
在这篇文章中,我们介绍多项式朴素贝叶斯分类器是如何工作的,然后使用scikit-learn作为实际工作的示例来介绍如何使用。

与假设高斯分布的高斯朴素贝叶斯分类器相反,多项式朴素贝叶斯分类器依赖于多项分布。通过学习/估计每个类的多项概率来“拟合”多项式分类器-使用平滑技巧来处理空特征。Multinomial Naive Bayes(多项式朴素贝叶斯)是一种常用的文本分类算法,特别适用于处理多类别分类问题,例如文档分类、垃圾邮件检测等。它是朴素贝叶斯(Naive Bayes)算法的一种变体,主要用于处理特征是离散型变量的情况,通常用于文本分类任务中。
多项分布
如果你已经熟悉多项分布,可以跳过这个部分。
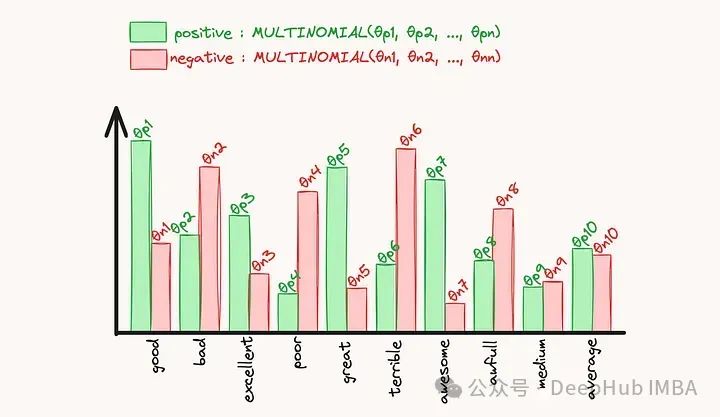
了解多项式朴素贝叶斯的第一步是了解什么是多项分布。
多项分布(Multinomial Distribution)是概率论和统计学中常用的一种概率分布,用于描述具有多个离散结果的随机试验。它是二项分布的推广,适用于多类别问题,例如投掷一枚骰子多次,每次可能得到1、2、3、4、5、6这六种结果的其中一种。
多项分布描述了进行 nn 次独立的多项试验时,各个类别的概率分布。如果一个随机变量 XX 表示了这些试验中各类别出现的次数,其中有 kk 个类别(例如在骰子的例子中就是6个类别),则多项分布的概率质量函数为:
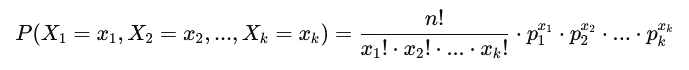
多项分布是离散型的。与二项分布类似,但不同的是,二项分布只涉及两种结果,而多项分布适用于多种结果的情况。每个试验的结果可以是多个类别之一。多项分布中的概率质量函数考虑了各个类别出现的次数以及各类别的概率。
如果投掷一个六面骰子 10 次,每个面出现的次数是 X1,X2,...,X6X1,X2,...,X6,那么 X1+X2+...+X6=10X1+X2+...+X6=10。假设骰子是公平的,则每个面的概率是相等的,即 p1=p2=...=p6=16p1=p2=...=p6=61。这时多项分布可以描述各个面出现次数的概率分布。
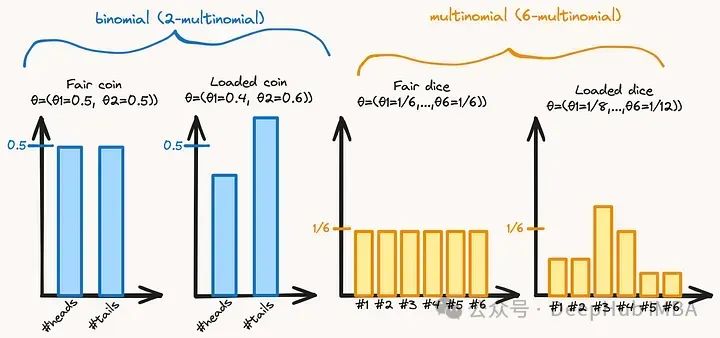
我们可以使用numpy随机选择函数模拟这样的分布。例如,从加载骰子分布中抽取100个样本:
loaded_dice_probs = [1/6, 1/4, 1/4, 1/6, 1/12, 1/12]
dice_faces = [1, 2, 3, 4, 5, 6]
n_try = 100
# Sample the distribution
sampled_loaded_dice = np.random.multinomial(n_try, loaded_dice_probs)
sampled_loaded_dice
#--> array([17, 26, 21, 18, 8, 10])关于多项分布,另一个需要了解的重要的东西是概率质量函数。概率质量函数给出了从离散分布中观察到特定结果的概率。投掷100次,得到64次正面36次反面的概率为:
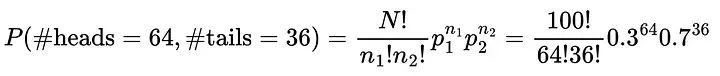
其实就是二项式定理。对于一个多项式定理,我们得到了多项式概率(p_1,…,p_n)和总尝试次数N=x_1+…+x_n的广义表达式:
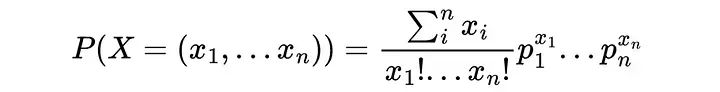
假设有一个装好的骰子,我们想计算这个骰子的分布是(1/6,1/4,1/4,1/6,1/12,1/12)的概率。掷骰子100次,得到x1=12面1,x2=15面2,然后我们可以计算观察到这样一个结果的概率:
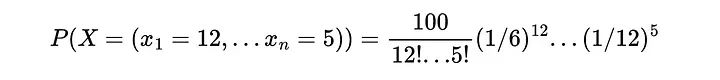
这个示例展示了如何在给定相关概率(所有pi)的情况下计算观察给定结果(所有xi)的概率。这很重要,因为它将有助于计算给定样本X=(x1,…,xn)属于分类问题中可能的多项分布p=(p1,…,pn)的概率。
分类问题
高斯朴素贝叶斯和多项是朴素贝叶斯实际上在原理上非常接近,主要是对潜在特征分布的假设不同:我们假设每个类别的每个特征都遵循高斯分布,而不是假设它们遵循多项分布。
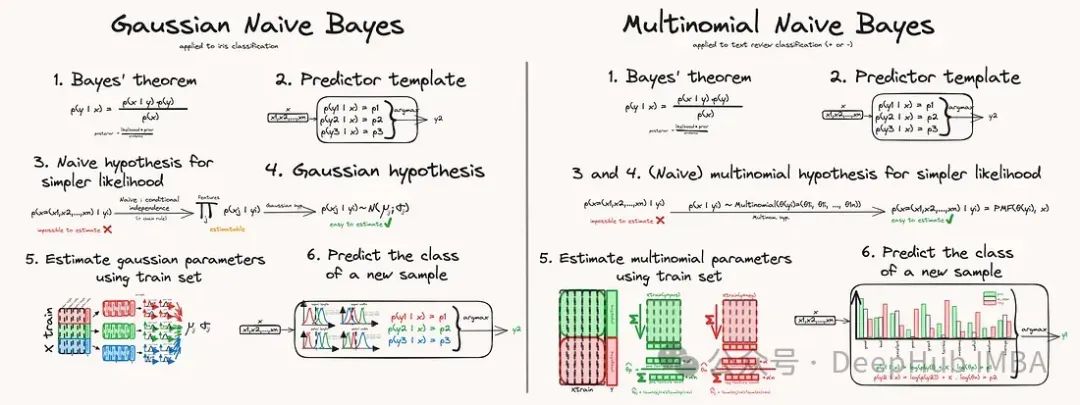
与高斯方法相比,在学习过程中估计分布参数的方式不同,在预测过程中使用分布参数的方式也不同。但总的来说,过程是相似的。以下是重要的步骤:
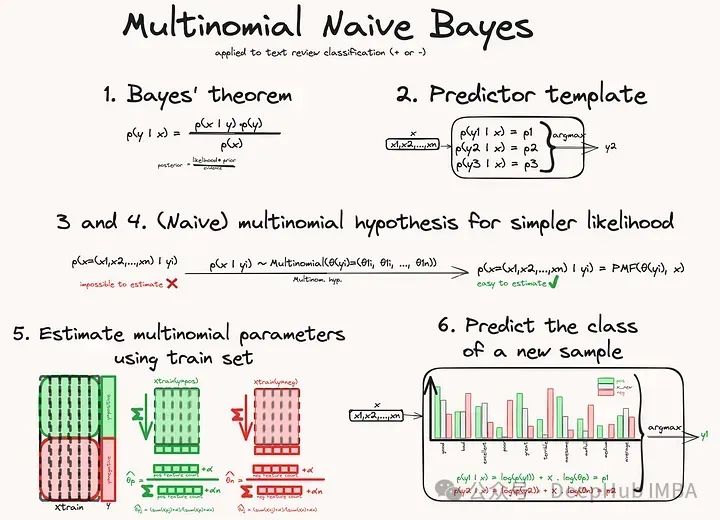
贝叶斯定理允许我们计算样本属于给定类别y的概率。创建一个空分类器,计算新样本属于所有类的概率,并返回概率最大的类。为了能够计算贝叶斯方程的概率,我们丢弃分母p(x),因为在比较每个类时它并不重要。然后需要使用假设所有特征都遵循多项分布来简化可能性项,对于每个类(朴素独立性实际上是内置在多项分布中的)。然后使用多项分布的概率质量函数来计算给定样本属于一类的概率。
这样就可以来拟合我们的模型,通过学习每一类的多项分布参数。一旦模型拟合就可以使用pmf来计算贝叶斯定理给出的最终概率,并返回最高概率类。
对于上面说的计算贝叶斯方程的概率
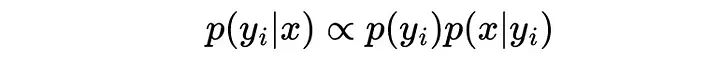
其中p(y_i)是任何样本属于类y_i的概率,这是由数据集中每个类的比例给出的——p(x|y_i)是一个样本等于x的概率,假设它属于类y_i:这正是PMF给我们的,或者说样本x属于y_i类的概率为:
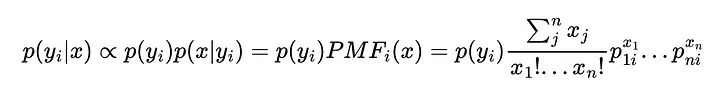
式中p_1i为类i与特征1相关的多项概率。
就像我们从贝叶斯方程中去掉分母一样,我们也可以去掉PMF的前导分数,因为它也只取决于x而不是类,所以最终得到:
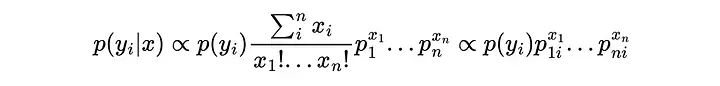
这意味着我们只需要估计每个类的多项概率,就能够计算一个样本属于任何类的概率。并且不需要像高斯方法那样使用链式法则和独立性假设。用独立概率项的乘积来表示它的另一种方法是:
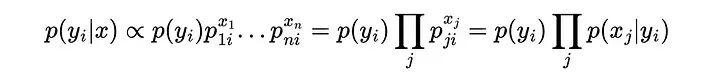
与类先验(p(yi))成正比乘以p(xj|yi)的所有j的乘积,这是在给定样本属于类yi的情况下,观察到特征j的xj结果的概率。
使用平滑技巧估计多项参数
我们已经知道了如何计算一个给定样本属于一类yi的概率,现在需要估计多项概率参数,包括正分布和负分布。
我们将使用数据集的一部分,即“训练集”来训练我们的模型,以便它“学习”那些多项参数。这一部分解释了它是如何在数字上实现的。
第一步也是最简单的一步是计算类先验,即观察到类yi的概率(与样本x无关),这是通过计算训练集中每个类的比例来完成的。

下一步是计算多项参数(对于pos和负数都是pj)。每个类都是独立于其他类处理的。对于每个类,X训练集对所有样本求和,因此我们计算一个“特征计数”向量:这个向量分布是真实底层分布的映射。然后将这些特征计数的向量转换为多项式分布参数的“有效”向量,将该向量除以总和。
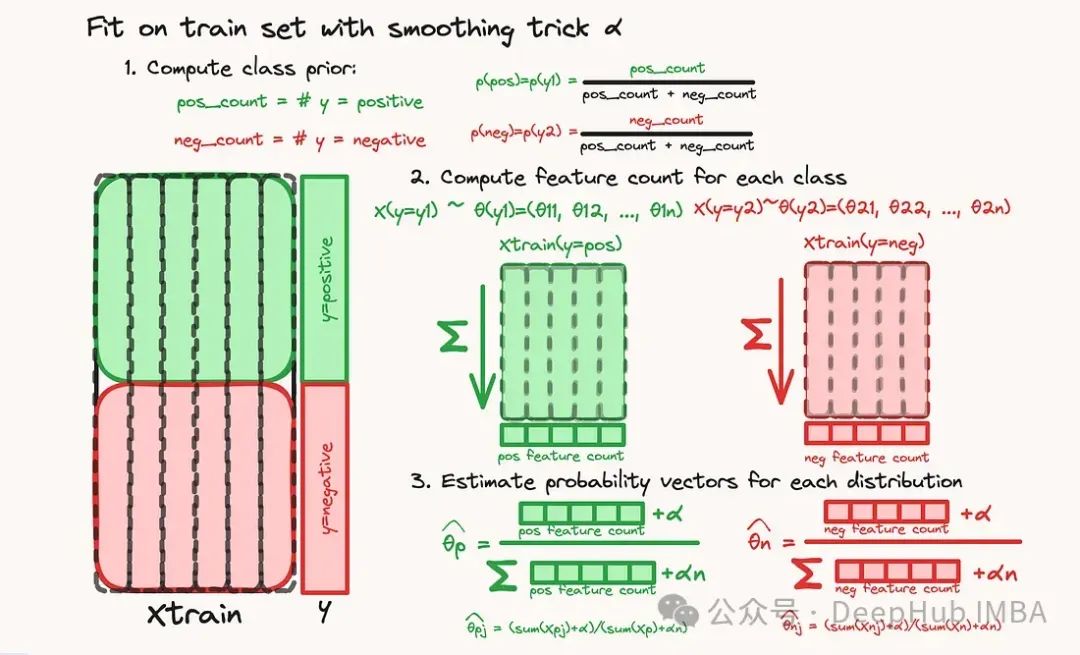
但是,如果一个类从未出现在类中,比如单词“atrocious”从未出现在训练集的正部分,该怎么办?那么,正类的相关概率θ_atrocious将为0(分子为0),这将导致该样本属于正类的总体概率也为0:
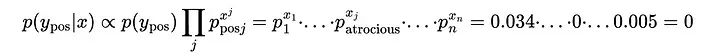
在学习过程中从未出现过“atrocious”这个词这一事实意味着,无论新样本的内容如何,任何新样本属于正类的概率都为0。或者说我们不能允许任何一类的多项式分布概率参数为0;否则,该类的总贝叶斯概率总是0。
为了避免这种情况,我们使用了“平滑技巧”,即在估计概率参数时在分子和分母上都添加一个α项。这样,即使一个特征(一个词)在所有样本中都不存在,估计的学习概率也不会为0:

现在我们知道如何正确估计多项概率参数,可以继续预测新样本的类别。
在对数空间计算预测,避免数值下溢
现在我们有了计算每个样本属于任何类的概率所需的所有值,我们可以代入数字并执行计算来预测该类。
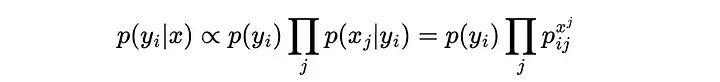
假设输入数据集包含1000或10000列(想想词表中的所有单词),其中许多单词非常稀疏地出现,使得它们的概率非常小。这将如何转化为给定类别y的总概率的计算:
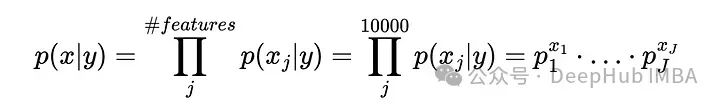
其中x_j是样本x在第j列的值,p_j是该类的多项分布参数j的概率。
让我们通过创建一个包含300个样本、10000个特征列的数据集来模拟这一点,其值在1到50之间。在文本上下文中,这相当于300个文档,词汇表为100000个单词,其中每个文档中的每个单词出现1到50次。
import numpy as np
J = 10000
nsamples = 300
X = np.random.choice(np.arange(1, 50), size=(nsamples,J))
# split into train and test (test has only 1 sample)
X_train, X_test = X[:-1], X[-1]
# estimate the distribution probabilities
feature_probs = X_train.sum(axis=0)/ X_train.sum()
print(feature_probs)
# [9.53780825e-05 1.05477725e-04 1.03631698e-04 … 1.07925718e-04
# 1.09517582e-04 9.51506733e-05]相应的概率是1e-4的数量级,这个数量级很小,计算机可以很好的处理这样的数字,所以现在没有问题。但是当计算样本属于一个类时,问题就出现了,这个概率如上所示,通过取所有p_j^{x_j}的乘积得到,其中p_j是单词j的估计概率,x_j是单词j在测试样本中出现的次数。我们得到:
# compute the probability for the test sample
print(feature_probs ** X_test)
print(np.prod(feature_probs ** X_test))
[1.37037886e-169 2.34731879e-064 5.34752484e-188 ... 1.84077019e-032
1.72545280e-024 4.29538125e-069]
0.0乘积的单个项在1e-24和1e-188之间,这是非常非常(非常!)小的数值,已经难以处理的数量级了。计算这些数字的整体乘积肯定会低于计算机可以处理的范围,我们最终得到Python识别为0的结果。换句话说,从一个不含0的乘积得到0这是不对的。
这个问题被称为数值下溢,其中变量值非常接近于0,以至于我们失去了它们之间的精度和相对顺序。
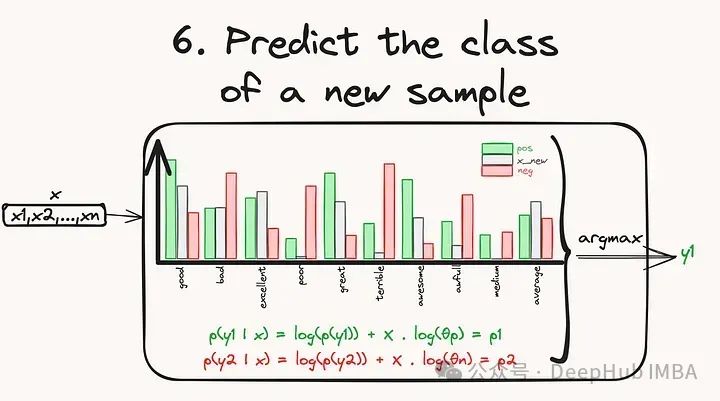
为了避免这种下溢问题,我们需要在“对数空间”中进行所有计算,因为小值的对数只是一个负值,但并不小(不那么接近0)。一般的想法是取我们数量的对数,因为对数函数提供了有用的性质,我们甚至可以重写公式:
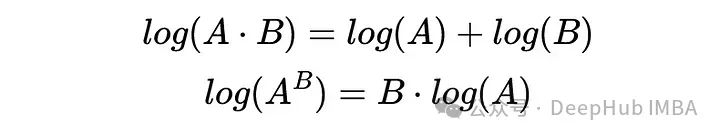
样本x属于y类的概率是
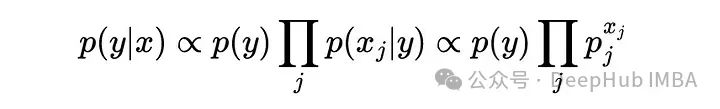
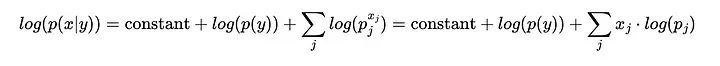
这样就从一个非常小的值的乘积,变成了一个(常规)负值的加权和。这仅仅是因为log是单调的。下图总结了在对数空间中预测新样本类别的计算过程:
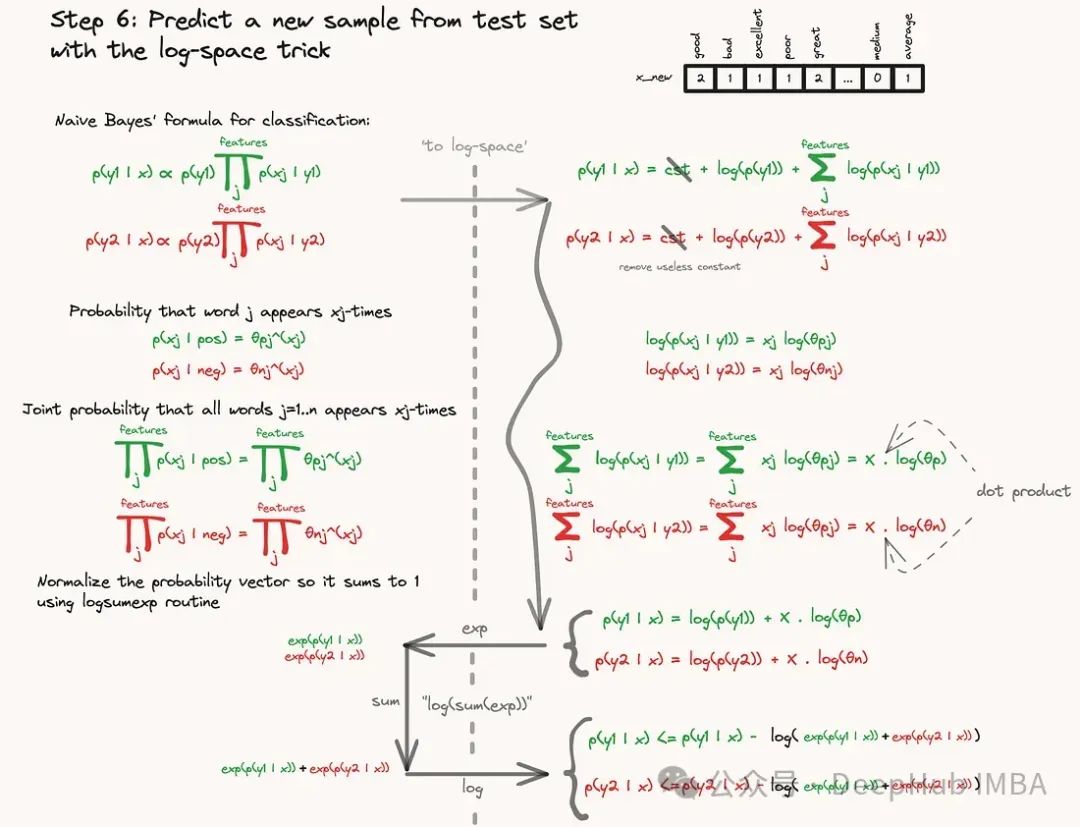
Python示例
让我们首先使用已知分布创建一个单词的示例数据集。然后使用多项式朴素贝叶斯创建一个文本分类器。
我们使用词袋方法对单词进行特征提取,特征表示每个单词在评论中出现的次数。然后生成2个多项分布:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
# Define the vocabulary
vocabulary = ['good', 'bad', 'excellent', 'poor', 'great', 'terrible', 'awesome', 'awful', 'fantastic', 'horrible']
# here the learned vocabulary is set from the begining
# it is usually created with the dataset but for this we assume it is limited to this list
# Define probabilities for positive distribution
# note that probabilities for "bad" words are not 0, so they might appear in positive docs, and vice versa
# also, normalize probabilities to sum to
positive_probs = np.array([0.3, 0.1, 0.5, 0.1, 0.4, 0.1, 0.6, 0.1, 0.5, 0.1])
negative_probs = np.array([0.1, 0.3, 0.1, 0.5, 0.1, 0.4, 0.1, 0.6, 0.1, 0.5])
positive_probs /= positive_probs.sum()
negative_probs /= negative_probs.sum()
# Let's plot each distribution
df = pd.DataFrame({'neg': negative_probs, 'pos': positive_probs},index=vocabulary)
df_melted = df.reset_index(names='word').melt(id_vars='word', value_vars=['pos', 'neg'], var_name="class", value_name="prob.")
g = sns.catplot(df_melted, y="prob.", hue="class", x='word', kind='bar')
g.ax.set_xticklabels(g.ax.get_xticklabels(), rotation=90, ha='center', va='top')
g.ax.set_title('True distrbutions')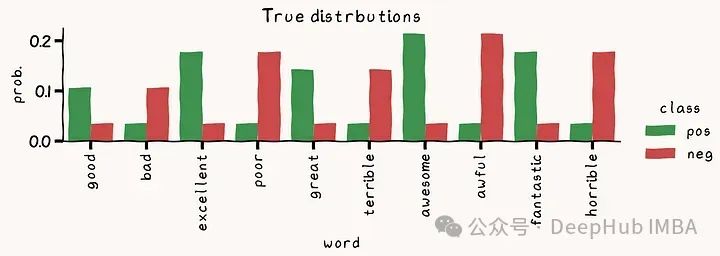
我们只创建了两个多项式分布。使用它们并对它们进行采样以创建具有已知类的实际数据集。
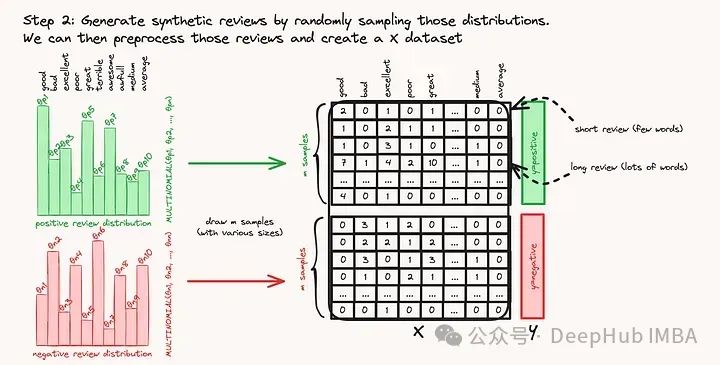
# Generate random documents for each class
# create 1000 positive reviews and 1000 negative reviews : our dataset is balanced
# the length (=number of words=sum of each row) may vary between 5 and 15 words)
# note that the vocabulary of each review (=number of distinct word) may be different
n_samples = 1000
positive_docs = [' '.join(np.random.choice(vocabulary, size=np.random.randint(5, 15), p=positive_probs)) for _ in range(n_samples)]
negative_docs = [' '.join(np.random.choice(vocabulary, size=np.random.randint(5, 15), p=negative_probs)) for _ in range(n_samples)]
# Create labels
labels_positive = np.ones(n_samples, dtype=int)
labels_negative = np.zeros(n_samples, dtype=int)
# Combine documents and labels
documents = np.concatenate([positive_docs, negative_docs])
labels = np.concatenate([labels_positive, labels_negative])
plt.figure()
sns.heatmap(CountVectorizer(vocabulary=vocabulary).fit_transform(documents).toarray(), xticklabels=vocabulary, cbar_kws={'label':'word count'})#, cmap="copper")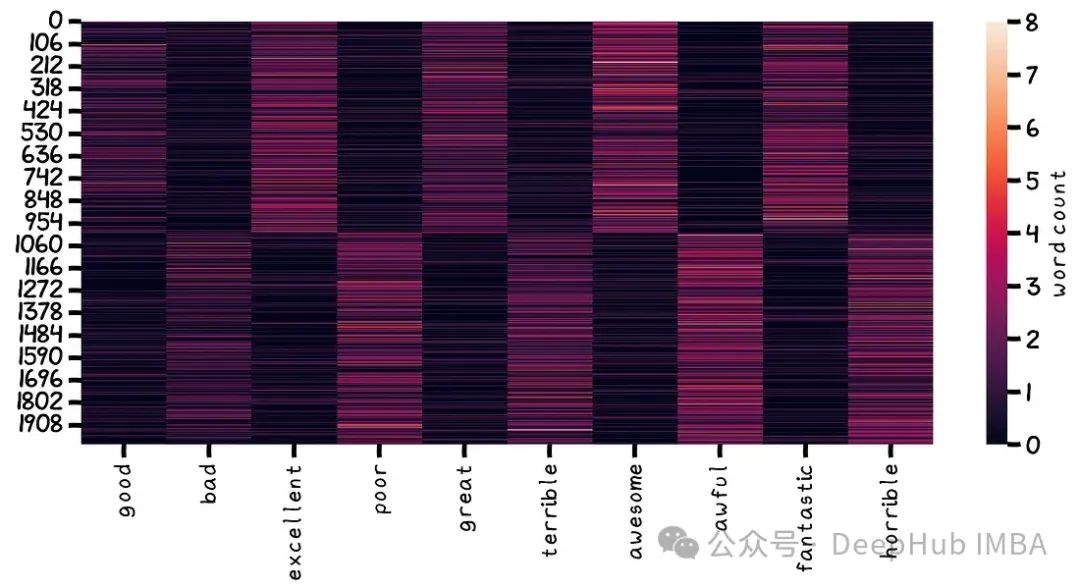
生成了2000个样本,其中1000个样本来自正多项式分布,1000个样本来自负多项式分布。词表使用scikit-learn的CountVectorizer(本质上相当于标准的collections.Counter)转换为数值矩阵。这样我们就有一个输入数据集X和相应的目标类向量y。
我们可以首先手动估计分布参数,就像scikit-learn中fit所做的那样。scikit-learn实际上是在“对数空间”中工作的,而概率并不是可用的。我们可以简单地使用theta = (classifier.feature_count_)来计算学习到的概率。T / classifier. feature_count_sum (axis=1)).T。
X_train, X_test, y_train, y_test = train_test_split(documents, labels, test_size=0.2, random_state=42, shuffle=True)
# Create a CountVectorizer to convert documents into a matrix of token counts
vectorizer = CountVectorizer(vocabulary=vocabulary)
# Fit and transform the training data
X_train_counts = vectorizer.fit_transform(X_train)
# Train a multinomial naive Bayes classifier
classifier = MultinomialNB(alpha=0) # notice I use alpha=0 here because I control the dataset and know there are no "empty" feature
classifier.fit(X_train_counts, y_train)
for class_, count_, feature_count_ in zip(classifier.classes_, classifier.class_count_, classifier.feature_count_):
print("For class", class_, "there were ", count_, "instance in the dataset. For those samples, the total counts for each word is", feature_count_)
# estimate distribution parametsers ourselves from scikit-learn stored attributes
thetas = (classifier.feature_count_.T / classifier.feature_count_.sum(axis=1)).T
print(thetas)
# sort by class
X_train_pos = X_train_counts[y_train==0]
X_train_neg = X_train_counts[y_train==1]
print(X_train_pos.sum(axis=0)/X_train_pos.sum(), X_train_neg.sum(axis=0)/X_train_neg.sum())
df = pd.DataFrame({'neg': thetas[0], 'pos': thetas[1]}, index=vocabulary)
df_melted = df.reset_index(names='word').melt(id_vars='word', value_vars=['pos', 'neg'], var_name="class", value_name="prob.")
g = sns.catplot(df_melted, y="prob.", hue="class", x='word', kind='bar')
g.ax.set_xticklabels(g.ax.get_xticklabels(), rotation=90, ha='center', va='top')
g.ax.set_title('Learned distrbutions')结果如下
For class 0 there were 799.0 instance in the dataset. For those samples, the total counts for each word is [ 258. 815. 256. 1274. 294. 1134. 296. 1618. 264. 1402.]
For class 1 there were 801.0 instance in the dataset. For those samples, the total counts for each word is [ 827. 277. 1306. 281. 1121. 293. 1618. 228. 1344. 244.]
[[0.03389831 0.10708186 0.03363553 0.1673893 0.0386283 0.14899488
0.03889108 0.21258705 0.03468664 0.18420707]
[0.10969625 0.03674227 0.17323252 0.03727285 0.14869346 0.03886457
0.21461732 0.03024274 0.17827298 0.03236504]]
[[0.03389831 0.10708186 0.03363553 0.1673893 0.0386283 0.14899488
0.03889108 0.21258705 0.03468664 0.18420707]]
[[0.10969625 0.03674227 0.17323252 0.03727285 0.14869346 0.03886457
0.21461732 0.03024274 0.17827298 0.03236504]]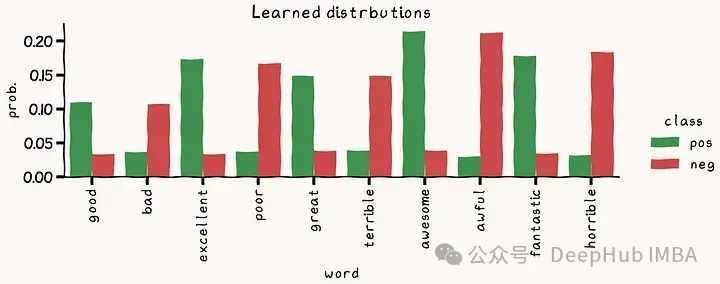
由于我们的训练集包含大量样本,因此学习到的分布非常接近用于生成它们的真实分布。
理解多项式分类在这里是如何工作的一种方法是比较候选类沿样本分布的分布。分类器返回与样本分布最相似的类:
x_new = vectorizer.transform(X_test)[0].toarray()[0]
x_normed = x_new / x_new.sum()
df = pd.DataFrame({'neg': thetas[1], 'pos': thetas[0], 'new':x_normed}, index=vocabulary)
df_melted = df.reset_index(names='word').melt(id_vars='word', value_vars=['pos', 'new', 'neg'], var_name="class", value_name='prob.')
g = sns.catplot(df_melted, y="prob.", hue="class", x='word', kind='bar')
g.ax.set_xticklabels(g.ax.get_xticklabels(), rotation=90, ha='center', va='top')
g.ax.set_title('Learned distrbutions along with new sample to predict')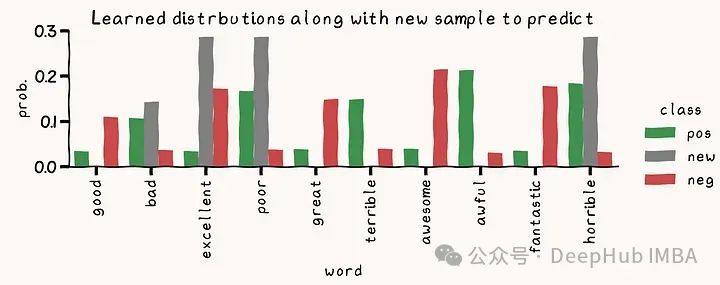
对于这个样本,我们可以直观地预测为正。但是让我们使用scikit-learn模型提供一个基于数字的决策:
classifier.predict([x_new])
#--> array([0])我们还可以检查并尝试在对数空间中手动重现模型所做的计算。当你在模型上使用.predict_proba时,它只是取log-probs的指数:
x_new = [vectorizer.transform(X_test)[0].toarray()[0]]
# class log prior
print(classifier.class_log_prior_)
print(np.log(classifier.class_count_/classifier.class_count_.sum()))
# feature log
print(classifier.feature_log_prob_)
print(np.log(classifier.feature_count_.T / classifier.feature_count_.sum(axis=1)).T)
# final log likelihood
print(classifier.predict_joint_log_proba(x_new))
jll = np.dot(x_new, np.log(classifier.feature_count_.T / classifier.feature_count_.sum(axis=1))) + np.log(classifier.class_count_/classifier.class_count_.sum())
print(jll)
# log prob.
print(classifier.predict_log_proba(x_new))
from scipy.special import logsumexp
log_prob_x = logsumexp(jll, axis=1)
print(jll - np.atleast_2d(log_prob_x).T)
# last 3 lines are equivalent to normalizing the sum of probability in 'not-log-space': x_ = x_ / x_.sum()
# final prob
print(classifier.predict_proba(x_new))
print(np.exp(jll - np.atleast_2d(log_prob_x).T))结果如下:
[-0.69439796 -0.69189796]
[-0.69439796 -0.69189796]
[[-3.38439026 -2.23416174 -3.3921724 -1.78743301 -3.25377008 -1.90384336
-3.24699039 -1.54840375 -3.36140075 -1.69169478]
[-2.21004013 -3.30382732 -1.75312052 -3.28949016 -1.9058684 -3.24767222
-1.53889873 -3.4984992 -1.72443931 -3.4306766 ]]
[[-3.38439026 -2.23416174 -3.3921724 -1.78743301 -3.25377008 -1.90384336
-3.24699039 -1.54840375 -3.36140075 -1.69169478]
[-2.21004013 -3.30382732 -1.75312052 -3.28949016 -1.9058684 -3.24767222
-1.53889873 -3.4984992 -1.72443931 -3.4306766 ]]
[[-16.67116009 -20.94229983]]
[[-16.67116009 -20.94229983]]
[[-0.01386923 -4.28500897]]
[[-0.01386923 -4.28500897]]
[[0.9862265 0.0137735]]
[[0.9862265 0.0137735]]这里我们使用alpha=0可以轻松地手工重现计算,但由于这是一个超参数,因此可能需要对其进行调优。
总结
多项分布是一种重要的概率分布,适用于描述多类别、多次试验的情况,是概率论和统计学中的基础之一。它表示实验可以有N个不同的输出,重复M次。可以把它看作投掷硬币的二项分布的概括,就像反复计算掷骰子的每面一样。多项式朴素贝叶斯分类器的总体思想与高斯朴素贝叶斯分类器非常相似,只是在拟合和预测计算上有所不同。为了学习每个类别的多项概率参数,可以简单地将训练集沿特征求和,并将结果除以该向量的和。这提供了对概率的估计。使用一个平滑的技巧可以处理在训练中未出现的特征。为了预测新样本的类别,则需要使用多项分布的概率质量函数,并在“对数空间”中计算所有概率,以避免下溢和计算机无法处理的小数字。
多项分布在实际中有广泛的应用,特别是在以下领域:
- 自然语言处理中的文本分类、主题建模等。
- 生物统计学中的多样性指数的计算。
- 计数数据的建模,如调查数据、市场调查等。
- 假设检验,用于检验多类别随机变量的比例是否满足某种期望。
https://avoid.overfit.cn/post/1fb34d655cdb4dcda077b75042256c45

