
先前对智能网卡技术进行介绍,前期介绍了NanoPU、PANIC、Tonic、Corundum、NICA、AccelNet、FairNIC、Lynx、iPIPE、L5P等,这次介绍“Dagger: Efficient and Fast RPCs in Cloud Microservices with Near-Memory Reconfigurable NICs”,原版见ASPLOS2021,提出基于FPGA网卡的RPC加速方法。高山留存阅读点滴。
现代云应用程序越来越多地转向Microservice编程模型,以提高其灵活性、弹性和模块性。微服务将复杂的单片应用程序(将整个功能实现为单个服务)分解为许多细粒度和松散耦合的层。这改进了设计模块化、错误隔离,并促进了开发和部署。然而,由于Microservice通过网络相互通信,它们也带来了巨大的通信开销。考虑到单个Microservice通常涉及少量计算,网络最终只占其总延迟的很大一部分。此外,由于Microservice相互依赖,网络拥塞导致的性能不可预测性可能会在依赖层之间传播,并降低端到端性能。
RPC延迟问题
Microservice通常通过远程过程调用(RPC)相互通信。然而,现有的RPC框架并不是专门为Microservice设计的,Microservice的网络需求和流量特性不同于传统的云应用程序,因此会给它们的性能带来很大的开销。Microservice严格的延迟要求、细粒度的请求、广泛的多样性和频繁的设计节奏给网络系统带来了很大的压力,这使得重新考虑使用微服务进行联网成为迫切的需要。大多数现有的商业RPC框架都是在商用操作系统网络(如Linux-TCP/IP)之上实现的。虽然这确保了通用性,但这类系统在系统堆栈的所有级别上都有相当大的开销。这些开销在深度Microservice调用路径上累积,并导致端到端QoS冲突。虽然这会影响所有的Microservice,但对于交互层来说尤其具有挑战性,因为交互层优化的是较低的尾部延迟,而不是平均吞吐量。
在过去的十年里,学术界和工业界对低延迟和高吞吐量的网络系统的兴趣越来越大。一种工作重点是优化传输协议,而另一种工作则将网络转移到用户空间,或者将其转移到专用适配器。通过使用SmartNIC来调整网络配置以满足目标应用程序的性能要求,网络可编程性也得到了发展。尽管这些方法在性能和效率上都有好处,但是它们在主机CPU和NIC之间使用的接口类型上是有限的。处理器将几乎所有商用NIC视为PCIe连接的外围设备。不幸的是,PCIe互连需要多个总线事务、内存同步以及对NIC的每个请求的昂贵MMIO请求。因此,在这些优化的系统中,每个数据包的开销仍然很高;这对于具有深度调用路径的细粒度工作负载(如微服务)尤其明显。
Dagger架构
一种基于FPGA的可重构RPC堆栈,通过NUMA互连集成到处理器的存储子系统中。集成和近内存NIC已经在减少PCIe开销和提高网络效率方面显示出了前景。以前的集成网卡都是基于缺乏可重构性的ASIC,并且需要定制芯片,这对于频繁改变数据中心规模的网络配置来说是昂贵和耗时的。广泛用于Microservice的RPC堆栈,如Thrift RPC、gRPC,提供了丰富的传输选项、反序列化方法和线程模型。基于硬件的RPC堆栈只有在Microservice环境中才是实用的,如果它们允许相同的灵活性的话。为此,提出了一种集成的可重构FPGA加速网络结构,能够支持真实的端到端RPC框架。
Dagger基于三个关键的设计原则:1)NIC在硬件上实现了整个RPC栈,而软件只负责提供RPC API。通过这种方式,从RPC流的关键路径中移除了与CPU相关的开销,并为Microservice高并发性释放了更多CPU资源。2) Dagger利用内存互连与处理器通信。表明,与最初为生产者-消费者数据流模式设计的PCIe协议相比,内存互连提供了更好的通信模型,特别有利于传输随时可用的RPC对象。通过内存互连集成NIC比以前提出的将NIC与CPU紧密耦合的方法更为实用,因为现在的处理器都带有公开的内存总线,而下一代服务器级CPU已经提供了专用的外围内存互连。3) 最后,Dagger是基于FPGA的,因此它的设计是完全可编程的。这使得它能够根据给定微服务的性能和资源需求进行调整。
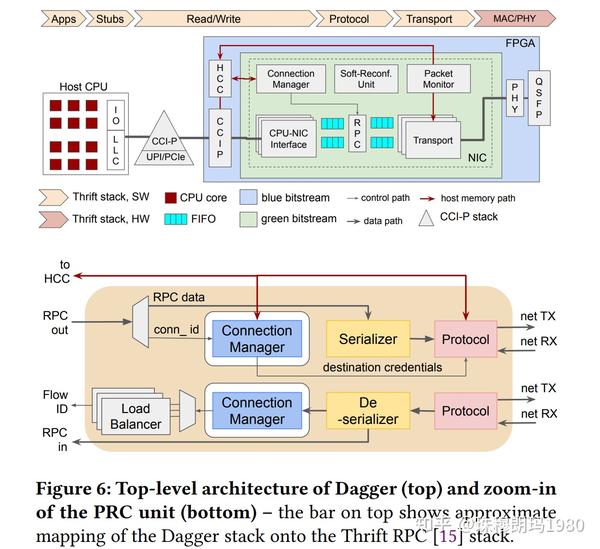
在Intel Broadwell CPU/FPGA混合架构上构建Dagger,类似于公共云中的架构,如Intel HARP。将整个RPC堆栈卸载到硬件可以实现更好的CPU效率,从而提高每个核心的RPC吞吐量和更低的请求延迟。此外,通过内存互连将硬件RPC堆栈与应用程序紧密耦合的好处。基于优化的软件RPC框架和专用硬件适配器,Dagger将单核RPC吞吐量提高了1.3-3.8倍。Dagger的单核吞吐量达到12.4-16.5 Mrps,它可以扩展到42 Mrps,两个CPU核上只有4个物理线程,同时实现了最先进的 s级端到端延迟。
Dagger可以很容易地集成到现有的数据中心应用程序中,只需对代码库做一些小的修改。在memcached和MICA-KVS上使用Dagger作为通信层的实验表明,memcached和MICA的中位和第99百分位尾部延迟分别为3.2和7.8 us,MICA的中位和第99百分位尾部延迟分别为3.5和5.7 us,同时在单核上也实现了5.2 Mrps的吞吐量。这个结果比基于Linux内核网络的本机传输上memcached的延迟低11.4倍,比高度优化的基于DPDK的用户空间网络堆栈上MICA的延迟低4.4-5.2倍。
小结
通过在Dagger之上移植一个8层的航班登记服务,证明了Dagger能够适应具有不同需求和线程模型的多层微服务应用,并且显示出与本机执行相比显著的性能优势。
作者:珠穆朗玛2048
来源:https://zhuanlan.zhihu.com/p/364255828更多FPGA智能网卡相关技术干货请关注FPGA加速器技术专栏。

