
大规模预训练模型已经在自然语言处理领域取得了巨大的成功,国内外各大人工智能巨头纷纷开始在该方向发力,其中比较有代表性的有:OpenAI的GPT[1]、华为的盘古[2]、百度的ERNIE[3]等。然而,大规模预训练模型的落地场景一直是个很大的挑战,最近,OpenAI和github、微软合作,基于CodeX[4]模型(GPT-3的编程语言版本)发布AI编程伙伴Copilot,赋能代码智能,有望成为GPT-3的首个商业化产品。那么,针对编程语言的大规模预训练模型和针对自然语言的大规模预训练模型有什么异同呢?又会带来哪些新的挑战?业界进展是怎样的?下文将逐个展开介绍。
一. 编程语言大规模预训练模型
自然语言预训练模型是为了实现在搜索、问答等自然语言领域的智能;同样,编程语言预训练模型是为了实现代码智能,如图1所示,我们希望模型能够自动完成各种各样的编程任务,从而大大提高编程效率,降低开发门槛。
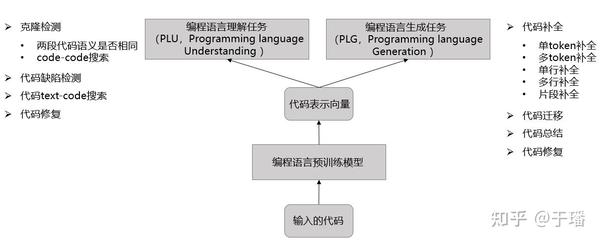
图1 各种编程任务。与自然语言领域类似,编程语言任务也可大致分为编程语言理解任务(PLU)和编程语言生成任务(PLG)
从模型输入来讲,与自然语言预训练模型相比,编程语言预训练模型的输入不仅包括自然语言(代码注释),还包括代码(Python/C/C++/JAVA等),这就导致自然语言预训练模型很难直接泛化到编程语言,需要研究专门的编程语言预训练模型。
二. 编程语言大规模预训练模型面对的挑战
与自然语言预训练模型相比,由于编程语言自身的特点,给编程语言预训练模型带来了一些新的挑战,下面简单提一下几个主要挑战:
1.更严重的OOV(out of vocabulary words)问题
和自然语言相比,代码引入新词的频率会更高(例如各种各样的变量名),这会使得OOV问题变得更加严重,如何解决或缓解OOV问题是一个很大的挑战;
2.代码的结构信息
代码通常是为了实现某种功能或算法,具有很严格的语法结构和逻辑结构,具体可以表现为抽象语法树(AST)、数据流图(DFG)、控制流图(CFG)等,这些额外的结构信息是自然语言所不具备的,如何合理利用这些结构信息提高模型效果一直是代码智能研究的主要方向之一;
3.更严格的语法约束
代码的语法约束比自然语言更严格,在代码生成中,如何保证生成的代码语法完整、正确是一个难点;
4.生成大段代码的功能正确性
在生成代码片段时(例如像Copilot一样生成函数),除了保证生成的代码语法正确完整、可执行以外,还要求功能与用户需求一致,这无疑对模型提出了更高的要求;
5.评价指标
我们在评价自然语言预训练语言模型时,通常使用困惑度作为评价指标,在生成任务时也会使用BLEU score等评价指标,但这些评价指标对编程语言是不够的。例如针对PLG问题,并不是BLEU score越高,生成的代码就质量越好、功能越正确,针对这个问题,有研究者提出了新的评价指标,如CodeBLEU,也有研究者通过Unit Test来评价模型,但都存在着缺点和限制,还有进一步研究的空间;对PLU问题,微软近期提出了Benchmark CodeXGLUE[5],感兴趣的朋友可以自行了解。
三.业界进展
目前,代码智能在工业界和学术界都得到了比较大的关注,编程语言预训练模型的应用是一个重要趋势。如图2所示,业界很多公司都开始将深度学习技术引入代码智能,其中,GPT模型基于编程语言的变体在代码补全领域取得了较大的成功。
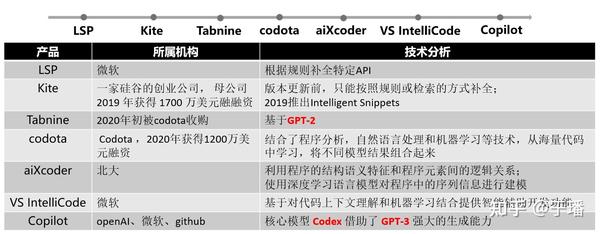
图2 代码智能工业界进展
有关代码智能的研究近年来也越来越多,下面主要介绍一下编程语言预训练模型的研究进展。
1.将编程语言当做序列——预训练Transformer Encoder(BERT/Roberta模型结构)
代表模型是CodeBERT[6],CodeBERT使用Bert的模型结构,在Roberta的checkpoint基础上继续训练。如图3所示,CodeBERT借鉴了Bert和Electra的预训练方式任务——MLM(Masked Language Modeling)和RTD(Replace Token Detection),采用多任务学习的方式,使用的数据集是CodeSearchNet数据集,包含2M (代码, 自然语言)对,其中的代码和自然语言分别是函数以及函数对应的doc\_string。
CodeBERT base模型参数量 1.1亿,large模型参数量 3.4亿,该模型虽然在下游任务上取得了一定效果,但仅仅把代码当做自然语言一样的序列处理,忽视了代码包含的语法结构和逻辑结构,仍然有一定提升空间,另外,该模型只预训练了encoder,在生成任务上效果一般。
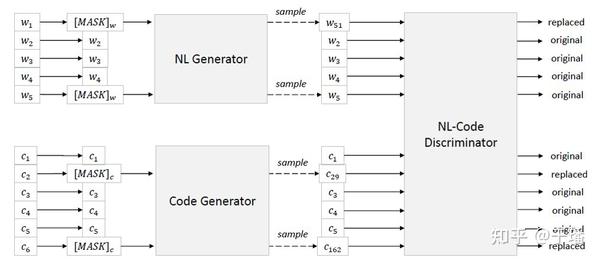
图3 CodeBERT示意图
2.将编程语言当做序列——预训练Transformer Decoder(GPT模型结构)
代表模型是GPT-C[7]和CodeX[4]。
GPT-C是GPT-2的变体,在github上收集的12亿行多语言源码上从头训练,参数量3.7亿,但该模型论文只给出了困惑度(PPL)的对比,不能很好的反映模型能力;
CodeX是openAI在GPT-3基础上训练的编程语言预训练模型,模型参数量120亿,训练数据集大小159G,既可以从头训练,也可以基于120亿参数GPT-3继续训练,按论文中的说法,二者效果相当,但继续训练的话收敛更快,因此论文中作者都采取了继续训练的做法。文中作者构建了一个测试数据集——HumanEval,采用Unit Test的方式评价模型。CodeX是目前最火的编程语言预训练模型,关于该模型,如果大家感兴趣的话,后面可以单独开文章介绍一下。
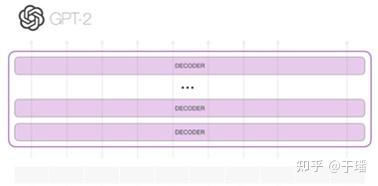
图4 GPT-2模型结构
3.将编程语言当做序列——预训练Transformer Encoder + Decoder(BART/T5模型结构)
代表模型是PLBART[8]。该模型基于BART结构训练,从Github和StackOverflow收集数据,参数量1.4亿。
4.引入结构信息——预训练过程中利用数据流图
代表模型是GraphCodeBERT[9],该模型在CodeBERT的基础上引入结构信息(数据流图),模型结构如图5所示。该模型在CodeBERT的checkpoint上继续训练,训练任务改为MLM和两个跟结构有关的任务(变量表示对齐和数据流图边预测)。
GraphCodeBERT参数量和CodeBERT相同,base模型1.1亿,large模型3.4亿,该模型在预训练、finetune和推理时都需要数据流图输入,一定程度上会增加开销。
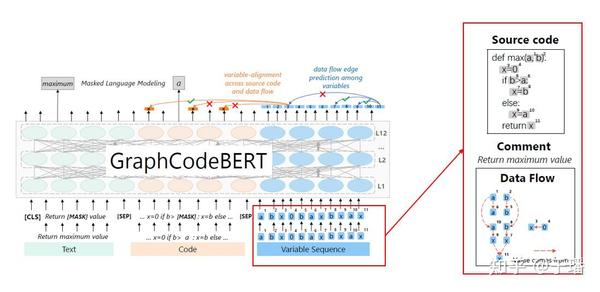
图5 GraphCodeBERT模型结构
综上所述,大规模预训练模型使代码智能前进了一大步,CodeX对每个问题,生成时采样多个sample,并选择mean log-probability最大的sample,结果针对44.5%的问题都可以生成能够通过Unit Test的函数,效果还是非常令人惊艳的;但是,尽管学习了海量的代码,但与人类相比,CodeX仍然有较大差距,就像论文中提到的,一个完成基础计算机课程的学生解决编程问题的能力可能就已经超过了CodeX,因此,编程语言预训练模型仍然有较大的研究空间;此外,大规模预训练模型推理时所需要的计算资源和耗时对该技术的推广构成了一定的障碍,如何进行大规模预训练模型的轻量化和高性能推理也将是一个挑战。
参考文献
[1]Language models are few-shot learners. 2020.
[2]PanGu-$\\alpha $: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation.2021.
[3]ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation. 2021.
[4]Evaluating large language models trained on code. 2021.
[5]CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation. 2021.
[6]Codebert: A pre-trained model for programming and natural languages. 2020.
[7]Intellicode compose: Code generation using transformer. 2020.
[8]Unified Pre-training for Program Understanding and Generation. 2021.
[9]Graphcodebert: Pre-training code representations with data flow. 2020.
本文转自:知乎
作者:于璠
推荐阅读
更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

