
6.5 流控机制的介绍(Introduction to Flow Control Mechanism)
6.5.1 整体说明(General)
协议规范定义了流量控制机制所要求的寄存器、计数器,以及一系列的机制用于报告(reporting)、追踪(tracking)和计算(calculating)一个事务是否可以被发出。这些元素并不是必需的,它们的实际实现是由设备的设计者来决定的。本节将介绍协议规范模型,并解释相关概念和对需求进行定义。
6.5.2 流控相关元素(The Flow Control Elements)
图 6‑8 说明了用于管理流量控制的元素。图中展示了在连路上单向传输的事务,而另一组这些流控元素则支持相反方向的传输。每个元素的主要功能都会再下面的内容中列出。虽然对于全部的 6 种接收 buffer 都重复有这些流控元素,但是为了简单起见,在本例子中仅考虑 Non-Posted Header 流控。
与管理流控相关的最后一个元素是流控更新 DLLP(Flow Control Update),它也是在链路正常传输期间唯一可使用的流控包。FC Update 包的格式如图 6‑9 所示
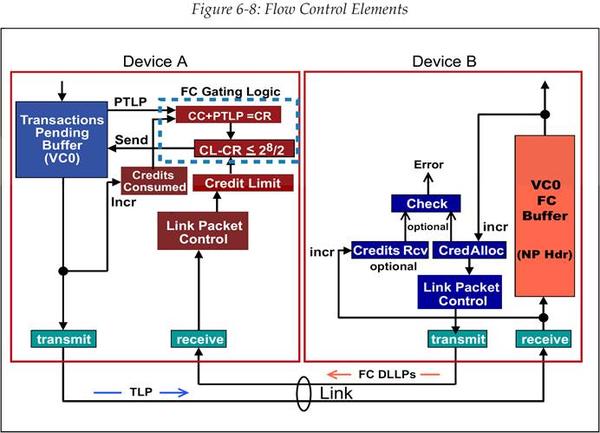
图 6‑8 流控元素

图 6‑9 流控 DLLP 的类型和包格式
6.5.2.1 发送方流控元素(Transmitter Elements)
- 事务等待缓冲区(Transactions Pending Buffer):把将要发送进统一虚拟通道的事务暂存起来。
- Credit 消耗计数器(Credits Consumed counter):该计数器是记录发送给对端当前类型 Buffer 的所有事务的 Credit 总和(也就是消耗了接收端多少 Credit),这个计数值也可以被缩写成“CC”。
- Credit 额度计数器(Credit Limit count):该计数器的初始值由对端接收者相应类型的 Buffer 大小而决定。在初始化之后,对端接收者会定期的发送流控更新包(FC Update),以便在接收方 Buffer 可用时更新流控 Credit。这个值可以被缩写为“CL”。
- 流控门控逻辑(Flow Control Gating Logic):它用于进行计算来确定对端接受者是否有足够的流控 Credit 来接收等待发送中的 TLP(Pending TLP,PTLP)。本质上来说,这个逻辑就是检查 CREDITS_CONSUMED(CC)加上下一个 PTLP 所需要消耗的 Credit 是否大于 CREDIT_LIMIT(CL)。协议规范中定义了下面的方程,以此来完成上述的检查,方程中所有的值的单位都是 Credit。
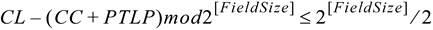
关于应用此方程式的例子,请参阅 6.6 中的“Stage 1 – Flow Control Following Initialization”一节。
6.5.2.2 接收方流控元素(Receiver Elements)
- 流控缓冲区(Flow Control Buffer):储存输入的 Header 或者数据。
- Credit 分配计数(Credit Allocated):记录已分配(可用)的全部的流控 Credit 数量。它是由硬件进行初始化的,反映了已分配的流控 Buffer 的大小。这些 Buffer 会在事务到达时被填充,但是填充进去的事务最终都会被接收端取出,也就是从 Buffer 中移除。当它们被移除时,这部分的 Buffer 空间 Credit 数量将会被加到 CREDIT_ALLOCATED 计数值上。因此这个计数器会记录并表征当前可用的 Credit 数量。
- 已接收 Credit 计数器(Credit Received counter,optional):这是一个可选项,它用于记录进入流控 Buffer 的所有 TLP 的总 Credit 数量。当流控功能正常时,CREDIT_RECEIVED 计数值应该小于等于 CREDIT_ALLOCTED 计数值。如果并未满足这二者的“小于等于”条件,那么就会发生 buffer 溢出并检测到出错。协议规范推荐设计者实现这一可选的机制,并且需要注意的是这里若出现违例则应该将其视作是一个 Fatal Error,即非常严重的错误。
6.6 流控示例(Flow Control Example)
接下来将会以 Non-Posted Header 流控 Buffer 作为例子进行讲解,并尝试捕捉出在多种情况下流控实现的细微差别。对流控的讨论将会分为如下几个基本阶段:
- 阶段一:在初始化之后紧跟着传输一个事务,并对其进行追踪,以此来解释流控元素中的计数器和寄存器的一些基本操作。
- 阶段二:发送方发送事务的速度大于接收方能处理事务的速度,使得接收方 Buffer 被填满。
- 阶段三:当计数器翻转到 0(持续增大后回到 0),流控机制依然可以正常工作,但是需要考虑几个问题。
- 阶段四:接收方可以对 Buffer 溢出错误进行检查,这是一个可选项。
6.6.1 阶段一——初始化后的流控(Flow Control Following Initialization)
一旦流控初始化完成后,设备就已经准备好进行正常工作了。我们的示例中的流控 Buffer 大小为 2KB,且种类为 Non-Posted Header Buffer,因此 1 个 Credit 代表 5dwords 大小,也就是 20Bytes。这意味着可用的流控单位数量为 102d(66h)。图 6‑10 显示出了涉及到的流控元素,包括流控初始化后各计数器和寄存器的值。
当发送方准备好要发送一个 TLP 时,它必须首先检查流控 Credit。我们给出的例子会比较简单,因为发出的数据包有且仅有一个 Non-Posted Header,它永远只会需要 1 个 FC Credit 即可,并且我们也事先假设这个事务中不存在数据荷载。
关于 Header Credit 的检查使用的是无符号算术(2 的补码,2’s complement),它需要满足以下公式:
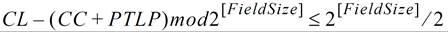
代入图 6‑10 中所示的值得到:
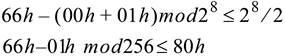
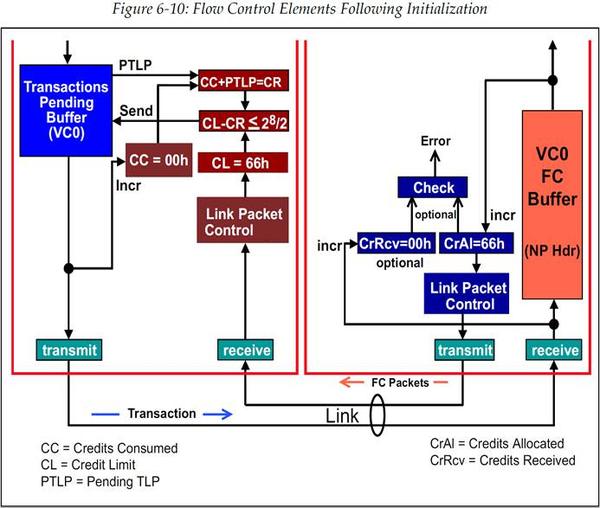
图 6‑10 初始化后的流控元素
在本例中,将当前 CREDITS_CONSUMED 计数值(CC)加上 PTLP 所需的 Credit(Header 需要 1 Credit,也就是 PTLP 所需的 Credit 数量=01h),以此来确定 CREDITS_REQUIRED(CR),也就是 00h+01h=01h。然后再用 CREDIT_LIMIT 计数值(CL)减去 CREDITS_REQUIRED(CR),这样就能确定是否有足够的可用 Credit。
下面的描述包含了对利用 2 的补码(就是计算机网络中熟知的补码,另一个 1 的补码其实是反码)进行减法的简要回顾。当使用 2 的补码进行减法计算时,将要减去的数先转换为反码(1 的补码)再加 1,这要就得到了减数的补码(2 的补码)。然后再将被减数与减数的补码(2 的补码)相加,并丢弃最高位进位。
Credit 检查:

CR 转换为 2 的补码:

CR 的 2 的补码加上 CL:

结果是否小于等于 80h 呢?是的。减法运算后的结果小于等于计数器最大值的一半,这里是用模 256 的计数器进行记录的,因此最大值的一半就是 128,满足此条件我们就认为接收 Buffer 有足够的空间,可以发送当前的数据包。这其中只使用一半的计数器值的做法可以避免潜在的计数错误的问题,参阅“Stage3—Counter Roll Over”一节。
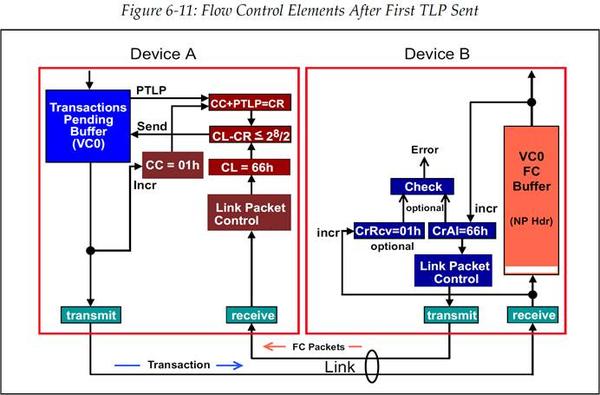
图 6‑11 第一个 TLP 发送后的流控元素
6.6.2 阶段二——流控 Buffer 已满(Flow Control Buffer Fills Up)
假设现在接收方已经有一段时间没有从流控 Buffer 中移除事务了,或许是 Device Core 繁忙,无法处理事务。最终流控 Buffer 完全被填满,如图 6‑12 所示。此时如果发送方又希望发送一个 TLP,那么它先进行流控 Credit 检查:
Credit Limit(CL)=66h
Credits Required(CR)=67h
进行 CL-CR 无符号减法运算,也就是减数转换为 2 的补码的加法运算:
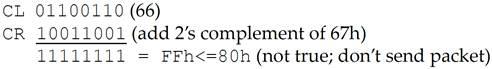
不难发现 FFh<=80h 并不成立,因此不能发送数据包。
这个通道会一直被阻塞,直到发送方接收到 Update Flow Control DLLP(更新流控 DLLP),这个 DLLP 将 CREDIT\_LIMIT(CL)的值更新为 67h 或者更大的值。当新的值存入 CL 寄存器时,发送方的 Credit 检查就可以通过了,也就可以发送下一个 TLP 了(Header 只占 1 个 Credit)。
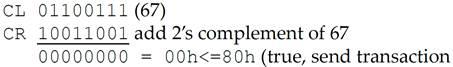
00h<=80h 成立,可以发送数据包。这里之所以 CREDIT\_LIMIT 值加 1 就够用是因为我们是使用 Non-Posted Header 流控 Buffer,Header 只占 1 个 Credit。
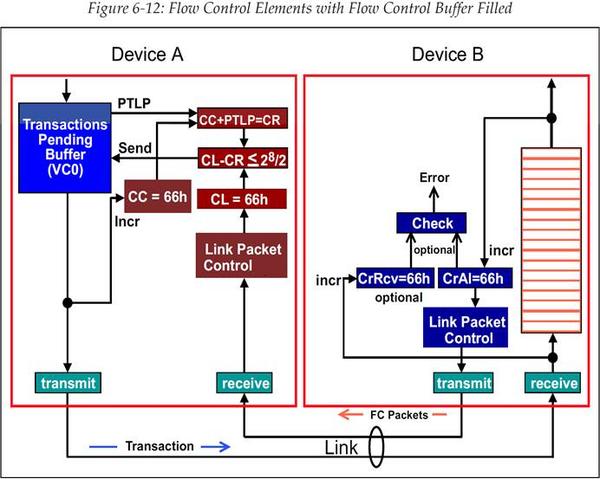
图 6‑12 流控 Buffer 填满后的流控元素
6.6.3 阶段三——计数器翻转为 0(Counters Roll Over)
由于 Credit Limit(CL)和 Credit Required(CR)计数只会向上增加,它们最终会翻转为 0。当 CL 翻转而 CR 还没翻转时,Credit 检查(CL-CR)就会出现较小值的 CL 减去较大值的 CR 的情况。然而,在使用无符号算术时,这种情况并不会引发问题。如前面的例子所描述的那样,当使用 2 的补码进行减法运算时,是可以得到正确的处理结果的。图 6‑13 展示了 CL 翻转前后,CL 与 CR 的值,以及 CL-CR 的 2 的补码减法运算结果。
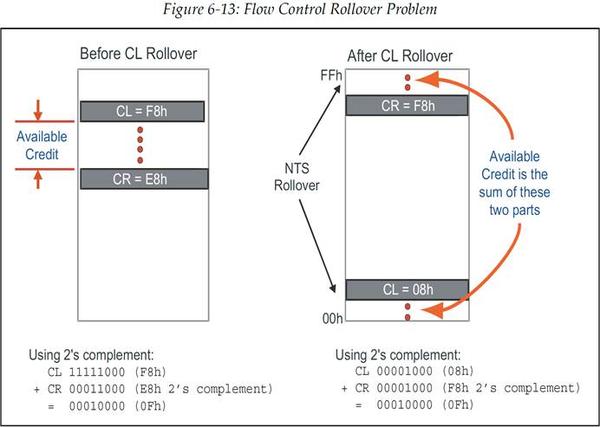
图 6‑13 流控计数器翻转问题
6.6.4 阶段四——流控 Buffer 溢出错误检查(FC Buffer Overflow Error Check)
尽管这是一个可选操作,但是协议规范还是推荐实现这个 FC Buffer 溢出错误检查机制。图 6‑14 展示了和溢出错误检查相关联的流控元素,包括:
- Credits Received(CR)计数器(译注: 注意这里 CR 不是前面的 Credit Required)
- Credits Allocated(CA)计数器
- 错误检查逻辑(Error Check Logic)
这些元素使得接收方可以使用跟发送方相同的方式来记录流控 Credit。如果流控机制正确运行,那么发送方的 Credits Consumed 计数值(CC)永远不会超过它的 Credit Limit(CL),并且接收方的 Credits Received(CR)也永远不会超过它的 Credits Allocated 计数值(CA)。
若检测到下面的公式成立,那么就说明出现了溢出情况。注意公式中的 Field Size 对 Header 来说为 8,对数据来说为 12。
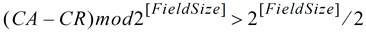
当公式成立时,说明发送至 FC Buffer 的 Credits 数量已经超过了可用的数量,也就是说发生了溢出。注意在 PCIe 1.0a 版本中定义的公式中使用的是≥而不是>。这是一个错误,因为 CA=CR(Credits Received)时并没有发生溢出。
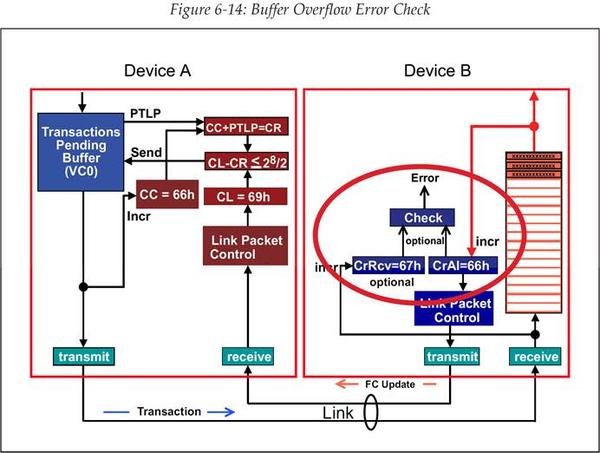
图 6‑14 Buffer 溢出错误检查
6.7 流控更新(Flow Control Update)
当接收方的 Buffer 内有事务被移除时,也就说明这一部分 Buffer 空间又变为可用了,那么接收方就需要定期的用最新的流控 Credit 数量来更新对端设备。图 6‑15 给出了一个例子,示例中发送方原本由于 Buffer 已满的原因阻塞了 Header 事务的发送,而后接收方从流控 Buffer 中移除了 3 个 Header,这使得现在有可用的 Buffer 空间了,但是此时对端设备并不知道这件事。当 3 个 Header 从 Buffer 中移除时,CREDITS_ALLOCATED 计数值(CA)会从 66h 增加至 69h,这个新的计数值被报告给对端设备(发送方)的 CREDIT_LIMIT 寄存器,报告的方式是使用流控更新包(FC Update packet)。一旦 CREDIT_LIMIT 被更新,发送方就可以继续发送 TLP 了。
需要特别指出的一点是,这里更新报告的是 CREDITS_ALLOCATED 寄存器的实际值。其实我们本可以只报告寄存器值的变化量,比如“Non-Posted Header +3 Credits”,但是这种表示会存在一个潜在的问题。为了理解这其中所含的风险,我们需要考虑如果包含了寄存器变化增量信息的 DLLP 因为某些原因造成了丢失,此时会发生什么。对于 DLLP 来说是没有 replay 机制的,如果出现了错误那么处理方式就是简单的把 DLLP 丢弃。在这种情况下,增量信息将会丢失,并且没有方法恢复它。
反过来说,如果报告的是寄存器的实际值而不是增量,那么在 DLLP 传输失败时,下一个 DLLP 依然可以完成计数值的同步更新。虽然这种情况有时会浪费一些时间,比如发送方需要在一个 DLLP 发送失败时等待下一个 DLLP 来更新流控 Credit,但是并不会有信息的丢失出现。
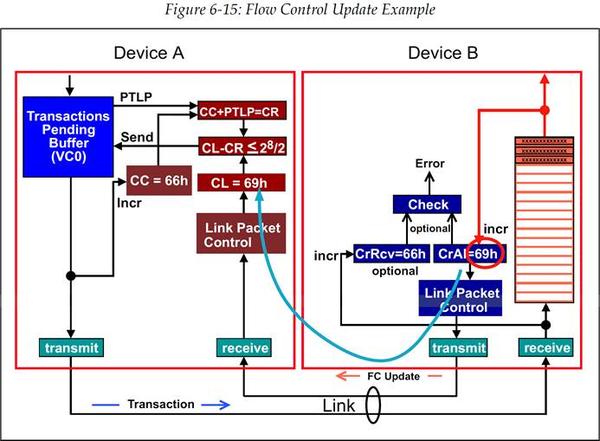
图 6‑15 流控更新示例
6.7.1 流控更新 DLLP 格式和内容(FC_Update DLLP Format and Content)
回想一下,流控更新包与流控初始化包一样,包含两个 Credit 字段,一个是 Header Credit 字段,一个是 Data Credit 字段,如图 6‑16 所示。接收方报告在 HdrFC 和 DataFC 字段的 Credit 值可能已经更新了很多次,也有可能自从上次发送更新包后就没有变过。
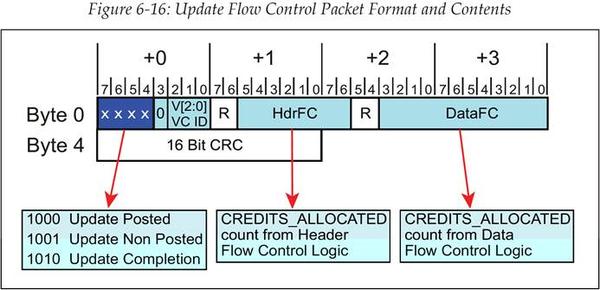
图 6‑16 流控更新包的格式和内容
6.7.2 流控更新频率(Flow Control Update Frequency)
针对流控更新 DLLP 应该如何发送,协议规范定义了各种规则以及建议的实现方式。它们是为了:
- 尽可能早的将最新的 CREDITS_ALLOCATED(CA)告知给发送方,特别是当有事务已经被阻塞的时候。
- 确立 FC 包之间的延时最坏情况。
- 平衡各相关的流控操作的需求,例如:
— 需要足够频繁的报告 Credit 信息,以此来避免事务阻塞
— 希望减少流控更新 DLLP 所需要的链路带宽
— 选择最优的 Buffer 大小
— 选择最大的数据荷载大小
- 检测流控包之间关于最大时延的违例情况。
流控更新仅在链路处于活跃状态(active state,L0 or L0s)时才能使用。所有其他的链路状态表示更加积极的电源管理,它具有更长的恢复时延。
6.7.2.1 立即通告 CREDITS_ALLOCATED(Immediate Notification of CA)
当一个流控 Buffer 已经满到无法接收最大的数据包时,协议规范要求要在 Buffer 出现更多可用空间时立即发送一个 FC_Update DLLP。存在两种情况:
- 最大数据包大小=1Credit。当数据包的发送由于非无限的 NPH(Non-Posted Header)、NPD(Non-Posted Data)、PH(Posted Header)和 CplH(Completion Header)这些种类的 Buffer 已满而被阻塞时,若此时有 1 个或多个的 Credit 变为可用(已分配),那么流控更新包(UpdataFC Packet)必须要被安排传输。
- 最大数据包大小=Max_Payload_Size。对于非无限的 PD 和 CplD 的 Credit 类型,流控 Buffer 空间可能会减小到无法发送最大数据包的程度。在这种情况下,当 1 个或多个的 Credit 变为可用(已分配),流控更新包必须要被安排传输。
6.7.2.2 流控更新 DLLP 间最大延时(Maximum Latency Between UpdateFC)
每种 FC Credit 类型(非无限)的流控更新包安排发送的频率至少要达到每 30us(-0%/+50%)发送一次。如果设置了控制链路寄存器(Control Link Register)内的扩展同步位(Extended Sync bit),那么安排更新的频率必须不低于 120us(-0%/+50%)一次。注意,实际安排发送流控更新包的频率可能要比协议规范中要求的更频繁。
6.7.2.3 基于 Payload Size 和链路宽度计算更新频率
协议规范中提供了一个公式用于计算更新频率,这个计算是基于最大 Payload Size 以及链路宽度的。在下面展示的公式中,使用符号时间(symbol time)来定义流控更新的发送间隔。作为参考,1 个符号时间的定义为传输 1 个 symbol 所需要的时间,Gen1 为 4ns,Gen2 为 2ns,Gen3 为 1ns。表 6‑3、表 6‑4、表 6‑5 展示了每种速率下的原生未调整的流控更新参数值。(译注:UF 意为 UpdateFactor,原文中的 FC 应该是写错了,应该也是 UF)
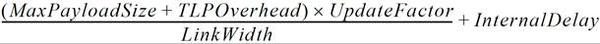
- 最大荷载大小(MaxPayloadSize):这个值在设备的控制寄存器(Control Register)中的 Max_Payload_Size 字段。
- TLP 开销(TLP Overhead):常数值(28 symbol)表示消耗链路带宽的附加 TLP 组件(TLP 前缀 Prefix、序列号 Sequence Number、包头 Header、LCRC、组帧符号 Framing Symbol)。
- 更新因子(UpdateFactor):在两个相邻流控更新包被接收到的中间间隔的这段时间里,所能发送的最大大小 TLP 的数量。这个数字是为了平衡链路带宽效率和接收 Buffer 大小——因为这个值会随 Max_Payload_Size 和链路宽度而发生变化。
- 链路宽度(LinkWidth):链路所使用的通道(Lane)数量。
- 内部延时(InternalDelay):是一个常数值,为 19 个符号时间(symbol time),表示接收到 TLP 并发送 DLLP 所需要的内部处理延迟。
公式中定义的关系表明,发送流控更新包的频率随链路宽度增加而减少,建议使用计时器来触发流控更新包的调度发送。需要注意,这个公式不考虑接收方或是发送方在 L0s 电源管理状态时相关的延时(译注:前面提到过仅在 active 状态才可以使用流控更新)。
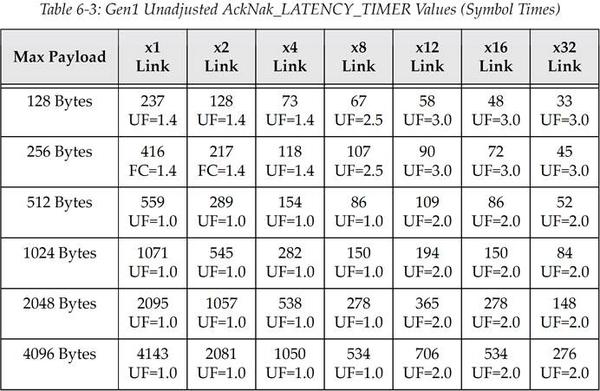
表 6‑3 PCIe Gen1 原生未调整的 AckNak_LATENCY_TIMER 值(单位为 Symbol time)
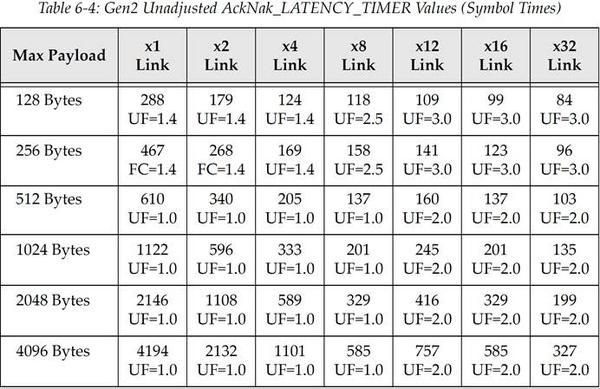
表 6‑4 PCIe Gen2 原生未调整的 AckNak_LATENCY_TIMER 值(单位为 Symbol time)
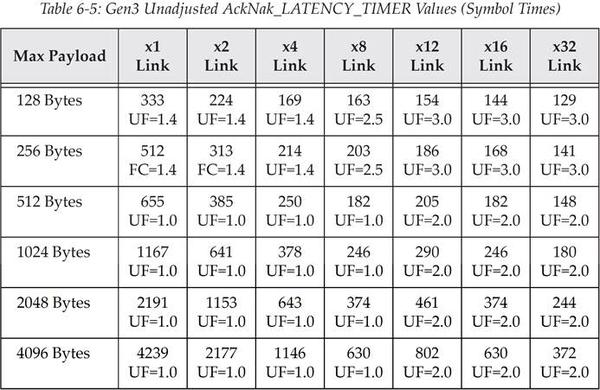
表 6‑5 PCIe Gen3 原生未调整的 AckNak_LATENCY_TIMER 值(单位为 Symbol time)
译注:译者对上面三个表格进行举例说明,选取 PCIe Gen1,Max Payload=256,x2 Link,代入公式得到((256+28)*1.4/2)+19=217.8,不难发现就是对应表中 217 这个值。
而对于 Gen2、Gen3 可能发现不符合公式,其实不难发现 Gen2=Gen1+51,Gen3=Gen2+45,这应该是书中没有提供一些常数参数的原因,总之 Gen2 表格内的值都等于 Gen1 对应的值加上 51;Gen3 表格内的值都等于 Gen2 对应的值加上 45。
协议规范认识到这个公式其实对于许多应用场景的使用是不恰当的,比如那些使用大块数据流的应用。这些应用可能会要求实际 Buffer 的大小要大于规范中给出的大小,以及使用更复杂的更新策略,以此来优化性能和降低功耗。由于解决方案依赖于具体应用的特定需求,因此协议规范中并没有提供此类策略的定义。
6.7.3 错误检测计时器——一个软要求(Error Detection Timer——A Pseudo Requirement)
协议规范中为流控包定义了一个可选的超时(time-out)机制,并且强烈建议实现它,目前它只是一个软要求,但是在未来版本的协议中它可能会成为一个硬性的要求。对于一种给定的 Credit 类型,它的两个流控包之间的最大延时间隔为 120us,而对于超时机制来说超时界限为 200us。对于每种流控 Credit 类型(Posted、Non-Posted、Completion),都各自有单独的超时计时器,且每个计时器都在收到相应类型的流控更新 DLLP 时进行复位。需要注意,与无限流控 Credit 相关联的超时计时器一定不能报告错误。
除开无限 Credit 的情况之外,其他情况下的超时意味着链路存在一个严重的问题。如果超时发生了,那么物理层就会被通知进入恢复状态(Recovery state),并重新进行链路训练,以期望清除错误状态。超时计时器的特性包括:
- 仅在链路处于 active 状态(L0 or L0s)才进行工作。
- 最大时间限为 200us(-0%/+50%)
- 当接收到初始化(Init)或者流控更新包(Update FCP)时,计时器就会复位。或者可选的,也可以在接收到任何 DLLP 时都复位计时器。
- 超时(Timeout)会强制物理层进入 LTSSM(链路训练和状态状态机,Link Training and Status State Machine)的恢复状态(Recovery State)。
- *
原文: Mindshare
译者: Michael ZZY
校对: LJGibbs
文章来源:https://zhuanlan.zhihu.com/p/509862763
《PCI Express Technology 3.0》翻译系列
- PCI Express Technology 3.0:Chapter 6 流量控制 1-4 节
- 《PCI Express Technology 3.0 》Chapter 5 第3 节
- 《PCI Express Technology 3.0》Chapter 5
- PCI Express Technology 3.0:Chapter 1 Background/背景
- PCI Express Technology 3.0:PCIe体系结构概述 2.1 节
- PCI Express Technology 3.0:PCIe体系结构概述 2.2-2.3
- PCI Express Technology 3.0:PCIe体系结构概述 2.2-2.3 节(完)
- PCI Express Technology 3.0:PCIe配置概述 3.1-3.7 节
- PCI Express Technology 3.0:PCIe配置概述 3.8-3.14 节(完)
- PCI Express Technology 3.0:地址空间与事务路由4.1-4.2节
更多IC设计技术干货请关注FPGA的逻辑技术专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

