
HotChips全称为A Symposium on High Performance Chips,每年8月份举行。不同于其他会议以学术研究前沿为主,HotChips是一场产业界的盛会,以各大处理器设计公司的最新产品或在研产品为主。IBM、Intel、AMD、ARM等都是HotChip会议的常客。HotChips能够让从业者了解产业发展趋势。
由于疫情的影响,HotChips2020改为在线进行。原本昂贵的参会成本降低到了100美元。组织者还贴心地提供了回放功能,不需要熬夜就可以观看。除了不能与业界大佬们面对面交流之外,参会效果还是很不错的。目前,HotChip的回放通道仍然开启。
HotChips2020一共规划了8个Section,覆盖了服务器处理器、移动处理器、边缘计算和传感、GPU和游戏架构、FPGA和可配置架构、网络和分布式系统、机器学习训练以及机器学习推断。Section的规划还是比较传统的。
HotChips没有论文集,只提供幻灯片。两天的会议一共进行25篇演讲,其中有23篇来自产业界,只有2篇来自学术界(分别来自哈佛大学和苏黎世理工大学),而且都与AI加速器有关。另外会议还接受了11篇Poster,以学术界成果为主。会议还安排了2个主题演讲,分别由Intel架构师Raja M. Koduri带来的《No Transistor Left Behind》和DeepMind杰出工程师Dan Belov带来的《AI Research at Scale-Opportunities on the Road Ahead》。
个人比较关注于处理器相关的三个Session:服务器处理器、移动处理器以及边缘计算和传感。
服务器处理器
Section1有4篇演讲,分别涉及Intel的IceLake-SP架构、IBM的POWER10处理器和z15处理器以及Marvell的ThunderX3处理器。
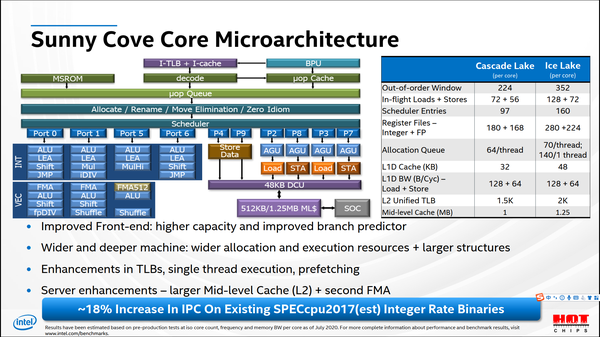
Icelake-SP架构使用10nm+工艺,采用Sunny Cove大核。相对于Cascake Lake,Ice Lake的IPC提高了18%,主要原因是大比例增加的各种资源,比如乱序执行窗口、物理寄存器、L1 Cache等。演讲的主要内容集中于IceLake-SP的系统架构,主要改进包括:可扩展的功耗控制、系统管理机制,可以减少SoC管理的复杂度,改进响应时间;对Cache机制的调整,缩短Cache的响应时间,提高通信带宽;从电路、算法和架构层面改进DVFS的效果。Intel将处理器核的电压频率调整时间缩短到0,体现了Intel的电路优化的根基。
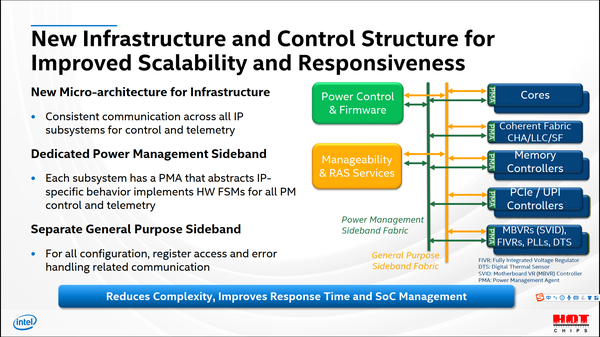
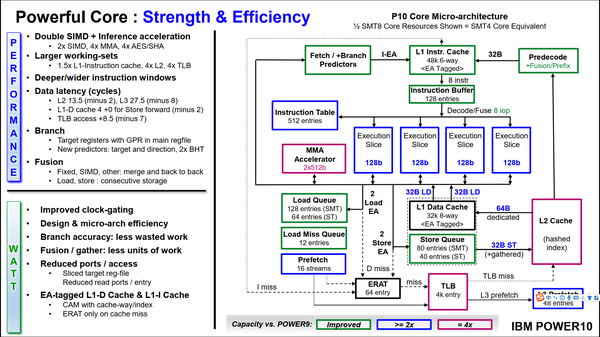
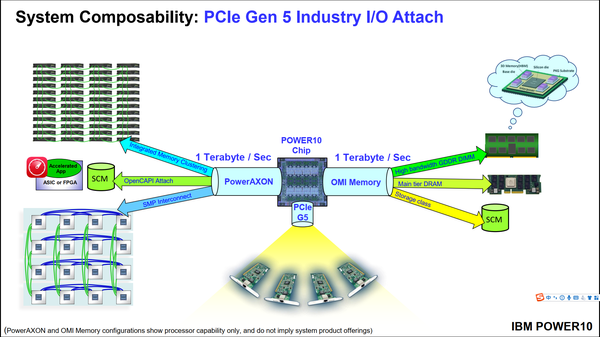
Power10是IBM的下一代架构,预计年底正式发布,采用7nm工艺。每块芯片可以集成16个核心,每个核心提供支持8线程。相对于前代产品,仍然是通过资源扩展来获得性能提升,有些模块的资源甚至被扩大了4倍(TLB、L2cache等)。IBM用了将近一半的篇幅介绍其PowerAXON接口和Open Memory Interface接口,这个接口的最大特点是高带宽和兼容性。两个接口都可以达到1TB/s的带宽。PowerAXON接口可以和其他芯片组成16块芯片的集群,可以连接到ASIC加速芯片集群,还可以连接到刀片服务器集群;OMI接口可以连接到SCM、DRAM以及GDDR DIMM。互联总线的兼容性为Power10构成的系统提供了强悍的可扩展性。
ThunderX3是Marvell的下一代ARM服务器处理器,预计60到96个core,每个core支持4SMT。处理器核采用Arm v8.3核芯,并支持部分v8.4/v8.5的特性。相对于ThunderX2,ThunderX3在资源和算法方面都进行了改进。在演讲中展示了各方面优化对于性能的贡献,其中比较重要的优化包括执行能力、ROB资源、分支预测算法、Cache容量等方面。ThunderX3的片上互联采用三环结构,每一个半环上连接5个节点,每个节点连接4个核心。
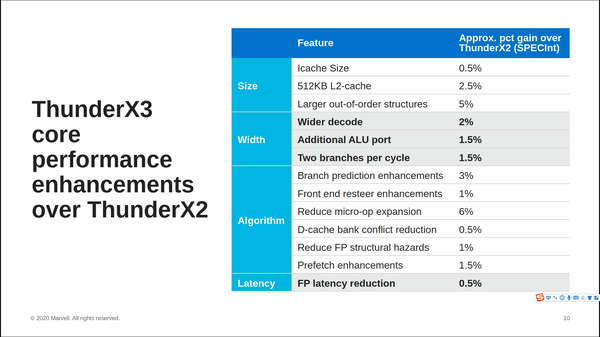
Z15则是当前最新的服务器整机架构,详细技术细节可以参见IBM在ISSCC2020上的论文和介绍,也可以参见本人年初撰写的ISSCC2020处理器巡礼。
面向服务器的处理器,设计目标就是提高性能。为了实现高性能,必须要提高处理器流水线的吞吐率以及提高访存和互联吞吐率。为了达到这个目的,最有效的实现方法就是在制造工艺的推动下,集成更多的资源,将处理器做得越来越大、越来越多。
移动处理器
Section2有两篇演讲,分别是AMD的RyzenTM 4000和Intel的Tiger Lake。这两款处理器都是面向桌面机和笔记本的。与服务器处理器相比,移动处理器需要集成图形处理能力和更多的外设接口。
两个演讲更像是产品发布会,介绍的技术细节不多。演讲中都只用了很小的篇幅介绍处理器核的微架构。演讲中介绍的大部分特性都是SoC系统架构层面的,比如互联结构、支持的外围接口、功耗管理方法等。
边缘计算
Section3有三篇演讲,分别是平头哥的玄铁910,ARM的Cortex-M55和Ethos-U55,以及哈佛大学设计的一款贝叶斯推断加速器。
玄铁910是国内唯一入选HotChips的处理器,推荐各位看平头哥在ISCA2020上发表的论文《Xuantie-910: A Commercial Multi-Core 12-Stage Pipeline Out-of-Order 64-bit High Performance RISC-V Processor with Vector Extension》。
ARM的Cortex-M55和Ethos-U55是面向AI终端市场的处理器核以及AI加速器。ARM希望由这两个IP的组合能够加速面向AI特定应用场景的SoC的开发。演讲的主要内容偏重于Ethos-U55以及系统集成。
贝叶斯推断加速器的演讲则完全与加速器设计为主。不在本文的讨论范围之内。
主题演讲
会议第一天的主题演讲由Intel的首席架构师Raja M. Koduri带来的《Left No Transistor Behind》。
演讲首先展望了未来,指出智能互联的设备数量会达到100B,数据会达到175ZB,需要超极智能来应对海量的数据和业务。
随后,演讲指出处理器的设计仍然可以为业务提供巨大的空间。一方面是优化软件充分挖掘硬件的能力;另一方面是制造工艺(比如3D堆叠等)仍然可以给硬件设计提供巨大的空间,提高芯片集成度,降低功耗等。
接下来的演讲介绍了Intel对于未来的愿景规划。Intel认为。在未来,通用处理器不会一统天下,多种计算资源(CPU、GPU、AI加速器、FPGA等)需要协同使用,有必要通过分层抽象统一调用接口。硬件的范畴将不仅仅包括处理器或专用芯片的设计,而是包括了驱动、OS、虚拟机以及中间件。软件的范围则是丰富多彩的业务软件和应用软件。Intel将构建包含了工艺封装、计算单元架构、存储、互联、安全和软件的完整体系。如果这套愿景规划成功,那么Intel将从一个芯片制造商转换为计算基础设施提供商(这就是新基建啊)。
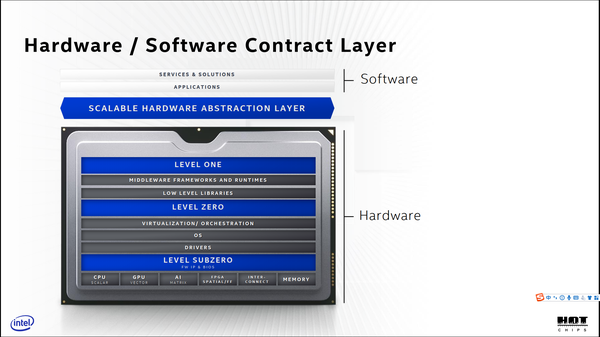
主题演讲给出的最重要的启示在于,处理器和软件的开发都是由实际业务驱动的,而处理器的设计又应该是由软件驱动的。当处理器设计已经确定的时候,软件可以作为粘合剂来适配处理器和业务。但是在处理器设计流程中,软件和硬件的关系是不应该颠倒的。
今年有机会连续关注了ISSCC、ISCA以及HotChips三个会议中产业界介绍的处理器设计,有一些个人的片面间接。
系统架构vs微架构
对于处理器领域来说,很多概念需要正本清源。第一个需要着重说明的就是微架构和系统架构。虽然都是架构设计,但是差别很大。微架构指的是处理器内部流水线的架构设计,也就是“取指-执行-发射-执行-回写-退休”这一个过程。系统架构的范围比微架构大得多。系统架构原本指的是整个计算机系统的架构,包括了CPU、总线、外设等构成完整系统。随着芯片集成度的提高,单个芯片也能实现一个完整系统,也就是片上系统(SoC)。SoC的系统架构包括内存系统、互联结构、加速器以及系统管理等等。所以,系统架构和微架构的侧重点和覆盖范围的区别还是很大的。
2010年之前,是微架构的黄金时代,各种微架构的概念层出不穷。不过最近10年,处理器微结构的设计逐渐趋同,已经形成了以超标量、乱序执行等为主要特征的CPU微架构,还有多核缓存、分支预测、同时多进程等典型特性。不仅仅是高性能CPU,甚至嵌入式和边缘计算场景的处理器也开始具备这些特征。此次HotChips2020中介绍的处理器微架构都符合这一特征。各家处理器的微架构非常相似,甚至关键的调度和预测算法都是相同的,相互对标的产品的架构参数也很接近的。
这种情况是处理器追求通用性的必然结果。如果按照集成电路的通用性和专用性做一个坐标轴的话,那么现在讨论的这种处理器就是各种集成电路中最为通用的一种。通过软件的参与,处理器可以完成世界上绝大部分的工作。对于通用性的要求,使得处理器的微架构需要满足对各种类型程序的支持,同时也失去了对特性应用优化的动力。正如Intel在演讲中提到,IceLake是对于所有类型的服务和应用都很平衡的处理器。
2010年之后,在“多核、众核”以及“异构”两大概念的推动下,系统架构的研究成为热点。各类处理器的系统架构的区别还是很明显的。
- 对于服务器处理器,设计目标主要是冲刺高性能。在微架构优化空间缩小的情况下,需要通过充分挖掘线程级并行(TLP)来获得更高的性能。所以,服务器处理器以众核同构集成为主,并通过环形或者Mesh互联结构来提高互联带宽,再通过优化cache协议来提高有效的访存带宽。在服务器处理器中集成一些特定业务场景的加速器也是一个明显的潮流。
- 对于移动端处理器,设计目标是为多功能场景提供能效最高的解决方案。常见的架构是4到8个不同规格的处理器(大-小核或大-中-小核)通过共享内存集成。同时集成在芯片中还有图形处理器、视频处理器、音频处理器、以及AI处理器等。这些加速器的存在保证了芯片在多媒体、AI等场景的用户体验。
- 对于边缘计算处理器,处理器已经完全不是重点了。设计重点完全转换到加速器电路上。处理器是用来处理不适合加速器电路完成的工作,比如控制类和交互类的事务。边缘计算场景处理器的微架构有可能不会遵循目前流行的处理器微架构,因为在有些特定场景,处理器的功耗比性能更加重要。单一边缘计算处理器的应用场景比服务器或移动端处理器要狭小很多,从而可以针对业务需求进行优化和调整。
随着IOT和AI的蓬勃发展,面向不同场景的SoC的系统架构会有明显的不同。系统架构师的主要工作就是,针对产品的应用场景,选择最合适的IP并将其集成为SoC。这也就是大神为什么称“未来的十年(应该还剩八年)是体系架构的黄金十年的原因”。
工艺、电路、架构、功能
私以为,支撑处理器指标(性能、功耗、面积)的主要因素包括四个方面, 分别是制造工艺、电路设计、系统架构和功能实现。
制造工艺是决定芯片的规模、功耗和频率的关键。集成电路设计领域有一个显著的特点,其能力边界并不是由设计师本身决定的,而是由半导体领域决定的。设计师只能做到最大程度地挖掘制造工艺给集成电路设计划定的边界。在处理器行业,鲜有通过架构设计来弥补工艺代差的例子。更多的例子都是通过抢占工艺制高点来提高芯片的各种指标,尤其在国内厂商更加常见。目前,性能最好的处理器都尽可能使用最先进的工艺,比如TSMC的7nm或5nm。在工艺方面的失守会给处理器设计带来很大的压力。
在本文中,电路设计特指的是在标准单元甚至以下层面进行的电路设计,比如定制SRAM和计算电路等。对于处理器来说,提供更多的资源(分支预测表容量、ROB队列深度、Load/StoreQ深度以及Cache容量等)对于提升处理器性能的作用远远大于处理器微架构的改进。可以看到,Intel每一代处理器的Cache容量都有至少50%以上的提升。资源的提升除了借助于工艺之外,还要借助于电路设计。在今年的ISSCC上,AMD和IBM都提到了他们与制造商合作,在SRAM上所做的优化。国内厂商即便使用了相同的工艺,也很难做到相同的资源容量和频率,这其中的差距就在于电路设计。
制造工艺和电路设计限定了处理器设计的边界,系统架构和微架构的目的就是挖掘这些边界,在性能、功耗和频率中某方面做到极致,或者在各个方面之间平衡。处理器的微架构已经基本稳定,国内处理器公司要做的是补课,做到不缺重要特性。系统架构还有很多的探索空间。架构设计可以利用的IP和参考的资料也很多。而且现在已经出现了系统级设计(ESL)的工具平台,比如Synopsys的Platform Architecture,以及强大的emulation工具,比如Zebu和Haps。搭配出一种系统架构的难度正在降低。近两年,国内厂商对于系统架构工程师的需要有所增加,但是对于微架构工程师的需求依然很小。
功能实现不仅仅包括通过加速器给片上系统添加功能,也包括实现各种调度和预测算法等。功能实现和电路设计的区别在于,功能实现利用标准单元实现逻辑,属于设计流程中的前端设计范畴,而电路设计则需要从晶体管级别重新设计电路,属于设计流程中的物理设计范畴。功能实现有完善的设计流程和设计工具可用。功能实现对于产品来说很重要。通过实现某一种加速器,可能会使得产品在某一个领域获得很好的市场占有率。
打破软件和硬件的边界
每到9月份,大家都会讨论人才培养和校招的问题。最近的一个热点新闻是集成电路成为一级学科,而且将集成电路认定为交叉学科。这是非常合理的。在前面提到的制造工艺、电路设计、系统架构和功能实现四个方面,我们都面临着产业链不完整,骨干人才缺乏,后备人才薄弱的问题。传统人才培养方法的主要缺陷在于将产业链上各个环节需要的人才放到了不同的专业培养。交叉学科有助于打破这种的局面,集合多学科优势力量发展集成电路。不过,集成电路学科更要打破狭义的硬件思维。
狭隘的硬件定义认为芯片设计流程中的步骤才算是做集成电路。形象地说,只有用EDA工具和HDL打交道的,才算是集成电路。而且芯片工程师很多时候会排斥软件开发手段的学习。但是集成电路专业引入一些软件方面的教育是很重要的,尤其是处理器设计领域。
第一,面向所有设计领域,硬件工程师都需要掌握一定的敏捷开发手段。具体来说,集成电路专业的学生需要具备编程思维并掌握一种脚本语言,比如Perl或Python。这些技能可以在实际工作中显著提高开发效率。
集成电路设计软件化的趋势还在逐步增强。从用HDL替代版图,到电子系统级设计,再到近两年很热门的HDL语言(Chisel、SpineHDL等)。其实在Chisel之前,软件思维已经在产业界得到了应用。Python、Perl等脚本语言已经在工业界大量用于实现重复代码生成、自动端口连接等功能,提高设计效率。Tcl脚本就是EDA工具的专用脚本语言,并于编写自动的设计流程。 此外,自动化验证也大量使用敏捷开发手段,比如自动生成测试向量、自动分析测试结果或者测试日志等。近来,各种软硬件联合验证手段的广泛应用也要求了硬件工程师不能仅仅聚焦于HDL。不过,集成电路设计专业对于这一方面能力的培养还是很薄弱的。新的设计方法学很难进入大学的课堂,学生更难有实际观摩和操作的机会。
第二,针对处理器设计领域,计算机系统和软件的背景知识更加重要。处理器与其他集成电路的最大区别就是处理器需要执行软件的。处理器的优化原动力不是硬件,而是软件程序。
边缘计算处理器的设计与其应用场景绑定关系很强,设计重点已经转移到了面向应用场景而增加的特定加速器。服务器处理器虽然是通用性最强的处理器,但是应用场景的影响也是很明显。为了应对大量事务响应类的应用(比如数据库查询、网络响应),IBM支持了8SMT(IBM的处理器分为资源相同的两个子部分,每个子部分支持4SMT)。为了应对安全应用等场景,IBM在芯片中集成一些加解密和加解压的加速器。处理器设计工程师还是需要对其应用场景有一定的理解才能走得更远。
说远一点,各类集成电路的设计都与其应用场景有关系。给集成电路设计专业的学生培养所有应用领域的知识是不现实的。那么吸引其他领域的学生进入集成电路领域,针对特性领域设计集成电路,也是非常重要的。
集成电路学科的设置,要避免强化狭隘的硬件思维。集成电路设计专业的学生也要培养一定的软件思维和敏捷开发能力,同时还需要吸引各领域背景的人才进入集成电路领域。
结语
以上是我根据有限信息的自我观察,难免有不全面不成熟之处,请指正。
END
知乎:https://zhuanlan.zhihu.com/p/200936940
推荐阅读
更多内容请关注其实我是老莫的网络书场专栏

