
原文:https://alastairreid.github.io/papers/sve-ieee-micro-2017.pdf
翻译: 修志龙(Zenon Xiu)
在这篇文章中我们介绍Arm可伸缩性向量扩展(Arm Scalable Vector Extension,SVE)。设计这个扩展的目标有几个:
- 首先,我们需要扩展arm AArch64执行状态的向量处理能力,以便更好适应如高性能计算(HPC),数据分析,机器视觉和机器学习这些场景对计算的需求;
- 第二,我们希望为现在和未来设计一个可伸缩地跨不同CPU实现的扩展,让CPU设计者可以选择最适合他们功耗,性能和面积目标的向量长度。
- 最后,这个构架可以避免为不同向量长度的CPU开发不同软件的代价,还可以利用这个技术更好地使用编译器自动向量化(SVE技术使编译器自动向量化更加可能)。
我们相信SVE可以达到这些目标。它让一个CPU实现可以选择128到2048 bit之间的向量长度。它支持可变长向量长度编程(VLA)模式,使代码不需要重编就可以自动跨所有的向量长度运行。最后,它引入了一些创新性的功能,可以克服一些传统自动向量化的障碍。
1. 简介
当构架第一次被引入时通常是比较保守的,然后当它的潜在好处被更好理解和晶体管预算更加宽松时,构架开始扩展。过去15年里,arm扩展提升了SIMD的支持。从armv6-A支持的在整形寄存器里进行的32 bit(仅支持整形)SIMD指令开始,到armv7-A和armv8-A支持的在共享浮点寄存器中进行的64-bit和128-bit的高级SIMD (NEON)。
这些扩展更高效地处理多媒体和图像工作负载,使用优秀DSP算法处理结构化的数据。但是,随着合作伙伴持续将armv8-A应用到新市场,我们看到越来越多对arm SIMD构架进行根本变化的需求,包括引入熟知的技术,如聚合-取(gather-load),分散-存(scatter-store),每道断定(per-lane predicate)和更长的向量。
但这带来了问题:向量长度应该是多少?包括arm在内的十几年对向量处理的研究,和传统的向量构架如CARY-1的经验,表明:没有什么最好向量长度。基于这个原因, SVE让向量长度变成CPU实现的选择(从128到2048 bit, 128 bit的整数倍)。重要的是,编程模型可以动态适应所有可能的向量长度,而不需要重新编译高级语言代码或是重新手写SVE汇编代码或编译器intrinsics.
当然,更长的向量只是解决方案的一部分,获得更明显的性能提升也需要更高的向量利用率。概括地说,以下关键SVE功能提升了自动化向量的可能性:
• 可伸缩的向量长度:增加了并行度,同时允许不同的CPU实现的选择
• 丰富的寻址模式: 可以做非线性的访问
• 每道判定(Per-Lane Predicate):使包含复杂控制流程的循环可以被向量化
• 判定驱动的循环控制管理( Predicate-driven loop control and management):减少向量化循环时,对剩余数据进行标量化处理的需求
• 丰富的水平方向操作集:可以应用在更多类型的reducible loop-carried 依赖性
• 向量分割和软件管理的推测性访问:使有数据依赖关系的循环可以向量化
• 标量化的内向量子循环(Scalarized intra-vector sub-loops):让有更复杂loop-carried依赖的循环的向量化成为可能
这篇文章后面内容的组织如下:在第二章,我们会介绍SVE构架和可变长向量编程模式,对重要的功能使用一些例子来演示,在第三章;我们会讨论对编译器的影响,着重在自动向量化方面的挑战;在第四章,我们会重点讨论CPU实现的挑战;第五章,我们呈现早期基于模型和实验阶段编译器的SVE性能数据;最后,第六章是总结。
2. SVE简介
在这章里,我们更加完整地描述SVE引入的构架状态,关键功能,在合适的地方,我们会使用代码例子来表达。
2.1构架状态
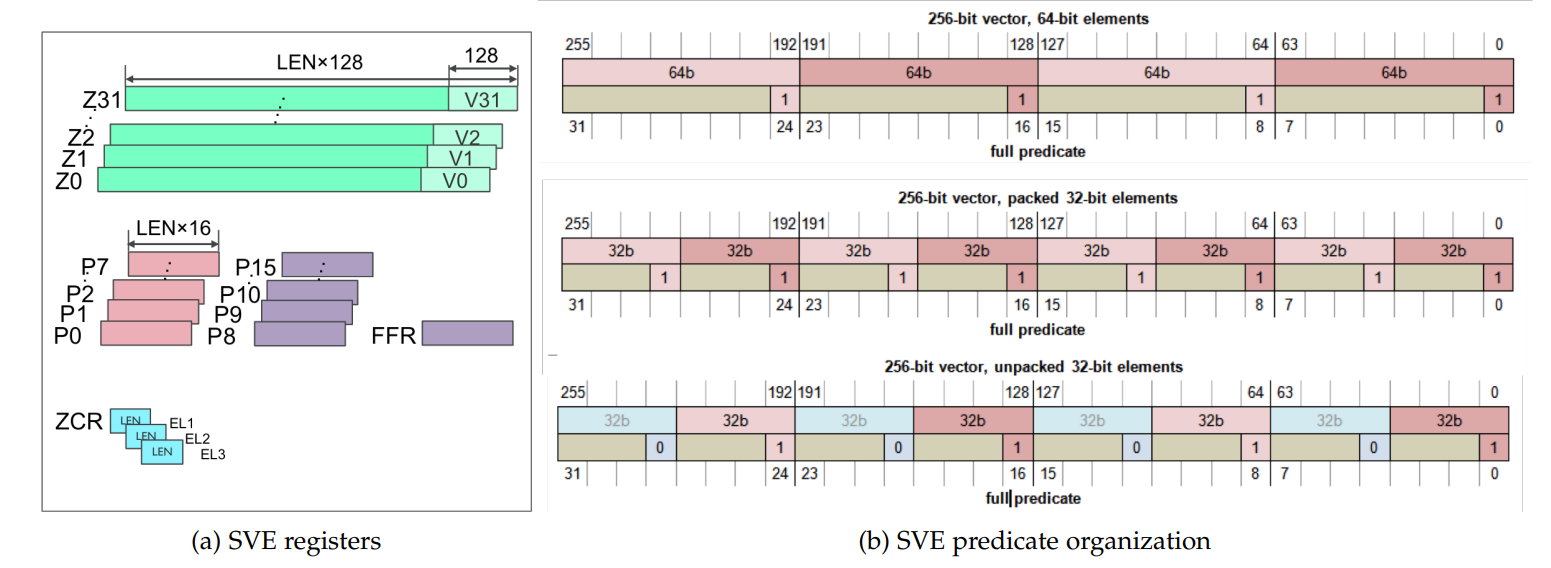
图1
SVE引入了如图 1a所示的新构架状态,它包括32个新的可伸缩向量寄存器(Z0-Z31), 它们的宽度是CPU硬件实现相关的。这些新寄存器扩展了现有32个128-bit的高级SIMD (NEON寄存器,V0-V31), 可以用作包含64-, 32-, 16-和8- bit数据元素的向量。
除了这些可伸缩向量寄存器外,SVE还提供了16个可伸缩判定寄存器(predicate register, P0-P15)和一个特殊目的first-fault寄存器(FFR)。
最后,引入了一组控制寄存器(ZCR_EL1-ZCR_EL3), 它们赋予了为每个特权级(EL)虚拟化(通过设置为更小的向量宽度)的能力。
2.2可伸缩向量长度
在固定32-bit指令编码空间的限制下,每当需要不同向量长度时创造一个新的指令集是不明智的(x86的MMX,SSE, AVX, AVX-512采用这种方式)。SVE根本上不采用这种方式,而是采用可变长向量(vector length agnostic, VLA), 允许CPU实现在128-bit到2048-bit之间选择一个128-bit整数倍的向量长度。无固定向量长度让SVE可以针对不同的市场实现不同性能-功耗-面积(PPA)优化的CPU。
SVE这种新颖设计让软件可以优雅游任于不同向量长度的CPU上,而不需要额外的指令编码,软件重编和移植工作。SVE让软件通过传统SIMD编码方式(需要固定长度,N的倍数或是2次幂的子向量)同时又使用向量分割的方式,具备了可变长向量编程的能力。
2.3以判定为中心(Predicate-centric)的方式
判定(Predicate)是SVE设计的中心。在这章中我们描述predicate寄存器,它们和构架状态的交互,以及如何利用predicate来实现一些高级功能。
2.3.1 Predicate寄存器
Predicate寄存器的组织和使用如下:
16个可伸缩的Predicate寄存器(P0-P15): 用于通用内存访问和算术运算的Predicate仅限于P0-P7, 但是Predicate产生指令(如vector比较指令)和仅使用Predicate寄存器的指令比如 predicate的逻辑运算)可以使用全部的P0-P15寄存器(如图1a).已经通过分析编译出的和手写的代码来验证这种权衡,减少了在其他构架上观测到的对Predicate寄存器的压力。
混合元素(element)大小控制:每个predicate由每64-bit向量元素对应8-bit使能bit组成(即Predicate寄存器的宽度固定为Z向量寄存器宽度的1/8),可以进一步划为per-byte的粒度。对于任何的元素大小,仅最低bit被用作使能bit. 这对包含多种数据类型的代码向量化是重要的(图 1b)
Predicate 条件(condition): SVE中的Predicate产生指令(如向量比较,逻辑运算)重用了AArch64的NZCV条件代码标志,它们在Predicate的语境里解释为不同的意义,如表1所示

隐含顺序: 相当于顺序执行,Predicate被隐含地从最低到最高的元素顺序方式解释。我们称之为first和last predicate,并且使用条件代码也遵从这个顺序。
2.3.2 Predicate驱动的循环控制
SVE中,Predicate被用作基本的循环控制。在其他支持Predicate的SIMD构架,如ICMI和AVX-512中,为循环产生控制Predicate通常需要一条测试变量指令。这通常是通过计算递增在向量寄存器中变量序列,然后使用这个向量作为Predicate产生指令的输入(如 向量比较指令)来实现的。
这种方式有2种开销:首先,需要浪费一个向量寄存器来存这个序列,第二,自动向量化编译器趋向于对齐一个循环里面所有的SIMD指令到最大的元素大小,因而导致当归纳变量(induction variable)的大小大于循环里处理的数据变量的大小时,会有潜在的吞吐量的损失。
为了克服这些常见场景下的限制,SVE引入了while指令家族,它利用标量的count (如循环计数变量 i)和limits(如循环限制 N)作为输入,产生一个Predicate用作循环控制,Predicate通过计算相应的顺序循环次数得到。注意,如果循环计数值接近最大的整数值,while指令会采用原先顺序代码一致的方式处理潜在的wrap-around.
和其他predicate产生指令类似,while指令也会更新条件标志。 

图2 Daxpy的标量C和SVE实现
图2中的例子演示了这些概念。它呈现了使用C, Armv8-A标量汇编,Armv8-A SVE汇编实现的Daxpy循环。对比图2b的等价标量代码,图2c 中的SVE版本没有指令数量的额外开销,而且还让编译器对未知循环次数的循环进行向量化。
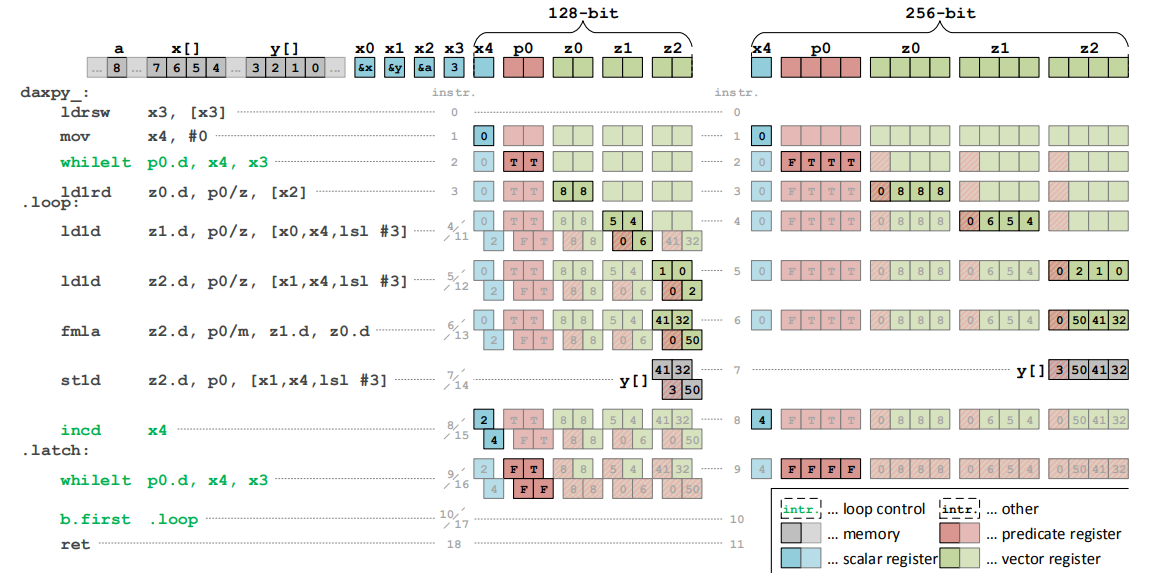
图3 硬件向量长度为 128-bit和256-bit, n=3的 Daxpy例子的执行周期
图3演示了同样的例子,使用128-bit和256-bit的向量长度,单步演示SVE代码。图表显示了中间的构架状态,包括P和Z寄存器,和相应的指令,用于使用不同向量长度处理4个数组元素。
我们推荐读者阅读SVE参考手册和VLA编程白皮书获取更多指令使用指导。
2.3.3 Fault-tolerant Speculative Vectorization (可容错推测性向量化)
为了向量化带数据依赖终止条件的循环,软件必须在这个条件还不知道成不成立的情况下推测性地进行一些操作。对于如简单的整形运算指令这类指令,推测性操作是无害的,因为它们没有副作用。但是,有些指令当操作无效地址时有副作用,必须有机制来避免这些副作用。
SVE通过引入一类带first-fault机制的向量取(Vector load)指令来实现的。这个机制在当向量取指令内存故障不是来自第一个active的元素时,会压制住内存故障汇报(不产生内存访问异常),取而代之的是,这个机制会更新first-fault寄存器(FFR)中的Predicate值来指示哪些内存故障后面元素没有被成功取出。
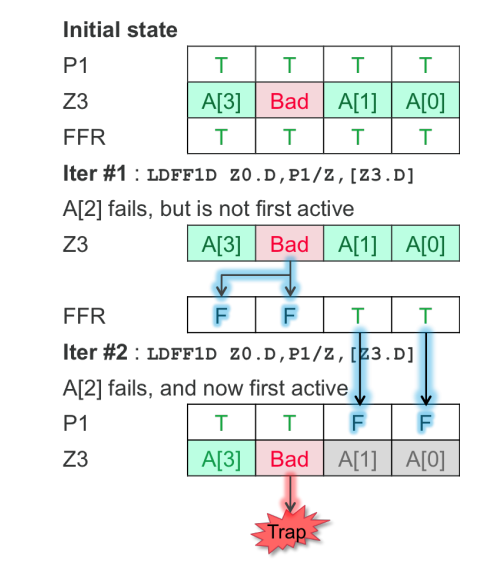
图4 FFR控制的推测性聚合-取例子
图4中呈现了使用gather-load (聚合-取)指令从Z3寄存器中地址指向的内存中推测性读的例子。第一次迭代时,FFR寄存器初始化为全部True,地址A[0], A[1]翻译成功,但地址A[2]是无效的(如没有被映射),访问A[2]失败,但它不会导致trap, 而是A[2], A[3]在FFR寄存器中对应的位置被设为False。第二次迭代时,P1 Predicate寄存器的A[0], A[1]对应的位置被设为false, FFR重设为全部True, 在这条件下,A[2]还是会失败,但因为 A[2]现在是第一个active的元素,它会导致trap, 陷入到内核来处理这个故障,或因为这是个非法地址而终止这个程序。
图5中显示了如何使用first-fault机制的推测性向量化来实现strlen函数的向量化。lddff1b指令从s地址取字符,并设置FFR中对应的从第一个故障地址开始位置的值为false,因此只有成功读取字符对应的FFR位置的值为True。FFR的Predicate值被赋给P1,它用来判定(Predicate)后面的指令来检查字符串的结尾。内存故障之后,下一次迭代中会重试访问故障地址,但现在它是第一个active元素,因而会导致trap。
这种灵活的机制让如strlen这样的有数据依赖终止条件的循环可以进行可容错推测性地向量化。
2.3.4 动态退出
上一章中呈现了在不知道准确循环次数的情况下如何使用SVE向量化循环。这种技术叫做向量分割(vector partitioning),它由操作动态条件决定的安全(safe)元素部分组成的。
分割(Partition)是通过predicate操作指令来实现的,并可被嵌套条件和循环承接。通过这种方式,向量分割是处理带数据依赖退出(如 do-while, break等)无计数循环的天然方式。被向量化的代码必须保证那些循环退出之后有副作用的操作不能够被构架性地(architecturally)操作。这是通过操纵before-break向量分割,并当检测到break条件是退出循环来实现的。


图5 strlen的C和SVE实现
图5中呈现了如何在strlen函数中使用向量分割。2.3.3节描述了ldff1d指令如何推测性地读取内存。rdffr指令报告被安全读取元素的分割信息。它被cmpeq指令用来仅比较安全(safe,正确)值是否为0. brkbs指令进一步产生由循环break条件弹回的子分割(sub-partition), 并相应地计算last条件。
2.3.5 Scalarized Intra-vector Sub-loops
复杂loop-carried依赖关系是重大的向量化障碍,SVE可以帮助解决。克服这个障碍的一种方式是:准确地将序列化的部分从循环里分离出来(loop fission),从而让循环的其他部分可以被向量化中获益。但是,在很多情况下,为此需要的组合和解组合数据操作很大程度上会对性能提升有负面影响。为了减少这个代价,SVE提供了在向量内序列化处理元素的支持。


图6 为部分向量化链表分离loop-carried依赖
这类问题的一个例子是遍历链表,因为每次迭代都有loop-carried依赖(图 6a)。通过应用loop fission,循环被拆分为一个序列化的pointer chase,加上一个可以向量化的循环。
图6c呈现了SVE如何向量化这个代码。第一部分是序列化的pointer chase:pnext指令通过设置P1为下一个active元素并计算last条件,逐一处理active的元素。Cpy指令将标量寄存器X1的值插入向量寄存器Z1的这个位置。然后,使用ctermeq指令检测链表结尾(p==null)或是向量结尾(通过测试pnext指令设置的last条件)。b.cont跳转指令检查条件代码,如果还有更多的指针要处理就继续那个序列化的循环。
读取的指针值的分割计算结果放在P2中。这种情况下,向量化的循环只需要做异或运算。最终,Z0中的所有向量元素通过水平方向上的缩减异或运算指令(eorv)来组合。在这个例子里,性能提升可能不明显,但它用来演示SVE可以适用到更多场景。
2.4 水平方向操作
传统SIMD处理的另一个问题是纯在跨多个循环迭代的依赖关系。在很多情况下,这个依赖可以简单使用水平方向缩减操作来解决。与一般的SIMD指令不一样,水平方向操作是个特例:它是跨同一向量寄存器中元素的操作。SVE有丰富的水平方向操作,包括逻辑,整形和浮点型缩减操作,也包括浮点型的严格顺序缩减操作(比如 fadda).

