
上半年MindSpore陆续发布了1.2和1.3两个版本,端侧Lite这一块其实增加了很多大特性,前面没有太多宣传,这次统一把MindSpore Lite最新版本的主要新增能力给大家介绍一下。这个版本中我们为大家带来了全新的南向自定义能力,Delegate机制,针对微处理器的Micro方案,新增支持NNIE/NVIDIA GPU等硬件推理,完善控制流,支持流式执行,支持稀疏编码,端云联邦学习、性能更高的算子库等,给端侧AI带来更多的全新体验。下面就带大家快速浏览这两个版本的关键特性。
1 新增对外开放机制
本次版本新增两个对外开放的接入机制:支持南向自定义算子接入,支持第三方AI框架通过Delegate机制接入。
南向自定义算子的接入功能,支持用户自定义图优化能力,实现在离线阶段生成特定硬件支持的模型文件,同时支持特有硬件算子接入MindSpore Lite Runtime,实现MindSpore Lite在第三方硬件上高性能推理。
Delegate机制,支持有构图能力的第三方AI框架接入MindSpore Lite,充分利用外部AI框架提供的特有硬件算子库或者更优越的推理性能。采用Delegate实现了 Lite+其他AI框架的异构执行,保持了离线模型一致性。
1.1 南向自定义算子接入
我们在1.3版本开放了标准化的南向接入接口,南向接口分为两块:离线转换工具部分与在线推理部分。
离线自定义接入能力可以实现用户把自身的图优化能力接入到MindSpore Lite转换工具中,生成用户想要的优化图,这其中包括生成用户自定义的算子。
在线自定义接入能力可以实现底层芯片基于南向接口把自身芯片的算子接入到MindSpore Lite Runtime中, MindSpore Lite运行时会调度到具体的硬件上去,帮助AI应用屏蔽底层硬件的差异。
南向接口开放的算子接入主要分为两种,一种是MindSpore Lite已有算子,用户可自定义优化后接入,推理运行时使用用户自定义算子,另一种是MindSpore Lite不存在的算子,用户在离线阶段通过图优化构建包含自定义算子的模型,在线运行时把该自定义算子的实现通过南向接口接入MindSpore Lite,实现在AI专有硬件上的运行。
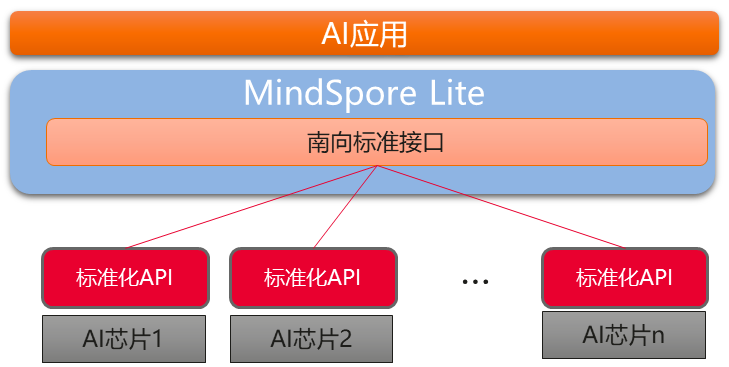
第三方专用AI芯片南向接入MindSpore Lite
当前南向接入机制已集成Hisilicon Hi3516D。接入Hi3516D我们采用了自定义算子接入的形态接入到MindSpore Lite,实现了自身代码与MindSpore Lite开源框架的解耦。
1.2 Delegate机制
在最新版本中我们开放了标准化的Delegate接口,为用户提供了一种灵活的、与MindSpore Lite内部实现解耦的方法来接入第三方AI框架。
Delegate适用于以下AI框架:
- 具备在线构图能力:在提供算子库的基础上,可以在线将多个算子构建成一张运行图。
- 支持新硬件:硬件厂商提供了配套的AI框架。
使用Delegate机制时,开发者可以基于开放的接口把自己的算子选择、子图构建、子图执行等能力接入MindSpore Lite中, Lite运行时会调度到Delegate对应的执行器上去。如下图所示,在Lite的模型构建结束之后,会生成拓扑排序的算子列表。构图时:解析算子的属性,将Delegate执行器支持的一段连续算子通过在线构图的方式,构建成一张Delegate子图,在原始的算子列表中,用子图去替换支持的算子;推理时:调度Delegate子图的执行,实现MindSpore Lite与第三方推理引擎的数据交换、后端引擎上的高速计算等。
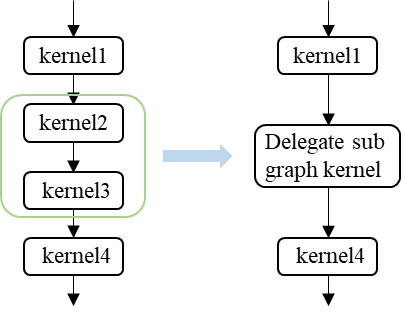
通过Delegate接入MindSpore Lite
Delegate机制使得MindSpore Lite可以调度其他AI执行器的推理,对于一些专用硬件厂商提供的配套执行器,可以明显提升在对应AI加速硬件上的推理性能。同时,Delegate提供了Lite+其他AI框架的异构能力,由于Lite支持的算子范围很广,因此可以大幅提升第三方或自定义框架的网络泛化能力。
之前版本Kirin NPU接入MindSpore Lite的代码与Lite自有的CPU和GPU代码完全耦合,开发时需要详细了解Lite推理的内部流程,对开发者要求非常高。当前最新版本,我们已经将Kirin NPU的接入方式切换到Delegate机制,实现了NPU调度代码与MindSpore Lite开源框架的解耦。
2 新增支持的后端
2.1 支持Hi3516D
网络范围更丰富
MindSpore Lite集成Hi3516D后,大幅扩展了Hi3516D支持的模型范围:Hi3516D本身NNIE支持的算子只有40+,而MindSpore Lite有210+支持的算子,同时MindSpore Lite支持异构推理,在NNIE运行不了的算子时可以继续运行在MindSpore Lite的算子上的。
模型转换更便捷
如果直接使用NNIE导出模型,如果存在不支持的算子,不但需要用户自行实现CPU算子,同时还需要用户对不支持的算子提供校正集,在使用MindSpore Lite Converter后,由于支持的算子大量增加,原先用户自定义的算子Converter内基本都已实现,所以Converter内的算子就不需要了提供校正集了,只需要提供输入集就可以了,Converter会自动生成过程中NNIE不支持算子的校正集。
集成开发更简单
相比集成NNIE推理引擎,集成MindSpore Lite的难度要降低很多:
- 集成NNIE的用户需关注NNIE推理控制相关变量及接口tensor的声明与初始化,并在推理过程中进行赋值控制,整体过程复杂。使用MindSpore Lite框架,用户无需关注。
- 集成NNIE的用户需关注mmz内存的申请,释放,缓存同步等。使用MindSpore Lite框架,用户无需关注。
- 集成NNIE的用户模型的加载,推理等接口需传递复杂的数据结构,并在推理时需根据不同情况调用不同接口和不等的次数。使用MindSpore Lite框架,接口简单易用且统一。
- 集成NNIE的用户存在自定义算子时,需要自己完成框架的集成调度与切换,代码耦合性上较强,而按照MindSpore Lite的接口接入的话,只需要关注自身的算子实现即可,无需关注框架的调度,开发工作更聚焦。
2.2 支持NVIDIA的GPU
在1.3版本中,我们通过Delegate新增接入了TensorRT,扩展了NIVDIA的GPU推理能力。
使用TensorRT时,用户要将模型离线导出成TensorRT定义的格式,对于有不支持的算子,就会报转换失败,无法使用推理功能。通过Delegate可以实现MindSpore Lite + TensorRT的异构,TensorRT不支持的算子可以运行在Lite内置的CPU算子上,在充分利用NIVDIA的GPU推理能力的同时,扩大了网络支持的范围。
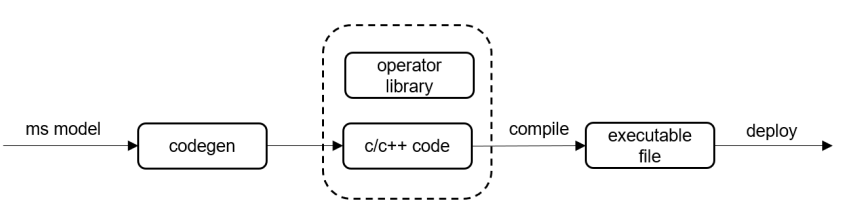
3 CodeGen支持微处理器上的推理
相较于移动终端,IoT设备上系统资源有限,对ROM空间占用、运行时内存和功耗要求较高。MindSpore Lite1.2版本正式发布了代码生成工具CodeGen,将运行时编译、解释计算图,移至离线编译阶段。仅保留推理所必须的信息,生成极简的推理代码。CodeGen可对接NNACL和CMSIS等不同算子库,支持生成可在x86/ARM64/ARM32A/ARM32M平台部署的推理代码。对微控制器等IoT设备上进行部署机器学习模型十分友好。
此方案我们同时针对OpenHarmony进行了适配,即将对外发布,敬请期待;
另外此方案我们也将开放南向硬件接入能力,支持更多IoT设备接入,该功能也将在Q4发布;
4 更丰富的语音语义场景
4.1 支持Attention结构
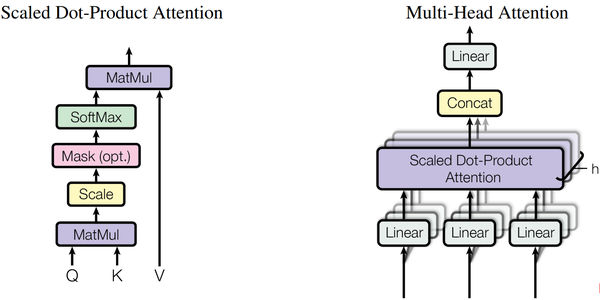
1.2版本我们增加了针对LSTM和GRU模型结构的融合支持与算子支持,并支持了基于LSTM和GRU的TTS场景。
我们观察到最近一段时间,Attention结构在语音语义场景甚至是CV场景中的研究和应用越来越广泛,因而本次MindSpore Lite1.3增加了针对Multi-Head Attention、Masked-Multi-Head Attention和Relative-Position Attention结构的融合支持,并进行了内存数据重排优化和性能优化。在此基础上,针对基于Attention的NLU模型和ASR模型进行了调优,针对语音场景首次推理时延和实时率两个关键指标,优化了模型的加载时间和推理时延。
4.2 支持流式执行
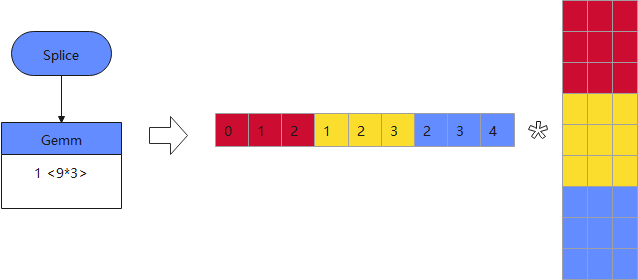
流式执行图示
语音类模型在一次推理中通常需要输入多帧数据,而前后几次推理的输入数据往往是有部分重叠的,如果每次都将所有的输入帧都做一次计算,会非常耗时。MindSpore Lite在本次更新中增加了流式执行的支持,即缓存前次推理时每层算子的输出结果,在当前推理时复用前次推理的结果,从而避免重复计算,真正需要计算的帧数会远小于总的输入的帧数。如上流式执行图示,MindSpore Lite将Splice和Gemm算子融合成一个算子,只在首次推理时全量计算矩阵乘,并将计算结果保存在算子中,后续计算只需要计算蓝色块部分的矩阵乘,红色和黄色部分只需用上次推理计算黄色和蓝色块得到的结果覆盖即可。在华为音箱中测试,这种流式执行可将语音模型的执行时长从6ms降到2.2ms。
4.3 完善控制流
在本次更新中,我们还进一步强化了对于控制流的支持,重构了控制流的图表达形式和推理引擎。
我们基于MindIR函数式编程的思想,重构了常见的分支、循环和递归的控制流结构的图表达形式:通过Partial算子,Switch算子和Call算子实现,Partial 算子代表一张有初始输入的子图,Call算子的语义是子图调用,Switch算子通过布尔量输入改变输出。IR中有两种控制流的模式,一种是Partial算子加Call算子,表示对一张子图的调用, 如图所示:
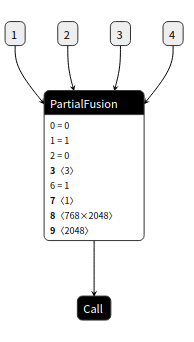
控制流Partial + Call 模式
另一种是Partial算子, Switch算子和Call算子组成的模式,根据Switch的一个布尔量的值,决定Call算子调用两个Partial算子中的哪一个,实现图的运行的转变。
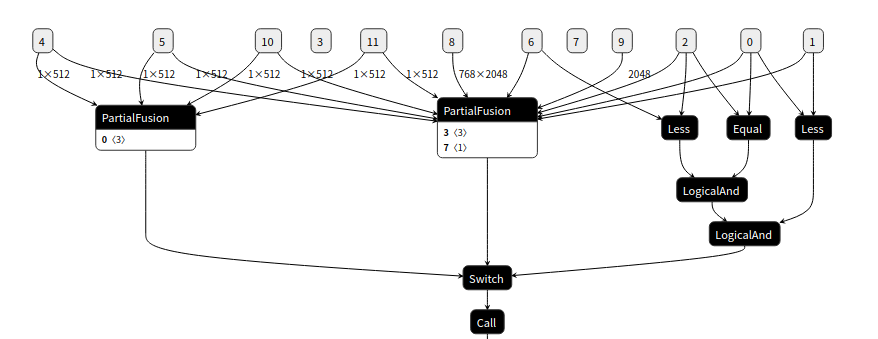
图控制流Partial + Switch + Call 模式
对于在线运行时,我们基于消息队列设计了一种异步执行框架,异步框架中的每个基本执行单元我们称为Actor,Actor是消息的消费者同时也是消息的生产者。在控制流场景中,每个子图会被编排成一个Actor。离线的两种模式会编排成两种Actor。Partial算子加Call算子的模式经过编排变成所属Actor的output data arrows, 通过消息发送激活下一个Actor (也就是子图) 运行;Partial算子加Switch算子加Call算子会被编排成拥有两条output data arrows的Switch Actor, 不同的布尔量的输入,可以发送消息给不同的Actor。
5 支持稀疏编码
我们的训练后量化工具支持权重量化、全量化两种量化方式,同时提供1~16 bit的选择,用户可以权衡压缩率和精度,选择合适的bit数。同时在量化的基础之上,MindSpore Lite还实现了稀疏编码的方式,支持将量化后的权重数据进行稀疏编码,量化工具会根据模型的数据分布情况,自动选择合适的稀疏编码策略,从而达到最优的压缩效果。
其中,稀疏编码是采用一张Coding Table将量化后的数据进行紧凑表示,在分布较为稀疏的场景下可以得到更大的压缩率。同时如果量化后的数据中存在大量的0值数据时,仅存储非0数值。稀疏编码可结合权重量化和全量化一起使用,实现极致的压缩效果。MindSpore Lite量化效果如下图所示,在交付场景下,部分模型压缩率最高可达30+倍。
6 端侧训练
自MindSpore Lite1.1版本我们发布了端侧训练能力后,1.2和1.3版本我们持续对端侧训练进行了优化。
在易用性方面,我们将训练和推的API以及编译构建进行了统一,训练和推理都可以直接通过LiteSession调用,而不需要切换成TrainSession,另外训练编译依赖的相关文件剥离到单独so文件,从推理切换到训练只需要链接统一个so文件,对用户、开发者更加友好。
训练性能方面,对1*1以及3*3 卷积核的Conv2DGrad算子和SparseSoftmaxCrossEntropyWithLogits 输入维度为1的场景进行了简化,将其优化成softmax计算,单算子性能提升了5%-10%左右。
小型化方面,支持训练权重后量化,减少训练后模型的大小。同时对端侧训练内存进行了优化,用公共的workspace内存代替算子运行时分配的临时内存,在albert等模型下可以节约10-20%的运行内存。
另外作为MindSpore1.3重要特性之一,我们对端侧训练场景进行了扩展,支持端云联邦学习场景,端云模型可以进行互相转换,权重采用差分隐私方式进行端云传输进一步保证了端云训练中的安全性。
7 支持千万级无状态设备的端云联邦学习
联邦学习是一种加密的分布式机器学习技术,它是指参与联邦学习的各用户在不共享本地数据的前提下共建AI模型,主要用于解决数据隐私和数据孤岛的问题。MindSpore Federated优先专注于大规模参与方的横向联邦的应用场景。
端云场景下的参与方是非常大量的手机或者IoT设备,其分布规模和设备不可靠性带来了系统异构、通信效率、隐私安全和标签缺失等挑战。MindSpore Federated设计了松耦合分布式服务器、限时通信模块、容忍退出的安全聚合等模块,使得任何时候只要部分客户端可用,都可以进行联邦学习任务,并解决了系统异构带来的“长尾效应”,提高了学习效率。
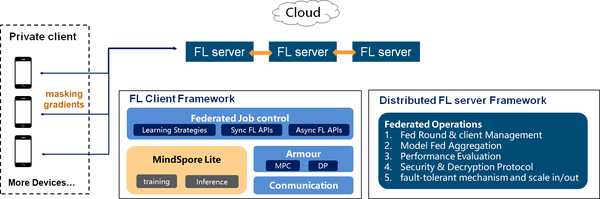
搭载于MindSpore端边云全场景统一的基础架构,MindSpore Federated将会作为华为终端的核心竞争力之一,在保护用户隐私的前提下,提供更具有个性化的用户信息决策。
8 算子库优化与扩展
推理性能优化依然是本次版本的重头戏,除了持续的ARM CPU(FP16/FP32/INT8)性能优化,ARM GPU和X86\_64的优化较之前版本也有了很大提升。GPU方面我们除了传统的算子优化,还优化了workgroup、block的切分策略,使得ARM GPU推理性能大幅提升;同时为了更好的支持PC侧推理,x86\_64从汇编层面入手,支持针对不同卷积shape的动态block切分,充分利用寄存器等硬件资源,使我们推理性能达到极致。
8.1 ARM CPU优化
ARM CPU优化依然是本版本的重点内容,在该版本我们不断完善ARMv8.2 FP16支持的算子,同时性能较上个版本有了10%左右的提升。此外新增ARMv8.2 Aarch32架构的FP16运算加速新特性,满足ARM64下不同应用程序的需求。
ARMv8.2 Aarch64架构FP16性能优化
本次版本我们持续对Aarch64架构的FP16推理性能进行优化,不断增加FP16支持的算子随着手机核心数的增多,我们不断摸索多线程下的推理时延,追求更极致的推理性能。
我们选择了开源的MNN(1.2.0)和TNN(v0.3)推理框架,在华为mete40 pro Aarch64架构下,4线程FP16推理性能测试。
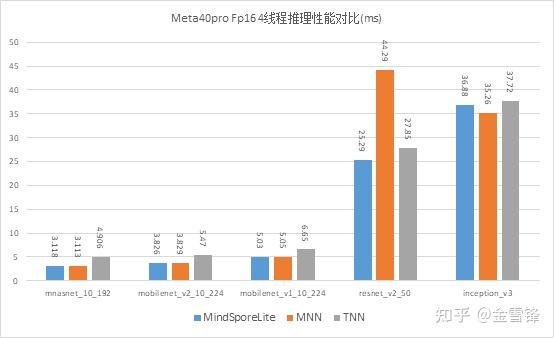
华为Mate40pro上FP16推理时延对比
ARMv8.2 Aarch32架构FP16性能优化
业界开源框架目前主流的优化依然是针对ARMv8.2 Aarch64架构下FP16运算,而ARM64系统是可以兼容Aarch32应用程序,Aarch32应用程序却无法使用Aarch64 FP16加速运算,这将导致Aarch32的应用程序速度很慢。基于此背景,MindSpore Lite新增ARMv8.2 Aarch32架构下的FP16运算优化特性,最新FP16加速运算的新特性将会打包到Arm32库中。在运行时,我们将根据硬件单元是否支持Fp16自动选择FP32或者FP16算子,极大提高我们算子库的兼容性。
MindSpore Lite已经支持了部分算子在Aarch32 架构下的FP16优化,性能方面有了很大提升,该特性已经应用在华为手机中。如下图是应用场景模型在meta40pro Aarch64和Aarch32架构下FP16推理时延的对比。
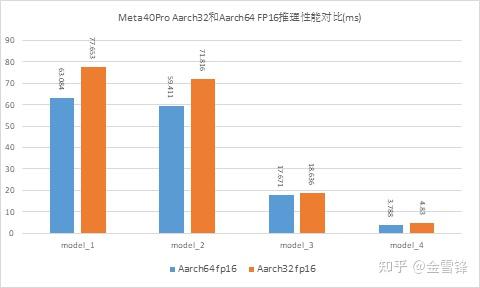
华为Meta40Pro上Aarch64和Aarch32架构下 FP16推理时延对比
8.2 ARM GPU优化
MindSpore Lite 1.3版本我们对GPU推理性能进行了重点优化,除了在算子层面进行了常规优化外,还优化了workgroup、block的切分策略,使得整体性能较MindSpore Lite 1.2在高通Adreno架构上提升20%+,Arm Mali架构上提升10%+;下图是在华为Mate40 Pro上与MNN(1.2版本)和TNN(v0.3版本)进行了GPU推理性能对比测试。
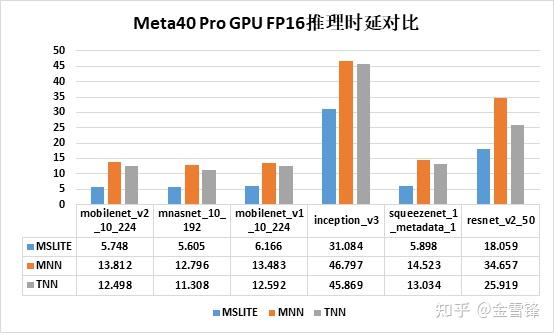
华为meta40 pro上GPU FP16推理时延对比
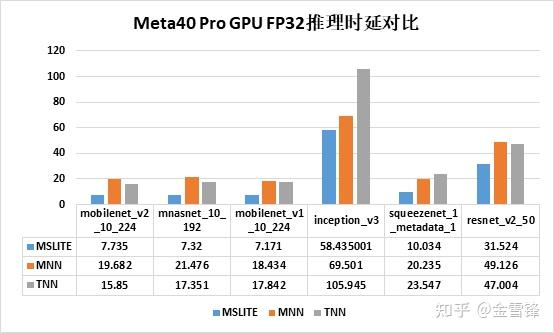
华为meta40 pro上GPU FP32推理时延对比
8.3 X86\_64 CPU优化
本次版本我们在X86\_64平台上的推理性能进行了大量优化工作,较上个版本推理时延有了10%~75%+的提升。
● 汇编层面使用SSE、AVX、AVX2等SIMD指令集加快运算速度。
● 针对最耗时的卷积操作shape不固定,我们在计算过程中可以根据不同的卷积shape动态进行计算block的切分,选择最优的重排和计算策略获得最低的推理时延,与固定block的切分方式相比内存使用和推理时延都有很大降低。
● 针对卷积层不同的shape,我们会根据shape大小选择原始的Slide-Window还是经典的Im2Col(Winograd)+Gemm算法,使用最优的算法降低我们的推理时延。
我们在Intel Core i7-8700 CPU上与OpenVINO(2021.3.394)、MNN(1.2.0)、TNN(v0.3)在几个经典CV类网络上进行单线程benchmark测试。
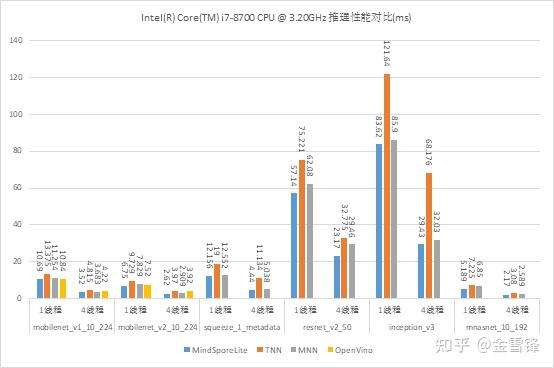
Intel Core i7-8700 CPU推理时延对比
原文:知乎
作者:金雪锋
推荐阅读
更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

