
PyTorch 2.0 于 2022 年 12 月上旬在 NeurIPS 2022 上发布,它新增的 torch.compile 组件引起了广泛关注,因为该组件声称比 PyTorch 的先前版本带来更大的计算速度提升。

这对我们来说是一个好消息,训练时间改进的结果令人印象深刻。PyTorch 团队在发布新闻稿和 PyTorch GitHub 上没有提到的是 PyTorch 2.0 推理性能。所以我们来对推理的速度做一个简单的研究,这样可以了解 PyTorch 2.0 如何与其他推理加速器(如 Nvidia TensorRT 和 ONNX Runtime)是否还有差距。
我们使用 Nebuly 的开源库 Speedster 运行了一些推理测试,对于这个我们这个测试,Speedster 允许我们运行 TensorRT、ONNX Runtime,并将它们与 16 位和 8 位动态和静态量化相结合(仅用 2 行代码)。在测试期间,我们还使用 Speedster 收集有关顶级策略的性能信息,以减少推理延迟。
这次测试是在带有 ResNet 的 Nvidia 3090Ti GPU 进行的,与 PyTorch 2.0 新闻稿中示例中使用的模型相同。
PyTorch 2.0 的推理性能结果如下图:
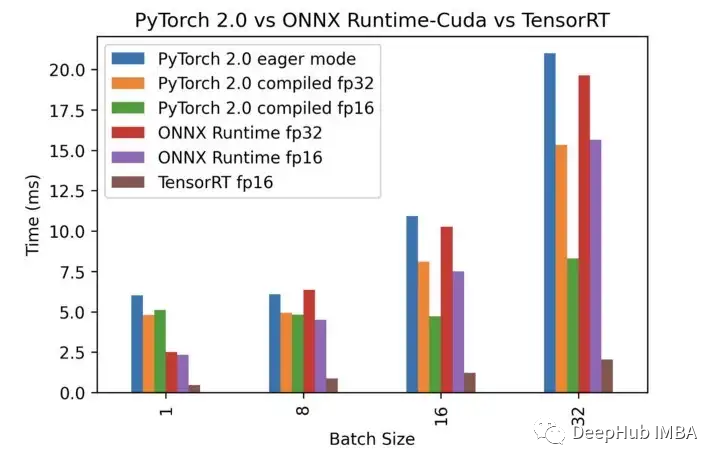
以下是测试结果的 4个要点总结:
- 批量大小越大PyTorch 2.0 的速度提升越明显(与前版本相比)。fp16的精度在大批次时比fp32编译版本更有效,这应该是因为Pytorch 2.0编译主要是为训练而设计的,训练的批大小一般会高于推理(线上产品使用时)。对fp16的优化是很正常的,因为在训练时,我们一般都会使用混合精度,特别是对于大型模型来说。
- ONNX Runtime 在较小的批量大小下比 PyTorch 2.0 表现更好,而在较大的批量大小下结果恰恰相反。这也是因为 ONNX Runtime 主要是为推理而设计的(通常使用较小的批大小),而PyTorch 2.0 的主要目标是训练。
- PyTorch eager 模式和 PyTorch 2.0(已编译)都显示批大小 1 和 8 的运行时间相同。这说明批大小等于 1 时没有使用全部计算能力,而其他推理的优化器,如 ONNX 运行时能够更好地管理计算能力。还是那句话这可能与 PyTorch 编译器主要为训练而设计有关,它会忽略批大小不足以使用其内核的所有计算能力的情况。
- 在经过测试的 Nvidia GPU 上,TensorRT 在小批量和大批量方面的表现都远远优于其他。随着批量大小的增加,相对速度变得更快。这显示了 Nvidia 能够在推理时更好地利用硬件缓存,因为激活占用的内存随着批量大小线性增长,适当的内存使用可以大大提高性能。
基准测试高度依赖于所使用的数据、模型、硬件和优化技术。为了在推理中获得最佳性能,始终建议在将模型部署到生产环境之前测试。
参考
Speedster 是一个开源工具,可硬件上自动应用 SOTA 优化技术实现最大的推理加速。
本文的代码在这里:
https://avoid.overfit.cn/post/0db857b606044b1db30210e32ca071af

