
转载于:知乎
作者: 金雪锋
今天带来的是MLSys 2021的一篇论文《A Learned Performance Model for Tensor Processing Units》[1],作者为google brain的Sam Kaufman等人。论文提出了一个基于GNN模型的cost model设计,用来预测张量计算程序在TPU上的执行时间。其实相关工作最早发表于NeurIPS 2019 的ML for Systems workshop[2],简要介绍了该模型的主要架构及流程。在MLSys 2021的这篇文章中,作者对其cost model进一步完善,并且补充了大量的对比实验。
背景:
由于硬件的稀缺性、运行时长等原因,编译器在解决性能优化问题时通常依赖于性能模型(Cost model),如LLVM通过cost model计算最优向量化和unroll的因子[3]。此外,cost model还常用来为编译器tuning工具评估搜索空间的候选配置参数,用以提升tuning的效率。在AI编译领域,cost model问题显得尤为突出,各类异构深度学习加速器(TPU、NPU等)的出现使得通用cost model的设计变得棘手,同时增加了额外的负担。
论文调研并总结了现有深度学习领域cost model存在的问题。作者认为传统的analytical model(如xla中用于提供切分参数使用的性能模型 [4])代价较大,通常需要数月的工程量,而现有的基于学习的建模方法,也存在各自的局限性。如Ithemal [5]没办法处理复杂的多层嵌套循环场景,Halide[6] 的需要繁重的特征工程设计,AutoTVM[7] 对于不同kernel的泛化能力有限等。综上,论文提出了一种基于GNN的Cost model,用来预测张量计算在TPU上的执行时间。该方法可同时满足以下需求:
1)通用性,可处理一些复杂的张量计算。
2)不同领域的泛化能力。
3)不依赖于需要人工开发的繁重的特征工程。
4) 可移植性,能够轻松的在不同优化目标上复用。
Cost model设计:
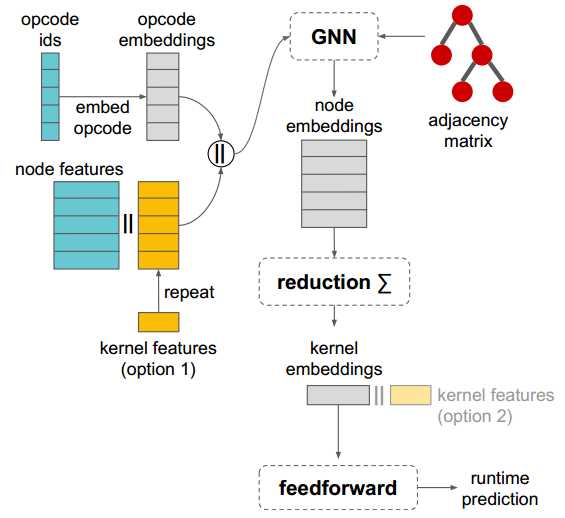
如上图所示,论文采用了GNN模型的架构:
模型的输入包括节点特征(蓝色部分),kernel特征(黄色部分)以及图结构特征(红色邻接矩阵)。节点特征包括opcode(操作类型)及进一步描述节点的标量特征,如output tensor的shape,layout,striding,padding等;kernel特征包括切分大小及可选的静态性能信息(如浮点操作的个数,数据读/写字节数等);邻接矩阵主要表示kernel中节点的数据流依赖关系。
论文首先将opcode映射为opcode embedding向量,随后将其同其他节点特征、kernel特征进行拼接,连同邻接矩阵传入GNN,并使用GNN构造各节点。作者在论文中指出,选择GNN模型主要基于2点考虑:1)张量计算的kernel常表示为DAG,2)作者认为在各节点特征中加入相邻节点特征可有效提高不同配置下的泛化性。在实现上,作者选择了GraphSAGE模型[8],通过训练聚合节点邻居的函数,使GCN扩展成归纳学习任务,对未知节点起到泛化作用。
通过将节点聚合可进一步构造kernel embedding。论文里列出了3中聚合函数:
- column-wise聚合。对邻居embedding中每个维度取平均,最大化,相加规约等。
- LSTM。将拓扑排序后的邻居节点embedding序列 作为LSTM输入。
- Transformer encoder。对节点 embedding做transformer encoder。
最后,将得到的kernel embedding 通过feedforward层线性转换为标量输出即可。
该性能模型主要用于两类优化任务,切分参数选择与算子融合评估。对于切分参数选择,主要关注相同kernel不同切分大小下的相对速度,因此模型损失函数可定义为:
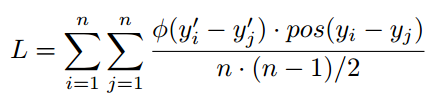
n为每个batch下样品数;pos(z)为一个分段函数,当z大于0是pos(z)为1,否则为0;φ(z) 要么为损失函数 (1 - z)+ ,要么为对数函数log(1 + e-z)。
对于算子融合任务,需要去计算kernel的绝对运行时间,因此将模型损失函数定义为(yi0 - yi)2的对数变换。
实验评估:
论文实验中的数据来自于实际使用的104个xla程序,并通过随机或人工分裂的方法,构造了超过2000万个kernels作为训练数据集。实验环境为单机NVidia V100 GPU。实验数据如下图所示。
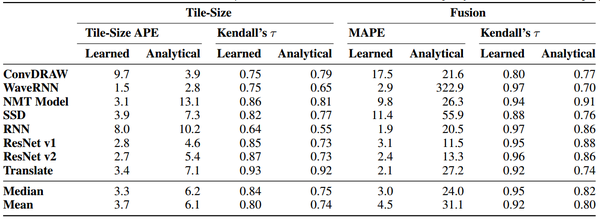
对于切分参数任务,baseline为XLA现有的分析模型,分别用Tile-Size APE(可看作同当前最快切分的距离)及肯德尔等级相关系数作为评价指标。从表中可以看出,除了ConvDRAW,论文提出的cost model均能够优于现有分析模型。此外,对于不同的硬件,如TPU V2、V3,该cost model均有不错的表现。
对于算子融合任务,在所有的benchmark中,cost model(平均4.5 MAPE)都要明显优于analytical model(平均31.1 MAPE)。这可能是因为XLA中并没有对算子融合任务提供准确的性能模型,只是从是否节约内存空间和访问时间上评估是否可融。
此外,这篇论文还做了大量的MODEL ABLATION STUDIES , 对不同节点特征、kernel特征,以及不同的神经网络模型都做了充分的实验分析。作者认为,从张量计算程序的泛化效果来看,使用GraphSAGE比用LSTM或者Transformer更准确,具体实验过程可查阅论文。
众所周知,由于TPU价格昂贵,且使用需求频繁,所以希望能够尽量减少TPU上tuning的时间。基于这一需求,论文最后将该cost model集成至XLA的compiler和autotuner中,评估不同tuning场景下的整网性能。
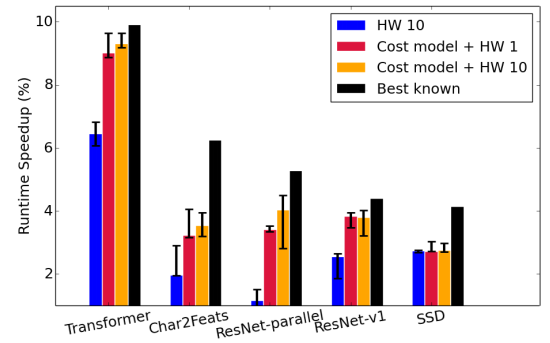
上图为Fusion Autotuner的实验对比,Baseline为Autotuner在硬件上Tuning10分钟所得到的最佳融合配置。集成cost model后的autotuner工具则首先在CPU上运行1个小时,然后再在TPU上tuning1-10分钟。从上图结果可以看出,使用costmodel之后,同仅在硬件上tuning相比平均能有1.5%的性能提升。同时,相比最佳融合配置性能差也不超过1.5%,而这些最佳配置是在TPU上运行4小时以上才得到的。 此外,通过使用cost model,可以有效减少在TPU上的tuning时间。上图中tuning时长从10分钟降到1分钟,性能基本上没有裂化。
参考文献:
[1] Sam Kaufman, Phitchaya Phothilimthana, Yanqi Zhou, Charith Mendis, Sudip Roy, Amit Sabne, Mike Burrows. A Learned Performance Model for Tensor Processing Units. Proceedings of Machine Learning and Systems 3 pre-proceedings (MLSys 2021)
[2] Kaufman Samuel, Phothilimthana, Phitchaya Mangpo and Burrows, Mike. Learned TPU cost model for XLA tensor programs. Proceedings of the Workshop on ML for Systems at NeurIPS 2019
[3] LLVM. Auto-Vectorization in LLVM. https://bcainllvm.readthedocs.io/projects/llvm/en/latest/Vectorizers. [Online; accessed 03-Feb-2020].
[4] TensorFlow. XLA: Optimizing Compiler for TensorFlow. https://www.tensorflow.org/xla. [Online; accessed 19 - September-2019].
[5] Mendis, C., Renda, A., Amarasinghe, S. P., and Carbin, M. Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation using Deep Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML, 2019a.
[6] Adams, A., Ma, K., Anderson, L., Baghdadi, R., Li, T. M., Gharbi, M., Steiner, B., Johnson, S., Fatahalian, K., Durand, F., and Ragan-Kelley, J. Learning to Optimize Halide with Tree Search and Random Programs. ACM Trans. Graph., 38(4):121:1–121:12, July 2019. ISSN 0730-0301. doi: 10.1145/3306346.3322967. URL http: //http://doi.acm.org/10.1145/3306346.3322967.
[7] Chen, T., Zheng, L., Yan, E., Jiang, Z., Moreau, T., Ceze, L., Guestrin, C., and Krishnamurthy, A. Learning to Optimize Tensor Programs. In Proceedings of the 32Nd International Conference on Neural Information Processing Systems, NIPS’18, 2018.
[8] Hamilton, W. L., Ying, Z., and Leskovec, J. Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems, 2017
推荐阅读
- 【从零开始学TVM】三,基于ONNX模型结构了解TVM的前端
- 动态路由条件计算-万亿级参数超大模型关键技术与MindSpore支持(1)
- Transformer系列 | 更深、更强、更轻巧的Transformer,DeLighT
更多嵌入式AI技术干货请关注嵌入式AI专栏。

