
恩,这个系列的第一篇文章,先谈点轻松的,常用CPU架构浮点峰值的理论计算和实测。做性能优化,先要知己知彼,了解自己优化的CPU的能力上限。这样优化做到什么程度,心里会有数。
本文只介绍Intel x86-64架构,并且只针对单精度float类型。浮点峰值的计算,一般是计算单位时间内,乘法和加法的最大总吞吐量,单位是GFLOPS或者TFLOPS,表示每秒钟计算乘法和加法的总次数。
乘法和加法可能涉及到的指令包括:单独的乘法指令,如vmulps;单独的加法指令,如vaddps;融合乘加指令,如vfmadd231ps等。后者将乘法和加法融合为一条指令,在多数处理器中,三种指令都可以在一个发射端口每周期发射一条,所以乘加指令往往比单独使用乘法或者加法带来翻倍的吞吐量。
先来看x86-64,Intel在2010年推出Sandy Bridge架构(下面简称SNB),首次引入了256位宽的向量指令集AVX,即一条指令可以同时操作8组32位宽的数据类型。SNB架构示意图如下:
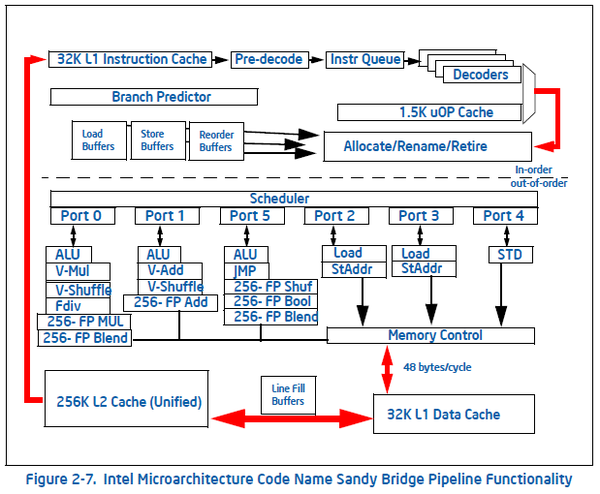
六个dispatch ports,其中port0和port1各有一条向量乘法(256-FP MUL)和向量加法(256-FP Add),即一个周期内,SNB架构可以吞吐一条浮点向量乘法和浮点向量加法。由于AVX指令集还不支持融合乘加FMA,浮点峰值计算只能使用这两条指令的总和吞吐量。
综上所述,SNB架构的理论浮点峰值就等于(8Mul + 8Add) * 核心频率 * 核心数。例如SNB桌面高端的i7 2600k,有四个核心,关闭睿频后每核心频率3.4GHz,所以这款CPU的理论浮点峰值(关闭睿频)就是(8+8)*3.4*4=217.6GFLOPS。
如果想写一个小程序实测的话,可以这样设计:设置一个简单的循环,次数足够多,保证每次循环执行一个时钟周期,发射两条无依赖的vmulps和vaddps指令:
.loop:
vmulps %ymm2, %ymm2, %ymm1
vaddps %ymm4, %ymm4, %ymm3
sub $0x1, %rax
jne .loop.loop是循环体;前两条vmulps和vaddps指令,输入和结果使用不同的寄存器,这样前后两个相邻循环的同一条指令产生WAW型寄存器依赖,通过寄存器renamer部件可以解决;然后用sub指令每次给rax寄存器里的循环计数减一,如果减到0,会修改状态寄存器的值,jne指令不会跳转,循环结束。sub指令和jne指令在SNB架构下和可以做到宏融合,形成单一的微指令,不会产生延迟,在port5和前面的乘法加法同周期分派。
由于本人手头没有SNB架构的处理器,暂时不能测试。SNB下一代微架构Ivy Bridge只是工艺升级版的SNB,各种特性几乎和SNB一样。我们再看下一代,即2013年推出的Haswell架构:
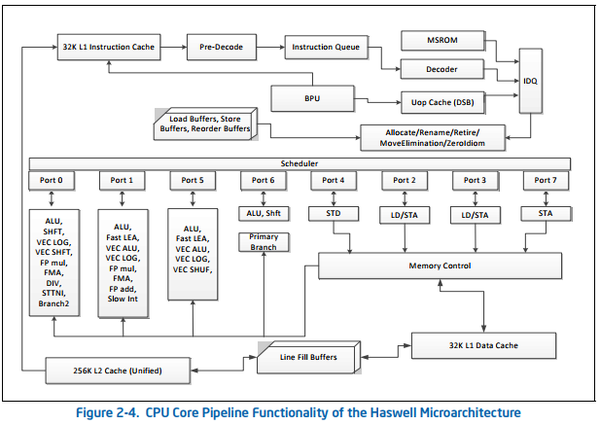
Haswell架构增加了AVX2和FMA指令集,其中FMA指令集就是256位的融合乘加指令,根据架构图中所示,port0和port1端口各有一个FMA单元,所以Haswell架构的理论峰值就等于2port * 8 * 2(mul+add) * 频率 * 核心数。例如i7系列的最高版本i7 4790k,四核心,关闭睿频固定4GHz频率,那么浮点峰值就是2 * 8 * 2 * 4 * 4 = 512 GFLOPS,每个核心的峰值就是128 GFLOPS。
如果要实测Haswell的理论峰值,与SNB大部分思路是相同的。除了用到不同的指令以外,与SNB还有如下一些区别:fma指令的某个参数寄存器,既做输入也做输出,这样前后两个相邻循环间的同一条fma,就形成了RAW型寄存器依赖。所以如果每个循环还要求一个周期执行,并发射两条fma指令,相邻循环间肯定就会有数据依赖发生,要等待前一个循环的两条fma执行完毕才能进行第二次循环的两条fma,这就会导致流水线停顿,浪费时钟周期。假设fma指令的执行周期是k,那么解决办法就是一次循环内安排2k个数据无依赖的fma指令。经过试验,我们发现放10条fma指令到一个周期,浮点吞吐刚好达到最大值:
.loop:
vfmadd132ps %ymm0, %ymm0, %ymm0
vfmadd132ps %ymm1, %ymm1, %ymm1
vfmadd132ps %ymm2, %ymm2, %ymm2
vfmadd132ps %ymm3, %ymm3, %ymm3
vfmadd132ps %ymm4, %ymm4, %ymm4
vfmadd132ps %ymm5, %ymm5, %ymm5
vfmadd132ps %ymm6, %ymm6, %ymm6
vfmadd132ps %ymm7, %ymm7, %ymm7
vfmadd132ps %ymm8, %ymm8, %ymm8
vfmadd132ps %ymm9, %ymm9, %ymm9
sub $0x1, %rax
jne .loop所以haswell架构下fma指令的执行延迟就是5个周期。感兴趣的同学可以试试改变循环内fma指令数量,看看测出来的GFLOPS有何变化。
我在自己的i7 4790k上测试了这个例子,结果如下:
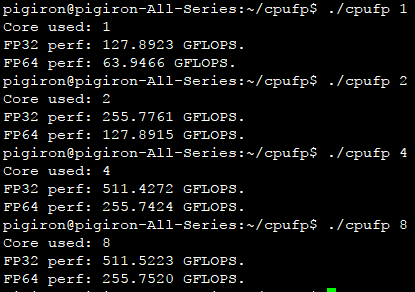
测试同时包含了单精度和双精度两种,分如下四种情况:单线程,双线程,四线程和八线程。i7 4790k是四核八线程的处理器,所以根据前三组测试可以发现,实测峰值和理论峰值极为接近,与使用核心数量严格成比例。最后一组八线程使用了i7处理器的八个超线程,发现测出来的值和四线程几乎一样。这是由于超线程只是为每个核心提供两组线程上下文单元,两个线程其实是共享各种核内运算部件的。超线程的好处是线程之间往往没有各种数据依赖关系,两个线程的指令流可以尽量填充流水线并充分利用乱序多发射能力。互相掩盖对方的各种延迟,提高每个核心的利用效率。我们这个测试程序已经完整地利用了浮点乘加的吞吐能力,所以超线程并不带来好处。
同样的方法也可以测试ARM架构的CPU浮点峰值,但是需要注意ARM NEON指令包含两种乘加方式:向量乘向量,以及向量乘标量。注意这两种方式的指令延迟可能是不一样的,差距甚至会比较大,需要分别测出两者的延迟。Intel也已经推出了基于Skylake-X架构的AVX512指令集的Xeon服务器CPU,在FMA指令的基础上又提升了一倍的浮点峰值性能。新的架构很有意思,高端版本支持一个周期发射两条AVX512版本的乘加指令,其中一条来自port0和port1的256位FMA的端口融合,另外一条来自port5。中低端版本的Skylake-X就去掉了port5的乘加单元,只与Haswell的浮点能力相当。大家在选购服务器的时候一定要考察清楚。
有了峰值性能的数据,我们在写矩阵乘法和卷积运算这些计算密集型算法的时候,就有了一个理论上限。通过测试结果与理论上限的差距,评估算法的可能优化空间。除了浮点峰值性能,还有很多处理器的指标对我们优化和评估程序性能都有重要意义,例如内存带宽和延迟,各级cache的带宽和延迟,分支预测失败的惩罚周期...... 本文就不一一展开详述了。
上面测试汇编代码的完整版本我放在了github上:pigirons/cpufp
参考资料:
[1] Intel® 64 and IA-32 Architectures Software Developer’s Manual
[2] Intel® 64 and IA-32 Architectures Optimization Reference Manual
[3] 《探求计算性能的极限》,王琤
[4] Intrinsics Guide
作者:高洋
文章来源:知乎
推荐阅读
- 项目开源!基于PaddleDetection打造实时人体姿态检测的多关节控制皮影机器人
- 自制深度学习推理框架-张量类Tensor的实现-第二课
- Windows 版的3D目标检测框架 smoke PyTorch 实现
- 回顾2022年计算机视觉领域最激动人心的进展
- 量化部署篇 | Vision Transformer应该如何进行PTQ量化?这个方法或许可以参考!
更多嵌入式AI干货请关注嵌入式AI专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

