
本文转载自知乎(https://zhuanlan.zhihu.com/p/571045566),作者凉风(https://www.zhihu.com/people/banzhuantou123456),是一位GPGPU/NPU方面的从业者,目前聚焦于AI编译器的工作,欢迎大家关注。
注:对原文做了一些修改和补充。
前言
目前AI DSA架构五花八门,不像CPU/GPU那么统一,面向DSA的编译软件栈也是各种轮子,未来何时能收敛是大家密切关注的话题。目前看来,硬件收敛应该还需要一些时间,毕竟DSA是结合应用场景定制的产物。对于编译软件栈来说,早些年的时候基于Caffe/Onnx甚至NCNN进行扩展开发,那个时候也更习惯叫AI工具链。用户换一个DSA平台就有新的学习成本,配置复杂还会导致很难发货DSA性能。因此在造新的DSA编译软件栈轮子的时候,按照传统编译器的思想进行解耦分层、减少用户的上手成本、性能提升等角度考虑。目前TVM/MLIR等开源AI编译器生态有一定起色,于是进入了TVM的坑(端侧对TVM的接受度更高)。

对于TVM来说,针对CPU/GPU等通用架构做了很多优化工作。我们的开发没有走BYOC路线(自身也没有现成编译软件栈,都需要0-1造所有轮子),于是就像CPU/GPU那样走relay->te->tir->(llvm)->dsa的路子,想沿用TVM上各种优秀的feature。
1、DSA优化基本思路
以CPU来说,cache不能显式操作,需要利用数据局部性来减少cache miss提高算力利用。对于DSA来说,是由一个可编程操作但容量较小的SRAM进行数据调度,需要尽可能的减少数据搬运而导致DSA处于空闲状态。
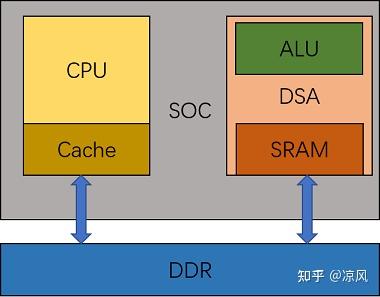
CPU与DSA结构
a、DSA指令粒度
对于CPU来说,Conv最终都归结为加减乘的基本运算。但对于DSA来说,Conv内部的操作已经固化在硬件里面,只需要进行输入输出配置就行了,下面是DSA上配置CONV指令的函数接口示例:(数据计算流可参考tflite)
dsa_call_conv(input_addr, kernel_addr, bias_addr, output_addr,
input_n, input_c, input_h, input_w, output_c, output_h, output_w,
i_nstride, i_cstride, i_hstride, i_wstride, o_nstride, o_cstride, o_hstride, o_wstride,
ins_h, ins_w, dh, dw, kh, kw, k_nstride, k_cstride, k_hstride, k_wstride,
pad_h_t, pad_h_b, pad_w_l, pad_w_r, using_bias, relu_type,
multiplier, shift, i_zp, k_zp, o_zp, i_dtype, k_dtype, b_dtype, o_dtype)40+的参数需要一次性全部配置才能运行Conv操作,粒度非常粗,一个for循环也没有。
b、优化思路
对于CPU来说,layer-by-layer优化,减少cache miss。对于DSA来说,layer-fused优化,减少中间数据倒腾。举个实际例子,假设有三个卷积如下:
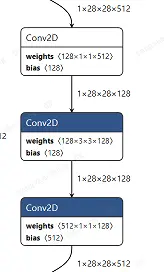
截取自resnet50
如果按照layer-by-layer的思路,对每个Conv output_h切割成2份(假设只有这样才能放入SRAM),假定DSA有512个MAC,数据总线宽度为128bit,可以如下折算layer-by-layer总共花了1159328个cycle。
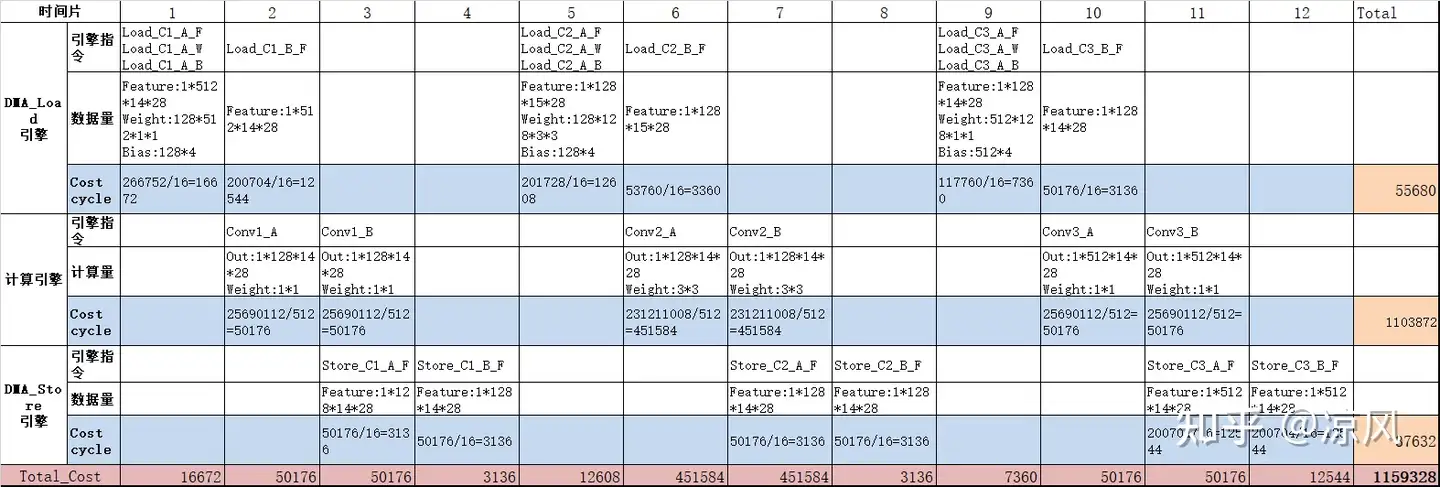
layer-by-layer cost cycle
如果按照layer-fused的思路,同样对每个Conv oh切割成2份,Cost折算如下:
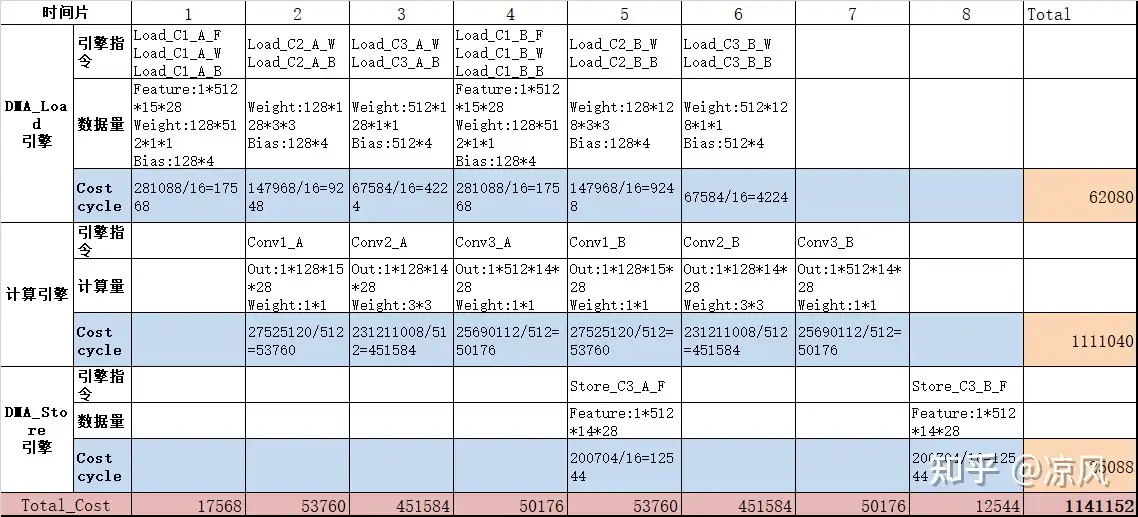
layer-fused cost cycle
layer-fused总共花了1141152个cycle,比layer-by-layer的方式减少了18176个cycle。此外,数据的总带宽也变少了,表格的总线latency都是按照0测算的。在SOC上,DSA的总线响应优先级比较低,outstanding配置也会被限制,一次burst可能需要数千cycle才能被响应。对应的cycle就多出数倍甚至数十倍。这也是单跑DSA和SOC满载业务下的性能差距比较大的重要原因。
性能上看起来是有提升了,需要注意的layer-fused减少了中间conv的数据搬运,但是会带来计算量(1111040>1103872)的增加,这是因为切分多卷积后输出锥形减少的,输入存在重叠部分导致计算量上升。fused的layer数量不是越多越好,需要结合硬件特性、网络模型结构综合来看。当然这里只是一个基本的优化思路,实际操作要考虑SRAM容量、切割调度策略、满算力约束、系统带宽等诸多因素。除了layer-fused优化思想外,也还有一些其他的优化思想。
c、性能指标
目前来说,绝大部分的DSA宣传跑resnet50是多少多少fps,对于用户来说无可厚非。但是开发人员要计算一下MAC利用率来推测性能水准,而不是看fps的绝对值。以NVDLA为参考如下:
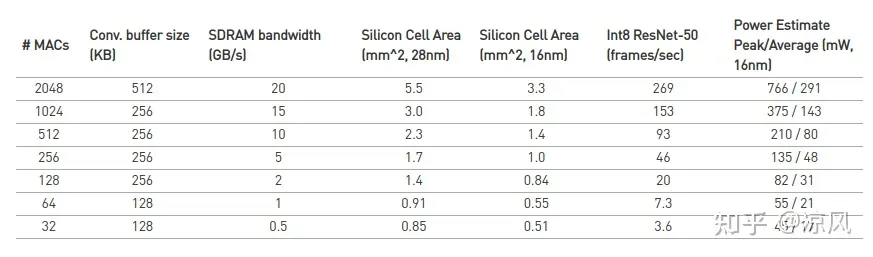
NVDLA PPA
以1T算力来说(512MAC),resnet50 MAC利用率为70.3%;对于4T(2048 MAC),MAC利用率为50.8%。1T算力下,毕竟面积小,这个MAC利用率算正常,当然可以增加一些feature来提升性能(面积功耗代价),1T的resnet 50是可以把MAC利用率做到85%以上。对于4T以上算力来说,NVDLA架构确实存在一些需要改进的点,所以MAC利用率下降比较多,做一些改进是可以将MAC利用率进行提升的,比如4T下resnet50到340fps,8T下Resnet50到650fps都可以不需要增加太多的开销。如果要更高算力可以通过叠加更多核来实现,对应的MAC利用率也会有一定下降,但不能太多。

不同算力下的Resnet50性能
不同的DSA对应着不同的场景,关注的模型是不一样的,这里用最常见的Resnet50来举例在不同算力下的MAC利用率情况。
d、PPA Trade-Off
如果只看模型fps的话,是可以通过硬件堆MAC(增大面积、提高了芯片的成本)来实现的,因此我们在看fps的同时也需要关注设计算力。 当然,仅仅看MAC利用率是不够的,除了fps/T之外,还需要关注mm^2/T,W/T,MB/T等指标综合对比。就以93 fps/T来说,业内也很少看到有芯片能达到这个性能。一方面是优化是否到位,另外一方面则是因为芯片需要进行功耗面积妥协。如用20%的面积来换10%的性能,就是一个非常划算的Trade-Off,毕竟在这样性能折损下MAC利用率也是比较可观的。
2、TVM中的一些工作
前面说了DSA的指令粒度、优化思路、性能结果,在TVM中进行落地开发面则临的一些对应的挑战。
a、指令粒度:由于DSA有的指令粒度粗,而relay/te非常细粒度,需要进行packed,尤其是在选配参数问题上一不小心就容易出Bug
b、layer-fused:从TVM的层次结构看,layer-fused放在relay层还算比较合适,但是一组layer-fused里面有很多conv等各种算子,因此lower的时候需要考虑拓扑结构和大量参数的传递。
c、tensor memory:进行layer-fused的时候,模型中间的tensor是不需要进行DDR交互的,因此涉及到内存分配和优化的问题。
d、inferbound:比如原始in shape=[1,ic,14,14],k\_size=1,k\_stride=2,这里out shape是[1,oc,7,7]。TVM的Inferbound会把in_shape变成[1,ic,13,13],看起来减少了数据量的操作,但是对于DSA来说会显著增加带宽消耗。
e、tir:指令排布、并行调度、时间片分配,SRAM管理等需要较多复杂的pass进行处理。
f、cost-model:当前的cost是直接利用程序运行的时间差来计算的。DSA一般是具备Cmodel进行cycle模拟的,而cycle是不关注程序执行时间,只看指令配置的。通过rpc连接DSA芯片在回片后也会介入,这样得到的最准确。此外还有以带宽作为cost的,毕竟SOC上系统带宽对性能的影响极大甚至挤压其他模块。
3、硬件的一些思考
从PPA的角度看,软件能直接可见的是Performance。AI DSA芯片本身就是基于CNN定制化的产品,因此AI编译器的开发也需要对于Power、Area密切关注,可以从更好的维度进行优化提升。
1、架构
对于端侧来说,从layout的角度看,DSA架构看起来其实也就那么几种,大家基本上都会参考NVDLA(NCHWc)。评估一个架构,既要结合落地场景需求,也要看看架构本身的性能、带宽瓶颈(系统带宽与SRAM带宽)。
2、面积
面积分两部分,DC面积和PR面积。
DC面积:主要是面积性能的trade-off,毕竟DSA是一个需要结合场景需求进行定制化的。比如对某些必须的配置做性能增强,对一些不太常用的配置进行面积裁剪,或者可以通过软件进行规避的配置,开合适大小的FIFO,前后级模块的流水承接,AI DSA芯片设计不仅仅是DE人员的事情,作为AI编译器开发人员,需要结合场景算法特点、优化策略参与进来,对面积性能都有较好的帮助。
PR面积:从物理实现角度上来看,内部各个模块的设计复杂度,是否有存在绕线拥塞问题导致物理实现代价比较大的,这个需要结合架构来看。
3、功耗
功耗分成峰值功耗和平均功耗:一般来说峰值功耗是通过错峰来对应,但核心问题还是怎么减少。比如设计阶段尽可能考虑减少数据的翻转、增加复用。而DSA本身是定制化的,那就进一步从cell的级别进行定制化固化对功耗就非常有帮助。功耗仿真分析的周期实在是太长了,前期设计的时候需要尽可能的考虑到可能的问题。
4、NVDLA架构思考
知乎上有不少文章已经分析的很清楚,作为一个开源的DSA架构,具备很高的参考价值。
a、满算力约束
前面提到的4T以上算力的MAC利用率下降的比较厉害。NVLDA的MAC是按照ic*ow*oc来进行配置的,其中ic=oc。比如512MAC就是8*8*8,2048MAC就是16*8*16,4096MAC就是16*16*16,也就是ic/ow/oc是对应的整数倍才能把算力打满。一般来说模型的第一层是1*3*224*224,ic=3与8/16就不能将算力打满,ow=8/16,但是模型的输出是7/13这种也会存在算力的浪费问题。
b、带宽功耗
取数进行计算的量对SRAM带宽和功耗有较大的影响,NCHWc的小c是8的整数倍,取数比较方便。进一步考虑通过数据的复用来减少取数的频率,对功耗有很大的帮助,当然也会带来一些面积的开销,需要结合具体情况来取舍。
5、总结
做一个自定义推理框架想把性能做好都很不容易,要结合TVM来深度开发就完全是给自己挖了个大坑。从当前的工作来看,总体上把TVM串起来了,同时性能上也有不错的结果,但是还有很多地方需要完善。在开发的过程中,软硬件的密切交流配合对PPA的提升非常有帮助,对AI编译器开发的人员来说,能更好的理解各种优化策略的影响与局限,并且结合场景也可以让芯片PPA指标更有竞争力,也会让工作更有趣。

对于AI来说,生态问题一直是大家密切关注的点,有TVM的生态、优异的性能、灵活的异构(DSA+GPU/DSP),相信未来在端侧会有更大的落地空间与更小的落地成本,并成为行业发展的趋势。欢迎各位大佬指点交流,一起学习提高。
作者:开心的派大星
文章来源:NeuralTalk
推荐阅读
- BYOC:加速器硬件接入深度学习编译器的统一框架
- 爱奇艺在DCN、EDVR等 4K 超分模型上的 TensorRT 10倍加速实践
- GTC 2022:GPU推理加速在OPPO NLP场景的优化落地
- AI时代视频云转码的移动端化:让模型设计/推理库/硬件成为一体
更多嵌入式AI干货请关注 嵌入式AI 专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

