
本文将用数据可视化的方法解释4种支持向量机核函数和参数的区别
简单地说,支持向量机(SVM)是一种用于分类的监督机器学习技术。它的工作原理是计算一个最好地分隔类的最大边距的超平面。

支持向量机除了提供简单的线性分离之外,还可以通过应用不同的核方法进行非线性分类。参数设置也是SVM更好地工作的另一个重要因素。通过适当的选择,我们可以使用支持向量机来处理高维数据。
本文旨将使用Scikit-learn库来展示每个核函数以及如何使用不同的参数设置。并且通过数据可视化进行解释和比较。
如果你正在寻找常见数据集(如Iris Flowers或Titanic)之外的另一个数据集,那么poksammon数据集可以是另一个选择。尽管你可能不是这些口袋怪物的粉丝,但它们的属性很容易理解,并且有各种各样的特征可供使用。
Pokemon的属性,如hp,攻击和速度,可以作为连续变量使用。对于分类变量,有类型(草、火、水等)、等级(普通、传奇)等。此外,如果有新一代或Pokemon出现,数据集将在未来进行更新。
免责声明:Pokemon和所有相关名称均为任天堂公司的版权和商标。
导入数据和库
为了直观地展示每个SVM的内核是如何分离分类的的,我们将只选择baby, legendary, mythical。我们先从导入数据和库开始。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('pokemons.csv', index_col=0)
df.reset_index(drop=True, inplace=True)
df = df[df['rank'].isin(['baby', 'legendary'])]
df.reset_index(drop=True, inplace=True)
df.head()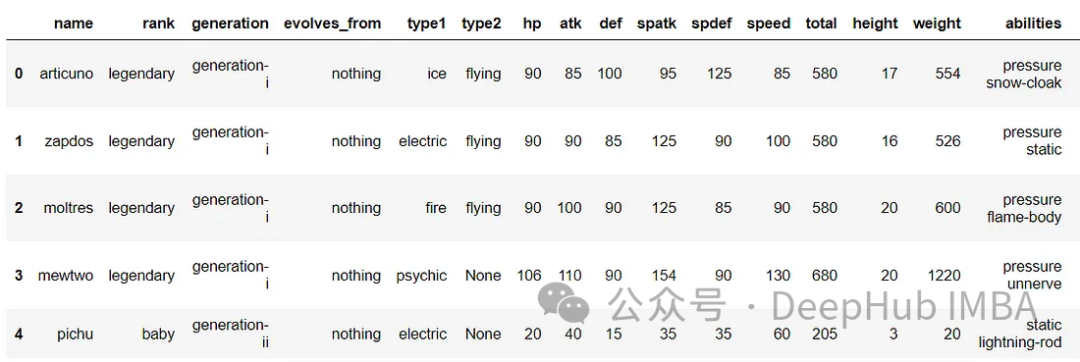
EDA
Pokemon有7种基本的属性- hp,攻击,防御,特殊攻击,特殊防御,速度和高度。下面的步骤是使用我们选择的统计数据执行一个快速EDA。
select_col = ['hp','atk', 'def', 'spatk', 'spdef', 'speed', 'height']
df_s = df[select_col]
df_s.info()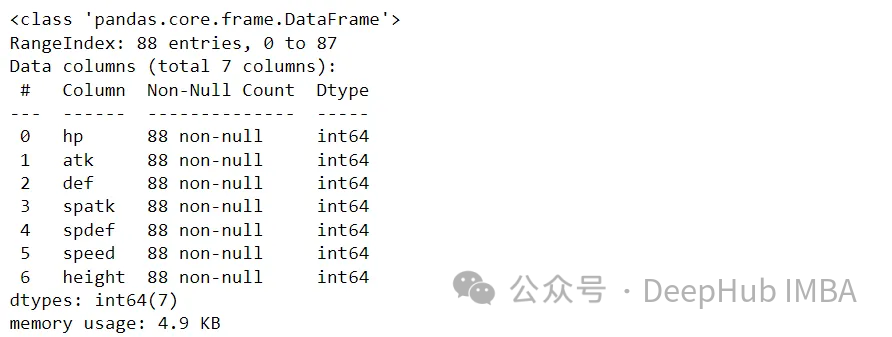
幸运的是,没有空值。接下来,让我们绘制Box和Whisker图,以查看这些变量的分布。
sns.set_style('darkgrid')
df_s.iloc[:,].boxplot(figsize=(11,5))
plt.show()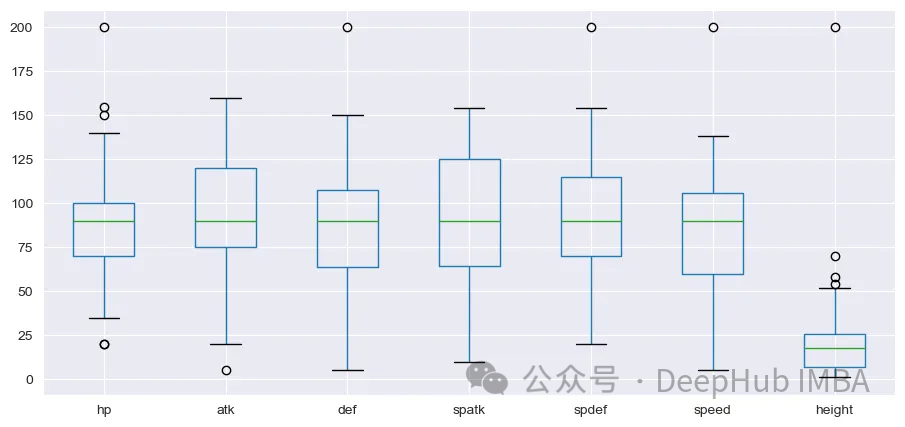
height变量的分布与其他变量有很大的不同。在继续之前应该执行标准化。我们将使用来自sklearn的StandardScaler来进行处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
array_s = scaler.fit_transform(df_s)
df_scal = pd.DataFrame(array_s, columns=[i+'_std' for i in select_col])
df_scal.boxplot(figsize=(11,5))
plt.show()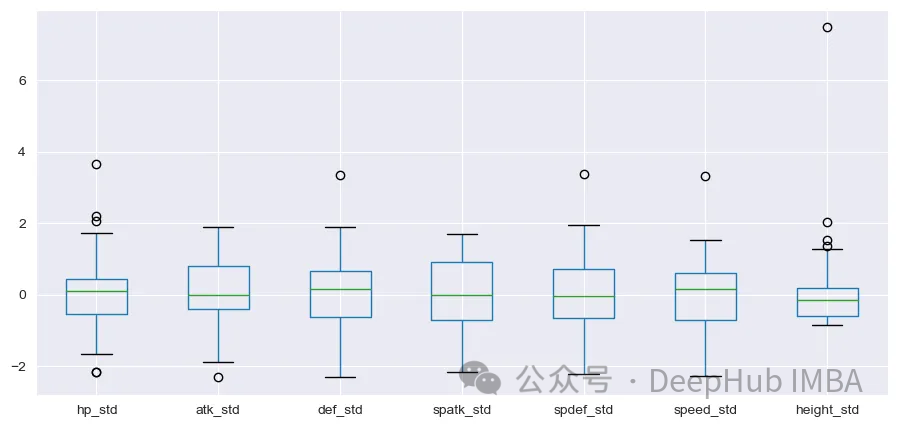
标准化之后,分布看起来更好。
由于我们的数据集有多个特征,我们需要进行降维绘图。使用来自sklearn.decomposition的类PCA将维数减少到两个。结果将使用Plotly的散点图显示。
from sklearn.decomposition import PCA
import plotly.express as px
#encoding
dict_y = {'baby':1, 'legendary':2}
df['s_code'] = [dict_y.get(i) for i in df['rank']]
df.head()
pca = PCA(n_components=2)
pca_result = pca.fit_transform(array_s)
df_pca = pd.DataFrame(pca_result, columns=['PCA_1','PCA_2'])
df = pd.concat([df, df_pca], axis=1)
fig = px.scatter(df, x='PCA_1', y='PCA_2', hover_name='name',
color='rank', opacity=0.9,
color_discrete_sequence=['red', 'blue'])
fig.update_xaxes(showgrid=False)
fig.update_yaxes(showgrid=False)
fig.show()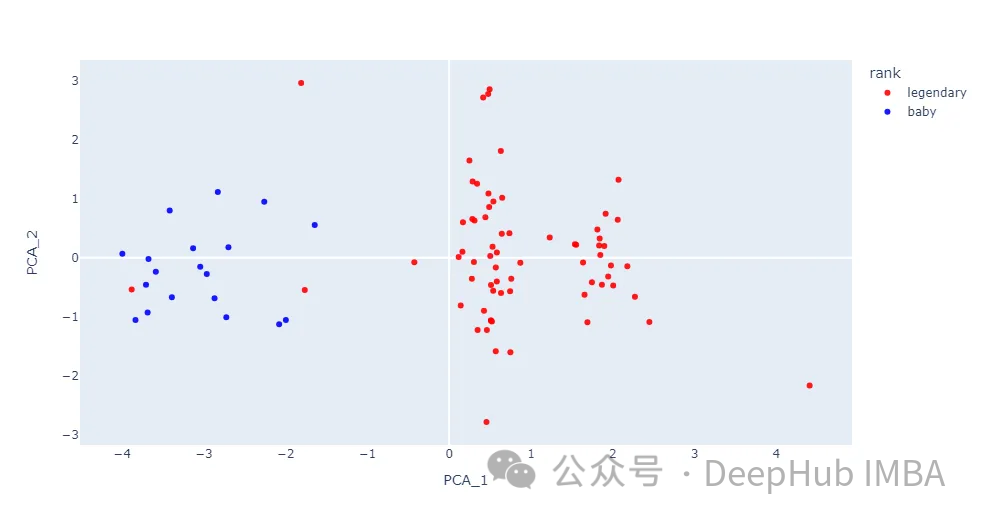
我们把Pokemon图片带入散点图。

再次免责声明:Pokemon和所有相关名称均为任天堂公司的版权和商标。
baby和legendary这两个类别之间的大多数数据点是分开的。尽管这两个类并没有完全分离,但在本文中对每个内核函数进行实验还是很有用的。
下一步是在三维空间中获得更多细节。让我们将PCA组件的数量更改为三个。这是3D散点图可以显示的最大数字。
pcaz = PCA(n_components=3)
pcaz_result = pcaz.fit_transform(array_s)
df_pcaz = pd.DataFrame(pcaz_result, columns=['PCAz_1', 'PCAz_2', 'PCAz_3'])
df = pd.concat([df, df_pcaz], axis=1)
fig = px.scatter_3d(df, x='PCAz_1', y='PCAz_2', z='PCAz_3', hover_name='name',
color='rank', opacity=0.9,
color_discrete_sequence=['red', 'blue'])
fig.update_traces(marker=dict(size=4))
fig.update_layout(margin=dict(l=0, r=0, t=0, b=0))
fig.show()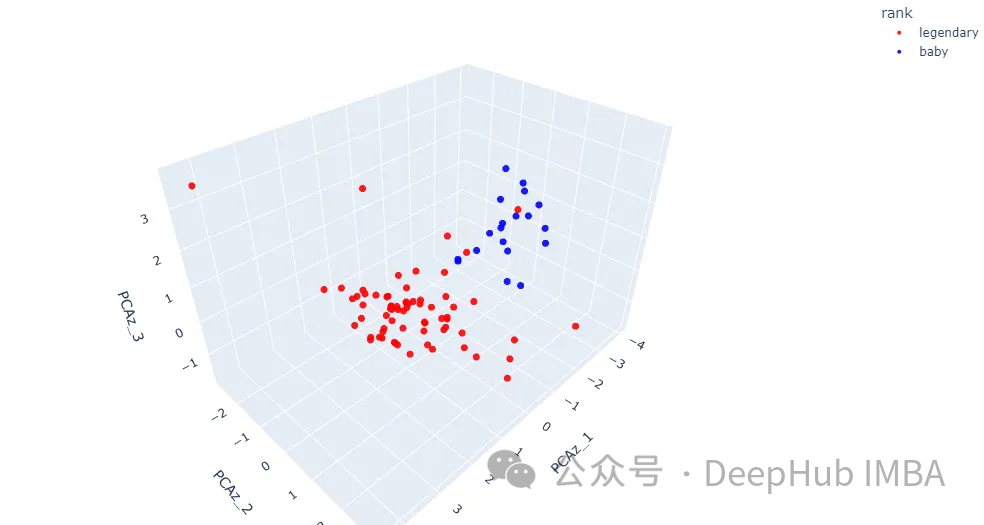
结果显示了更多关于数据点如何在三维空间中定位的细节。在一些区域两个类仍然混合在一起。下面我们讨论核方法。
核方法
支持向量机可以简单地使用Scikit-learn库中的sklearn.svm.SVC类执行。可以通过修改核参数来选择核函数。总共有五种方法可用:
Linear
Poly
RBF (Radial Basis Function)
Sigmoid
Precomputed本文将主要关注前四种核方法,因为最后一种方法是预计算的,它要求输入矩阵是方阵,不适合我们的数据集
除了核函数之外,我们还将调整三个主要参数,以便稍后比较结果。
C:正则化参数
Gamma(γ): rbf、poly和sigmoid函数的核系数
Coef0:核函数中的独立项,只在poly和s型函数中有意义
在下面的代码中,predict_proba()将计算网格上可能结果的概率。最终结果将显示为等高线图。
from sklearn import svm
import plotly.graph_objects as go
y = df['s_code'] # y values
h = 0.2 # step in meshgrid
x_min, x_max = df_pca.iloc[:, 0].min(), df_pca.iloc[:, 0].max()
y_min, y_max = df_pca.iloc[:, 1].min(), df_pca.iloc[:, 1].max()
xx, yy = np.meshgrid(np.arange(x_min-0.5, x_max+0.5, h), #create meshgrid
np.arange(y_min-0.5, y_max+0.5, h))
def plot_svm(kernel, df_input, y, C, gamma, coef):
svc_model = svm.SVC(kernel=kernel, C=C, gamma=gamma, coef0=coef,
random_state=11, probability=True).fit(df_input, y)
Z = svc_model.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 0]
Z = Z.reshape(xx.shape)
fig = px.scatter_3d(df, x='PCAz_1', y='PCAz_2', z='PCAz_3', #3D Scatter plot
hover_name='name',
color='rank', opacity=0.9,
color_discrete_sequence=['red', 'blue'])
fig.update_traces(marker=dict(size=4))
fig.add_traces(go.Surface(x=xx, y=yy, # prediction probability contour plot
z=Z+round(df.PCAz_3.min(),3), # adjust the contour plot position
name='SVM Prediction',
colorscale='viridis', showscale=False,
contours = {"z": {"show": True, "start": x_min, "end": x_max,
"size": 0.1}}))
title = kernel.capitalize() + ' C=' + str(i) + ', γ=' + str(j) + ', coef0=' + str(coef)
fig.update_layout(margin=dict(l=0, r=0, t=0, b=0), showlegend=False,
title={'text': title,
'font':dict(size=39),
'y':0.95,'x':0.5,'xanchor': 'center','yanchor': 'top'})
return fig.show()最后,创建三个参数的列表以进行比较,这里将比较0.01和100之间的值。如果您想尝试不同的值,可以调整该数字。
from itertools import product
C_list = [0.01, 100]
gamma_list = [0.01, 100]
coef_list = [0.01, 100]
param = [(r) for r in product(C_list, gamma_list, coef_list)]
print(param)
现在一切都准备好了,让我们用不同类型的核函数绘制结果。
1、线性核
这是最常见、最简单的SVM的核函数。这个核函数返回一个线性超平面,它被用作分离类的决策边界。通过计算特征空间中两个输入向量的点积得到超平面。
for i,j,k in param:
plot_svm('linear', df_pca, y, i, j, k)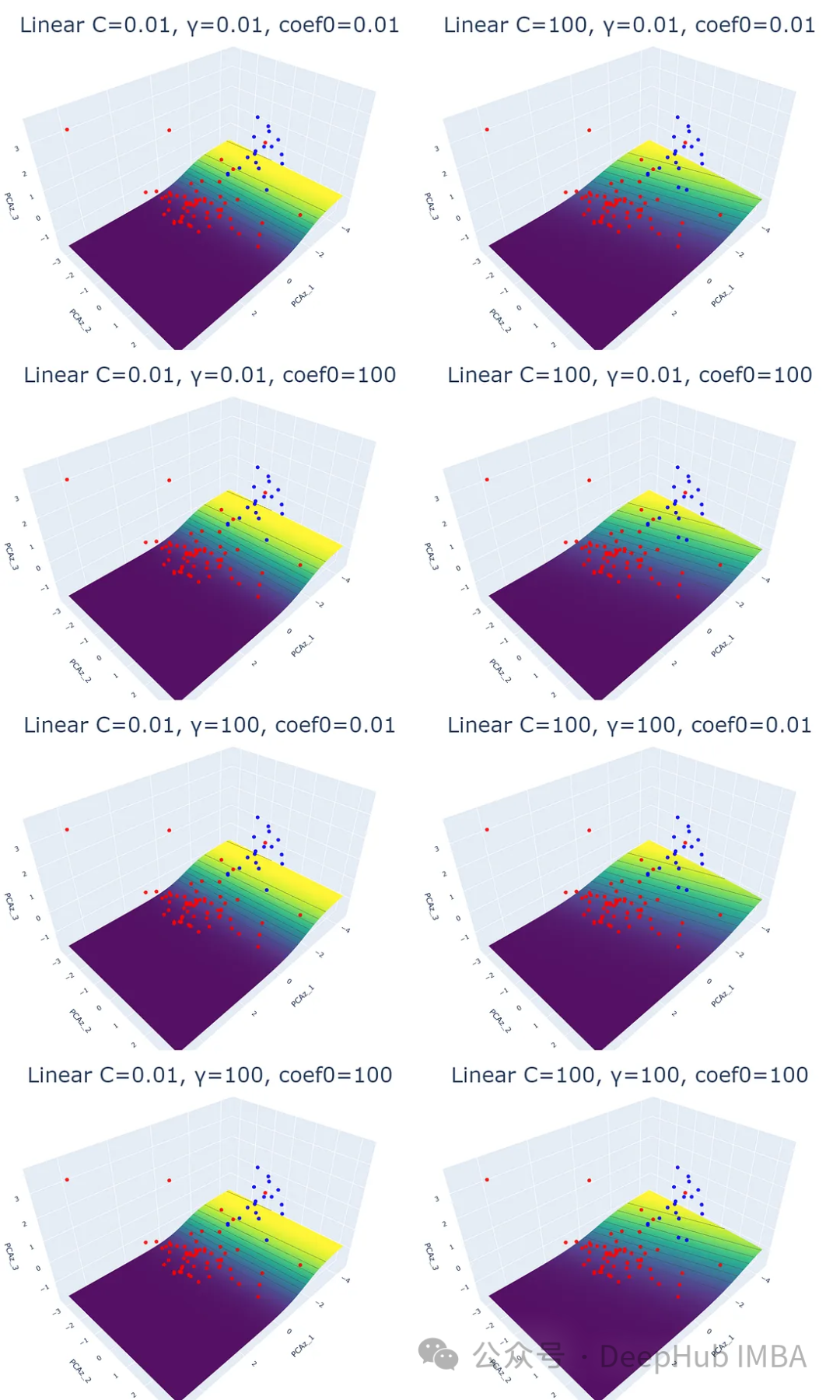
结果中的平面(等高线图)不是超平面。它们是predict_proba()的预测概率的结果,其值在0到1之间。
概率平面表示数据点被分类的概率。黄色区域意味着成为Baby可能性很大,而蓝色区域则表示成为Legend的可能性很大。
改变SVM结果的唯一参数是正则化参数(C)。理论上,当C的数量增加时,超平面的裕度会变小。当来自不同类别的数据点混合在一起时,使用高C可能会很好。过高的正则化会导致过拟合。
2、径向基函数(RBF)核
RBF(径向基函数)。该核函数计算欧几里得距离的平方来度量两个特征向量之间的相似性。
只需更改内核名称,就可以使用相同的for循环进程。
for i,j,k in param:
plot_svm('rbf', df_pca, y, i, j, k)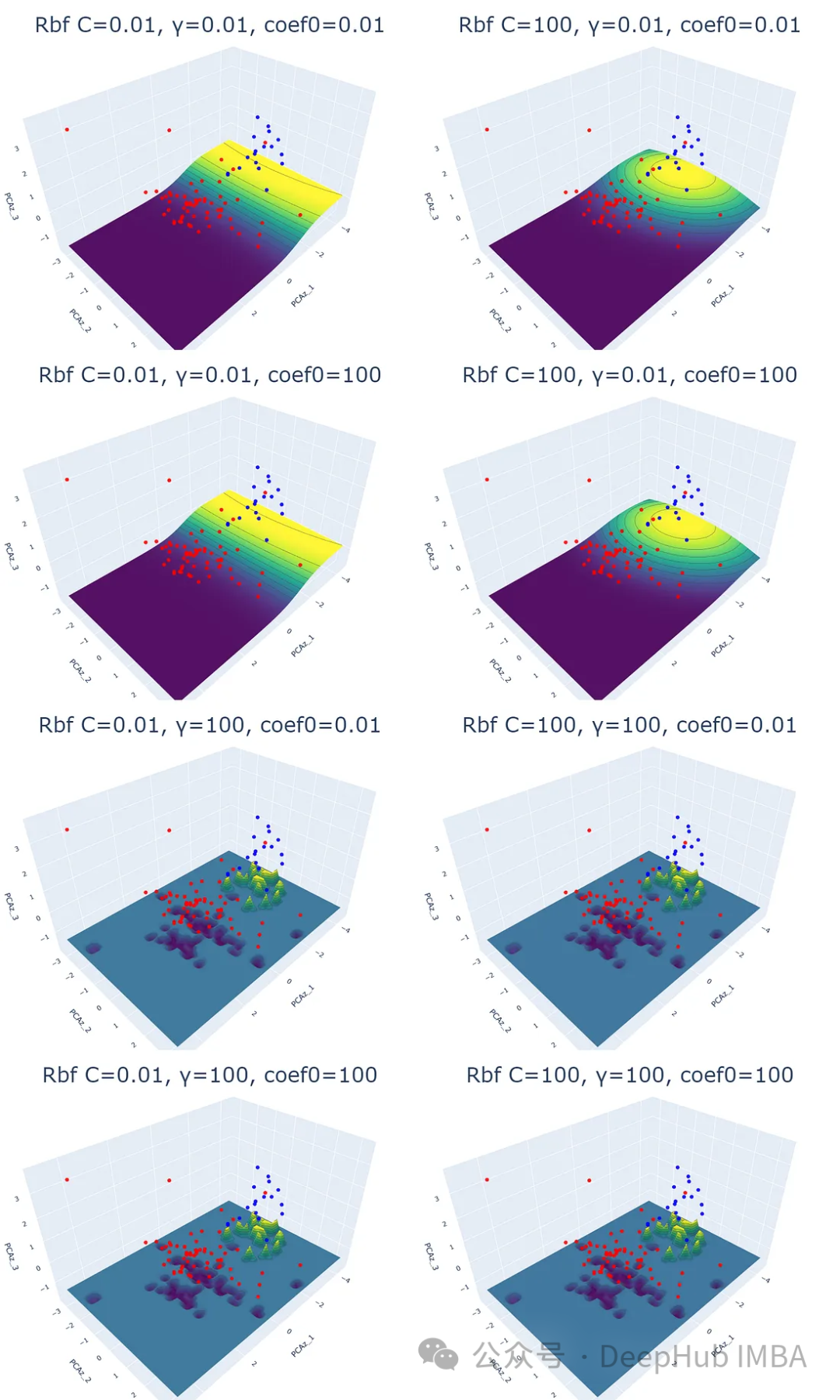
结果表明,除了正则化参数(C)外,γ (γ)也会影响RBF核的结果,coef0对RBF核函数没有影响。
伽马参数决定了数据点对超平面的影响。对于高伽马值,靠近超平面的数据点将比更远的数据点有更大的影响。
低伽马值的概率平面比高伽马值的概率平面平滑。结果在高伽马值的后4个散点图中更为明显;每个数据点对预测概率影响很大。
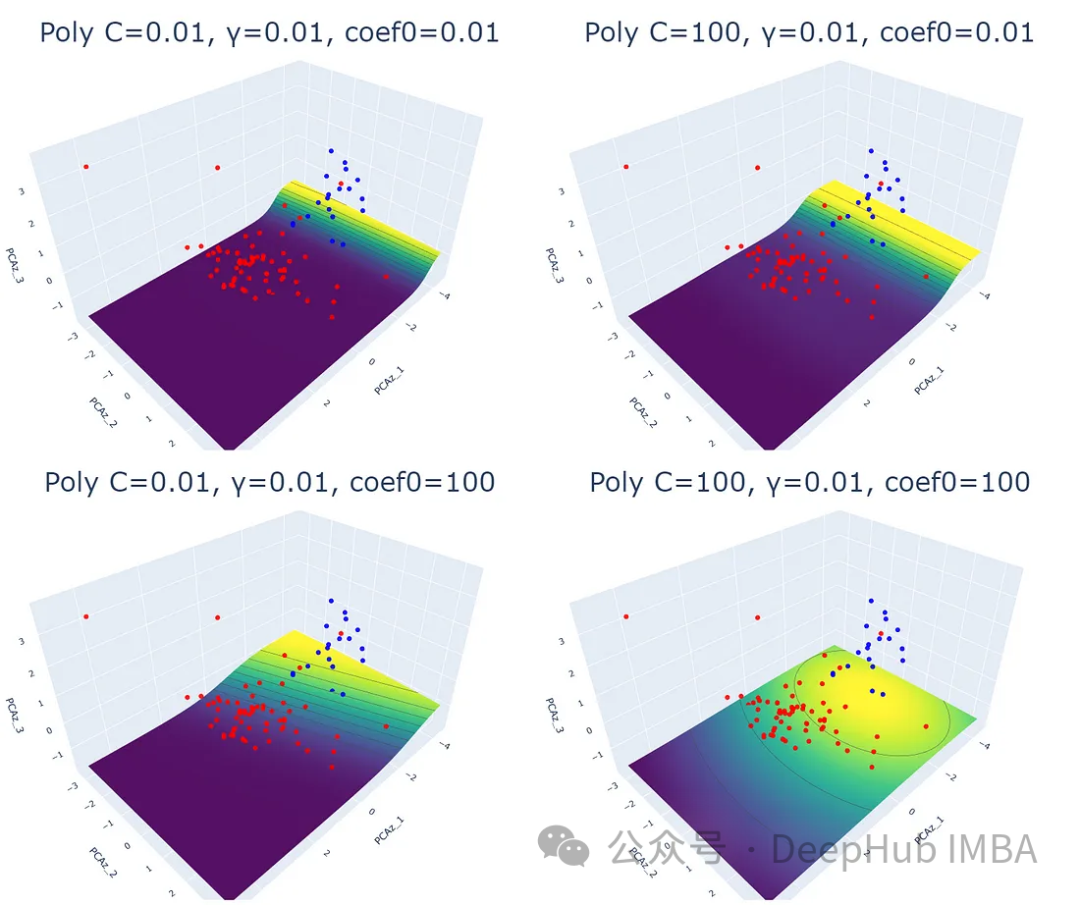
3、多项式核
多项式核通过将数据映射到高维空间来工作。取变换后的高维空间中数据点与原始空间的点积。由于它处理高维数据的能力,这个内核被推荐用于执行非线性分离。
多项式核与其他核相比,处理时间是最长的。这可能是将数据映射到高维空间的结果。
for i,j,k in param:
plot_svm('poly', df_pca, y, i, j, k)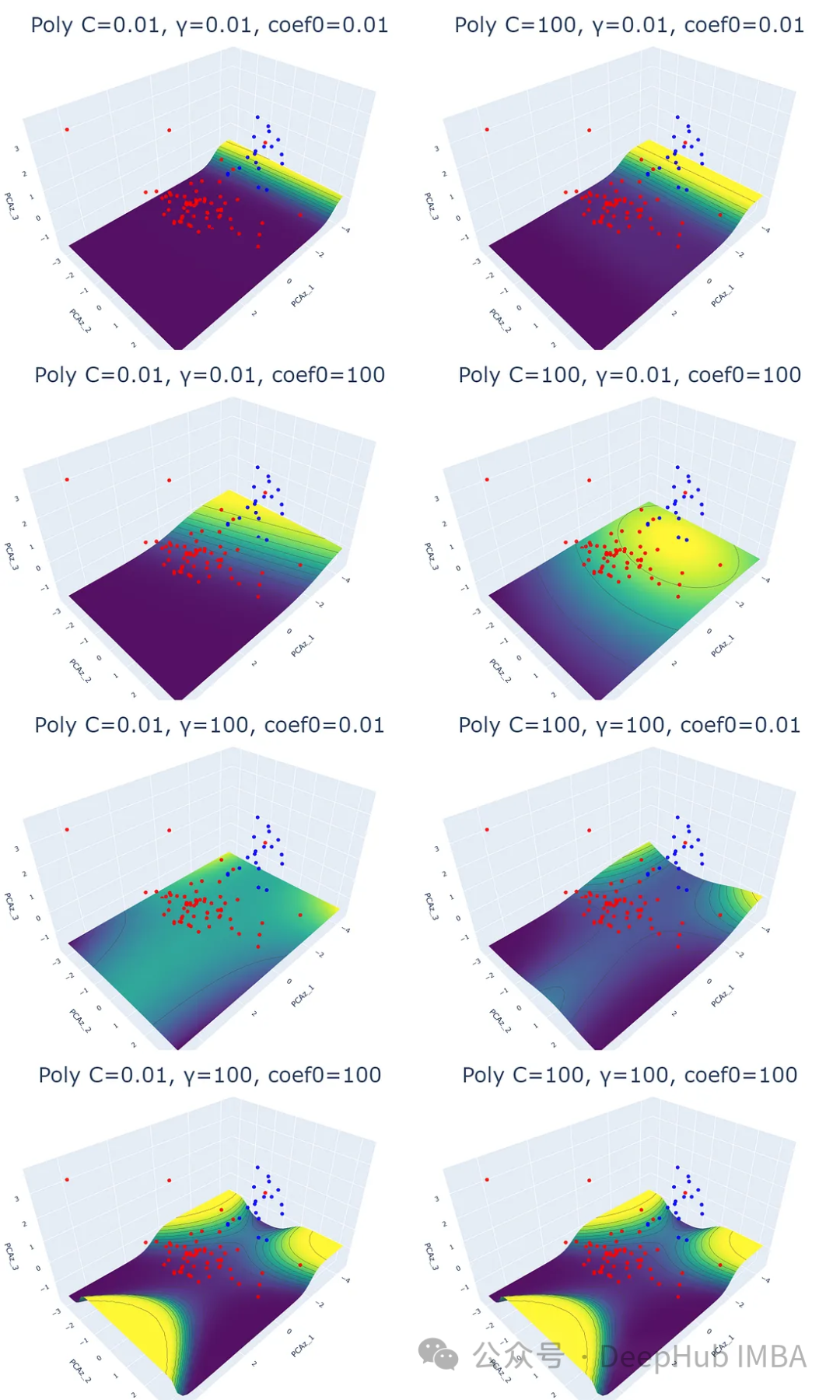
可以看出,这三个参数都会影响SVM的分类效果。除正则化参数(C)和γ (γ)外,coef0参数控制高次多项式对模型的影响程度。coef0值越高,预测概率等高线越趋于弯曲。
4、Sigmoid核
理论上,sigmoid函数擅长映射输入值并返回0到1之间的值。该函数通常用于神经网络中,其中s形函数作为分类的激活函数。
尽管它可以应用于SVM任务并且看起来很有用,但一些文章说结果可能太复杂而无法解释。我们这里使用数据可视化来查看这个问题。
for i,j,k in param:
plot_svm('sigmoid', df_pca, y, i, j, k)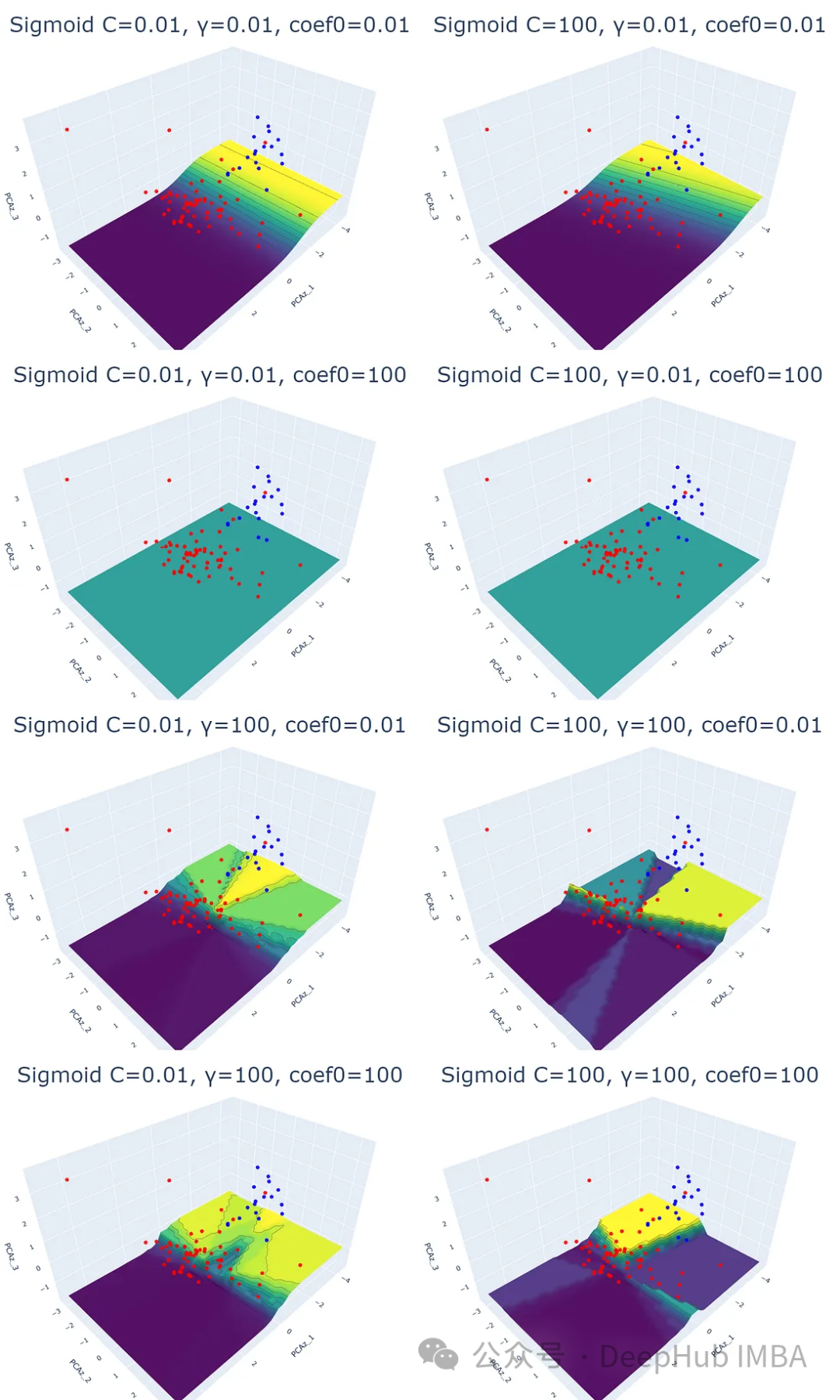
可以看到从Sigmoid核得到的图很复杂,也无法解释。预测概率等值线图与其他核的预测概率等值线图完全不同。并且等高线图的颜色不在它对应的数据点下面。最主要的是当改变参数值时,结果没有模式可循。
但是我个人认为,这并不意味着这个内核很糟糕或者应该避免使用。也许他找到了我们未察觉的数据特征,所以可能会有一些分类任务,sigmoid将适合使用。
总结
支持向量机是一种有效的机器学习分类技术,因为它能够提供简单的线性和非线性分类。
因为每个数据集都有不同的特征,所以不存在银弹。为了使支持向量机有效,必须选择好核和参数,同时还要注意避免过拟合,我们以上的总结希望对你的选择有所帮助。
https://avoid.overfit.cn/post/96c405b7aecf40c5a324ac8a2718f019

