
最近诺亚实验室在BERT的量化压缩上又有了新的进展-TernaryBERT,欢迎大家参考
TernaryBERT简介
基于Transformer的预训练模型如BERT在许多自然语言处理任务中都取得了显著的性能。然而,这些模型昂贵的计算和内存都阻碍了它们在资源受限设备上的部署。因此,我们提出了TernaryBERT,它将微调的BERT模型中权值三值化。此外,为了减少低比特导致的精度下降,我们在训练过程中采用了知识蒸馏技术。在GLUE和SQuAD上进行的实验表明,我们提出的TernaryBERT量化方法优于其他的BERT量化方法,甚至可以达到与全精度模型相当的性能,同时将模型缩小了14.9倍。现在TernaryBERT的开源代码已经在MindSpore上首发了。
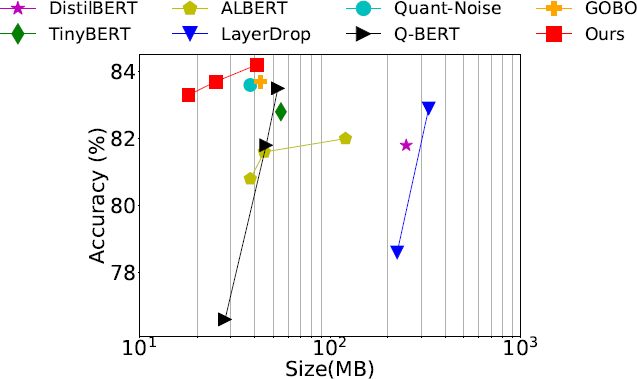
图1:不同算法的模型尺寸与MNLI-m精度对比。我们提出的方法(红色方块)优于其他的BERT压缩方法。
图片来源:https://arxiv.org/abs/2009.12812
论文链接:
https://arxiv.org/abs/2009.12812
开源地址:
https://gitee.com/mindspore/mindspore/tree/master/model\_zoo/research/nlp/ternarybert
具体原理参见:
让BERT瘦下来 MindSpore量化训练极低比特语言模型 TernaryBERTmp.weixin.qq.com
实验结果
和BERT量化算法对比的结果
表1显示了GLUE基准的开发集结果。从表1中我们发现:
1)对于2-bit权重,由于模型容量的急剧减少,Q-BERT(或Q2BERT)与全精度BERT之间存在很大的差距。TernaryBERT的性能明显优于Q-BERT和Q2BERT,即使word embedding的比特数更少。同时,TerneyBERT以14.9倍更小的尺寸实现了与全精度基线相当的性能。
2)当权值的位数增加到8时,所有量化模型的性能都得到了极大的改善,甚至可以与全精度基线相媲美,这表明设置8-8-8对BERT来说并不具有挑战性。我们提出的方法在MNLI和SST-2上都优于Q-BERT,在8个任务中有7个优于Q8BERT。
3)TWN和LAT在所有任务上都取得了相似的结果,表明两种三值化方法都具有竞争力。
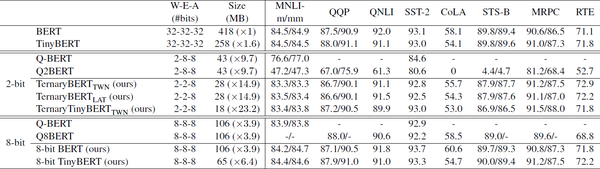
表1:GLUE基准上量化的BERT和TinyBERT的开发集结果。我们将Transformer层权重、word embedding和激活的位数缩写为“W-E-A(#位)”。
表格来源:https://arxiv.org/abs/2009.12812
和其他BERT压缩方法对比
从表2可以看出,与量化以外的其他常用的BERT压缩方法相比,本文提出的方法可以获得相似或更好的性能,但要小得多。
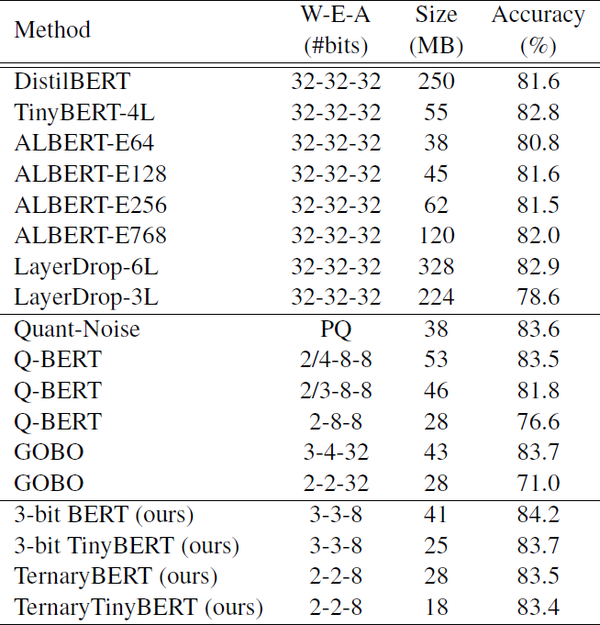
表2:在MNLI-m上,TernaryBERT与其他压缩方法的比较。
表格来源:https://arxiv.org/abs/2009.12812
MindSpore代码实现
相关训练与推理代码,以及使用方法已经开源在:https://gitee.com/mindspore/mindspore/tree/master/model\_zoo/research/nlp/ternarybert。
为了方便大家验证我们的结果以及创新,我们将模型的结构,以及超参数的设置汇总到了相关的代码仓的/script文件夹。src/config.py中存放了配置信息。参数设置以GPU训练脚本train.sh为例:
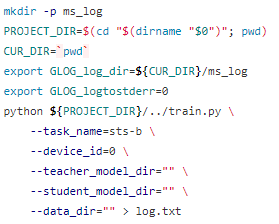
图5:训练脚本
如果想切换其他的glue数据集,只需要在--task\_name的位置将上图中的sts-b更改即可。若想使用自己的数据集。可以参考src/dataset.py中构造数据pipeline的代码。只事先将文本数据转换成需要的输入格式然后封装为tfrecord或者mindrecord格式,就可以使用pipeline进行读取。

图6:构造数据pipeline的代码
TernaryBERT的模型结构的定义和激活伪量化操作放在/src/tinybert\_model.py中。用户可以在这里手动插入激活的伪量化结点或更改网络结构。
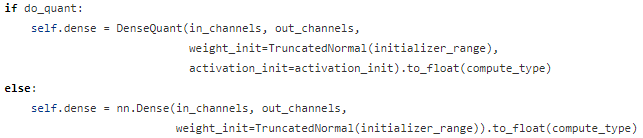
图7:可以灵活插入激活伪量化结点
src/cell\_wrapper.py封装了训练相关的类以及权重的伪量化操作。
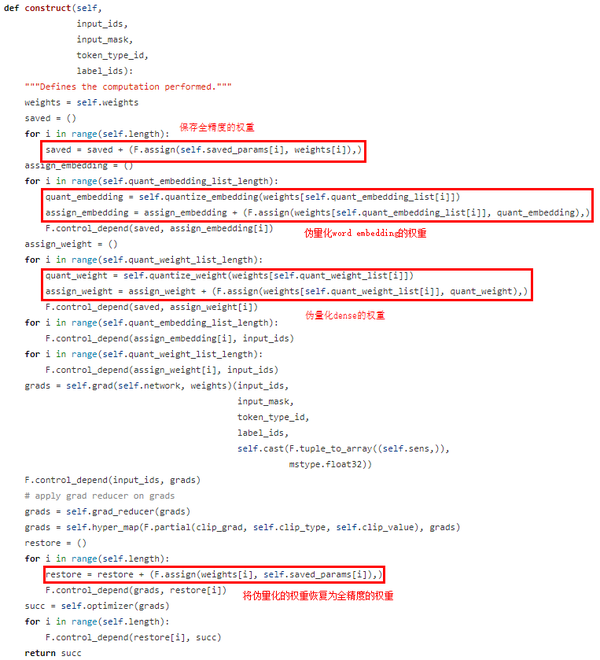
图8:权重伪量化操作
最后,MindSpore的model\_zoo中存放有TernaryBERT针对MNLI-m、QNLI和STS-B对应的训练脚本。模型均可达到论文中所述精度。

表3:在MNLI-m、QNLI和STS-B上,通过MindSpore实现的TernaryBERT的精度。
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

