
NanoPU
原版见arXiv.org e-Print archive。
2020年预印本公开了一篇“The nanoPU: Redesigning the CPU-Network Interface to Minimize RPC Tail Latency”,提出并设计实现了一种融合CPU的新型网卡架构NanoPU。
随着越来越多的应用程序使用微服务架构部署,云服务提供商CSP正试图降低RPC尾部延迟。分布式应用程序通过将计算划分为同时执行的细粒度任务,获得了在云数据中心的商用服务器上运行的高性能(例如,视频编码、视频压缩和人脸识别)。这些应用程序通常将远程过程调用(RPC)请求从根节点扇出到大量叶节点,并在多个层中扇出。通常情况下,服务级别性能受到单个叶的RPC尾部延迟的限制。因此,如果能够减少(甚至限定)RPC尾部延迟,分布式应用程序将运行得更快。
CSP正试图通过引入专门的NIC硬件来解决这个问题,比如,NIC具有快速的RDMA和运行低延迟微服务的驻留在NIC内的CPU核。一般,微服务的调用需要5-10毫秒,因此只有当发送它的计算时间超过10毫秒时才值得调用。NanoPU的目标是实现高效的亚微秒级RPC,它可以在服务器上以不到1ms的通信开销调用。一个关键指标是线-线延迟,定义为从RPC请求消息的第一比特到达NIC,直到处理的RPC响应的第一比特离开NIC的时间。典型的中位数线线延迟约为850ns。NanoPU目标是将中位数和尾数都减少到100ns以下,使运行“nanoService”变得有价值;短的RPC需要不到1ms的工作时间。
RPC尾延迟高的原因
a、 关键路径上的内存和缓存层次结构
CPU的网络堆栈使用内存作为工作空间来保存和处理数据包。这必然会干扰应用程序的内存访问,引发资源争用,从而导致较差的RPC尾部延迟。此外,如果一个数据包通过PCIe传输到DRAM,它在到达几百纳秒后才对CPU可用。使用直接缓存访问技术(如DDIO和DCA),这一点得到了减少,但数据包仍必须经过网络堆栈的许多层,并且上下文切换需要额外的延迟(1–5ms),包括内存拷贝、TLB刷新、虚拟内存管理和缓存替换。
b、 次优调度
当RPC数据包到达时,它必须被分派到核心进行网络堆栈处理;当完成时,RPC请求消息被转发到工作核心进行处理。在每个步骤中,软件核心选择算法选择核心;线程调度器决定处理何时开始。这两种算法都需要内核和NIC频繁访问内存,需要内存总线、PCIe和缓存的介入。已经证明,这些算法位于关键的处理路径上,并试图降低处理时间。然而,这些软件调度器的粒度本质上受到执行核心间同步(例如发送和接收中断)所需开销的限制。因此,每5ms进行一次以上的调度决策变得不切实际。
以前许多减少RPC开销的尝试包括低延迟和无损交换机,减少了网络层的数量,以及专门的库。目前最快的方法是部署专用NIC和交换机硬件,但这些都很难编程。能否设计一个易于编程的CPU内核,同时能够以绝对最小的开销和尾部延迟服务RPC请求?
虽然NanoPU不是第一个尝试减少这些处理的延迟,但描述了第一个将RPC尾部延迟最小化的完整设计。nanoPU的目标是通过使用流水线、可编程硬件,将数据直接放置到CPU内核中,完全绕过内存和缓存层次结构,最大限度地减少在每一层上花费的时间。
nanoPU可以看作是一个在线处理模型,除了常规处理,为未来的CPU核心优化亚微秒RPC服务。或者,nanoPU可以被认为是一种新的特定于领域的“nanoService”处理器,设计用于安装在smartNIC上,或者作为一个独立的集群来服务亚微秒级的RPC。例如,构建一个单芯片512核nanoPU是可行的,类似于Celerity,有100GE接口,以持续10Tb/s的速度每秒服务超过5亿个RPC。这样的设备可以从根本上提高大型分布式应用程序的性能。 nanoPU是一种NIC和CPU联合设计,最大限度地减少RPC尾部延迟。主要包括:1)NIC中的专用内存层次结构,直接连接到CPU寄存器文件;2)低延迟硬件传输逻辑、核心选择和线程调度;3)通过限制消息处理时间来限制尾部延迟。
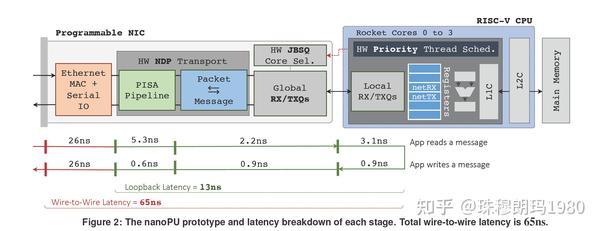
在NanoPU中,第一,需要最小化从RPC请求包通过以太网到达到它在运行线程中开始处理的时间。nanoPU通过用硬件替换软件线程调度器和核心选择器(又称负载均衡器);完全绕过PCIe、主内存和缓存层次结构;将RPC数据直接放入CPU寄存器文件;用硬件中的可靠传输层替换主机网络软件堆栈来实现这一点,向CPU传递完整的RPC消息。第二,需要尽量减少网络拥塞。nanoPU在硬件上实现了NDP(使用可编程P4流水线),减少了拥塞并提高了incast性能。第三,需要在硬件上通过流水线头和传输层处理、线程调度和核心选择来最大化RPC吞吐量。nanoPU在NIC中包含P4 PISA流水线,并行处理多个数据包,并重新组装RPC消息。最后,大型分布式应用程序的性能通常受到RPC尾部延迟的限制;因此,在处理RPC时,需要最小化尾部延迟。nanoPU提供了第一个确定性尾延迟RPC服务,保证了一致的RPC请求将在到达NIC的1ms内完成服务。
利用200Gb/s网络接口及扩展RISC-V Rocket核心的nanoPU开源原型,在AWS F1 FPGA实例上通过可重复的周期精确模拟进行评估。测试得到:1)线-线延迟仅为65ns(没有以太网MAC和串行I/0的情况下为13ns),2)每个核心的吞吐量为200Gb/s,比最新技术快2.5倍,3)NIC中的处理速度为350 Mpkts/s(包括传输和核心选择逻辑),比Shinjuku , Shenango和eRPC软件解决方案快50倍,4)硬件抢占式线程调度,在高负载下使99%的尾部延迟低于2:1ms。
作者:珠穆朗玛2048
来源:https://zhuanlan.zhihu.com/p/359303460
更多FPGA智能网卡相关技术干货请关注FPGA加速器技术专栏。

