
转载于:知乎
作者: 金雪锋
摘要:
今天小伙伴们带来的是MLSys 2021的一篇论文《A Deep Learning Based Cost Model for Automatic Code Optimization》[1]分析。该论文基于现在的研究热点“Automatic Code Optimization”,创新性的提出了一个基于deep learning的回归模型,该模型可以针对一个完整的程序,预测对这个程序进行一系列优化(code transformations)后能够获得的性能加速比。值得一提的是该模型不需要特别复杂的特征工程,就能达到比较不错的精度:mean absolution percentage error(MAPE)仅有16%。目前作者将这个模型作为自动代码优化的搜索过程中的评估模型(cost model),集成到TIRAMISU编译器[2]中,帮助TIRAMISU编译器在x86架构上自动进行代码变换来提升性能。
Automatic Code Optimization
这个地方简单介绍一下算子优化问题,他可以表示为求解公式1:
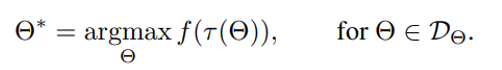
Eq. 1
其中Θ表示当前的采样candidate,代表了对当前的代码进行的一些优化手段,τ是特定硬件平台的代码生成函数,因此τ(Θ)代表了能在特定硬件平台运行的代码,f函数代表fitness,即对代码进行评估,通常指代码的运行时间,DΘ代表了design space,包含了candidate的全空间,Θ∗代表找到的最优candidate。因此自动算子优化问题可以描述为“在design space里找到一个candidate,使得生成的代码在特定的硬件平台上的运行结果最优”。那么自动算子优化就是自动搜索最佳candidate的这样一个过程,我们通常把这样的自动搜索工具称为auto tuner。本文提出的cost model,就是公式1中的f函数。
其实MLSys中还有类似的论文,例如Google brain的Sam Kaufman等人提出的一个基于GNN模型的cost model [12](前面已经介绍过了),同样地,他们的初衷也是想要去掉复杂易出错的特征工程,使用更为鲁棒和易扩展的深度学习来构建cost model,预测代码的性能。它跟本文的异同点,以及会进行详细介绍的章节如下表:
[1]
[12]
章节
集成框架
TIRAMISU
XLA
2
目标架构
CPU
TPU
-
cost model输入
AST tree(原始程序表示)+ 优化手段序列(candidate)
Graph(应用了不同优化手段的程序表示)
4.1
提取的特征
Loop Nest
Assignmentloop transformation representation
Num of floating point operations
Amount of data read in bytesAmount of data being written in bytesNum of instructions executing on a special functional unitTile-size
4.1
目标任务
针对给定的program,选取需要进行的优化(代码变换)以及优化顺序
针对给定program进行切分优化(选取loop tiling这个代码优化的参数tile-size)
针对网络选取算子融合方式(会把网络拆分为不同的program)
5
1、背景:
现在深度学习领域的网络大部分都还存在性能优化空间,例如一个经过深度优化的网络XLNet[3]可以比PyTorch的同样实现提速1.8倍,但是进行这样的网络优化需要很多的人力和专业知识,因此进行自动的网络优化成了现在深度学习编译器的研究热点。
其实网络优化就包括了对网络中的算子进行优化,而如何对算子进行优化,论文认为必须要解决两个问题:
1. 对算子生成的代码能进行的优化有哪些,以及如何将这些优化实际作用到代码上;
2. 这些优化应该以什么顺序作用到代码上才能达到最高的性能。
目前许多编译器已经解决了第一个问题,目前经典的优化方法包括loop fission, fusion, parallelization 和vectorization等。但是没能够解决第二个问题,因为无法保证找到的优化方式能达到“最高的性能”。因此本文重点描述了如何解决第二个问题,他将第二个问题归类为搜索问题,解决思路包括三个步骤:
1. 生成优化空间(design space):把一系列有序的代码变换步骤称作一个candidate,所有candidate的合集组成了优化空间,目标就是在优化空间中搜索到能达到“最高的性能”的candidate;
2. 将空间进行裁剪,去掉所有不合法的candidate;
3. 对可行的candidate进行评估排序,找到性能最好(硬件上运行时间最短)的candidate。
其实从解决步骤来看,这是一个经典的auto tuner的思路,但是论文的核心就在于第三步的评估:最准确、直接的评估方式就是将生成的代码直接在硬件上运行来获取性能。但是由于代码优化问题的空间通常是巨大的,对每一个candidate都进行实测是不可行的,而且有时候硬件在编译阶段甚至也没有ready,无法进行实测。因此另一种非常自然的选择就是使用一个cost model来预测性能。前人在设计cost model上也做了许多工作,但是他们有两个不足之处:要么是只能针对代码片段进行预测[4],或是需要非常精密复杂的特征工程[5]。本文提出的基于DNN的cost model能够弥补上述不足:基于完整的代码和高级的语言表达,这个cost model在预测时可以考虑到较为完整的信息,例如main memory的使用;除此之外,基于DNN的特性也让它不需要过多的特征工程就可以工作。
2、TIRAMISU Embedded DSL:
由于本文的cost model是基于TIRAMISU编译器的,因此这里简要介绍一下TIRAMISU的工作原理。TIRAMISU是基于C++的一种领域特定语言(DSL),用户首先通过TIRAMISU提供的接口定义硬件无关的算法(图1中定义了一个conv),TIRAMISU会基于polyhedral model [2,6,7,8,9]来将算法表达为一系列的循环(图2)。接着可以调用各种TIRAMISU提供的代码变换接口对算法生成的代码进行优化(图3)。
图3中调用的代码变换接口所组成的序列 {parallelize, interchange, tile, vectorize, unroll} 以及对应的参数,就是上面所说的一个candidate。 TIRAMISU现在需要用户来提供这样的candidate来进行代码优化,而本论文的目标就是让TIRAMISU能够自动找到这样的代码变换序列。

Fig.1

Fig.2

Fig.3
3、数据生成:
由于训练DNN需要大量的数据,TIRAMISU现有的算子显然不够用,因此本文实现了一个code generator来生成随机的程序(random program),以及对这个程序进行代码变换的序列(sequence of code transformations)。接着对program + transformations生成的最终程序进行实测获取运行时间,并和原先program的实测运行时间对比计算加速比(speedup),这样一个(program + transformation,speedup)就是一组训练数据了。
本文大约生成了1.8 million的programs,其中有56250个random algorithm(programs),每个program会进行32组code transformations。进行实测运行时间时候实测30次取中位数,生成所有数据大约花了3周。
3.1 随机程序
根据TIRAMISU程序特性,会随机生成三种类型的计算:1. simple assignments;2. stencils;3. reductions;而最终的程序就是对这三种类型的计算进行任意组合,而计算的数据也从1. constants;2. input arrays;3. previous computed values里面选取。
3.2 随机代码变换序列
代码变换也是随机生成,但是会保证变换的合法性,对每一个random program会随机生成32组不同的code transformations。
4、设计:
所有使用TIRAMISU表示的算法都可以使用这个cost model,支持的code transformations包括 loop fusion, loop tiling, loop interchange, 和loop unrolling这些较难用经验定义的,而parallelization and vectorization两种变换,则使用了和[10]一样的方式:最外层循环parallelize,最内层循环vectorize,这种变换方式通过以往经验来看是效率比较高的。
4.1 program建模
摒弃了复杂的特征工程,本文对program(图4.a)的建模从最基础的AST(Abstract Syntax Tree)入手(图4.b),可以看到原来在各种循环嵌套下的计算语句A-E都表示为树上的叶子节点,循环则表示为中间节点;对于每一条计算语句,本文提取的特征则表示为图4.c中的computation vector,包括:
(1) loop nest representation;
(2) assignments representation;
(3) loop transformation representation。
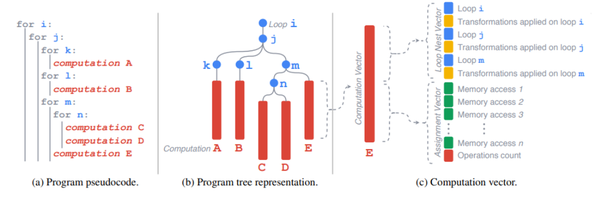
Fig.4
4.1.1 Loop Nest Representation
表示该计算语句所在的循环嵌套,例如E语句在i,j,m三个循环内,因此computation vector里记录了这三个循环的信息(图中的蓝色小块),包括循环上下界,是否reduce,是否fusion,是否interchange,是否tiling,以及tiling参数(表1)。
4.1.2 Assignments Representation
对于形如“左值=右值”的assignment语句,我们对左值和右值都分别进行了特征提取:
由于左值只允许有一个buffer,因此左值直接提取了buffer的维度信息,以及每个维度的大小;右值可能存在多个buffer,因此会首先对每一个buffer编号,用ID表示,再分别对每一个buffer提取memory access pattern(也就是和poly中一样的access matrix[11],一种表示array access的方式)并与ID相关联;然后还会提取右值所进行的所有计算类型的数量。(详细可以见表1)
4.1.3 Loop Transformation Representation
对循环的变换可以通过两个信息确定:变换的类型(type)和变换的参数(parameters),这两个信息会直接加在前面说的Loop Nest Representation后面(图4.c中黄色的小块)
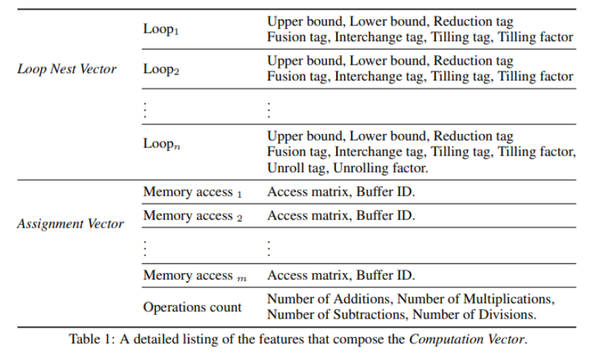
Table.1
论文中所有的特征都与硬件无关,因为这个cost model只针对CPU一种硬件。如果要将该模型扩展到其他硬件,只需要在特定的硬件上面使用上述方法重新收集数据进行训练即可。值得一提的是这个特征提取的阶段是对base-program进行的(还没做任何代码变换的程序),其原因一是进行代码变换后再提取特征比较耗时,二是变换后的代码较为复杂,不容易提取特征。
对比看一下同是MLSys 2012中文章[12] 中提取的特征,其实和本文的比较类似,因为两篇文章目标都是想要提取一些通用的特征。 [12] 中同样的也提取了buffer的访问信息,算子内部的运算数量。但是他们对于特征提取的时机和本论文不一样:他们是在进行了相应的代码变换后生成的代码上进行提取的,目的就是为了将做的代码变换信息能够提取到特征中。除此之外在求解tile-size任务时, [12] 还将他们的求解目标“loop tiling”变换的参数的tile size单独作为一个可选的特征加入。由于[12]中的代码优化只有一种——loop tiling,因此他们可以这么做,而本文求解的目标是“一系列代码变换以及顺序”,就难以对变换后的代码进行特征提取了。
4.2 Model Architecture
接下来讲一下cost model的设计。由于任务1)是一个回归任务——预测一系列代码变换带来的加速;2)任务需要支持不同长度的输入;3)任务的递归特性,因此cost model采用Recurrent + Recursive Neural Networks结构(图5),该论文也探究了其他网络结构,效果都没有下面这个好。下面来看一下这个网络结构:
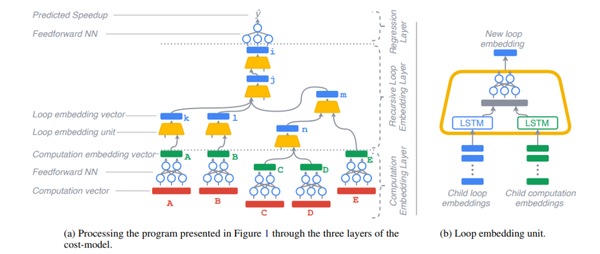
Fig.5
1. computation vector首先进行log-transformation来减少数据的方差,接着通过feedforward NN传入神经网络,形成computation embedding vector;
2. loop embedding unit(图5.b)使用两个LSTM对computation embedding vector进一步编码提取递归特征:第一个LSTM提取当前loop特征;第二个LSTM提取之前loop特征;
3. 上一层的输出loop embedding vector进入regression layer进行预测,目标函数使用MAPE(Mean Absolute Percentage Error),优化器使用AdamW。
5、空间搜索
这里就到了最开始说的argmax f()那一步了,本文使用了cost model来引导搜索方向。由于cost model的输入是一个序列,因此tree search是一个非常自然的搜索算法,该论文实现了是Beam Search和MCTS(Monte Carlo Tree Search)两种方法,并进行了比较。
5.1 Beam search
Beam search算法如图6所示,搜索空间被表示为决策树,图中红框部分表示了每一个需要做决策的时刻,而做的决策就是应该进行什么样的代码变换,在每个该做决策的时候都调用了cost model,通过预测在当前节点进行不同代码变换带来的性能收益,排序后来保留最好的K个变换(图中展示的是K=1的搜索过程)。
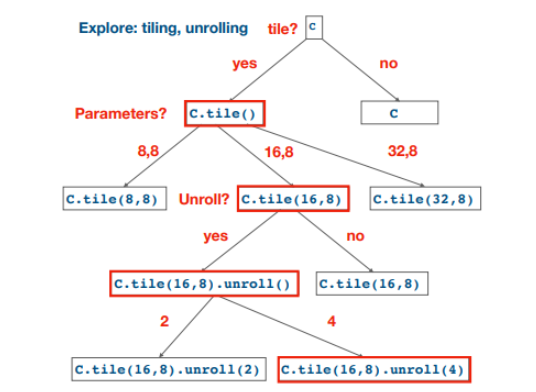
Fig.6
5.2 MCTS
但是我们都知道cost model的预测存在误差,而beam search会比较依赖cost model给出一个准确的结果。因此本论文也尝试了MCTS(Monte Carlo Tree Search)。MCTS由于引入了实测,比起Beam search方法来说能够一定程度上减少模型的随机性。MCTS做决策的过程包含两个步骤:1)同样地,在每一个做决策的点,MCTS调用了cost model来预测当前节点带来的收益,并选取好的决策往下遍历,直到遍历到叶子节点时就获取了一个完整的代码变换的序列,代表了cost model预测最好的序列; 2)对这个序列在硬件上进行实测,最终的实测数据再从叶子节点返回到一开始做决策的点。这样的一个反馈机制能够一步一步提升做决策的精度。
由于目标任务不一样,本文搜索的目标是一个对程序进行优化的序列,因此非常自然的使用了tree-search,而文章[12]中是一个多任务的cost model,因此他们选取了两种任务都能共用的graph方式作为cost model的输入,同时他们的cost model直接集成在XLA对应的任务的编译流程中,代替了原先使用的“分析模型”,来提高任务精度。因此文章[12]没有类似的空间生成和搜索过程,他们关注的更多的是在cost model的预测效果上。
6、实验评估:
论文主要用了三个指标来评判cost model的好坏:1)使用随机生成程序(生成训练数据的)来生成测试集,进行speedup的精度验证;2)将cost model集成到编译器中,对真实网络进行优化,计算网络优化前后的加速比(和优化时间);3)和Halide[10] 中的cost model进行上述比较;
论文的实验环境为16个相同的多核CPU节点上。每个节点都有一个双插槽,每个插槽是12核Intel Xeon E5-2680v3 CPU,具有128 GB RAM。
6.1 cost model在测试集上的效果
论文中将60%的数据用于训练,20%用于验证,20%用于测试。验证精度使用了MAPE (Mean Absolute Percentage Error),最终结果是16%。由于目的是挑选candidate,因此论文也非常自然的计算了皮尔逊相关系数,来检验预测数据和实测数据的相关程度,最终结果是0.90。除了皮尔逊相关系数之外,斯皮尔曼等级相关系数是0.95,这些都证明了预测和实测的相关程度是非常高的。实验结果如下:
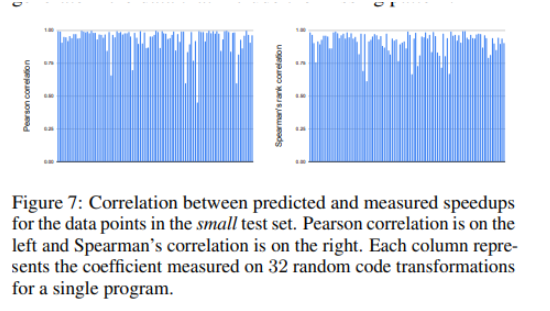
Fig.7
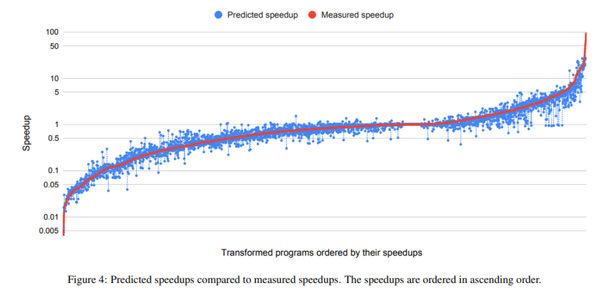
Fig.8
图8中展示了100个程序*32种代码变换序列,总计3200个数据的实测和预测的speedup数据,从图中可以看到他们是非常接近的。
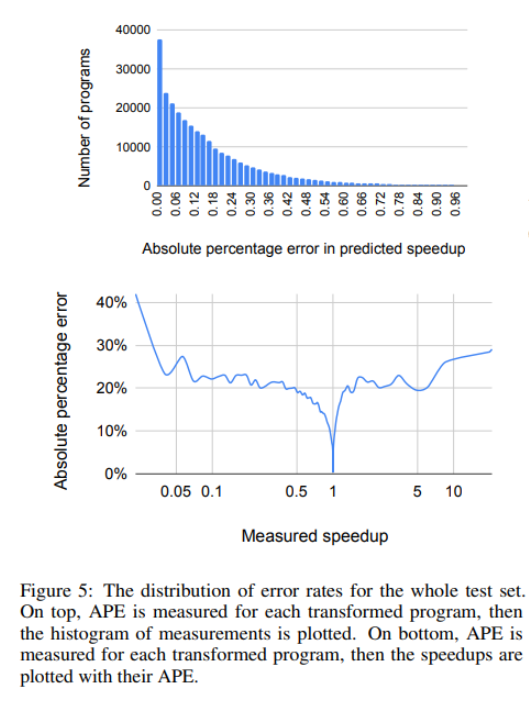
Fig.9
图9展示了模型预测的APE(Absolute Percentage Error),该实验说明了实测speedup小于0.05的时候模型更容易出错,而speedup较大的时候(大于1),模型几乎不出错。
6.2. cost model在网络优化中的效果
论文选取了一系列在图像处理,深度学习等应用中使用的真实的网络来验证cost model的效果。图10中选取了四种搜索方式来对网络进行优化:蓝色的Beam search with execution代表使用beam search算法进行搜索,搜索过程中的评估方式采用了execution这样实测的方式,被作为性能基线;接下来是论文中提到的两种搜索方式beam search + cost model (红色)和MCTS + cost model (黄色),其中评估采取了cost model的方式;最后作为对比的则是Halide里提出的auto scheduler(绿色)。从图中可以看出除了box blur网络以外,其余所有的网络都超越了Halide的效果。除此之外,使用论文中的cost model,采取beam search和MCTS的搜索算法,在某些网络里面能够达到和基线差不多的水平,在其余网络里的表现则各有千秋,其原因可能与网络结构有关。
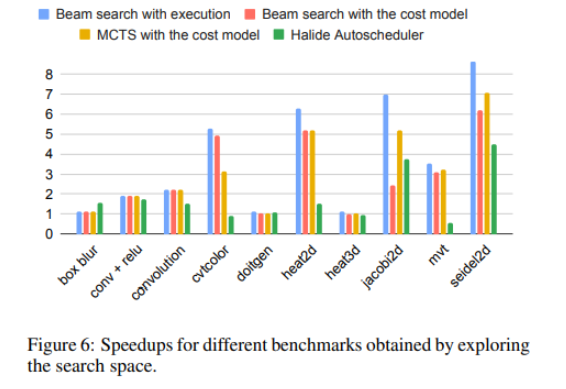
Fig.10
6.3. 搜索时间和搜索效果的平衡
在真实应用场景中,通常我们花更多时间来搜索,就能够搜索到更好的结果,但是搜索时间和搜索效果的平衡往往难以平衡。该论文在平衡这两点上也做了许多实验(表2):比较的基线同样是beam search with execution (BSE),左边是使用beam search with cost model (BSM)对比BSE在时间上的提速(第二列)以及搜索到的最佳代码的性能劣化(第三列),右边是使用MSTC搜索算法。
可以看到对于一些网络(box blur, conv + relu, convolution),使用cost model可以大大加速搜索,同时不会带来性能差异,总体来说在这些网络上使用cost model可以带来11.8到106.5倍的提速,性能差异控制在15%以内。而那些与基线相比性能差异较大的网络原因就是cost model的精度不够,论文中提出弥补办法是可以生成更多的数据来训练这样的pattern。
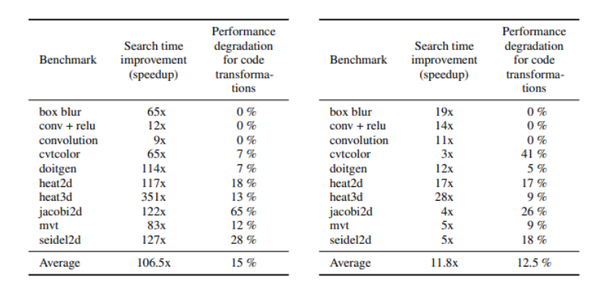
Table.2
具体实验过程可查阅论文。
参考文献:
[1] Baghdadi R, Merouani M, Leghettas M H, et al. A Deep Learning Based Cost Model for Automatic Code Optimization[J]. Proceedings of Machine Learning and Systems, 2021, 3.
[2] Baghdadi, R., Ray, J., Romdhane, M. B., Del Sozzo, E., Akkas, A., Zhang, Y., Suriana, P., Kamil, S., and Amarasinghe, S. Tiramisu: A polyhedral compiler for expressing fast and portable code. In Proceedings of the 2019 IEEE/ACM International Symposium on Code Generation and Optimization, CGO 2019, pp. 193–205, Piscataway, NJ, USA, 2019. IEEE Press. ISBN 978-1-7281- 1436-1. URL http://dl.acm.org/citation. cfm?id=3314872.3314896.
[3] Yang, Z., Dai, Z., Yang, Y., Carbonell, J. G., Salakhutdinov, R., and Le, Q. V. Xlnet: Generalized autoregressive pretraining for language understanding. CoRR, abs/1906.08237, 2019. URL http://arxiv.org/abs/1906.08237.
[4] Mendis, C., Amarasinghe, S. P., and Carbin, M. Ithemal: Accurate, portable and fast basic block throughput estimation using deep neural networks. CoRR,abs/1808.07412, 2018. URL http://arxiv.org/abs/1808.07412.
[5] Adams, A., Ma, K., Anderson, L., Baghdadi, R., Li, T.-M., Gharbi, M., Steiner, B., Johnson, S., Fatahalian, K.,Durand, F., and Ragan-Kelley, J. Learning to optimize halide with tree search and random programs. ACM Trans. Graph., 38(4):121:1–121:12, July 2019. ISSN 0730-0301. doi: 10.1145/3306346.3322967. URL http: //http://doi.acm.org/10.1145/3306346.3322967.
[6] Feautrier, P. Array expansion. In Proceedings of the 2nd international conference on Supercomputing, pp. 429–441, St. Malo, France, 1988. ACM. ISBN 0-89791-272-1. doi: 10.1145/55364.55406. URL http://portal. acm.org/citation.cfm?id=55406.
[7] Baghdadi, R., Beaugnon, U., Cohen, A., Grosser, T., Kruse, M., Reddy, C., Verdoolaege, S., Betts, A., Donaldson, A. F., Ketema, J., Absar, J., Haastregt, S. v., Kravets, A., Lokhmotov, A., David, R., and Hajiyev, E. Pencil: A platform-neutral compute intermediate language for accelerator programming. In Proceedings of the 2015 International Conference on Parallel Architecture and Compilation (PACT), PACT ’15, pp. 138–149, Washington, DC, USA, 2015a. IEEE Computer Society. ISBN 978-1- 4673-9524-3. doi: 10.1109/PACT.2015.17. URL http: //http://dx.doi.org/10.1109/PACT.2015.17.
[8] Bondhugula, U., Hartono, A., Ramanujam, J., and Sadayappan, P. A practical automatic polyhedral parallelizer and locality optimizer. In PLDI, pp. 101–113, 2008.
[9] Baghdadi, R., Cohen, A., Grosser, T., Verdoolaege, S., Lokhmotov, A., Absar, J., van Haastregt, S., Kravets, A., and Donaldson, A. F. PENCIL language specification. Research Rep. RR-8706, INRIA, 2015b. URL https://hal.inria.fr/hal-01154812.
[10] Ragan-Kelley, J., Adams, A., Paris, S., Levoy, M., Amarasinghe, S., and Durand, F. Decoupling algorithms from schedules for easy optimization of image processing pipelines. ACM Trans. Graph., 31(4):32:1–32:12, July 2012. ISSN 0730-0301.
[11] Paul, F. and Christian, L. The polyhedron model. In Padua, D. (ed.), Encyclopedia of Parallel Computing, pp. 1581, 1592. Springer, 2011.
[12] Sam Kaufman, Phitchaya Phothilimthana, Yanqi Zhou, Charith Mendis, Sudip Roy, Amit Sabne, Mike Burrows. A Learned Performance Model for Tensor Processing Units. Proceedings of Machine Learning and Systems 3 pre-proceedings (MLSys 2021)
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

