
转载于:知乎
作者: 金雪锋
近日,Hinton在arXiv上挂了一篇44页的长文——只有idea,没有实验。在这篇名为《How to represent part-whole hierarchies in a neural network》中,Hinton基于17年的胶囊网络(capsule network)提出一个想象的系统GLOM。GLOM通过固定结构的神经网络将不同的图像解析为局部-整体的层次结构。
·想法来源
借鉴心理学的研究成果,Hinton认为,人类在识别图像的时候是将图像分为局部-整体的层次结构并对其中的空间关系进行建模。因此,他一直致力于研究如何通过神经网络呈现出局部-整体的层次关系。在先前的胶囊网络中,模型会将一组特定的功能的神经元称为“胶囊”用以处理特定区域中特定类型的图像输入。网络通过动态路由的机制选取部分激活的胶囊处理特定的输入,从而解决CNN面临的无法识别局部-整体的关系以及不同视角理解物体的问题。
但是胶囊网络发展多年,仅在一些较小的数据集上取得一些成功。主要有几个原因:
- 因为需要特定的“胶囊”处理不同的输入,在大规模数据集上需要大量不同的“胶囊”结构
- “胶囊”并没有类似于随机梯度下降(SGD)和transformers结构的实际“激励”信号
- 由于混合不同“胶囊”来建模,无法分辨两部分输入是否真正不同。比如车灯和眼睛,使用相同的胶囊建模,无法预测出它们整体的性质(车和人);如果使用不同的胶囊建模,它们之于整体关系的相似性又无法挖掘
针对于上述,需要一种统一的通用胶囊,包含足够多的“知识”用以建模不同类型的输入。Hinton认为,相比较于需要考虑路由到哪个物体层级“胶囊”,一个更彻底的方法就是将这些通用的“胶囊”预分配于图像的每一个位置,并且每个位置上的“胶囊”还可以是不同层级的。比如这个位置属于某个场景,某个物体,某个部分,某个子部分等。这就是GLOM。
·GLOM结构
GLOM是由大量的column组成,每个column是局部空间的自编码器用以学习不同层级(level)的小块图像表示。单个column分为多个层级,每个层级对应于局部-整体层次结构。在不同层级之间网络的参数可以不同,但在不同的column和时间t下参数是共享的。如图1所示,不同层级之间包含了bottom-up编码器(蓝线)和top-down解码器(红线)。按照Hinton的想法,每一个离散时间t,每一个column中层级L的embedding更新来自四部分:
- 时间t-1时层级L-1的embedding通过bottom-up网络的预测。
- 时间t-1时层级L+1的embedding通过top-down网络的预测。
- 时间t-1层级L的embedding向量(绿线)。
- 时间t-1层级L近邻column的embedding的基于注意力的加权求和(图中未表示)。
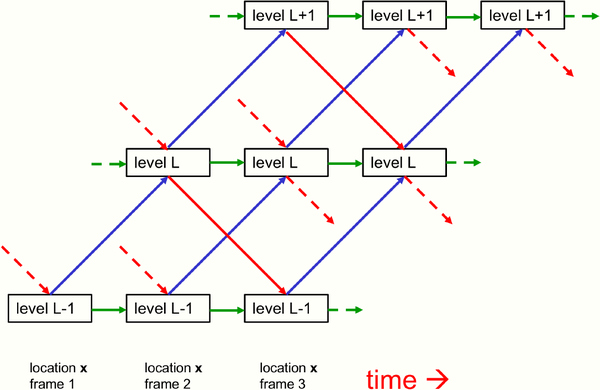
图1 GLOM single column结构图
对于一张静态的图片,如图2所示,某一层级的相近的embedding向量形成“孤岛”,各个层级的“孤岛”形成一颗“解析树”,这些“孤岛”在更高的层级上会变得更大。Hinton认为这些特征孤岛相比于短语结构语法要强大得多,它们可以轻易地表示不相连的物体。
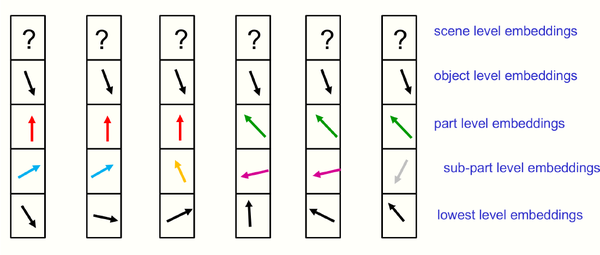
图2 某个时间步,相近的column的embedding表示
·设计的讨论
Hinton提出一些关于结构设计的讨论
·level
Hinton认为,GLOM的level层数应该是5层。同时针对不同层级间bottom-up和top-down网络参数是否应该如同不同locations之间一样共享的问题,他给出的答案是否。在NLP工作中,处于不同level中的短语和词汇本身拥有很多不同的性质,图像的分形会更加严重。
·location
位置的划分可以是像素粒度或者更大的patch。Hinton认为使用不同分辨率的图片作为输入是最简便的训练模型对于不同粒度敏感能力的方法。
·attention
GLOM利用一种最简单的attention形式:
和表示L层级上x和y位置的向量,“.”表示标量乘积,z代表了所有的位置,表示“逆温度”用来控制注意力的“锋利度”。Hinton提出马尔科夫随机场等工作可以用来使得x无法关注于某些位置y,从而可以保证同一“孤岛”的向量更加接近,不同“孤岛”的向量尽量远离。
·input
利用CNN处理原始图像的输出作为GLOM结构中最低level的向量初始化。并且借鉴于神经场的思想,GLOM的输入应该包含图像以及位置的表示。对于位置的表示不应该是简单的x和y坐标系的标量输入,而是将位置转化为更高维度的表示。Hinton认为,不应当在每一层级设计独立的一部分embedding向量专门用于pose的表示,而是和该层级物体的其他特性融合在一起。他坚信,GLOM这种通用“胶囊”来处理不同视角的不同类型物体,拥有足够的“能力”泛化到不同视角。而不是需要显式的pose表示,通过线性变化来建模不同视角的影响。
·learning
GLOM的训练过程可以类似BERT一样的mask策略用来还原图像中移除的区域。但是通过简单地鼓励相近区域的embedding表示更加相似,可能会导致“表征坍塌”:所有的embedding向量变得很小所以互相相似,从而需要很大的权重来重构。
因此,对比学习十分必要,即引入正负样本的概念来使得同一“孤岛”向量相似,不同“孤岛”向量尽量远离从而不被注意力计算中关注。Hinton认为可以采用上一时刻的bottom-up和top-down网络的预测值作为一种“伪标签”,从而给予注意力计算中应该关注哪些embedding一些“参考”,并且结合BN和LN以及一些tricks可能可以消除对于负样本的依赖。
·比较
1、胶囊网络
- 不需要预先分配特定的神经元处理图像的每个部分,GLOM利用连续空间特征来表示图像的每个部分,能够实现相似图像部分更多的“知识共享”同时更灵活地处理不同数量和类型的图像部分。
- 不需要动态路由。
- GLOM这种“孤岛”的聚类形成过程优于胶囊网络的聚类过程。GLOM在连续向量空间的聚类过程不需要离散簇数量的更改,即不需要认为设置一些聚类的参数。
2、Transformer结构
如图3和图4所示,相比于transformer结构,GLOM结构中的时间步t对应于transformers中的每一层的,但是GLOM的每个时间步t的权重是相同的。Transformer中的多头机制在GLOM中重新设计为用于实现局部-整体层次结构的多个层级,并且多层级之间通过Bottom-up和Top-down网络进行交互。同时注意力机制被简化为使用每个位置的embedding向量作为Q,K,V值。
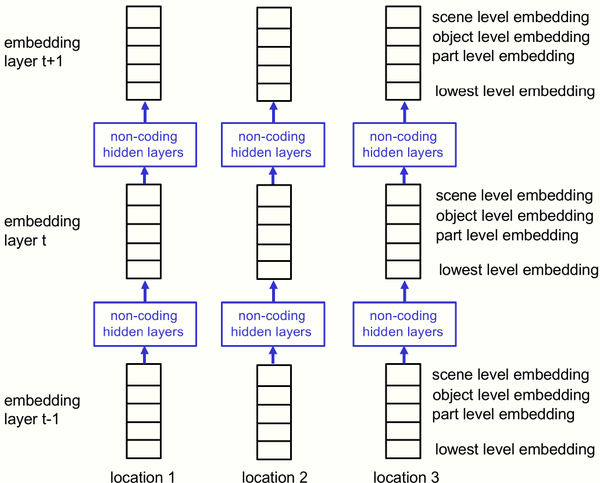
图3 GLOM结构图
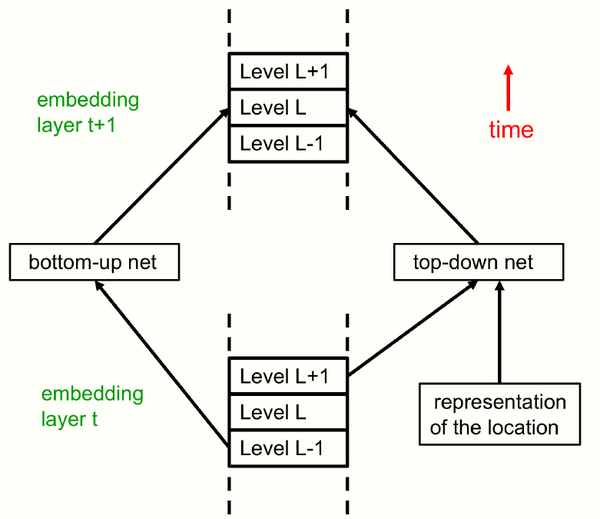
图4 不同时间的交互
3、CNN
- 只使用1x1的卷积(除了最初输入)。
- 不同位置的交互用的是通过无参数的平均实现而不是匹配过滤。
- 在不同层级之间top-down自上而下的交互。
- 不同于CNN的单独任务,GLOM使用对比的自监督学习并且实现层次上的分割。
Hinton综合Transformer、神经场、对比学习等近年来AI领域的诸多成果以及心理学、生理学、物理学等相关研究提出GLOM结构并且通过不同视角具体化。虽然全篇仅有系统设计的一些想法并没有实验及可运行的系统,但是其中诸多思想还是可以借鉴从而应用于其他AI领域研究中。
推荐阅读
- MLSys 2021论文分析1—《A Learned Performance Model》
- 【从零开始学TVM】三,基于ONNX模型结构了解TVM的前端
- 动态路由条件计算-万亿级参数超大模型关键技术与MindSpore支持(1)
更多嵌入式AI技术干货请关注嵌入式AI专栏。

