
LayerNorm 一直是 Transformer 架构的重要组成部分。如果问大多人为什么要 LayerNorm,一般的回答是:使用 LayerNorm 来归一化前向传播的激活和反向传播的梯度。
其实这只是部分正确:Brody、Alon 和 Yahav 的一篇题为“On the Expressivity Role of LayerNorm in Transformer's Attention”的新论文表明,LayerNorm 的作用要深得多。
LayerNorm其实为Transformer的Attention提供了两个重要的功能:
1、Projection:LayerNorm 帮助 Attention 设计一个注意力查询,这样所有的Key都可以平等地访问。它通过将Key向量投影到同一个超平面上来实现这一点,从而使模型能够将查询对齐。这样一来,Attention 组件就无需自己学习如何执行此操作。
论文包含了更精细的细节,比如论文中的这图片可以让我们进行可视化的查看
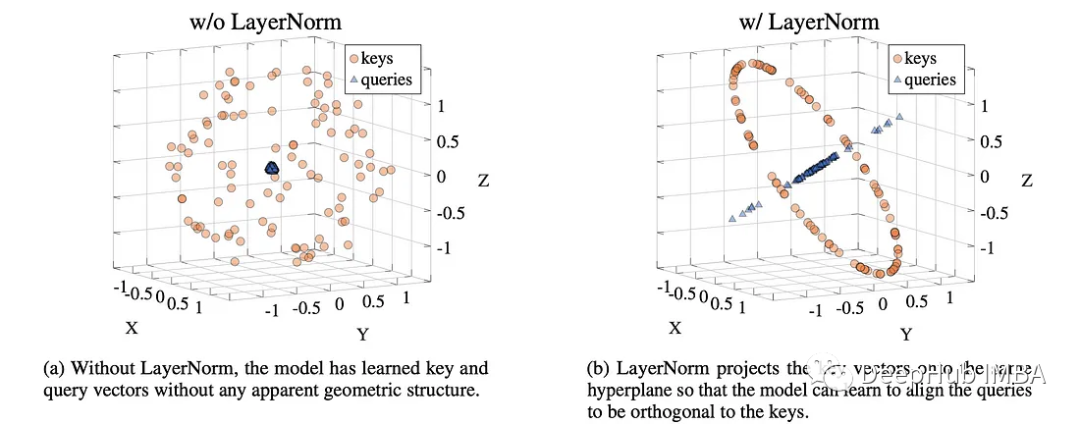
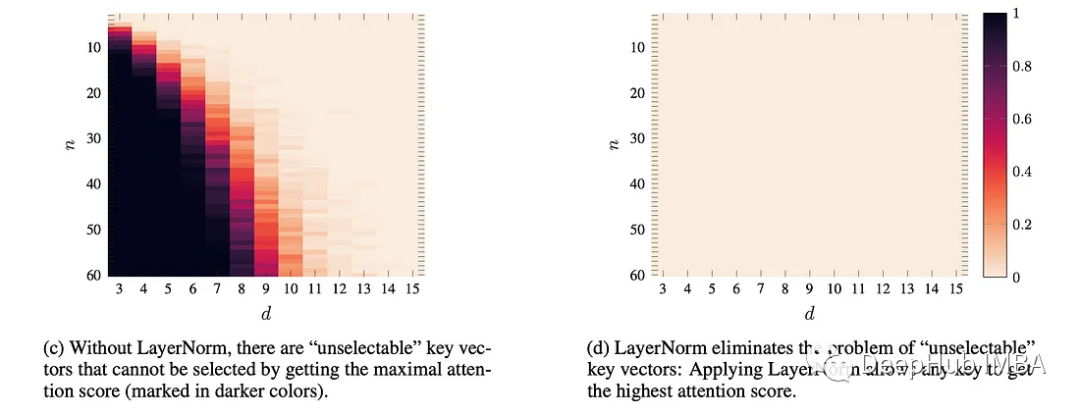
2、Scaling:这是更明显的部分,LayerNorm 重新缩放输入。但这种重新缩放做了什么呢?根据这篇论文潜在的好处是有两个好处:
每个Key都有可能获得“最高”关注
没有Key可以在“un-selectable”区域结束。
论文中的第二张图片在视觉上给了我们答案:
他们还注意到:Attention 之后的 LayerNorm仍然实现了相同的目的,但是作用是用于下一个 Attention 块的。并且在较大的 Transformer 模型中,这些好处似乎并不那么明显。论文认为这是由于更大尺寸的模型能够找到替代解决方案(也就是上面说的Attention不需要帮助而是自己学习到了如何执行这个操作)。
但是 LayerNorm 的确隐含地具有两个核心功能,即投影和缩放。这篇论文的细节要多得多,本文的总结并以直观的形式展示这两个主要发现,因为这论文中这两个图可以直接的表达这个内容。
如果你像详细阅读,论文地址:
https://avoid.overfit.cn/post/ac6bbc9b20fb4bd292009d0a5370bb46
作者:Less Wright

