

Embedding 是分析非结构化数据的重要方式,当我们将图片、声音编码为向量后,这些数据依旧能够保留原始数据(图片、声音等)的详细信息。然而,我们很难直接对这些编码后的向量中的数字与原始数据建立联系,想要弄清楚向量构成的空间到底意味着什么就更是难上加难了。
本篇文章,我们将以向量 Embedding 场景中最重要的应用 “以图搜图” 为例,通过使用开源工具 Feder 来剖析相似性检索场景中的向量空间到底是怎样的,以及介绍最常用的向量索引 IVF_FLAT 在空间中的结构表现、它的数据检索过程是如何进行的。
向量检索常见场景:“以图搜图”
日常网络数据中,图片、视频等非结构化数据越来越多。“以图搜图”这种新型信息检索方式,也变得越来越常见。以图搜图,通常也被称作“反向图像搜索”,它的工作流程非常简单:我们向搜索引擎提交一张图片,搜索引擎从数据库中返回最相似的几张图片结果给我们。
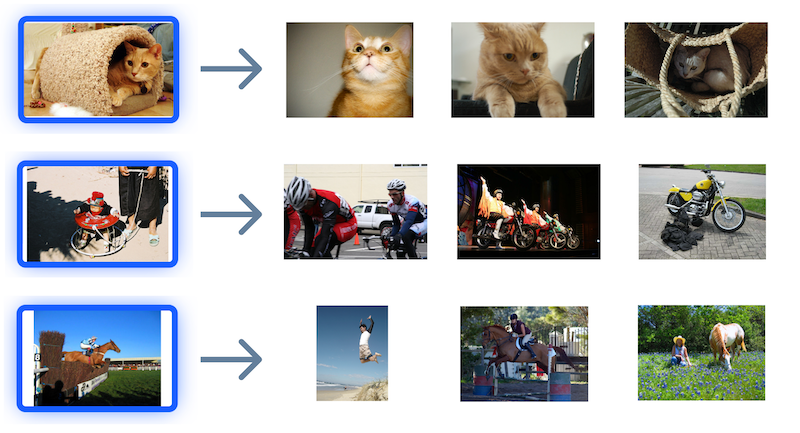
有的时候,我们会惊叹搜索结果非常相似,有的时候也难免吐槽结果离谱至极。那么,这个结果到底是怎么来的呢?或者说,计算机是如何判断图片们是否“相似”的呢?
计算机如何理解“图片的相似性”:嵌入向量(Embedding)
我们知道图片是由许多像素点构成的,所以直接对比位图的每一个像素点是可以判断图片的相似性的,但是这个方案显然不是那么高效,甚至不会那么有效:一张夜空的图片和一张黑猩猩的图片只有颜色构成相似,内容则完全不同。

如果我们预先对图片进行“打标签”来进行分类,把相似图片的搜索问题转化为标签的搜索和匹配问题,是不是就能够解决这个问题了呢?比如:识别到用户上传的图片是一只橘猫,那么就在数据库中查找并返回所有带橘猫标签的图片。这个方法是可行的,早期的搜索引擎中也是这样实现的,但是我们很容易发现一个致命问题:搜索结果的准确性高度依赖于标签的精细程度。在数据量爆炸的今天,为每一张图片打上足够的标签的经济成本显然会非常高,并且“标注”非常依赖于人工。
那么是否有什么方法,能够在没有“标签”的情况下,完成图片之间的相似度判断呢?AI 领域最为流行的嵌入向量 (Embedding) 就很好地解决了这个问题。那什么是嵌入向量呢? 以我们熟悉的“苹果”举例,在我们脑海中,它的特征关键词可以被描述为 [红色,球形,甜,芳香,长在树上, ...] 等等,任何与这些特征相似(不一定完全相同)的物品都可能是苹果。
好了,如果我们设置一套规则,用数字来对应这些特征概念,就能够得到苹果的向量表达方式,比如将它表示为:[1.024, 9.527, 1.314, 5.201, 1.111, 0.618 ...]。此时,再交给计算机程序,完成这些数字的计算,再合适不过了。我们可以设置多种映射规则,从不同维度对图片进行特征提取,并将这些特征以数字的形式展示出来,然后使用程序获取图片之间的向量距离,比如:欧式距离、余弦距离等等。
通常,我们会将这些“确定的映射规则”称作训练好的模型,而“提取尽可能多的特征”就是模型在学习和训练过程中获取的核心能力,这些“提取出的特征”就是图片标签在向量空间中的表达方式。我们只需要通过程序来判断不同图片在向量空间中的距离,就能够判断图片之间是否存在相似性,以及相似度有多高。
如果在提取过程中,我们使用了不同的模型,即使对于相同的图片,我们得到的嵌入向量的结果也是不同的,如同不同的人看待相同事物的认知存在不同一样。但只要是一个质量还不错的模型,计算得到的红苹果和青苹果之间的向量距离,一定会比它们和一只猫要近得多。单纯比较向量的绝对数值是没有意义的,相比之下“相对距离”对于计算机理解图片相似度更为重要。
如何高效地搜索距离最近的向量:近似最近邻搜索
在了解计算机是如何计算图片之间的相似度之后,我们来简单归纳下它的具体工作流程:
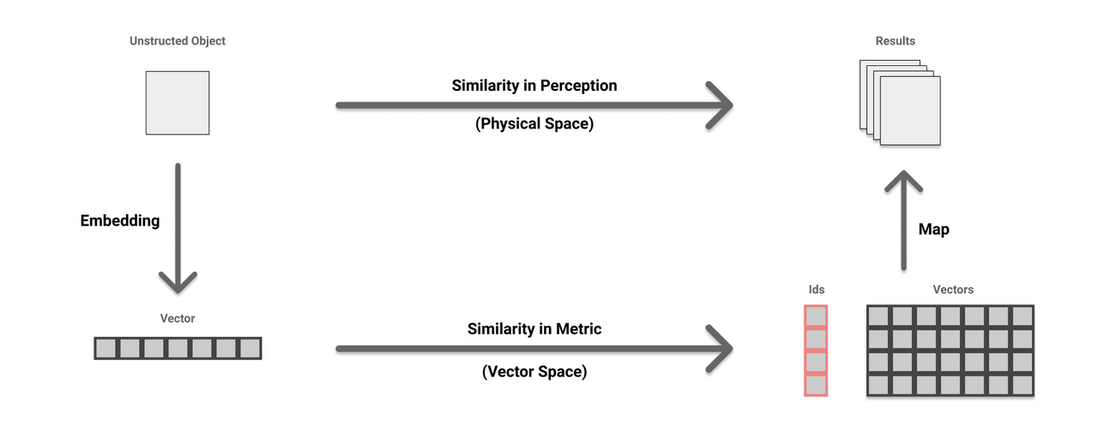
- 准备工作:训练模型,针对数据进行预处理,将图片全部编码为向量并进行储存。
- 第一步:获取目标图片的嵌入向量。
- 第二步:在向量数据库中找到距离最近的向量,收集向量的 ID。
- 第三步:根据检索到的结果,返回对应向量 ID 所代表的图片。
在实际检索过程中,如果我们不进行任何优化,采用默认的索引类型,比如 FLAT ,那么在查找的过程中,会暴力地对所有数据进行遍历查询。在图片相似度比对的过程中,如果 embedding 抽取数据维度为 512 / 1024 甚至更高维度,意味着单次计算量也会非常高。生产环境中,我们的数据总量一般都比较大,如果不采取任何优化措施,数据量 x 向量维度带来的将是非常可怕的计算量,与之相对的是单次查询的负载将非常高。
在云主机环境中(8cores),当我们在 100 万 512 维向量数据中进行数据检索时,如果使用 FLAT 索引进行检索,将花费接近 100ms 的时间,而如果我们采用 HNSW 索引进行数据检索,检索时间将降低到 1~2ms,是不是很惊艳!
为了能够让向量检索程序高效的执行,我们需要思考如何针对它进行优化。这个检索过程中,除了准备工作中的数据预处理会花费比较多的时间之外,最费时的莫过于第二步操作。因为准备工作是一次性计算,所以我们可以将其忽略,重点放在如何优化高频次的向量检索过程。
除了优化计算效率,让计算加速之外,有一个流行的方案是通过算法来减少整体计算量,来提升整体检索效率。在计算机领域,对时空复杂度很高的算法,常常会用近似检索来平衡准确率和计算效率。通过牺牲一些精度来换取效率的巨大提升。
这篇文章中,我们先来介绍最为经典的一种近邻搜索算法:IVF_FLAT,通过向量数据库可视化工具Feder揭开它在向量检索过程中的神秘面纱。
理解 IVF_FLAT 向量索引的检索过程
IVF_FLAT 向量索引的检索过程一共分为三步,在了解具体步骤之前,我们先来准备向量数据。
准备工作:使用 Towhee 获得向量数据
通过使用Towhee,我们可以轻松地将机器学习领域经典图片数据集VOC 2012中的一万七千多张图片转换为向量数据。
import numpy as np
import towhee
dc = (towhee.glob('train/*/*.JPEG')
.image_decode()
.image_embedding
.timm(model_name='resnet50')
.to_list()
)
vectors = np.array(dc, dtype="float32")步骤一:对所有向量进行聚类
接下来,我们使用开源项目facebookresearch/faiss来为这些向量数据构建 IVF_FLAT 索引。关于 Faiss 的入门,可以参考《向量数据库入坑指南:聊聊来自元宇宙大厂 Meta 的相似度检索技术 Faiss》这篇文章,本文就不过多展开了。
和现实世界中一样,当国家由于土地广袤,通常会进行行政区域划分,比如将距离相近、有共同特点的区域归属于一个省份。IVF_FLAT 索引采用的思路也是类似的,会将距离相近的向量组成一个聚类。类似现实中不同省份拥有城市、乡镇数量不同,由于向量分布的密度不同,每个聚类包含向量的数目也会是不一样的。
import faiss
num_elements, dim = vectors.shape
nlist = 256
index = faiss.index_factory(dim, 'IVF%s,Flat' % nlist)
index.train(vectors)
index.add(vectors)
faiss.write_index(index, 'faiss_ivf_flat_voc.index')在上面的代码中,我们设置索引构建参数nlist=256,根据k-means算法,能够将前文中 Towhee 处理好的所有向量分为 256 份。k-means是机器学习领域里最简单和最常见的无监督的聚类方法,可以让距离相近的向量尽可能归属于同一个聚类中,同时每一个聚类中的向量们,距离这个聚类的几何中心相比较其他的聚类而言都是最近的。
为了更好的理解上面的内容,我们通过 Feder 进行了可视化呈现。如下图所示,我们在一个二维平面上模拟了高维空间上的聚类划分。 
我们可以通过移动鼠标来查看不同聚类中的内容,鼠标停下的地方,将随机展示该聚类中最多九张图片。(在线预览地址) 
完成向量数据的聚类后,当我们进行查询的时候,会发生什么呢?
步骤二:粗查询 (Coarse Search)
当我们输入目标向量进行查询时,首先会将目标向量与上图中所有聚类(256个)的中心进行距离计算,并找到距离最近的几个聚类。由于聚类的划分依据是向量间的相对距离,因此我们可以认为,距离目标最近的向量极大概率会属于这最近的几个聚类中。 
在查询过程中,我们通过设置查找个数的参数nprobe=8,将检索范围从 17000 张图片所在的 256 个区域,缩减为最相似的八个聚类中(图中高亮的区域)。在粗查询过程中,我们一共进行了nlist(256)次计算。(在线预览地址)
步骤三:精细查询(Fine Search)
在完成“粗筛”之后,我们确定了与查询数据距离最近的几个聚类,接下来将进行精细查询。
我们可以通过设置查询参数k=9,来指定最终检索的结果是最相似的九张图片。在检索过程中,算法将逐一将查询数据与这些聚类中的每一个向量进行距离计算,并从中选取距离查找数据最近的九个向量结果。 
如上图所示,我们将不同的聚类使用不同的颜色来进行区分,可以观察到这些聚类中的向量的具体空间分布。其中,每个向量节点距离中心的距离映射了该向量与我们要检索的目标向量的实际距离。 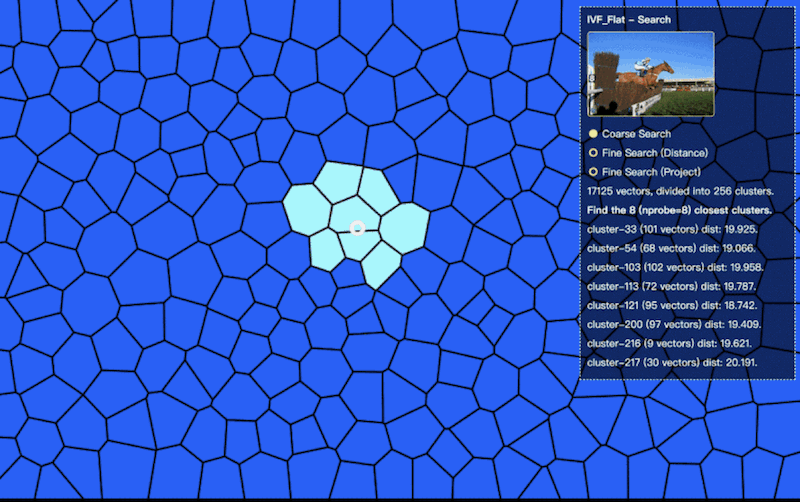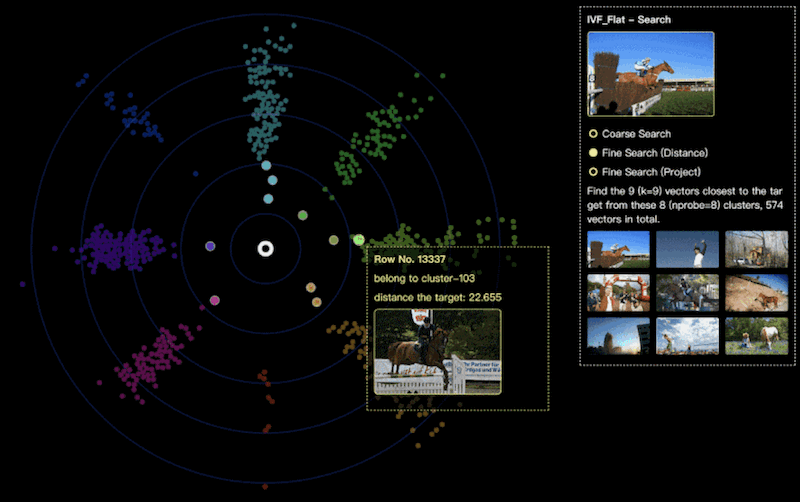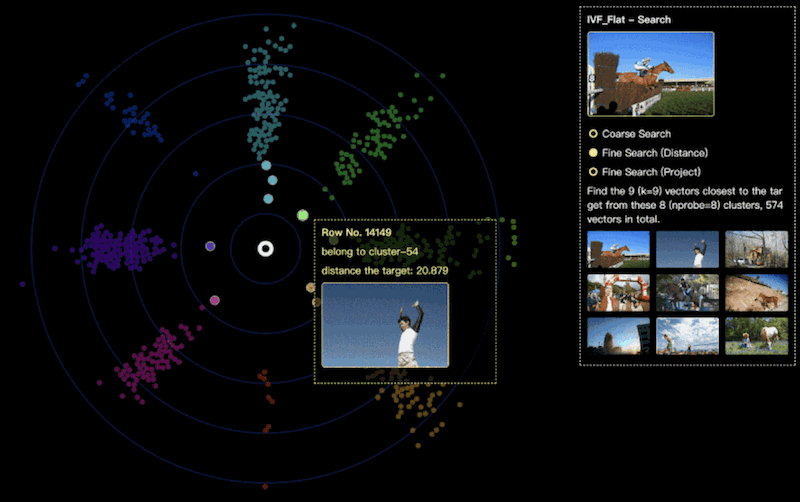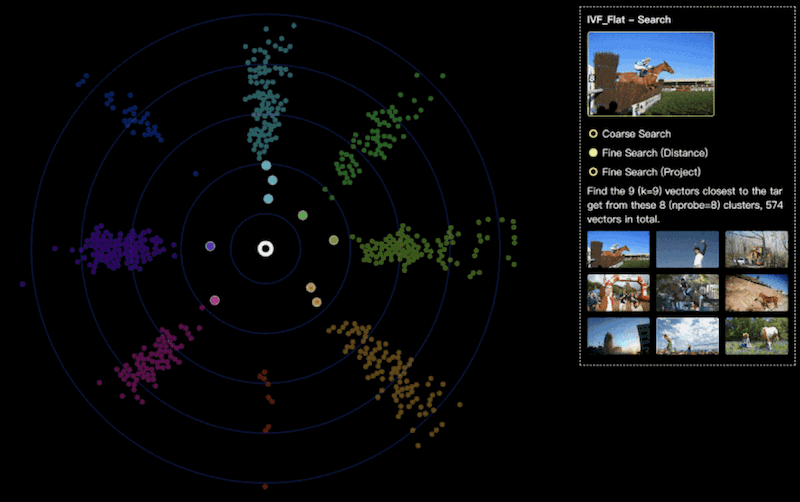
除了看概况之外,我们还可以进一步查看这些向量更详细的数据。
除了根据与目标的距离来布局外,Feder 还支持通过降维投影的方式来可视化向量分布,欢迎亲自动手来试一试,轻松玩转向量数据。https://github.com/zilliztech/feder
IVF_FLAT 类型向量检索性能分析
如果我们使用传统的 FLAT 类型的索引,想要完成相同的检索,至少需要计算一万七千次,完成整个向量数据库的遍历。而当我们使用了 IVF_FLAT 索引之后,根据上文中的参数配置,我们只需要进行不到一千次的计算:包含了粗略查询 256 次,以及后续的精细查询 742 次左右,能够大幅提升我们对于检索效果的获取速度。
而通过在精细查找阶段的nprobe参数,将能够满足具体的业务场景需要,平衡效率(检索效率)和精度(召回率):增大 nprobe,通过搜索更多的数据所在的聚类空间,能够得到更多的搜索结果;减少 nprobe,则可以通过减少搜索范围来缩短计算时间,得到更快速的检索结果返回。
重新审视以图搜图
在了解了 IVF_FLAT 背后的近似最近邻算法后,回顾下整个以图搜图的流程,我们不难发现,最终搜索结果的好坏取决于下面两点,以及背后的各种因素:
1. 第一步:机器学习模型是否能够正确的提取图片的特征数据?提取的特征数据量是否足够?这些嵌入向量保留了多少原始空间中的信息?
2. 第二步:通过“近似最近邻搜索”算法获得的数据本身是否精确?是否存在有更近的向量数据存在,但是没有通过索引查找到?通过调整索引参数是否能够改善搜索结果?以及这些参数是如何影响搜索过程的?
虽然写出来就几句话,但是这两个问题都并不是那么简单。想要解决第二步中的问题,需要我们对于近似最近邻算法非常熟悉,才能够对各个参数发挥实际效用有所了解;而第一个问题,则是困扰学术界多年的难题,关于机器学习模型的可解释问题。
以往我们评价上面两个过程对于检索结果的好坏,主要是通过准备不同测试集来从宏观上计算不同模型在不同近似最近邻算法下的准确率和召回率。在有了 Feder 这个可视化工具之后,我们可以尝试从单次查询出发,从微观上来深入观察这个过程。 以前文中的图片为例: 
我们先从一般的视觉感知角度出发,来进行图片描述:晴空万里,一个人骑着马,在场馆的草地上,此时一人一马正腾飞在空中,跨越栏杆。
接下来,我们通过使用 Feder 来进行图片查询,看看模型是如何理解这张图片的。在粗略查询中,我们找到了距离目标最近的几个聚类区域。 
可以发现,图片右上角的 cluster-54 这个聚类中的图片大多描绘了人的跳跃过程:腾飞在空中;而右下角的图片 cluster-103 更多包含了以人骑马为主题的图片;在 cluster-217 与 cluster-113 虽然看起来和原图不是很相似,但实际上包含了栏杆和场馆这类建筑特征。 
在精细查询过程中,我们可以从深入到聚类内部,进行更细致向量粒度的图片对比。来思考嵌入后的信息空间与真实感知的视觉空间的差异。
最后
你或许会疑惑为什么图片 A 比图片 B 更近?为什么最符合视觉的图片 C 反而被错过?或许,现在的我们还不能够很好的解答这些问题,但恰恰是这些一个又一个的“为什么”在指引着我们去不断接近真相,去更好的认识模型、优化模型。我们认为神经网络绝不只是冷冰冰的参数堆砌的多层结构,在不远的未来,研究者们终将能够训练出和人类感知一致的模型,甚至通过模型反观人脑的认知神经,揭开大脑更深层次的奥秘。
如果看到这里你还意犹未尽,想亲自上手体验,我们为你准备了一个可交互的以图搜图分析网页,你可以自由地挑选感兴趣的图片进行搜索,并结合可视化工具 Feder 去观察模型和近似最近邻的搜索过程。欢迎向大家分享你的所思所感~
如果你对近似最近邻算法很感兴趣,那么请保持关注,接下来的内容中,我们将分享更多精彩的技术干货。
最后的最后,不论你是进阶的模型训练家,还是刚刚入门的炼丹士,都欢迎使用我们的开源可视化工具 Feder,来探索模型中隐藏的奥秘。Feder 包含两个版本:Python 以及 JavaScript,我们在 GitHub 有详细的文档和教程,希望能够得到你的“一键三连”。你的鼓励,将是我们继续进步的动力!
作者:Zilliz
文章来源:https://segmentfault.com/a/1190000042605554

