
AlphaFold开源后(后续若不做特殊说明,AlphaFold均指AlphaFold 2),很多研究团队都在分析、重现和尝试进一步提升。相比于AlphaFold的推理运行起来,AlphaFold的训练重现要复杂得多。主要挑战在于:
1)AlphaFold开源的是的推理代码,训练的部分没有公开,但给出了深度网络结构和主要训练超参;
2)AlphaFold训练数据集的构造对训练出好效果非常重要但非常耗时,包含原始训练序列MAS和模型收敛后作为训练样本扩展序列的MSA的搜索,和Template的搜索。每条MSA和Template的搜索从数十分钟到数小时不等,计算成本非常高。
我们尝试从开源的推理代码分析开始,构建典型的训练代码:
1、整体结构
AlphaFold包含三大部分:
1)Data蛋白质多序列比对和模板数据处理,
2)Model深度学习网络部分,
3)Relax预测结果再处理部分。
AlphaFold基于Jax实现,在下表给出了在AlphaFold中用到的Jax和Jax之上NN相关的库用到的主要的API和功能。 在Data和Relax部分,是AI无关的,下表简洁的罗列了数据集和对应的处理工具。
**

**
如果对Jax不熟悉,下图给出了一个基于Jax构建应用算法的简单的模块关系:
**
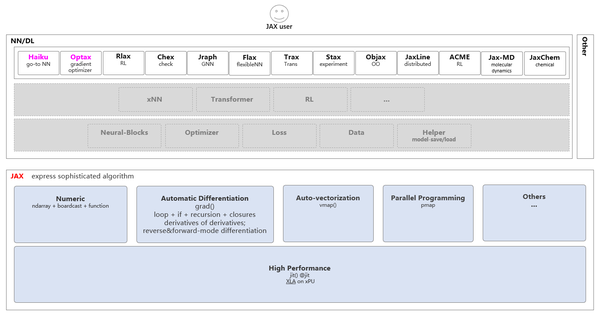
**
在构建训练代码前,需对AlphaFold的整个流程了然于心。下面三幅图,是中间AI相关的部分最主要的三幅图。为了理解方便,在图中用多于原图的部分-追加文字,标明了缩写的含义、主要模块之间的流动的数据、和Recycling具体的实现对应的代码。
**

**
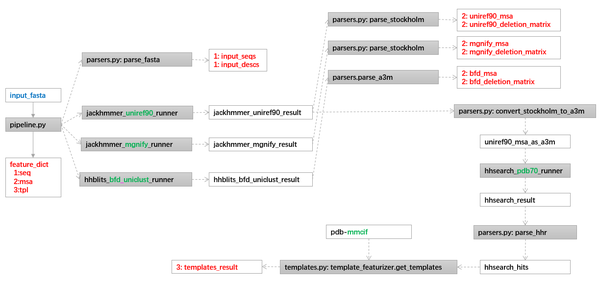
2、数据处理
训练的数据处理,可以基于推理的数据处理增补,数据集包含:
原始数据:
genetics:
UniRef90: v2020\_01 #JackHMMER
MGnify: v2018\_12 #JackHMMER
Uniclust30: v2018\_08 #HHblits
BFD: only version available #HHblits
templates:
PDB70: (downloaded 2020-05-13) #HHsearch
PDB: (downloaded 2020-05-14) #Kalign(MSA)
派生数据:
按照论文的技巧,sequence-coordinate数据对不仅有来自于PDB原始的17万多的数据的清洗,还有在训练收敛后,挑选了置信度高的35万左右的数据。这部分的数据的产生,可以从自己的模型训练收敛后排序选择;也可以直接利用AlphaFold提供的模型参数,直接推理无结构的序列来选择;还可以从AlphaFold公开的预测数据集中下载排序选择,从而节省计算资源。
数据处理部分的代码结构:
run\_alphafold.py
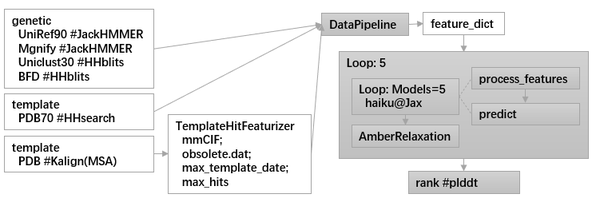
data\_pipeline.py
如下是预测部分的输入数据列表(样例):
predict-input:
'aatype': (4, 779),
'residue_index': (4, 779),
'seq_length': (4,),
'template_aatype': (4, 4, 779),
'template_all_atom_masks': (4, 4, 779, 37),
'template_all_atom_positions': (4, 4, 779, 37, 3),
'template_sum_probs': (4, 4, 1),
'is_distillation': (4,),
'seq_mask': (4, 779),
'msa_mask': (4, 508, 779),
'msa_row_mask': (4, 508),
'random_crop_to_size_seed': (4, 2),
'template_mask': (4, 4),
'template_pseudo_beta': (4, 4, 779, 3),
'template_pseudo_beta_mask': (4, 4, 779),
'atom14_atom_exists': (4, 779, 14),
'residx_atom14_to_atom37': (4, 779, 14),
'residx_atom37_to_atom14': (4, 779, 37),
'atom37_atom_exists': (4, 779, 37),
'extra_msa': (4, 5120, 779),
'extra_msa_mask': (4, 5120, 779),
'extra_msa_row_mask': (4, 5120),
'bert_mask': (4, 508, 779),
'true_msa': (4, 508, 779),
'extra_has_deletion': (4, 5120, 779),
'extra_deletion_value': (4, 5120, 779),
'msa_feat': (4, 508, 779, 49),
'target_feat': (4, 779, 22)如果复用AlphaFold的代码实现train逻辑,输入数据上还需要增加一些字段的处理:如pseudo\_beta等target信息,当然可以另行修改自己的框架的表示。
3、主体网络
文首附上了主体网络的结构图,AlphaFold的代码实现部分,结构如下:
model.py
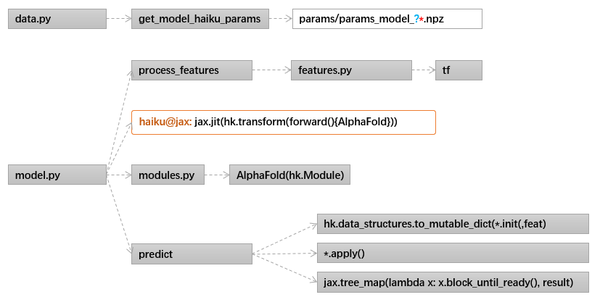
整个模型的构建和关键点,如下图:

关于AlphaFold技术上什么点,让效果这么好,网上解读甚多。最客观的解读其实论文的对主要技术点的消融实验,很能说明问题。如果非要最简洁的总结,我们认为:让各种各层信息在整个网络中来回流动是最重要的,各种信息包含Seq + MSA+ (Pair) + Template,各层信息的各种功能流动是指各种Iteration + Recycling + Multiplication + Production。
在训练代码的构建部分,由于是train的逻辑,在AlphaFold的构造参数中,需要设置:is\_training=True, compute\_loss=True,这样才会讲各层各处的复合loss给返回出来,计算梯度和让优化器优化权重。
4、结构精化
5、训练构建
在数据准备好后,要实现自己的训练,有两种做法:在不修改网络结构的情况下,可以从AlphaFold公开的模型参数上开始进一步训练优化;如果要修改网络,一个最基本的训练逻辑,通过实现两部分可以开始从头训练:
- 构建自己的数据集和加载器。最简单的做法,是从pipeline.DataPipeline开始修改,增加上训练所需的target相关的信息的读取。
- 类似于推理的RunModel,实现自己的TrainModel,其重要逻辑包含:模型的代码直接利用开源的推理的:
modules.AlphaFold(model\_config.model)(batch, is\_training=True, compute\_loss=True, ensemble\_representations=True, return\_representations=False).
优化器用optax@jax实现。
如上,可以基于现有推理代码,构建一个最简单的训练版本。
原文:知乎
作者:金雪锋
推荐阅读

