类别的列表数据被用来进行分类等训练;以音频为例,通过训练可以直接将语音转换为文字,进一步作为智能AI的输入,完成语义理解及指令性操作。
在数据集加载时,如何支持种类繁多的图像、文本、音频、视频格式,屏蔽IO差异并将其映射到内存结构中进行下一步处理,是AI框架重点需要解决的问题。
- 数据增强算法非常灵活,需要框架提供足够易用的接口来支持用户定制数据处理过程
例如CV类场景,图像作为网络的输入,需要保证一定的一致性(如:大小、通道数、归一化等),也需要有一定的泛化能力(如:镜像、旋转、混合、颜色变换等),才能使训练得到的模型具有更好的精度。研究已经证明,采用不同的数据处理逻辑,训练得到的模型精度会有明显的不同。
以resnet50和ssd为例,数据处理过程对比如下:

其中既涉及到经典的数据处理逻辑,又包含了用户自定义的处理过程。AutoML和动态shape等场景,也对数据处理的灵活性提出了更高要求。所以,提供更多、更灵活的数据处理机制,也是框架需要重点考虑的。
2.3 端云统一
- 训练导出的模型,在推理时如何高效进行数据处理:
网络训练生成的模型文件中,记录了训练时的计算图及权重信息,但是数据处理过程往往没有统一存储到模型中,这就导致AI工程师在使用模型进行推理时,需要重新编写数据处理代码,十分不便。
- 端侧资源受限,需要提供更轻量化的数据处理方式:
在端侧场景下,CPU和内存资源往往比较少,在提供数据处理的能力时,要求API尽可能简单、轻便,以最少的资源占用获得最快的执行效率。同时,需要AI框架提供的库尽可能的小。所以,使用云化场景提供的数据处理机制(启动慢、资源占用大)就不是特别适用。如何在不同的场景下提供最合适的数据处理方法是AI框架面临的挑战。
典型的云侧场景与端侧场景资源对比如下:
资源
云侧
端侧
CPU
100+核
4核-8核
内存
250G-750G
3G-8G
Device
GPU/Ascend910
CPU/Ascend310
MindSpore设计思考
3.1 设计目标与思路
MindSpore的设计中,充分考虑了数据处理的高效性、灵活性以及在不同场景下的适配性。整个数据处理子系统分为以下模块:

API:数据处理过程在MindSpore中以图的形式表示,称为“数据图”。MindSpore对外提供Python API来定义数据图,内部实现图优化和图执行。
整个数据加载和预处理的流程实现为多步并行流水线(data processing pipeline),包括:
Adaptor:将上层语言(如Python)构建的数据图,转换为下层可执行的C++数据图(Execution tree)
Optimizer:数据图优化器
Runtime:运行优化后Execution tree的执行引擎
数据集算子(dataset operators):Execution tree中的某个节点,对应数据处理流水线中的一步具体操作,比如从文件夹加载训练数据的ImageFolder算子,做各种数据增强的Map算子,Repeat算子等。
数据增强算子(data augmentation operators):也可称为tensor算子,是对某个tensor变换的,比如Decode,Resize,Crop,Pad等,通常是被dataset operator中的Map算子调用。
数据增强后的结果,通过队列和前向反向计算系统相连。下面将介绍这套子系统如何达到极致的数据处理性能。
3.2 极致的处理性能
- 多段pipeline流水线:
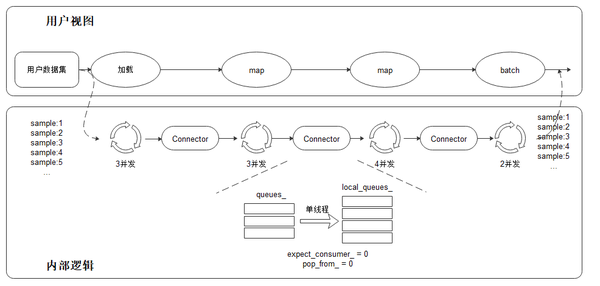
相比于业界其他框架,MindSpore采用了多段并行流水线(multi-stage parallel pipeline)的方式来构建数据处理pipeline。这种架构一方面可以更加细粒度地规划CPU等计算资源的使用,另一方面天然支持各段使用异构硬件进行流水处理,从而提高数据处理过程的吞吐量。如上图所示,每个数据集算子(inline除外)都包含一个输出Connector:由一组阻塞队列和计数器组成的保序缓冲队列。每当一个数据集算子完成一块缓存数据的处理,这个算子会将这块缓存推送到自身的输出Connector。下游的数据集算子会从上游的输出Connector里取出缓存进行后续处理。这种机制的优势包括:
- 数据集加载、map、batch等操作以任务调度机制来驱动,每个操作的任务互相独立,上下文通过Connector来实现Pipeline;
- 每个操作均可以实现细粒度的多线程/多进程并行加速。数据框架为用户提供调整算子线程数/多进程处理的接口,可以灵活控制各个节点的处理速度,进而实现整个数据处理Pipeline性能最优;
- Connector支持用户对其大小进行设置,在一定程度上可以有效的控制内存的使用率,适用于不同网络对于数据处理速度的要求。
在这种数据处理机制下,对输出数据进行保序处理是保证训练精度的关键。保序意味数据处理流水线运行时,同样顺序的原始数据输入,需要保证数据处理完成后,得到同样顺序的数据输出。MindSpore采用轮询算法来保证多个线程数据处理的有序性:
在上面的数据处理pipeline示例中,保序操作发生在下游map操作(4并发)的取出操作(单线程执行)中,其以轮询的方式取出上游队列中的数据。Connector内部有两个计数器expect\_consumer\_记录已经有多少个consumer从queues\_中取了数据,pop\_from\_记录了哪个内部阻塞队列将要进行下一次取出。expect\_consumer\_以consumer个数取余,而pop\_from\_以producer个数取余。在expect\_consumer\_再次为0时,说明所有的local\_queues\_已经都处理上一批任务,然后继续下一批任务分配及处理,进而实现了上游至下游map操作的多并发保序处理。
- 数据处理与计算过程pipeline
数据pipeline会不断地进行数据处理,并把处理后的数据发送到device侧的缓存;当一个step执行结束后,会直接从device的缓存中读取下一个step的数据。
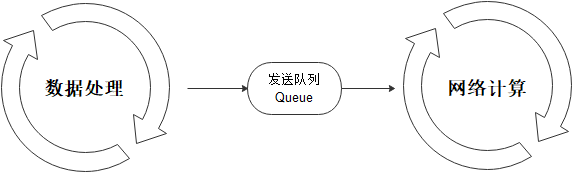
数据处理:负责将数据集处理成网络需要的输入,并传递给发送队列中,保证数据处理的高效取可;
发送队列Queue:维护数据列队,保证数据处理与网络计算过程互不影响,实现桥梁的作用;
网络计算:从发送队列中获取数据,用于迭代训练。
以上三者各司其职,相互独立,构筑整个训练过程中Pipeline。这样,只要数据队列不为空,模型训练就不会因为等待训练数据而产生瓶颈。
- 缓存技术
当数据集的size较大时,无法全部加载到memory cache,此时训练中的部分数据需要从磁盘读取,可能会遇到I/O瓶颈,增大每个epoch的cache命中率就显得尤为关键。传统的缓存管理策略采用LRU策略,没有考虑深度学习数据的读取特点:在不同的epoch之间数据是重复读取的,而在同一个epoch中随机读取。每条数据的读取概率都是相同的,因此哪个数据被缓存并不是最重要的,已经cache的数据在被使用之前不被换出更加重要。针对这个特点,我们使用了一个简单高效的缓存算法:数据一旦被缓存,就不会从cache中被换出。
在数据图优化的过程中,会根据流水线结构自动生成缓存算子,既可以缓存原始数据集,也可以缓存数据增强处理后的结果。
3.3 灵活的定制能力
整个数据处理pipeline中,用户往往需要特定的处理逻辑,这些处理逻辑有其特殊性,无法固化到框架中。因此,框架需要具备开放的能力,让用户能够订制不同的数据处理逻辑。MindSpore提供了灵活的数据集加载方式、丰富的数据处理算子、自动数据增强、数据动态Shape、数据处理Callback等机制等供开发人员在各种场景使用。
- 灵活的数据集加载方式
针对数据集种类繁多、格式与组织各异的难题,MindSpore提供了三种不同的数据集加载方式:
1)如果用户使用常用数据集,那么可以使用MindSpore内置的API接口直接进行加载。MindSpore实现了包括CelebADataset、Cifar10Dataset、CocoDataset、ImageFolderDataset、MnistDataset、VOCDataset等数据集的C++ IO Reader加载,在保证性能的同时,实现了数据集的开箱即用。
2)用户将数据集转换为MindSpore数据格式,即MindRecord,然后通过MindSpore的API进行加载。MindRecord可以将不同的数据集格式归一化,有聚合存储、高效读取、快速编解码、灵活控制分区大小等多种优势。
3)如果用户已经有自己数据集的Python读取类,那么可以使用MindSpore的GeneratorDataset API调用该类实现数据集加载。这种方式可以快速集成已有代码,改动最小,但因为是Python IO Reader,需要额外关注数据加载性能。
- 通过Python层自定义、C层插件的方式支持更多算子
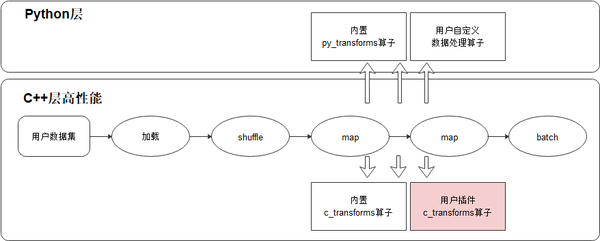
MindSpore内置了丰富的数据处理算子。这些算子可以分为C层以及Python层,C层算子能提供较高的执行性能;Python层算子可以很方便集成第三方包完成数据处理的功能,但是性能较低,好处是易开发易使用。MindSpore支持用户扩展自定义的数据处理算子,用户可以开发C层算子代码,编译后以插件的形式注册到MindSpore的数据处理中进行调用。
- 支持自动数据增强策略
MindSpore提供了基于特定策略自动对图像进行数据增强处理的机制:通过基于概率或者回调参数的数据增强策略,可以实现算子自动选择执行,达到训练精度提升的目的。
例如对 ImageNet 数据集,自动数据增强最终搜索出的方案包含 25 个子策略组合,每个子策略包含两种变换,针对每幅图像都随机的挑选一个子策略组合,然后以一定的概率来决定是否执行子策略中的每种变换。
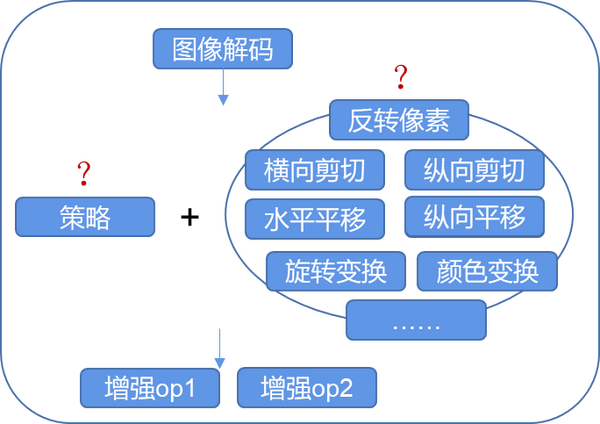
这些策略包括:
RandomSelectSubpolicy - 多批概率算子,随机选择其中一批执行
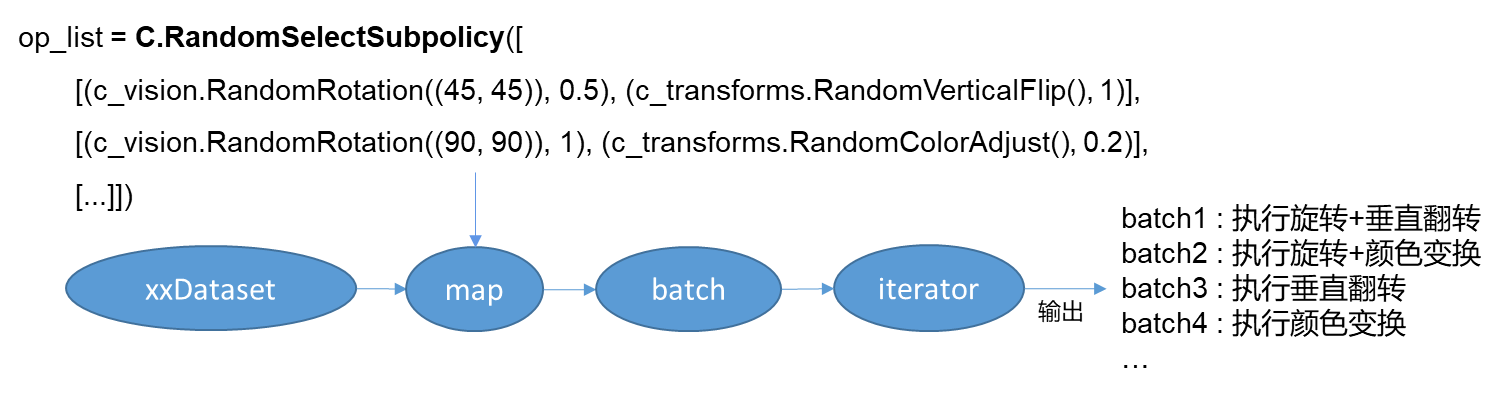
RandomChoice - 多个算子选择其中一个执行
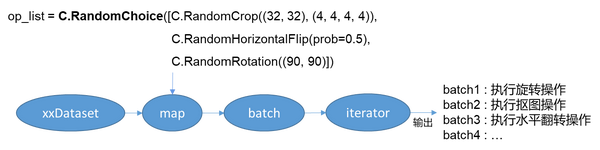
RandomApply -基于某个概率执行这批算子
**
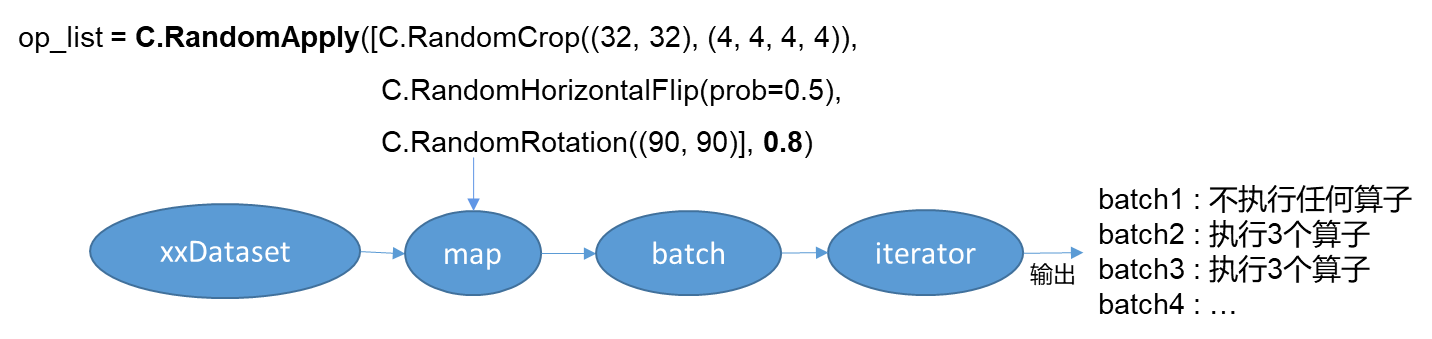
**
通过自动数据增强操作,在ImageNet数据集上可以提升1%左右的训练精度。
- 支持动态shape
MindSpore通过 per\_batch\_map支持用户自定义控制输出不同Shape的训练数据,满足网络需要基于不同场景调整数据Shape的诉求。

- 用户自定义数据Shape生成逻辑udf,如:第n个step生成shape为(x,y,z,...)的数据;
- 通过batch(…, per\_batch\_map=udf)将第一步定义的逻辑生效,最终得到不同Shape训练数据。
- Callback机制让数据处理更加灵活
通过callback机制实现根据训练结果动态调整数据增强的逻辑,为数据增强过程提供更灵活的操作。
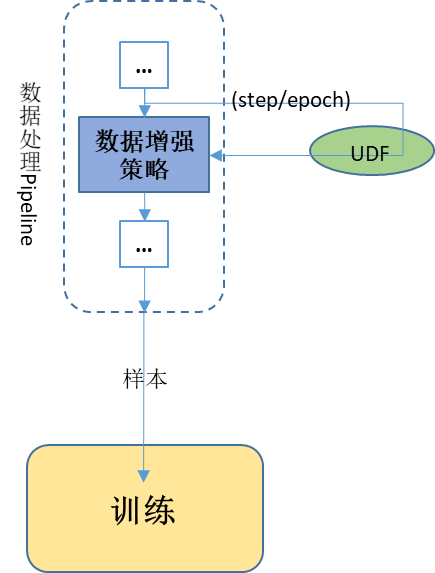
MindSpore支持用户基于数据处理提供的DSCallback(包含epoch开始、step开始、step结束、epoch结束等)实现自己的数据增强逻辑UDF,并将其添加至map操作中,以实现更灵活的数据增强操作。
3.4 端云统一架构
- 数据图与计算图的统一
MindIR是MindSpore基于图表示的函数式IR,其最核心的目的是服务于自动微分变换。自动微分采用的是基于函数式编程框架的变换方法,因此IR采用了接近于ANF函数式的语义。
推理数据图典型的场景为:数据集样本大小缩放、中间截图、归一化、通道变换。

我们将推理数据图以子图的方式保存至生成的模型文件(MindIR)中,那么在推理时,可以通过统一的接口加载模型中数据处理流程,自动进行数据处理得到模型需要的输入数据,简化用户的操作,提升易用性。
- 轻量化的数据处理
云侧训练时,可以被使用的资源往往比较充裕,数据处理Pipeline在运行过程中是会占用比较多系统资源(CPU和内存),以ImageNet为例,训练过程中CPU占用20%,内存占用30-50G,这显然在端侧是不可被接收的,并且数据处理Pipeline在初始化时启动会慢些,这也不适用于端侧需要快速启动、多次训练/推理的前提条件。故:MindSpore基于现有数据处理算子,提供一套更轻量化、更适用于端侧的API,解决云化场景数据处理Pipeline不适用于端侧的问题。
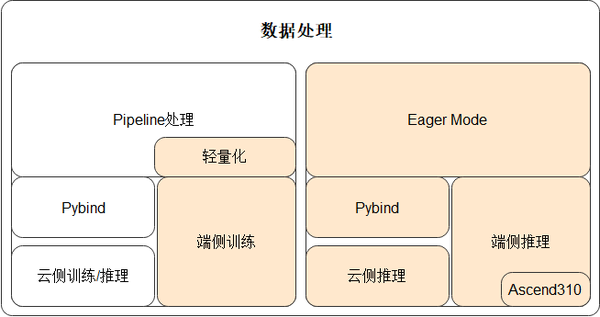
MindSpore基于Pipeline调整架构,支持数据处理单算子独立使用(Eager Mode),支持各种场景推理,提供给AI开发人员更大的灵活性;同时,将Pipeline轻量化,实现基于Pull Base的轻量化pipeline,减少资源占用并且处理速度快。
通过上述两种方法,MindSpore保证了统一的数据处理架构支撑多种不同的应用场景。
未来计划
在未来,MindSpore将继续完善数据处理的易用性,提供更丰富的算子和内置数据集。与此同时,探索大规模数据处理的加速技术,包括:
- 资源自适应分配
当前各数据增强算子使用的处理线程数目由用户手工配置,对用户的调优经验要求极高。通过自适应判断Pipeline瓶颈,由框架给各个数据增强算子合理分配CPU资源,可以在训练过程中动态优化数据处理性能,免去用户繁琐的调优过程。
- 异构硬件加速
当前的数据处理Pipeline操作在CPU执行,一旦出现瓶颈,带来AI芯片/GPU等待空闲,用户无法充分利用所有硬件的计算能力。MindSpore期望构建用户无感知的异构硬件资源调度能力:通过监测硬件资源使用,完善Ascend/GPU上的数据处理算子,采用代价模型自适应地将数据处理任务调度至合适的资源,实现异构硬件的充分利用。
- 分布式缓存
当前如GPT-3等网络的训练需要使用超大规模数据集,这些数据难以在本地存储,直接从OBS读取会受网络IO限制而影响性能。与此同时,在AutoML场景下,用户经常在集群中运行同一类模型的多个作业(只是超参设置不同),每个作业独立进行数据加载和处理效率极低。MindSpore期望构建分布式缓存能力,加速这些场景下的数据处理。
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

