
前言
今年上半年由OpenAI提出的CLIP[1],利用4亿图像文本对训出了一个在各个图像分类数据集上表现能同有监督方法相媲美的模型,再一次将"zero-shot learning"这个名词映入了人们的眼帘。什么是"zero-shot learning"呢,首先让我们来看一下它的定义[2]:
ZSL, which was defined as zero-data learning, was first proposed in the field of artificial intelligence in 2008 [3]. It is used to solve the classification problems with insufficient labeled training data. In 2009, Mark et al. [4] extended such a problem to the field of neural information processing and named it “zero-shot learning” for the first time.
以经典的图像分类问题举例,现在有一个训练集和测试集,测试集中包含有不存在于训练集中的"未知类别","zero-shot learning"研究的问题就是如何利用训练集中"已知类别"的数据以及"未知类别"与"已知类别"之间存在的隐式关系,从而能够正确预测出"未知类别"。
现在我们已经对"zero-shot learning"有了一个基本的概念,那么CLIP是如何利用这么多图像文本对去训练一个"zero-shot"分类器的呢?其实思想并不复杂,主要用到了对比学习的方法。由于图像大部分都是从网上收集来的,每个图像对应地都有一个网页描述,正好可以作为图像的"天然标签"。
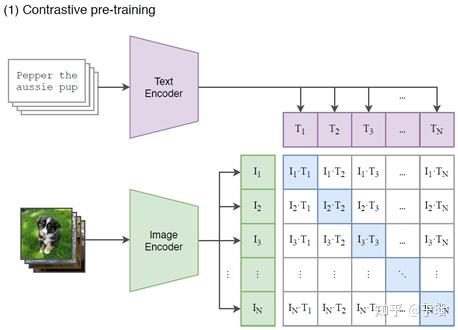
练阶段会选取N个图像文本对,其中文本描述通过文本编码器Transformer转化成shape为 的文本embedding,图像通过图像编码器ResNet-50/ViT[5]同样转化成 的图像embedding,之后两种embedding分别经过L2正则之后进行矩阵乘,得到的关系矩阵,与对应的one-hot矩阵(对角线上值为1,其余值为0)计算交叉熵损失。
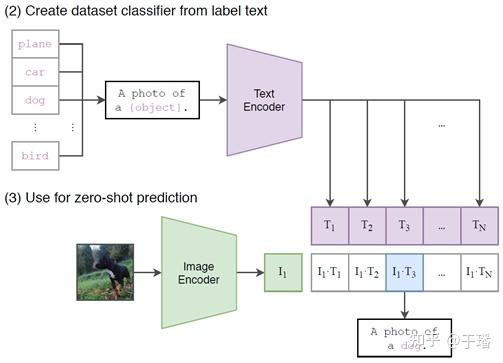
CLIP的推理阶段需要设置好测试集中的标签集合,每个标签都需要先转化成文本描述之后输入文本编码器生成文本embedding。之后将测试图像输入到图像编码器中获得图像embedding,与文本embedding生成 的关系矩阵,利用SoftMax激活函数得到最终的类别预测概率值。
CLIP的"zero-shot"能力主要体现在经过4亿文本图像对的训练后,可以直接在包含ImageNet在内的多个图像分类公开数据集上进行推理而不需要任何fine-tune。其通过对比学习展现出来的"zero-shot learning"新思路给后续的研究带来了极佳的insight,而ViLD[6]就是其中之一。
Zero-Shot Detection via Vision and Language Knowledge Distillationhttp://arxiv.org
Long-Tailed Detection
ViLD是一个基于知识蒸馏的"zero-shot detection"训练方法,在正式介绍其核心方法之前,有必要先来聊一聊其主要用到的公开数据集——LVIS[7]。不同于经典的Pascal VOC和COCO,LVIS是一个包含1203种类别的呈长尾分布(Long-Tailed distribution)的实例分割公开数据集。所谓的长尾分布指的是训练集中只有少部分类别有着较多的样本数量,而大部分的类别都只具有少量样本量的情况。相比较于均匀分布,长尾分布显然更符合现实世界中通用检测领域的样本情况。同时,呈长尾分布的数据集也天然契合了"zero-shot learning"的应用场景,即在测试集中存在的大量训练集缺少甚至没有样本类别的情况下,如何利用"已知类别"的数据赋予模型预测"未知类别"的能力。

Overview of ViLD
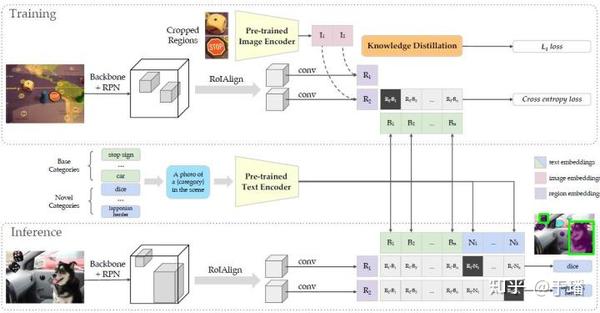
ViLD基于经典的实例分割框架Mask R-CNN[8]进行修改,由于传统的检测或者实例分割方法,不管是one-stage,two-stage还是近几年涌现的anchor-free类方法最终输出的检测框都是带有具体类别预测的,因此文章通过将Mask R-CNN的RCNN分支改为只预测"类不感知"的检测框和分割结果,从而彻底将分类任务和检测/分割任务进行解耦。这种做法的好处是Mask R-CNN的主体部分只需要关注如何将目标物体的位置准确地预测出来,而"zero-shot"分类的任务全权交给同CLIP结合的部分去处理。当然,这样做同样也会带来问题,将在后文中进行进一步分析。
训练阶段

文章将LVIS上的"zero-shot"问题定义为只利用样本数较多的少量类别 作为训练数据,最终对涵盖所有类别( 、 )的测试集进行预测。前面提到ViLD的Mask R-CNN部分输出的是类不感知的检测框和分割结果,这里我们先将分割结果放在一边,因为其类别是跟随检测框的类别。按照文章的描述,Mask R-CNN部分的训练和"zero-shot learning"没有关系,推测是独立完成的。本文的重头戏在于获得了RoI(Region of Interest,位于原始Mask R-CNN的分类器之前)之后,如何利用CLIP这个预训练模型,使得ViLD具有"zero-shot"分类的能力。这里可以看出,真正意义上的ViLD其实只包含和CLIP进行交互部分的结构,分别为与CLIP文本编码器进行交互的ViLD-text,与CLIP图像编码器进行交互的ViLD-image。
看到这里,读者可能会有些迷惑,怎么一下子出现了ViLD,ViLD-text和ViLD-image三个模块呢?事实上上述的三个模块都是共享的同一个结构,输入到ViLD的RoI都是经过一个轻量网络转化为区域embedding,之后分别作为ViLD-text和ViLD-image部分的输入,下面介绍下两种不同的ViLD分支在训练方式上的区别,
ViLD-text
输入到ViLD-text的区域embedding 将会与已经转化成文本embedding的 加上背景类别的embedding 计算相似度,最后经过softmax函数后与one-hot形式的真值计算交叉熵损失作为ViLD-text部分的损失。
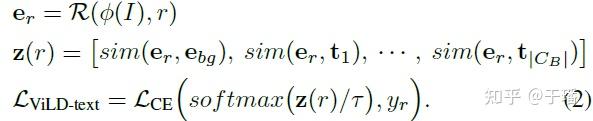
ViLD-image
输入到ViLD的RoI所包含的检测框在滤除了背景框,经过NMS算法过滤后,将直接在原图像上进行裁剪操作,裁减之后的区域图像输入到CLIP的图像编码器中获得蒸馏学习要用到的参考图像embedding 。这里的图像embedding聚合了1倍和1.5倍大小的检测框的信息。
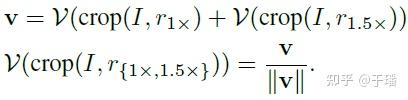
获得了参考embedding之后,对ViLD主干部分生成的区域embedding进行蒸馏学习,其损失函数如下:
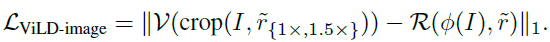
整个ViLD模块的损失函数为ViLD-text和ViLD-image的损失加权求和:
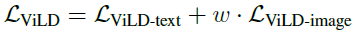
推理阶段
ViLD在推理阶段需要将训练集中的类别 和仅在测试集中出现的类别 的集合,以及通过CLIP的文本编码器转化为文本embedding,外加上背景类别的embedding 进行组合。分别与ViLD-text和ViLD-image生成的区域embedding计算相似度,并通过softmax函数得到类别预测概率,之后将两个概率按照如下规则进行ensemble得到最终的分类预测结果 :
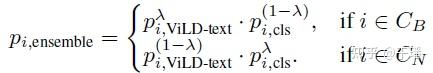
确定了RoI的类别之后,最终输出的检测框与分割结果的类别信息也随之确定了。
实验结果
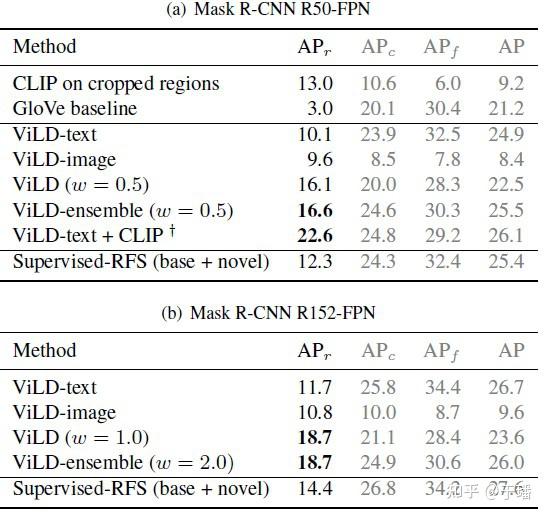
从LVIS测试集的结果上看,ViLD在"未知类别"上的表现要远优于同时使用"已知类别"和"未知类别"进行训练的监督方法,同时在"已知类别"上的表现可以和监督方法相当。
思考与总结
总体来讲,ViLD是一个具有zero-shot能力且完成度较高的通用检测框架,但是依旧存在以下的不足之处:
1. 为了适配CLIP将分类任务和定位任务解耦,导致Mask R-CNN部分需要将所有目标类别的语义和位置信息整合成一个,同时由于缺乏分类任务的指导,一定程度上引起了模型定位任务的表现下降,这在文中失败案例分析部分也有体现。
2. zero-shot分类部分整体来看更像是一个ensemble的方案,虽然文章这样设计的初衷是为了让两个分支分别侧重已知类别与未知类别的预测,但是只保留一个分支并不影响模型的功能,是否还能进行进一步的精简呢?
CLIP、ViLD这些工作的陆续推出,再次掀起了一波zero-shot的浪潮,证明了zero-shot在图像分类、检测这些任务上具有媲美有监督方法的实力。我们有理由相信,在不远的未来,zero-shot还会在更多的领域绽放光彩。
Reference
[1] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[J]. arXiv preprint arXiv:2103.00020, 2021.
[2] Sun X, Gu J, Sun H. Research progress of zero-shot learning[J]. Applied Intelligence, 2021, 51(6): 3600-3614.
[3] Larochelle H, Erhan D, Bengio Y. Zero-data learning of new tasks[C]//AAAI. 2008, 1(2): 3.
[4] Palatucci M M, Pomerleau D A, Hinton G E, et al. Zero-shot learning with semantic output codes[J]. 2009.
[5] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[6] Gu X, Lin T Y, Kuo W, et al. Zero-Shot Detection via Vision and Language Knowledge Distillation[J]. arXiv preprint arXiv:2104.13921, 2021.
[7] Gupta A, Dollar P, Girshick R. LVIS: A dataset for large vocabulary instance segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 5356-5364.
[8] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.
END
原文:知乎
作者:于璠
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

