
金融领域:产业链知识图谱包括上市公司、行业和产品共3类实体,构建并形成了一个节点10w+,关系边16w的十万级别产业链图谱
包括上市公司所属行业关系、行业上级关系、产品上游原材料关系、产品下游产品关系、公司主营产品、产品小类共6大类。 上市公司4,654家,行业511个,产品95,559条、上游材料56,824条,上级行业480条,下游产品390条,产品小类52,937条,所属行业3,946条。
领域知识图谱的数据集,当前还比较缺失,而作为构建难度最大的产业链图谱领域更为空白。产业链作为产业经济学中的一个概念,是各个产业部门之间基于一定的技术经济关联,并依据特定的逻辑关系和时空布局关系客观形成的链条式关联关系形态。从本质上来说,产业链的本质是用于描述一个具有某种内在联系的企业群结构,产业链中大量存在着上下游关系和相互价值的交换,上游环节向下游环节输送产品或服务,下游环节向上游环节反馈信息。
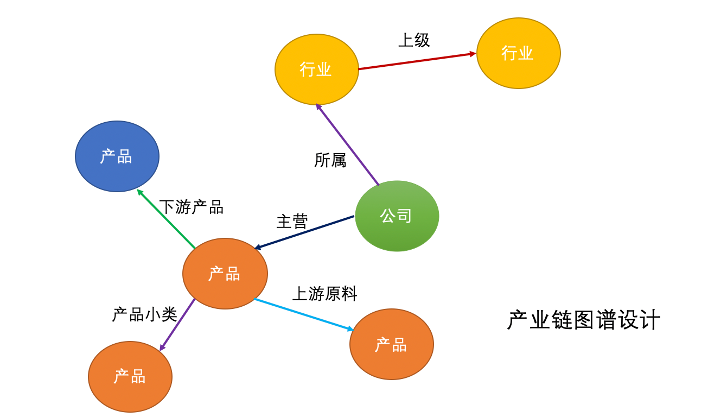
1.项目构成
产业链知识图谱包括A股上市公司、行业和产品共3类实体,包括上市公司所属行业关系、行业上级关系、产品上游原材料关系、产品下游产品关系、公司主营产品、产品小类共6大类。
通过数据处理、抽取,最终建成图谱规模数十万,其中包括上市公司4,654家,行业511个,产品95,559条、上游材料56,824条,上级行业480条,下游产品390条,产品小类52,937条,所属行业3,946条。
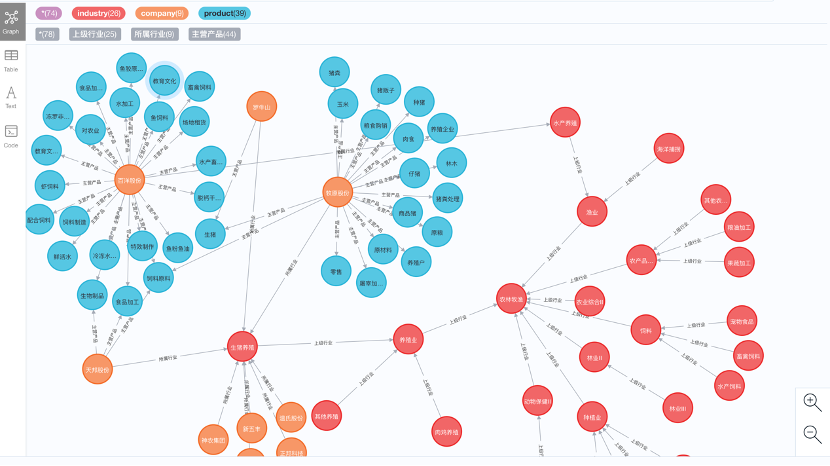
2.项目构建
2.1 实体构建
2.1.1 上市公司
目前上市公司已经达到四千多家,是我国重要的公司代表与行业标杆,本图谱选取上市公司作为基础实体之一。通过交易所公开信息中,可以得到上市公司代码、全称、简称、注册地址、挂牌等多个信息。

2.1.2 行业分类
行业是产业链图谱中另一个核心内容,也是承载产业、公司及产品的一个媒介,通过这一领携作用,可以生产出大量的行业指数、热点行业等指标。
目前关于行业,已经陆续出现多个行业规范,代表性的有申万三级行业分类、国民经济行业分类等。中国上市公司所属行业的分类准则是依据营业收入等财务数据为主要分类标准和依据,所采用财务数据为经过会计事务所审计并已公开披露的合并报表数据。
2021年6月,申万发布了2021版的行业分类规范,将1级行业从28个调整至31个、2级行业从104个调整至134个、3级行业从227个调整至346个,新增1级行业美容护理等,新增2级行业,并将上市公司进行了归属。本图谱选用申万行业作为基础数据。

2.1.3 业务产品
业务产品主要指公司主营范围、经营的产品,用于对一个公司的定位。可以从公司的经营范围、年报等文本中进行提取得到。

2.2 关系构建
2.2.1 公司所属行业
通过公开的上市公司行业分类表,可以得到上市公司所对应的行业分类数据。

2.2.2 行业上级关系
通过公开的行业三级分类情况,可以通过组合的形式得到行业之间的上级关系数据。

2.2.3 公司主营产品关系
上市公司的经营产品数据可以从两个方面来获得,一个是从公司简介中的经营范围中结合制定的规则进行提取,另一个是从公司每年发布的半年报、年报中进行提取。这些报告中会有按经营业务、经营产品、经营地域等几个角度对公司的营收占比进行统计,也可以通过制定规则的方式进行提取。第二种方法中,由于已经有统计数据,所以我们可以根据占比数据大小,对主营产品这一关系进行赋值。

4)产品之间的上下游关系
产品之间的上下游关系,是展示产品之间传导逻辑关系的一个重要方法,包括上游原材料以及下游产品两大类。我们可以多种来获取:
一种是基于规则模式匹配的方式进行抽取,如抽取上游原材料这一关系可以由诸如"a是b的原料/原材料/主要构件/重要原材料/ 上游原料"的模式进行抽取",而下游产品,则同理可以通过"A是B的下游成品/产品"等模式进行提取。
另一种是基于序列标注的提取。还有一种是基于现有结构化知识图谱的提取,例如已经结构化好的百科知识三元组,可以通过设定谓词及其扩展进行过滤。

5)产品之间的小类关系
对于一个产品而言,其是有大小层级分类的,在缺少大类产品名称的时候,可以通过计算小类产品来得到相应指标。与产品之间的上下游数据类似,可以通过启发式规则的方式进行提取,如“A是一种B”,也可以通过字符之间的组成成分进行匹配生成,如“螺纹钢”是“精细螺纹钢”的一个大类。

3.项目运行
- data文件夹下包括了本项目的数据信息:
1)company.json:公司实体数据
2)industry.json:行业实体数据
3)product.json:产品实体数据
4)company_industry.json:公司-行业关系数据
5)industry_industry.json:行业-行业关系数据
6)product_product.json:产品-产品数据
7)company_product.json:公司-产品数据
2、项目运行:
python build_graph.py
import os
import json
from py2neo import Graph,Node
class MedicalGraph:
def __init__(self):
cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])
self.company_path = os.path.join(cur_dir, 'data/company.json')
self.industry_path = os.path.join(cur_dir, 'data/industry.json')
self.product_path = os.path.join(cur_dir, 'data/product.json')
self.company_industry_path = os.path.join(cur_dir, 'data/company_industry.json')
self.company_product_path = os.path.join(cur_dir, 'data/company_product.json')
self.industry_industry = os.path.join(cur_dir, 'data/industry_industry.json')
self.product_product = os.path.join(cur_dir, 'data/product_product.json')
self.g = Graph(
host="127.0.0.1", # neo4j 搭载服务器的ip地址,ifconfig可获取到
http_port=7474, # neo4j 服务器监听的端口号
user="neo4j", # 数据库user name,如果没有更改过,应该是neo4j
password="123456")
'''建立节点'''
def create_node(self, label, nodes):
count = 0
for node in nodes:
bodies = []
for k, v in node.items():
body = k + ":" + "'%s'"% v
bodies.append(body)
query_body = ', '.join(bodies)
try:
sql = "CREATE (:%s{%s})"%(label, query_body)
self.g.run(sql)
count += 1
except:
pass
print(count, len(nodes))
return 1
"""加载数据"""
def load_data(self, filepath):
datas = []
with open(filepath, 'r') as f:
for line in f:
line = line.strip()
if not line:
continue
obj = json.loads(line)
if not obj:
continue
datas.append(obj)
return datas
'''创建知识图谱实体节点类型schema'''
def create_graphnodes(self):
company = self.load_data(self.company_path)
product = self.load_data(self.product_path)
industry = self.load_data(self.industry_path)
self.create_node('company', company)
print(len(company))
self.create_node('product', product)
print(len(product))
self.create_node('industry', industry)
print(len(industry))
return
'''创建实体关系边'''
def create_graphrels(self):
company_industry = self.load_data(self.company_industry_path)
company_product = self.load_data(self.company_product_path)
product_product = self.load_data(self.product_product)
industry_industry = self.load_data(self.industry_industry)
self.create_relationship('company', 'industry', company_industry, "company_name", "industry_name")
self.create_relationship('industry', 'industry', industry_industry, "from_industry", "to_industry")
self.create_relationship_attr('company', 'product', company_product, "company_name", "product_name")
self.create_relationship('product', 'product', product_product, "from_entity", "to_entity")
'''创建实体关联边'''
def create_relationship(self, start_node, end_node, edges, from_key, end_key):
count = 0
for edge in edges:
try:
p = edge[from_key]
q = edge[end_key]
rel = edge["rel"]
query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s]->(q)" % (
start_node, end_node, p, q, rel)
self.g.run(query)
count += 1
print(rel, count, all)
except Exception as e:
print(e)
return
'''创建实体关联边'''
def create_relationship_attr(self, start_node, end_node, edges, from_key, end_key):
count = 0
for edge in edges:
p = edge[from_key]
q = edge[end_key]
rel = edge["rel"]
weight = edge["rel_weight"]
query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{%s:'%s'}]->(q)" % (
start_node, end_node, p, q, rel, "权重", weight)
try:
self.g.run(query)
count += 1
print(rel, count)
except Exception as e:
print(e)
return
if __name__ == '__main__':
handler = MedicalGraph()
handler.create_graphnodes()
handler.create_graphrels()4.项目总结
产业链图谱是众多领域知识图谱中较为棘手的一种,本项目通过现有的数据,借助数据处理、结构化提取方式,设计、构建并形成了一个节点100,718,关系边169,153的十万级别产业链图谱。就产业链图谱的构建而言,我们需要至少从以上三个方面加以考虑:
- 其一,产业链的主观性与标准性。产业链的主观性较强,不同的人对产业链的构建、产业链节点、关系的类型,产业链的颗粒度问题都有不同的理解。不同的设定会直接导致不同的应用结果。正如我们所看到的,目前存在不同的行业标准,不同的网站、机构也将公司归为不同的行业。
- 其二,产业链的动态性和全面性。产业链需要具备足够大的复用性和扩展性,几千家上市公司实际上是冰山一角。国内有几千万家公司,而且不断会有新增,如何将新增的公司融入到这个额产业链中,也是一个很大挑战。此外,产业本身是动态的, 随着行业的发展,不断会有新的行业出现。如何捕捉这种行业的变化,使得整个图谱变得与时俱进,也是需要考量的点。
- 其三,产业链的定量推理特性。单纯定性的构建产业链知识图谱,如果没有足够的参数,仅有知识表达是无法进行推理的,推理要求知识图谱Schema具备节点间推理传导的必备参数,以及影响推理传导的其他关键参数。对于必备参数来说,从公司到产品必须有主营占比、市场占比、产能占比等数据,从产品到产品必须有成本占比和消耗占比等数据。
- 参考数据来源
1、申万行业:http://www.swsindex.com
2、深交所: http://www.szse.cn
3、上交所: http://www.sse.com.cn
项目链接:
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。



