
本篇文章是2022年第六届全国大学生集成电路创新创业大赛飞腾杯二等奖作品分享,参加极术社区的【有奖征集】分享你的2022集创赛作品,秀出作品风采活动。
1.团队介绍
参赛单位:西安电子科技大学
指导老师:蔡觉平、丁瑞雪
参赛队员:王瑞青、江立峰、陈培林
总决赛奖项:二等奖

2.项目简介
2.1项目背景
由于深度对于理解三维场景非常重要,因此它被广泛应用于机器人技术、三维建模和驾驶自动化系统等领域。如图1所示,单目深度估计从单个RGB图像生成像素方向的深度。单目深度估计有可能取代现有的深度传感器,如激光雷达和红外传感器,成为低成本和功率单目RGB相机。由于单目RGB相机的可靠性和高精度,最近基于CNN的单目深度估计方法受到关注。然而,CNN需要大量的乘法运算,在有限的功耗限制下,很难对嵌入式系统进行实时、准确的估计。在以往的单目深度估计研究中,为了加快gpu上的训练时间或推理速度,这些研究通常使用具有轻量级卷积(如可分离卷积)的编解码网络[2]。然而,gpu需要很高的功耗,并且不适合处理编码器-解码器网络中使用的许多不同卷积的快速内存访问。

2.2项目功能
单目深度估计是指从单个二维彩色图像中估计像素级深度测量的任务。这个问题的输入是一个2D RGB彩色图像,输出是一个密集的深度图,如图1-1所示。2D RGB图像提供像素级的颜色信息,这有助于识别场景中对象的相对位置;然而,图像本身并不能提供尺度感。因此,可以想象不同的RGB图像如何能够产生相同的深度图,例如,保持对象的相对位置但在垂直于图像平面的深度维度上具有缩放的距离的图像。这对单目深度估计算法提出了挑战,因为它们必须推断适当的比例,以便生成精确的像素级深度测量。

2.3项目应用
深度估计对于许多机器人应用来说至关重要,尤其是导航。这通常是即时定位与地图构建(SLAM)算法中的一个关键步骤,一些著作已经将基于学习的深度估计结合到SLAM框架中,例如CNN-SLAM 。深度估计也是3D重建算法的一个关键步骤,应用于增强现实和医学成像。当我们考虑功率受限的小型化机器人时,单目深度估计变得也很重要,这种机器人上的机载传感器技术可能仅限于简单的RGB相机,并且可能不存在附加信息(例如,立体图像对、IMU测量、稀疏深度点云、光流)。对于这样的应用,以计算有效的方式从单个RGB图像估计密集深度的能力成为挑战和目标。
3.系统组成
- 天乾C216F开发板
我们使用的开发板,完成将RGB图像处理成深度图像的功能 - 全息相册
展示天乾C216F处理后的全息影像 - 上位机
发送指令,完成使系统功能在“怀旧模式”、“摄影模式”、“拍照模式”等多种模式之间的切换 - 单目摄像头
可以捕获图像或者视频,并输出给天乾C216F - HDMI显示器
显示当前模式以及图像处理情况

4.网路设计与优化方法
4.1FastDepth简介
我们设计的单目深度估计网络FastDepth主要由卷积构成,主要由编码器-解码器两部分组成。编码器从输入图像中提取高层次低分辨率特征。然后将这些特征输入解码器,在解码器中对它们进行逐步的上采样、细化和合并,以形成最终的高分辨率输出深度图。

编码器用蓝色表示;解码器用黄色表示。中间特征图的尺寸对应关系为高× 宽×深度。从编码层到解码层的箭头表示加法跳过连接。
FastDepth的大部分卷积层使用深度可分离卷积。只有MobileNet编码器的第一层(标准卷积层)和解码器的最后一层(简单的逐点卷积,然后是插值)没有使用深度可分离卷积。FastDepth中的每个卷积层后面是一个标准化层和一个ReLU函数。在训练之后,将标准化层和卷积层合并,从而形成一个仅由卷积层、ReLU函数和加法跳过连接操作组成的神经网络拓扑。
我们在PyTorch中建立了FastDepth网络,并使用官方的train/test数据分割在NYU Depth v2数据集上进行训练。编码层使用了已经在ImageNet上预训练的模型的权重进行初始化。然后将网络作为一个整体进行20个epochs的训练,batch size为16,初始学习率为0.01。学习率每5个epochs降低2倍。
4.2网络优化
4.2.1网络剪枝
为了进一步减少网络延迟,我们使用NetAdapt执行训练后网络修剪。NetAdapt从一个经过训练的网络开始,自动地从特征映射中识别和删除冗余通道,以降低计算复杂度。在每次迭代中,NetAdapt都会生成一组从参考网络简化而来的网络建议。然后选择具有最佳精度和复杂度权衡的网络方案作为下一次迭代的参考网络。该过程一直持续到达到目标精度或复杂度。网络复杂性可以通过间接指标(如mac)或直接指标(如目标硬件平台上的延迟)来衡量。

4.2.2将5×5卷积和最近邻插值分解为3×3卷积
参考了Yazdanbakhsh等人在他们关于FlexiGAN的工作中探索的这种分解的一种变体,他们在FlexiGAN中使用了滤波器和行重新排序,以使零插入后的卷积更加紧凑和密集,从而更好地利用硬件资源。我们采用了一种类似的方法如图所示。

把5×5核分解成4个更小的3×3核。当5×5卷积之前是最近邻插值。此处的红色框表示插值输入特征图中具有相同值的像素窗口。随着5×5核的滑动,2×2的窗口中的内核值将与相同的特性映射值相乘。与执行4次乘法和4次加法不同,内核值可以先预加,然后再与共享像素值相乘一次。(b)经过滤波器分解,每四个较小的3×3滤波器可与非插值输入特征映射卷积。这将产生四个可以交错的输出。得到的输出特征映射与最近邻插值后执行的原始5×5卷积的特征映射相匹配。
5.部署方式
本文实现了两种部署方式:通过TVM编译器和pytorch深度学习框架部署。通过TVM端到端深度学习编译器部署fastdepth模型,显示效果一般,但由于对模型经过剪枝、量化等优化操作,帧率高达34.7fps;通过pytorch深度学习框架部署midas,模型精度高,显示效果好,但帧率下降至0.82fps左右。
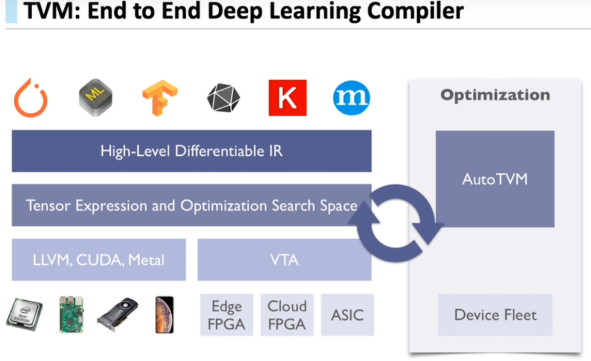
TVM是由华盛顿大学在读博士陈天奇等人提出的深度学习自动代码生成方法,该技术能自动为大多数计算硬件生成可部署优化代码,其性能可与当前最优的供应商提供的优化计算库相比,且可以适应新型专用加速器后端。
TVM可以优化CPU和其他专用硬件为后端的常见深度学习计算负载。
TVM通过利用多线程、数据布局转化和一些新的计算原语,可以针对GPU做很多高效优化。
同时,TVM已为x86、ARM等平台提供了同意的优化框架,利用其部署大大提高了板子资源利用率,帧率高达34.7fps。
下图是TVM端到端深度学习编译器的说明图:
6.作品效果展示
通过全息相册上位机选择生成后的深度图即可在全息相册上展示。

演示视频:
https://www.bilibili.com/vide...
赶快来提交你的队伍的集创赛作品,让更多人看到你们的成果,更有丰富礼品给到每个队员。点击此处发布作品文章。

