
本文转自:知乎
作者:金雪锋
背景
深度学习发展到今天,大规模的分布式训练已经成为常态,增加训练节点数,充分利用数据并行可以大幅减少训练时的迭代数,即正反向传播的时间。下图是数据并行的示意图,数据并行中不可避免的一个问题是不同节点间的梯度聚合操作,这需要在不同节点间进行集合通信,而通信量又比较大,因此网络带宽就成为了大规模分布式训练场景下的一个瓶颈。此问题在联邦学习场景下尤为突出。
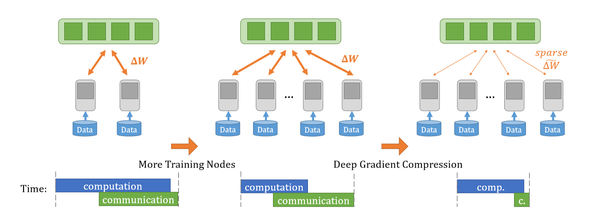
应对此问题,在网络带宽一定的情况下,最为直接的思路就是减少通信量即进行梯度压缩。
相关工作
之前的梯度压缩的工作可以分为两大类:梯度量化和梯度稀疏化。
梯度量化显而易见,是用更低的比特来表示梯度,这个思路和训练后量化与量化感知训练一致。梯度量化的问题也很明显,梯度量化压缩的极限是32x(32bit表示的梯度,量化为1bit),这对于超大规模的模型可能并不够;越低的比特,反量化后还原回来的梯度与原始梯度的差异越大,可能导致训练不稳定。
梯度稀疏化则是在梯度聚合时只有选择地聚合一部分梯度从而减少通信时间,根据选择多少比例的梯度进行聚合,这种方式理论上可以实现任意倍数的压缩率。
最简单的梯度稀疏化方法是基于TopK采样,选择绝对值最大的K个梯度进行聚合。虽然TopK操作的复杂度是O(n),但是由于梯度的向量非常庞大,整个计算依然非常耗时。
后续又有了Deep Gradient Compression(DGC)的工作,DGC提出稀疏化的原则是判断梯度的绝对值是否大于某一阈值,随机选择一定比例的梯度值(0.1%-1%),然后对这部分梯度进行TopK操作,得到阈值,进而再全部梯度上用此阈值进行稀疏化。如果此阈值不够准确,筛选出了过多的梯度,那么会对筛选出的梯度再进行一次TopK采样。DGC也提出了Momentum Correcition与Local Gradient Clipping来保证训练的收敛,Momentum Factor Masking和Warm-up Training来应对梯度过时的问题。但是在稀疏化阈值的选择上,DGC采用了一种启发式的方式,而且在最差的情况下,要进行两次TopK操作,这会比较耗时。
基于此,又出现了RedSync和GaussianKSGD两种方法,这两种方法和DGC相比,主要是在稀疏化阈值的选择上的变化。这两种方法均假定梯度是按照某种高斯分布,然后根据设定的压缩比,选择阈值,从而选择出需要聚合的梯度。这样相比DGC,在稀疏化操作的时候耗时就会明显减小,但是符合某种高斯分布这个强先验条件不一定会满足,从而导致这两种方法的实际压缩比会和预定压缩比有不少差异。
SIDCo
这篇论文主要是提出了一种基于稀疏分布的压缩方法(Sparsity-Inducing Distribution-based Compression, SIDCo),假设梯度是符合某种稀疏性分布,然后提出了一种多段式的阈值估计方法来相对准确的得到阈值。
SIDCo中依然有一个很强的先验条件,梯度符合某种稀疏性分布,文章中先引出了可压缩信号的定义

然后在附录中详细证明了深度学习模型中的梯度满足此种性质,而可压缩信号具有一个性质即他们很好的被SID来近似。
下图是在Cifar10上面训练一个ResNet20网络得到的梯度的PDF与CDF,以及三种SID:double exponential, double gamma double GP distributions的曲线
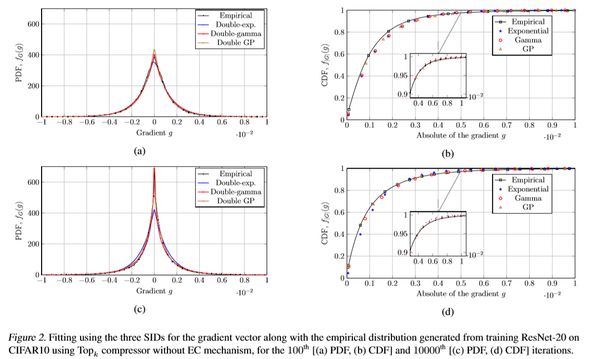
可以看到这三种分布均可以比较好的拟合真实的梯度分布,但是在CDF尾部的地方会有一定偏差。
给定压缩比之后,可以直接在CDF曲线上得到阈值,给定压缩比,三种SID对应的阈值解析解均在论文中给出,经过简单计算即可得到。
当压缩比很大(<0.01%)时,如果只用单一的SID来拟合会出现比较大的偏差,因此论文提出使用段式的阈值估计方法。
先选择某种SID,以更大的压缩比计算一次阈值,得到筛选出的梯度;
在对筛选出的梯度,以某种压缩比、某种SID再计算一次阈值,得到进一步筛选出的梯度;
重复上述步骤M次。
总的压缩率就是
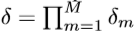
算法流程入下表所示


实验结果
分别在RNN和CNN的经典模型上进行了对比实验,下图给出了加速比、吞吐率以及真实压缩比的数据
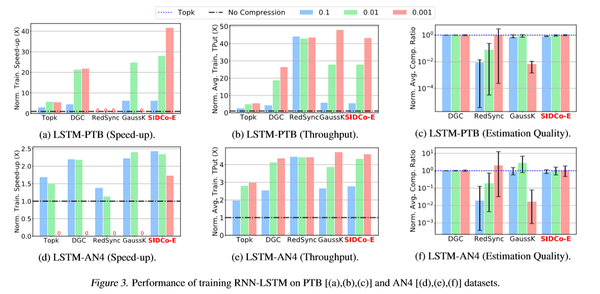
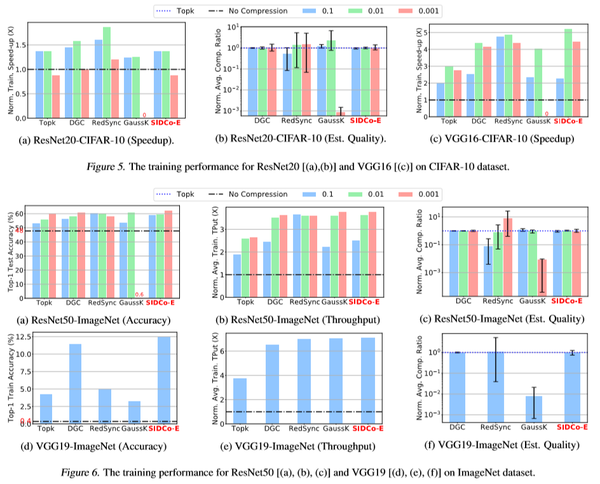
可以看到相比于TopK、DGC、RedSync和GaussK,SIDCo的加速比和吞吐率都会更优,主要原因是算取阈值的时候效率更佳,相较于RedSync和GaussK,SIDCo的真实压缩率更为准确,这也说明了符合某种稀疏性分布的先验条件比较准确。
结论
这篇论文提出了一种基于稀疏性分布的梯度压缩方法,利用一个多段式的阈值估计可以相对准确的算出真实的阈值。在多种RNN和CNN的网络上面进行了对比实验,对比不压缩、TopK和DGC,SIDCo取得了41.7x、7.5x和1.9x的加速,而且真实压缩比的方差相较于RedSync和GaussK更小。
参考
《AN EFFICIENT STATISTICAL-BASED GRADIENT COMPRESSION TECHNIQUE FOR DISTRIBUTED TRAINING SYSTEMS》
《DEEP GRADIENT COMPRESSION: REDUCING THE COMMUNICATION BANDWIDTH FOR DISTRIBUTED TRAINING》
《RedSync: Reducing synchronization bandwidth for distributed deep learning training system》
《Understanding Top-k Sparsification in Distributed Deep Learning》
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

