
Lynx
原版见ASPLOS 2020。
这个专题主要对基于FPGA的智能网卡技术进行介绍,上篇介绍了NanoPU、PANIC、Tonic、Corundum、NICA、AccelNet、FairNIC等,这次介绍“Lynx: A SmartNIC-driven Accelerator-centric Architecture for Network Servers”,提出加速器为中心的网络服务器架构,主要向SmartNIC卸载数据和控制平面功能。高山留存阅读点滴。
引入
数据中心往往采用异构计算,部署了多种计算加速器以满足不断增长的性能需求。许多云供应商利用它们来构建硬件加速的网络连接计算服务。例如,Amazon在GPU上提供弹性推理,Microsoft Azure公开FPGA加速的ML服务,Google在TPU上运行AutoML服务。在这样的系统中,加速器运行应用程序逻辑的主要部分。
同时,不断增长的网络速率推动了可编程智能网络适配器的采用,以减轻数据中心联网的工作负载。微软是最早大规模部署SmartNIC的公司之一,在超过一百万台Azure服务器中,每台服务器都安装了基于FPGA的Catapult SNIC。如今,云供应商对SNIC的采用正在上升:部署在中国移动、腾讯、华为等。
到目前为止,SNIC主要用于加速低级数据包处理应用,如网络功能和软件定义的网络。然而,SNIC也为提高硬件加速的网络连接计算服务的效率和性能创造了新的机会。
Lynx以加速器为中心的架构
Lynx是以加速器为中心的网络服务器体系结构,在SNIC上执行大部分通用服务器数据和控制平面。启用加速器之间的网络I/O,而无需使用主机CPU进行网络处理,也无需在加速器上运行网络堆栈。
在传统的硬件加速服务器设计中,CPU执行两个主要任务:1)运行基本处理,如网络堆栈中的数据包处理,并与网络客户机交互;2)向计算加速器发送请求,处理相关的数据传输,加速器调用和同步。相反,Lynx将这两个任务卸载到SNIC,允许加速器上的应用程序代码直接与网络交互,绕过主机CPU。
与传统的以CPU为中心的设计相比,Lynx体系结构提供了几个好处:
1)加速器的轻量级网络
Lynx使加速器能够在加速器执行的任何时候通过网络与其他机器通信。虽然一些工作已经证明了GPU端网络API的优点,但它们运行资源密集的GPU端网络堆栈,只有支持远程直接内存访问(RDMA)作为主要协议,并且只适用于GPU。相反,Lynx在加速器上运行轻量级API层,本机支持TCP/UDP,并且可以跨不同类型的加速器部署。
2)CPU高效率
主机CPU从网络处理和加速器管理任务中解放出来。因此,主机可以运行其他任务,这些任务可以更好地利用延迟优化的CPU体系结构。同时,专门的SNIC内核对于一般用途的计算效率较低,足以驱动硬件加速的网络服务,而性能成本可以忽略不计。例如,由SNIC管理的GPU加速神经网络推理服务仅比其CPU驱动版本慢0.02%,而Memcached key-value store更好地利用额外的主机CPU核,与额外的CPU核成线性扩展。
3)性能隔离
Lynx在SNIC驱动的硬件加速服务和在同一台机器上并发运行的其他应用程序(例如,来自其他云租户)之间实现了强大的性能隔离。例如,与硬件加速网络服务器共同执行的内存密集型干扰的多租户应用程序会导致服务器响应延迟的高度变化,在对延迟敏感的软实时工作负载中是不可接受的,例如在自动驾驶的图像处理中。
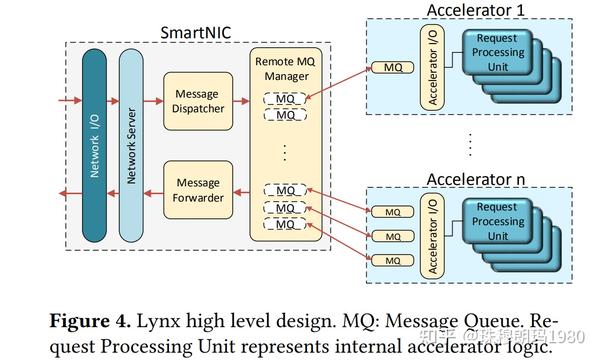
为了实现这些优势,Lynx的设计基于两个关键理念:
1)将网络服务器逻辑卸载到SNIC
SNIC运行一个完整的网络堆栈和一个通用的网络服务器,该服务器监听应用程序指定的端口,并向加速器传递应用程序消息。SNIC不需要应用程序开发。
服务器通过消息队列(MQUE)将接收到的消息分发给相应的加速器,响应并将它们发送回客户端。加速器在MQueue之上运行一个轻量级I/O层,提供零拷贝网络。MQUE是一种类似于RDMA队列对的用户级抽象,但经过优化以降低从加速器访问它的复杂性。
2)使用SNIC RDMA实现可移植性和可扩展性
加速器将MQUE数据和控制缓冲区存储在自己的内存中,而SNIC则远程访问MQUE,并代表加速器执行I/O操作。对于远程访问,SNIC使用其内部硬件加速RDMA引擎通过单向RDMA高效地读/写MQues。注意,RDMA只在SNIC和加速器之间使用,对于通过UDP/TCP连接到加速服务的外部客户端是透明的。
这种设计选择确保了Lynx的可移植性和可扩展性:它允许SNIC支持多种加速器,而不需要SNIC运行加速器驱动程序。此外,RDMA的使用使其能够扩展到单个机器之外,使Lynx能够无缝地通过网络向远程加速器提供I/O服务。
Lynx的一个关键目标是促进网络服务器的实现,这些服务器遵循以加速器为中心的设计,最大限度地减少主机CPU的占用。这对于低延迟加速的服务器是有利的,这些服务器可以完全在加速器上运行,但不太适合必须使用CPU的混合应用程序。然而,新兴的优化框架通常会在加速的应用程序中忽略主机CPU的参与,使其成为Lynx的理想候选。
在一个具有多个本地和远程NVIDIA GPU以及一个Intel Visual Compute Accelerator(VCA)的系统上设计了Lynx原型,该系统配置了三个Intel E3处理器,支持软件保护扩展(SGX)可信执行。此外,在基于ARM的Mellanox Bluefield SNIC上实现了Lynx,并用Xilinx FPGA在Mellanox Innova SNIC上实现了原型。
用微基准和实际应用来评估系统性能和可扩展性。例如,开发了一个LeNet模型,为数字识别服务,完全在GPU上实现。Bluefield上的Lynx以300微秒的延迟实现3.5 K请求/秒,这比优化的以主机为中心的服务器的吞吐量高25%,延迟低14%,但不使用主机CPU。为了演示可伸缩性,运行了一个LeNet服务器,其中12个GPU分布在三台物理机器上。Lynx实现了线性扩展,并预计将分别扩展到100和15个GPU用于UDP和TCP网络服务,从而节省了网络处理和GPU管理所需的CPU核心。
小结
Lynx将以前工作中以加速器为中心的服务器设计概念推广到GPU之外,使之适用于其他加速器。为了实现可移植性和效率,它利用了SNIC硬件体系结构的最新进展。虽然目前的设计主要集中在运行在单个加速器上的服务器上,但Lynx将成为针对多加速器系统的通用基础设施的基础,该基础设施将在单个应用程序中实现加速器和CPU的高效组合。
FPGA智能网卡专题回顾:
FPGA智能网卡介绍(5):NICA
FPGA智能网卡介绍(4):Corundum
FPGA智能网卡介绍(3):Tonic
FPGA智能网卡介绍(2):Panic
FPGA智能网卡介绍(1):NanoPU
作者:珠穆朗玛2048
来源:https://zhuanlan.zhihu.com/p/362401418更多FPGA智能网卡相关技术干货请关注FPGA加速器技术专栏。

