
五月份买了12代Alder Lake架构的笔记本,CPU型号是i7 1280p,6大8小的配置。最近终于有机会研究一下这个架构的特性,顺便记录一下感想。为了适配这个新的架构,我大幅修改了cpufp这个程序,大家可以帮忙多测一测:
Alder Lake大小核架构与拓扑
在ubuntu 22.10下运行lstopo(可以通过apt install hwloc的方式获得),可以看到如下处理器拓扑结构:
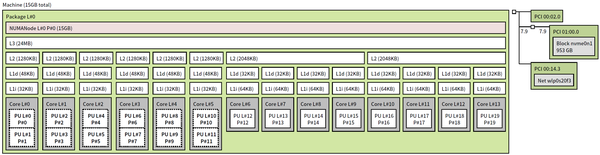
i7 1280p处理器结构拓扑
可以看到:
[1] 处理器6个大核心,以及8个小核心都识别到了。编号上,大核心在前,小核心在后,这个特性和arm在android下是相反的。
[2] 每个大核心有独立的L2,共享L3,且有两个超线程。同一个核心的超线程优先编号,与早期Linux相反。
[3] 每个小核心只有一个线程。每四个小核心共享L2 cache。
这样的架构拓扑,与以前的CPU拓扑有了很大差别。以前的架构,全部是同构核心,即便有NUMA这样非对称内存访问结构,也还算简单,并行程序在分配,管理,访问内存的时候注意区分本地内存和远端内存即可,在任务调度上不需要考虑因同样的任务在不同核心上计算效能的差异导致的负载不均衡问题。
所以旧版本的cpufp做多线程并行的方式,问题就很大了:假设所有核心都是同构核心,静态任务分配,会造成多核心测试负载不均衡;大小核超线程的数量的不同,以及超线程的新的编号方式,导致线程池的亲和性设置很难自动且正确地完成。基于这些问题,我修改了cpufp的绑核方式,需要在命令行参数由用户明确指定绑定线程的编号(图中的PU编号)。比如要开6个线程的线程池,绑定6个大核,那么需要运行:
./cpufp --thread_pool=[0,2,4,6,8,10]要绑定小核,则参数可以用“-”号表示连续区间:
./cpufp --thread_pool=[12-19]这样并没有解决自动负载均衡的问题,但是对于cpufp这个demo程序也足够用了。
新指令集AVX VNNI
Alder Lake架构虽然屏蔽掉了AVX512系列指令集,但是仍然保留了AVX VNNI指令集,可以把它看成是AVX512 VNNI指令集的256和128位子集。但是,它是一个全新的指令集,在编码上与AVX512并不相同,指令需要加上{vex}前缀,否则生成的机器码是AVX512 VNNI的,在不支持AVX512 VNNI的CPU上会报illegal instruction,{vex}前缀表示编译成AVX版本的指令。下面一段代码是测试AVX VNNI的int8峰值的代码:
cpufp_kernel_x86_avx_vnni_int8:
vpxor %ymm0, %ymm0, %ymm0
vpxor %ymm1, %ymm1, %ymm1
vpxor %ymm2, %ymm2, %ymm2
vpxor %ymm3, %ymm3, %ymm3
vpxor %ymm4, %ymm4, %ymm4
vpxor %ymm5, %ymm5, %ymm5
vpxor %ymm6, %ymm6, %ymm6
vpxor %ymm7, %ymm7, %ymm7
vpxor %ymm8, %ymm8, %ymm8
vpxor %ymm9, %ymm9, %ymm9
.cpufp.x86.avx.vnni.int8.L1:
{vex} vpdpbusd %ymm0, %ymm0, %ymm0
{vex} vpdpbusd %ymm1, %ymm1, %ymm1
{vex} vpdpbusd %ymm2, %ymm2, %ymm2
{vex} vpdpbusd %ymm3, %ymm3, %ymm3
{vex} vpdpbusd %ymm4, %ymm4, %ymm4
{vex} vpdpbusd %ymm5, %ymm5, %ymm5
{vex} vpdpbusd %ymm6, %ymm6, %ymm6
{vex} vpdpbusd %ymm7, %ymm7, %ymm7
{vex} vpdpbusd %ymm8, %ymm8, %ymm8
{vex} vpdpbusd %ymm9, %ymm9, %ymm9
sub $0x1, %rdi
jne .cpufp.x86.avx.vnni.int8.L1
retVNNI指令集支持int8和int16两种精度,现在都已加入cpufp的benchmark里。同时新版本的cpufp可以在编译期(执行build.sh时)识别本机支持的指令集,直接生成支持指令集的benchmark测试,避免了旧版系统编译不了新指令集的问题。
Alder Lake峰值测试结果与分析
修改后的cpufp代码在我的i7-1280P上测试结果如下:
$ ./cpufp --thread_pool=[0]
Number Threads: 1
Thread Pool Binding: 0
--------------------------------------------------
| Instruction Set | Data Type | Peak Performance |
| AVX_VNNI | INT8 | 590.31 GOPS |
| AVX_VNNI | INT16 | 295.06 GOPS |
| FMA | FP32 | 149.87 GFLOPS |
| FMA | FP64 | 74.931 GFLOPS |
| AVX | FP32 | 112.39 GFLOPS |
| AVX | FP64 | 56.203 GFLOPS |
| SSE | FP32 | 56.054 GFLOPS |
| SSE | FP64 | 28.001 GFLOPS |
--------------------------------------------------
$ ./cpufp --thread_pool=[0,2,4,6,8,10]
Number Threads: 6
Thread Pool Binding: 0 2 4 6 8 10
--------------------------------------------------
| Instruction Set | Data Type | Peak Performance |
| AVX_VNNI | INT8 | 2636.8 GOPS |
| AVX_VNNI | INT16 | 1319.1 GOPS |
| FMA | FP32 | 670.05 GFLOPS |
| FMA | FP64 | 335 GFLOPS |
| AVX | FP32 | 502.4 GFLOPS |
| AVX | FP64 | 251.2 GFLOPS |
| SSE | FP32 | 250.42 GFLOPS |
| SSE | FP64 | 125.16 GFLOPS |
--------------------------------------------------
$ ./cpufp --thread_pool=[12]
Number Threads: 1
Thread Pool Binding: 12
--------------------------------------------------
| Instruction Set | Data Type | Peak Performance |
| AVX_VNNI | INT8 | 114.89 GOPS |
| AVX_VNNI | INT16 | 57.445 GOPS |
| FMA | FP32 | 57.444 GFLOPS |
| FMA | FP64 | 28.723 GFLOPS |
| AVX | FP32 | 28.723 GFLOPS |
| AVX | FP64 | 14.362 GFLOPS |
| SSE | FP32 | 28.312 GFLOPS |
| SSE | FP64 | 14.361 GFLOPS |
--------------------------------------------------
$ ./cpufp --thread_pool=[12-19]
Number Threads: 8
Thread Pool Binding: 12 13 14 15 16 17 18 19
--------------------------------------------------
| Instruction Set | Data Type | Peak Performance |
| AVX_VNNI | INT8 | 867.99 GOPS |
| AVX_VNNI | INT16 | 434 GOPS |
| FMA | FP32 | 434 GFLOPS |
| FMA | FP64 | 217 GFLOPS |
| AVX | FP32 | 217.01 GFLOPS |
| AVX | FP64 | 108.5 GFLOPS |
| SSE | FP32 | 216.39 GFLOPS |
| SSE | FP64 | 108.5 GFLOPS |
--------------------------------------------------第一个表格是单个大核的执行结果,可以看到如下特性:
[1] AVX VNNI指令集的int8吞吐,是FMA指令集(CPU最大浮点吞吐指令)中fp32的4倍;int16则是fp32的2倍,与其他支持dp4a类指令架构非常一致。
[2] SSE指令是AVX指令对应精度类型的正好1/2吞吐,这个与以往在intel先前架构也吻合。
[3] AVX指令和FMA指令对比,对应精度类型的吞吐大约是3/4( 112.39\div149.87\approx74.99\%112.39\div149.87\approx74.99\% )。这就与Intel前面几代架构有了较大的差别。我在另外一台10代Comet Lake架构CPU(桌面Skylake架构的某改ya良gao版)上测试的结果如下:
$ ./cpufp --thread_pool=[0]
Number Threads: 1
Thread Pool Binding: 0
--------------------------------------------------
| Instruction Set | Data Type | Peak Performance |
| FMA | FP32 | 125.93 GFLOPS |
| FMA | FP64 | 62.898 GFLOPS |
| AVX | FP32 | 62.948 GFLOPS |
| AVX | FP64 | 31.491 GFLOPS |
| SSE | FP32 | 31.28 GFLOPS |
| SSE | FP64 | 15.686 GFLOPS |
--------------------------------------------------可以看出该架构中AVX指令对应浮点类型的吞吐是FMA指令的一半。这是由于,Alder Lake之前的架构,浮点向量乘加类指令集中在port0和port1这两个发射端口(port5作为AVX512唯一完整的发射端口,经常在桌面架构或者低端服务器产品屏蔽掉浮点乘加),这两个端口一般各有一条256位的FMA单元。同时,这两个端口也支持256位的MUL和ADD指令,或者,其中一个端口支持MUL,另一个端口支持ADD。这样我们在测试AVX指令时用到MUL和ADD,分别只有FMA指令一半的吞吐(乘和加各算一次计算,所以乘加相比乘或者加单独的指令就是两倍的浮点吞吐)。然后我们再看一下Alder Lake大核Golden Cove的架构:
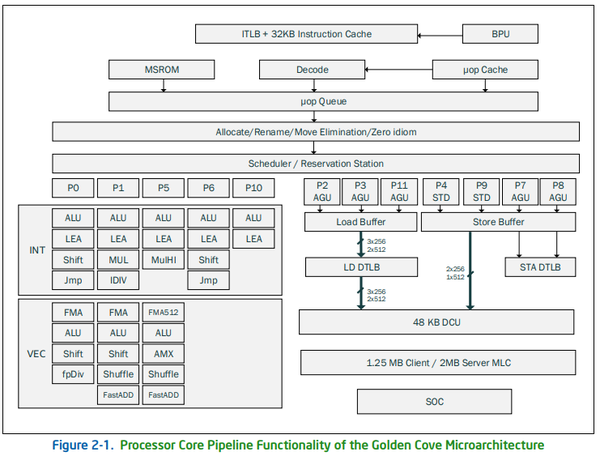
Intel 12代处理器大核Golden Cove架构图
我们发现Port5也多了一条FastADD单元(Fast指的是延迟周期更短)。这样,Golden Cove在Port0和Port1各有一条256位的FMA;在Port0和Port1各有一条MUL(与FMA单元共享);同时,Port1和Port5各有一条FastADD。因此Port1既可以发射MUL,也可以发射FastADD。我们的AVX指令测试程序是下面这样乘加交换排指令流水的:
.cpufp.x86.avx.fp32.L1:
vmulps %ymm12, %ymm12, %ymm0
vaddps %ymm12, %ymm12, %ymm1
vmulps %ymm12, %ymm12, %ymm2
vaddps %ymm12, %ymm12, %ymm3
vmulps %ymm12, %ymm12, %ymm4
vaddps %ymm12, %ymm12, %ymm5
vmulps %ymm12, %ymm12, %ymm6
vaddps %ymm12, %ymm12, %ymm7
vmulps %ymm12, %ymm12, %ymm8
vaddps %ymm12, %ymm12, %ymm9
vmulps %ymm12, %ymm12, %ymm10
vaddps %ymm12, %ymm12, %ymm11
sub $0x1, %rdi
jne .cpufp.x86.avx.fp32.L1执行的时候,第一个周期发射乘加乘,第二个周期发射加乘加,第三个周期又是发射乘加乘... 以此类推。三个端口支持乘和加1:2和2:1两种比例,都可以填满流水线。这样浮点吞吐量正好是两条FMA流水线的3/4,算是近几代intel架构里一个不小的改进,为AVX和SSE(SSE就是简单地复用AVX的一半计算单元)优化的重型浮点程序,可以在Golden Cove上获得相当的性能提升(IPC提升)。
第二个表格,是6个大核的测试,由于低功耗版处理器的限制,多核频率达不到单核的6倍,所以整体计算吞吐没有达到6倍,表现算是正常。
第三个表格是小核心单核,可以看出如下几个特性:
[1] AVX VNNI的int8吞吐只有FMA的fp32吞吐的2倍,int16与FP32的吞吐持平,小核的AI能力缩水不少。
[2] 小核心的浮点吞吐只有大核心的1/3多一点,一方面因为小核心只有一条FMA流水线,另一方面是频率也有差距。即便使小核心对比10代Comet Lake处理器,也只有不到1/2的吞吐(频率差距小一些)。
[3] 小核的AVX指令吞吐只有FMA的一半,与之前的架构一致,比起大核的差距拉的更大了(接近1/4)。
再加上Cache容量和架构上的精简,小核实现同样计算的效率肯定是不如大核的。所谓小核接近skylake的说法,至少在浮点或向量密集型生产力应用上,小核就是鸡肋,帮不上什么忙。
第四个表格小核多核吞吐与大核类似,同样也达不到8倍。
CPU并行编程的新挑战
其实这个挑战从移动端arm架构引入bigLittle就开始了,但终究与桌面和服务器端有所不同。移动端SoC发展到今天,高通已经搞出单个SoC里,实现1+2+2+3四种异构核心。一个大核的能力非常强,中间两种中核比较接近,比大核慢1/3到一半左右,小核性能极差,基本只是为了跑一些常规应用时降低功耗。这样的系统环境,再加上由于电池环境导致的小核优先调度策略,使并行编程难如登天。我们为手机和APP业务开发计算密集型应用,在使用多核编程时候问题非常多,要么降频,要么优先调度小核,且没法控制,甚至很多时候大小核需要不同的代码来达到最优性能,根本无法兼顾,所以很多时候只是用单个大核在跑应用,减少复杂性和混沌。还好随着GPU OpenCL/Vulkan环境,以及SoC里面的DSP和AI加速器日趋成熟,我们很多移动端的项目已经大量迁移到这些更高效能的处理器中。但是桌面和云端环境,我们终究是希望利用多个CPU核心以提升总的效率。尤其是云端还面临核数众多,NUMA非对称内存访问等问题。
并行计算在划分任务的时候,通常分为静态划分和动态划分,目标都是为了给不同计算核心分配均匀的负载,以追求线性加速。静态,是按照可并行的线程单元数量,平均划分任务,且在运行时不能改变任务划分方式。动态则是在运行时,根据各个线程的状态,动态分配任务,使多个线程动态调整自己的负载,大致达到均衡状态。前者的好处是方便开发,单个线程执行效率最高,对大多数并行度很好的程序有非常好的并行效果。后者的好处是可以根据运行时的各种突发问题做出调整,防止因条件变化导致任务负载不均。下面这个图展示了这两种调度方式在同构核心和异构大小核环境下的执行模式:
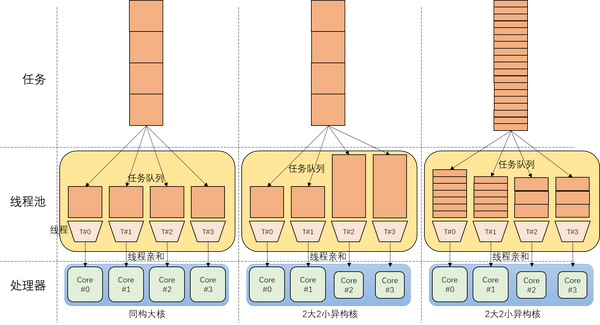
两种调度方式在同构多核和大小核异构情况下的调度结果
左边展示了同构大核使用静态调度的方式,一般可以取得不错的负载均衡。中间这个图换成2大2小的核心,对于小核心,同样的任务执行时间变长,导致静态调度后,负载不均衡。大小核对于不同任务的执行速度比例也可能不一样(比如大小核分别计算FFT,是2:1的吞吐;计算矩阵乘法可能就变成4:1。甚至同一种计算使用不同参数,这个比例也会改变),很难根据不同架构来分配不同大小的静态任务。唯一的办法,就如最后一张图所示,缩小单个任务的规模,增加任务数量,并进行动态调度,这样不同的处理器核可以根据自己的“胃口”,吃进适合自己的任务量,基本达到平衡。
过去的CPU都是同构核心,对于已有的,可以并行的软件和代码,为了开发简便,相当一部分并行的工作都是静态任务划分,比如简单调用OpenMP的循环并行。这样很容易造成大小核同时加速这个程序的时候,并行效果并不好。
同时,这种大量小任务动态调度的方式,还有一些问题:
对于这种调度方式,任务体量越小,数量越多,越容易达到负载均衡,均衡误差也越小。但是很多并行任务的并行度是有限的,可以拆成更细粒度的小任务是有上限的,天然限制了这个方案;同时每个任务有相对固定的拆分成本和调度成本,任务越多,拆分和调度的开销占比就越大。
另外,对于优化好流水线的单个计算任务来讲,如果拆成更小的任务,那么就会多出很多进出流水线的开销,如下图所示:
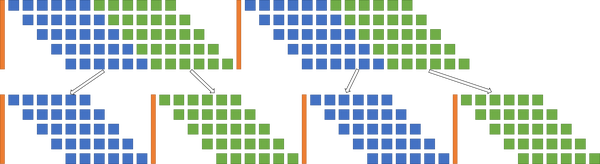
大任务拆成小任务时,总体执行的延迟增加
所以总的来说,静态任务改成大量小任务动态划分和调度的方式,效果有其极限,随着任务拆分越多,延迟变化呈U字形变化,先降低后升高。
结语
今后的CPU并行编程,我们要面对的困难更多了。除了要考虑核心越来越多,NUMA非对称这些问题,还要关注intel和arm这些CPU大小核的异构任务调度问题。操作系统对这些问题的解决能力十分有限,寄希望于新内核对调度系统的改进,其实是缘木求鱼,只要不添乱就好了。任何严肃的大规模系统软件和生产力系统,都必须自己解决资源的调度和优化。Intel最开始引入大小核的目的,其实是想在单核和多核两种场景都可以取得跑分的突破。但是忽略了对于现有大量遗留软件的适配难度问题,以及开发新软件带来的成本和难度的挑战。硬件性能的提升,还是尽量不要给软件带来太多负担为好。
作者:高洋
文章来源:知乎
推荐阅读
- 让AI生成AI绘画提示词,OpenAI最新成果ChatGPT被网友玩坏了!还会写代码修bug作诗
- 在JetsonNano上编译OpenCV源码与OpenCV C++ YOLOv5程序演示
- CVPR2022 人-物交互检测中结构感知转换
- bottom-up多层规约【图融合】策略
更多嵌入式AI干货请关注嵌入式AI专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

