
NL2SQL进阶系列(5):论文解读业界前沿方案(DIN-SQL、C3-SQL、DAIL-SQL)、新一代数据集BIRD-SQL解读
[NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]](https://blog.csdn.net/sinat_3...)
NL2SQL基础系列(2):主流大模型与微调方法精选集,Text2SQL经典算法技术回顾七年发展脉络梳理
NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
[NL2SQL进阶系列(2):DAIL-SQL、DB-GPT开源应用实践详解[Text2SQL]](https://blog.csdn.net/sinat_3...)
[NL2SQL进阶系列(3):Data-Copilot、Chat2DB、Vanna Text2SQL优化框架开源应用实践详解[Text2SQL]](https://blog.csdn.net/sinat_3...)
[☆☆NL2SQL进阶系列(4):ConvAI、DIN-SQL、C3-浙大、DAIL-SQL-阿里等16个业界开源应用实践详解[Text2SQL]](https://blog.csdn.net/sinat_3...)
☆☆NL2SQL进阶系列(5):论文解读业界前沿方案(DIN-SQL、C3-SQL、DAIL-SQL、SQL-PaLM)、新一代数据集BIRD-SQL解读
NL2SQL实践系列(1):深入解析Prompt工程在text2sql中的应用技巧
NL2SQL实践系列(2):2024最新模型实战效果(Chat2DB-GLM、书生·浦语2、InternLM2-SQL等)以及工业级案例教学
NL2SQL任务的目标是将用户对某个数据库的自然语言问题转化为相应的SQL查询。随着LLM的发展,使用LLM进行NL2SQL已成为一种新的范式。在这一过程中,如何利用提示工程来发掘LLM的NL2SQL能力显得尤为重要。
1.DIN-SQL-V3 2023.11.02
- [v1] Fri, 21 Apr 2023 15:02:18 UTC (8,895 KB)
- [v2] Thu, 27 Apr 2023 17:49:23 UTC (8,895 KB)
- [v3] Thu, 2 Nov 2023 20:30:12 UTC (2,202 KB)
论文链接:DIN-SQL: Decomposed In-Context Learning of Text-to-SQL withSelf-Correction
摘要:我们研究将复杂的文本到 SQL 任务分解为更小的子任务的问题,以及这种分解如何显着提高大型语言模型 (LLM) 在推理过程中的性能。目前,在具有挑战性的文本到 SQL 数据集(例如 Spider)上,微调模型的性能与使用 LLM 的提示方法之间存在显着差距。我们证明 SQL 查询的生成可以分解为子问题,并且这些子问题的解决方案可以输入到 LLM 中以显着提高其性能。我们对三个 LLM 进行的实验表明,这种方法持续将其简单的小样本性能提高了大约 10%,将 LLM 的准确性推向 SOTA 或超越它。在 Spider 的 Holdout 测试集上,执行准确度方面的 SOTA 为 79.9,使用我们方法的新 SOTA 为 85.3。我们的情境学习方法比许多经过严格调整的模型至少高出 5%。
在本文中,我们提出了一种基于少样本提示(few-shot prompting)的新颖方法,将自然语言文本到 SQL(称为 text-to-SQL)的任务分解为多个步骤。之前使用 LLM 进行文本到 SQL 提示的工作仅在零样本( zero-shot)设置中进行评估。然而,零样本提示仅提供了LLM对于大多数任务的潜在能力的下限。在这项工作中,我们首先评估了 LLM 在少样本设置中的性能,然后提出了我们的分解方法,该方法大大优于少样本提示方法。为了将我们的方法与以前的方法进行比较,我们使用执行精度和匹配精度这两个官方评估指标。我们利用 CodeX 系列的两个变体,即 Davinci 和 Cushman以及 GPT-4 模型进行prompt。在Spider的测试集上,我们的方法使用GPT-4和CodeX Davinci模型分别实现了85.3%和78.2%的执行精度,并且使用相同模型分别实现了60%和57%的匹配精度。
1.1 Few-shot Error Analysis
为了更好地了解 LLM 在少样本设置下失败的地方,我们从 Spider 数据集的训练集中的不同数据库中随机抽取了 500 个查询,排除提示中使用的所有数据库。我们搜索的查询产生的结果与Spider官方给出的标准的结果不同,因此执行准确性不合格。我们手动检查了这些故障,并将其分为六类,如图 1 所示,并在接下来进行讨论。
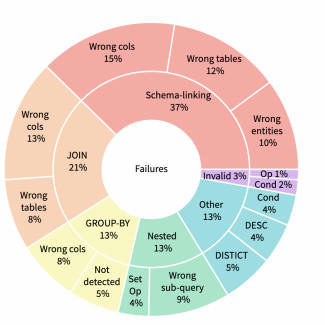
- Schema Linking
此类别包含最大数量的失败查询,并包含模型无法识别问题中提到的列名称、表名称或实体的实例。在某些情况下,查询需要聚合函数,但会选择匹配的列名称。例如,问题 “所有体育场的平均容量和最大容量是多少?” 的数据库模式包括一个名为 “average” 的列,该列是由模型选择的,而不是取容量列的平均值。
- JOIN
这是第二大类别,包括需要 JOIN 的查询,但模型无法识别所需的所有表或连接表的正确外键。
- GROUP BY
此类别包括以下情况:SQL 语句需要 GROUP BY 子句,但模型无法识别分组的需要,或者使用了错误的列对结果进行分组。
- Queries with Nesting and Set Operations
对于此类别,Spider 给出的标准查询使用嵌套或集合操作,但模型无法识别嵌套结构或无法检测正确的嵌套或集合操作。
- Invalid SQL
一小部分生成的 SQL 语句存在语法错误,无法执行。
- Miscellaneous
此类别包括不属于上述任何类别的案例。示例包括包含额外谓词、缺少谓词或缺少或冗余 DISTINCT 或 DESC 关键字的 SQL 查询。此类别还包括缺少 WHERE 子句或查询具有冗余聚合函数的情况。
1.2 Methodology
尽管少样本比零样本模型有所改进,但少样本模型在处理更复杂的查询时遇到了困难,包括那些模式链接不那么简单的查询以及使用多个联接或具有嵌套结构的查询,如第 3 节中所述。
我们应对这些挑战的方法是将问题分解为更小的子问题,解决每个子问题,并使用这些解决方案构建原始问题的解决方案。
类似的方法(例如,思想链提示(Wei et al, 2022b)和从最少到最多的提示(Zhou et al, 2022))已被用来提高法学硕士在任务上的表现,这些任务可以分解为多个步骤,例如数学应用题和构图概括(Cobbe 等人,2021;Lake 和 Baroni,2018)。与这些任务具有过程结构(其中一个步骤直接进入下一步)的领域不同,SQL 查询在大多数部分都是声明性的,可能的步骤及其边界不太清晰。然而,编写 SQL 查询的思维过程可以分解为 (1) 检测与查询相关的数据库表和列,(2) 识别更复杂查询的一般查询结构(例如分组、嵌套、多重联接 、集合运算等)(3)制定任何可以识别的过程子组件,以及(4)根据子问题的解决方案编写最终查询。
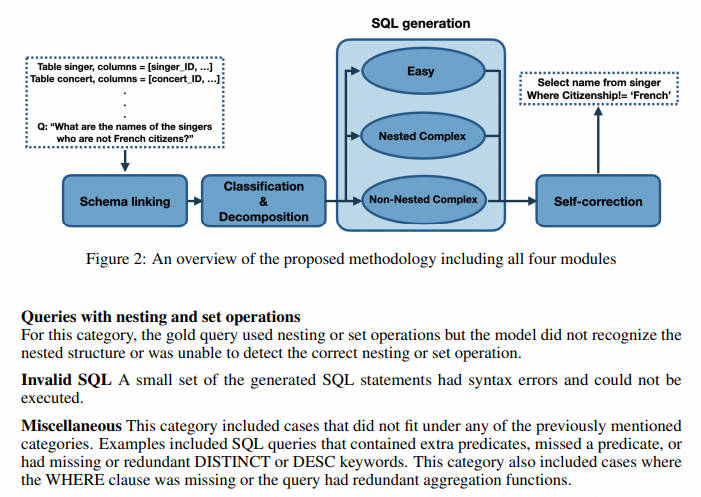
基于这个思维过程,我们提出的分解文本到 SQL 任务的方法由四个模块组成(如图 2 所示):(1)模式链接,(2)查询分类和分解,(3)SQL 生成, (4) 自我修正,将在以下小节中详细解释。虽然这些模块可以使用文献中的技术来实现,但我们都使用提示技术来实现它们,以表明如果问题被简单地分解到正确的粒度级别,LLM 就有能力解决所有这些问题。
Schema Linking Module(模式链接)
模式链接负责识别自然语言查询中对数据库模式和条件值的引用。 它被证明有助于跨领域的通用性和复杂查询的综合(Lei 等人,2020),使其成为几乎所有现有文本到 SQL 方法的关键初步步骤。在我们的案例中,这也是 LLM 失败次数最多的一个类别(图 2)。我们设计了一个基于提示的模式链接模块。提示包括从 Spider 数据集的训练集中随机选择的 10 个样本按照思路链模板(Wei 等人,2022b),提示以 “让我们一步一步思考” 开头,正如 Kojima 等人(2022)建议的那样。
对于问题中每次提到的列名,都会从给定的数据库模式中选择相应的列及其表。还从问题中提取可能的实体和单元格值。图 3 给出了一个示例,完整的提示可以在附录 A.3 中找到。
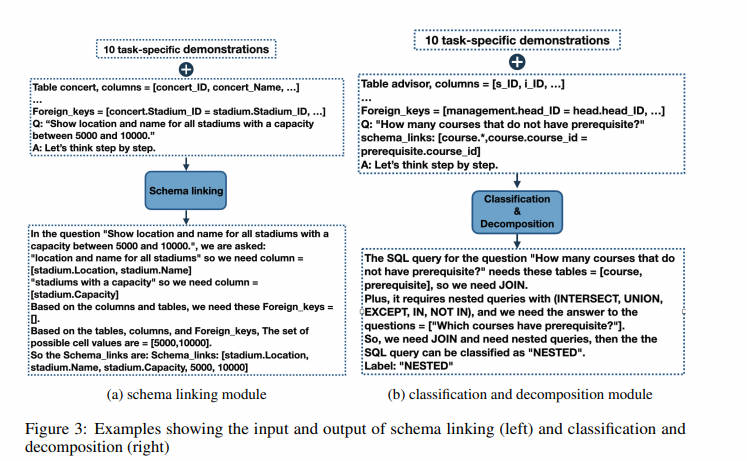
Classification & Decomposition Module(查询分类和分解模块)
对于每个连接,都有可能未检测到正确的表或连接条件。随着查询中联接数量的增加,至少一个联接无法正确生成的可能性也会增加。缓解该问题的一种方法是引入一个模块来检测要连接的表。此外,一些查询具有过程组件,例如不相关的子查询,它们可以独立生成并与主查询合并。为了解决这些问题,我们引入了查询分类和分解模块。该模块将每个查询分为三类之一:简单、非嵌套复杂和嵌套复杂。
- easy 类包括无需连接或嵌套即可回答的单表查询。
- 非嵌套类包括需要连接但没有子查询的查询,
- 嵌套类中的查询可以需要连接、子查询和集合操作。
类标签对于我们的查询生成模块很重要,该模块对每个查询类使用不同的提示。除了类标签之外,查询分类和分解还检测要为非嵌套和嵌套查询以及可能为嵌套查询检测到的任何子查询连接的表集。图 4 显示了提供给模型的示例输入以及模型生成的输出。
SQL Generation Module(SQL生成)
随着查询变得更加复杂,必须合并额外的中间步骤来弥合自然语言问题和 SQL 语句之间的差距。这种差距在文献中被称为不匹配问题(Guo et al, 2019),对 SQL 生成提出了重大挑战,这是因为 SQL 主要是为查询关系数据库而设计的,而不是表示自然语言中的含义。
虽然更复杂的查询可以从思路链式提示中列出中间步骤中受益,但此类列表可能会降低更简单任务的性能(Wei 等人,2022b)。在相同的基础上,我们的查询生成由三个模块组成,每个模块针对不同的类别。
- 对于我们划分的简单类别中的问题,没有中间步骤的简单的少量提示就足够了。此类示例 Ej 的演示遵循格式 <Qj, Sj, Aj>,其中 Qj 和 Aj 分别给出英语和 SQL 的查询文本,Sj 表示模式链接。
- 我们的非嵌套复杂类包括需要连接的查询。我们的错误分析(第 3 节)表明,在简单的几次提示下,找到正确的列和外键来连接两个表对于法学硕士来说可能具有挑战性,特别是当查询需要连接多个表时。为了解决这个问题,我们采用中间表示来弥合查询和 SQL 语句之间的差距。文献中已经介绍了各种中间表示。特别是,SemQL(Guo et al, 2019)删除了在自然语言查询中没有明确对应项的运算符 JOIN ON、FROM 和 GROUP BY,并合并了 HAVING 和 WHERE 子句。 NatSQL(Gan 等人,2021)基于 SemQL 构建并删除了集合运算符。作为我们的中间表示,我们使用 NatSQL,它与其他模型结合使用时显示出最先进的性能 (Li et al, 2023a)。非嵌套复杂类的示例 Ej 的演示遵循格式 <Qj, Sj, Ij, Aj>,其中 Sj 和 Ij 分别表示第 j 个示例的模式链接和中间表示。
- 嵌套复杂类是最复杂的类型,在生成最终答案之前需要几个中间步骤。此类可以包含不仅需要使用嵌套和集合操作(例如 EXCEPT、UNION 和 INTERSECT)的子查询,而且还需要多个表连接的查询,与上一个类相同。为了将问题进一步分解为多个步骤,我们对此类的提示的设计方式是 LLM 应首先解决子查询,然后使用它们生成最终答案。此类提示遵循格式 <Qj, Sj , <Qj1, Aj1, ..., Qjk, Ajk> , Ij, Aj>,其中 k 表示子问题的数量,Qji 和 Aji 分别表示第 i 个问题 - 第一个子问题和第 i 个子查询。和之前一样,Qj 和 Aj 分别表示英语和 SQL 的查询,Sj 给出模式链接,Ij 是 NatSQL 中间表示。
附录 A.4 中提供了所有三个查询类别的完整提示,并且这三个类别的所有示例均从为分类提示选择的完全相同的数据库中获得。
Self-correction Module(自我纠正模块)
生成的 SQL 查询有时可能会缺少或冗余关键字,例如 DESC、DISTINCT 和聚合函数。我们对多个 LLM 的经验表明,这些问题在较大的 LLM 中不太常见(例如,GPT-4 生成的查询比 CodeX 生成的查询具有更少的错误),但仍然存在。为了解决这个问题,我们提出了一个自我纠正模块,指示模型纠正这些小错误。
这是在零样本设置中实现的,其中仅向模型提供有错误的代码,并要求模型修复错误。我们为自我纠正模块提出了两种不同的提示:通用和温和。通过通用提示,我们要求模型识别并纠正 “BUGGY SQL” 中的错误。另一方面,温和提示并不假设 SQL 查询有错误,而是要求模型检查任何潜在问题,并提供有关要检查的子句的一些提示。我们的评估表明,通用提示可以在 CodeX 模型中产生更好的结果,而温和的提示对于 GPT-4 模型更有效。除非另有明确说明,否则 DINSQL 中的默认自我更正提示对于 GPT-4 设置为“温和”,对于 CodeX 设置为“通用”。通用和温和的自我纠正提示的示例可以在附录 A.6 中找到。
主要方法讲完,更多内容细节和测评效果参考原论文
1.3 案例
- Zero-shot prompting
用于零样本提示场景的提示灵感来自于 Liu 等人的工作 (2023a) 为 ChatGPT 的提议。在图 6 中,我们演示了我们工作中使用的零样本提示的一个示例。

- Few-shot prompting



2.C3: Zero-shot Text-to-SQL-2023.07.14
论文链接:https://arxiv.org/pdf/2307.07...
代码 https://github.com/bigbigwate...
在DIN-SQL提出的Few-shot方案的基础上,C3使用chatgpt作为基座模型,探索了zero-shot的方案,这样可以进一步降低推理成本。并且在生成效果上和DIN-SQL不相上下。C3方法的框架如图1所示。C3由三个关键组件组成:清晰提示(CP、Clear Prompting)、提示校准(CH)和一致性输出(CO),它们分别对应模型输入、模型偏差和模型输出。每个组件的细节如下介绍。
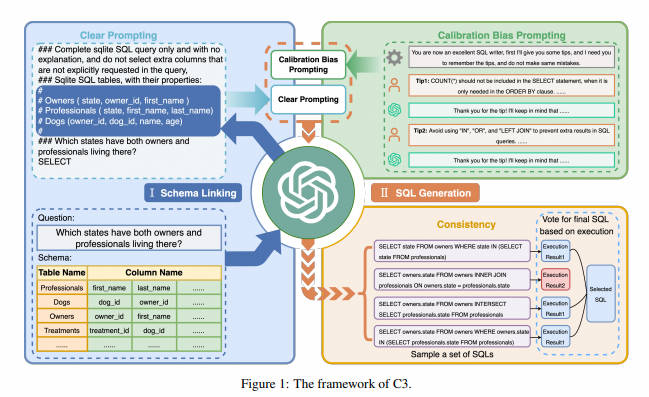
C3也通过Schema Linking先定位问题相关的数据表和查询字段。不过在指令构建上,论文认为在编写指令时,简洁的文本格式(clear layout),以及不引入不相关的表结构(clear context),会降低模型理解难度,对模型效果有很大提升。下面我们分别看下这两个部分
2.1 Clear Prompting
Clear Prompting (CP) 组件的目标是为文本到SQL解析提供有效的prompt。它包括两个部分:clear layout and clear context
- 类型 1:复杂布局:这种提示布局直接将说明、问题和上下文(数据库模式)直接连接在一起,显得混乱不堪。
- 类型 2:清晰布局:这种布局通过采用清晰的符号将说明、上下文(数据库模式)和问题分开,看起来清晰明了。
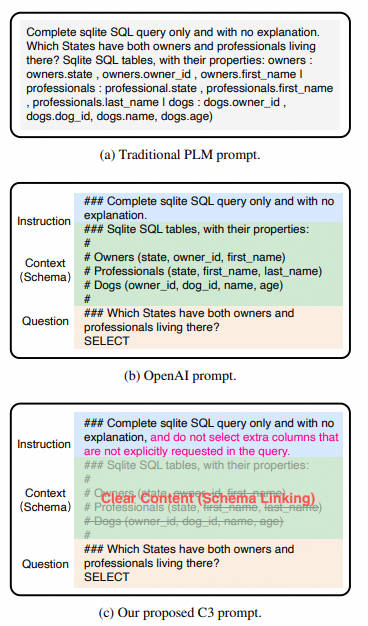
2.1.1 Clear Layout
后面的SQL-Palm也进行了类似的消融实验,对比符合人类自然语言描述的Table Schema,使用符号表征的prompt效果显著更好,在执行准确率上有7%左右的提升。
2.1.2 Clear Context
把整个数据库的全部表结构放入schema linking Context,一方面增加了推理长度,一方面会使得模型有更大概率定位到无关的查询字段。因此C3通过以下两步先召回相关的数据表和表字段,再进行schema linking
- 数据表召回
C3使用以下zero-shot指令,让大模型基于数据表schema,召回问题相关的数据表。这一步作者采用了self-consistency来投票得到概率最高的Top4数据表。当前的一些开源方案例如ChatSQL等,也有采用相似度召回的方案,更适合低延时,面向超大数据库的场景。不过需要先人工先对每张表生成一段表描述,描述该表是用来干啥的,然后通过Query*Description的Embedding相似度来筛选TopK数据表。
- 首先,表格应基于其与问题的相关性进行排名。
- 其次,模型应检查是否考虑了所有表格。
- 最后,输出格式被规定为一个列表
为确保Table Recall的稳定性,我们采用了一种self-consistency。具体而言,模型生成了十组检索结果,每组包含前四个表格。最终的结果由在这十组中出现最频繁的一组确定。
instruction = """Given the database schema and question, perform the following actions:
1 - Rank all the tables based on the possibility of being used in the SQL according to the question from the most relevant to the least relevant, Table or its column that matches more with the question words is highly relevant and must be placed ahead.
2 - Check whether you consider all the tables.
3 - Output a list object in the order of step 2, Your output should contain all the tables. The format should be like:
["table_1", "table_2", ...]
"""

- 表字段召回
在以上得到问题相关的数据表之后,会继续执行表字段召回的操作,同样使用了Self-Consistency多路推理投票得到概率最高的Top5字段。这一步同样可以使用相似度召回,尤其在中文场景,以及垂直领域的数据表场景,直接使用字段名并不足够,也需要对表字段名称生成对应的描述,然后使用相似度进行召回。
- 首先,基于它们与问题的相关性对每个候选表格内的所有列进行排名。
- 然后,输出格式被规定为一个字典。
instruction = '''Given the database tables and question, perform the following actions:
1 - Rank the columns in each table based on the possibility of being used in the SQL, Column that matches more with the question words or the foreign key is highly relevant and must be placed ahead. You should output them in the order of the most relevant to the least relevant.
Explain why you choose each column.
2 - Output a JSON object that contains all the columns in each table according to your explanation. The format should be like:
{
"table_1": ["column_1", "column_2", ......],
"table_2": ["column_1", "column_2", ......],
"table_3": ["column_1", "column_2", ......],
......
}

在提示中,我们还强调了与问题词或外键更匹配的列应该放在前面,以协助更准确的检索结果。同样,我们采用了self-consistency。具体而言,对于每个表格,我们一次生成十组检索到的列。然后,我们选择在每组中出现最频繁的五列作为最终结果。除了被检索到的表格和列之外,我们还将被检索到的表格的外键信息添加到上下文部分,以指定join操作所需的列。
2.2 self-consistency
Schema Linking之后,c3没有像DIN一样去判断问题的难度,而是用统一的zero-Prompt来对所有问题进行推理。不过在推理部分引入了Self-Consistency的多路投票方案。
针对每个问题会随机生成多个SQL,然后去数据库进行执行,过滤无法执行的sql,对剩余sql的执行结果进行分组,从答案出现次数最多的分组随机选一个sql作为最终的答案,也就是基于sql执行结果的major vote方案。效果上c3在spider数据集上,使用干净简洁的zero-shot-prompt+self-consistency,基本打平了Few-shot的DIN-SQL
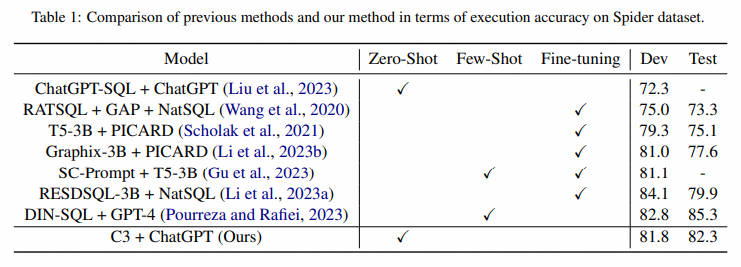
2.3 Calibration of Model Bias(模型校准)
通过分析生成的SQL查询中发生的错误,我们发现其中一些错误是由ChatGPT固有的某些biases引起的。如图3所示,ChatGPT倾向于提供额外的列和额外的执行结果。本文总结了它们为以下两种biases。
- bias1:ChatGPT在输出中倾向于保守,通常选择与问题相关但不一定必需的列。此外,我们发现在涉及数量的问题时,这种倾向尤为明显。例如,在图3(左侧)中的第一个问题中,ChatGPT在SELECT子句中选择了Year和COUNT(*)。然而,Spider数据集中的正确SQL仅选择了Year,因为COUNT()仅用于排序目的。
- bias2:ChatGPT在编写SQL查询时倾向于使用LEFT JOIN、OR和IN,但通常未能正确使用它们。这种偏见常常导致执行结果中出现额外的值。图3(右侧)中可以找到这种偏见的一些例子。
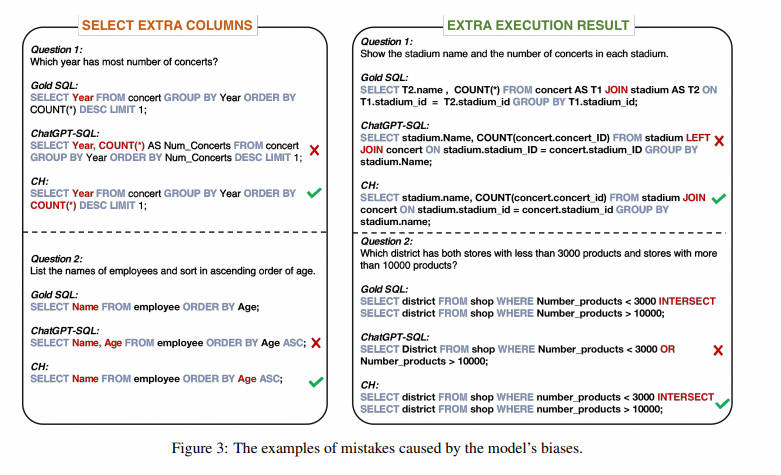
2.3.1 Calibration with Hints (CH)策略校准
为了校准这两个偏见,我们提出了一种插件校准策略,称为Calibration with Hints (CH)。CH通过使用包含历史对话的上下文提示将先验知识引入ChatGPT。在历史对话中,我们最初将ChatGPT视为出色的SQL撰写者,并引导它遵循我们提出的去偏提示。
- 提示1:针对第一个偏见,我们设计了一个提示,引导ChatGPT仅选择必要的列。这个提示在图1的右上部分有图示。它强调在仅用于排序目的时,不应在SELECT子句中包括诸如COUNT(*)之类的项目。
- 提示2:针对第二个偏见,我们设计了一个提示,防止ChatGPT滥用SQL关键字。如图1右上部分所示,我们直接要求ChatGPT避免使用LEFT JOIN、IN和OR,而是使用JOIN和INTERSECT。我们还指示ChatGPT在适当时使用DISTINCT或LIMIT,以避免重复的执行结果。
2.4 Consistency Output 一致性输出
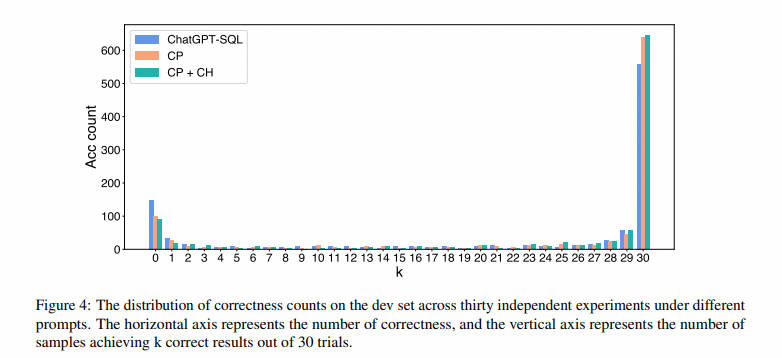
使用CP和CH方法,ChatGPT能够生成更高质量的SQL。然而,由于大型语言模型的固有随机性,ChatGPT的输出是不稳定的。为了了解ChatGPT不确定性输出的影响,我们分析了在不同提示下,在30次独立实验中开发集上正确计数的分布,如图4所示。在这个图中,ChatGPT-SQL是文献中提出的方法(Liu等,2023);此外,CP和CP + CH分别表示我们提出的Clear Prompt和Clear Prompt与Clear Hint方法的组合。无论使用哪种方法,只有不到65%的SQL语句能够一致地被正确撰写。这意味着通过提高输出的一致性,模型有很大潜力正确地撰写大多数查询。
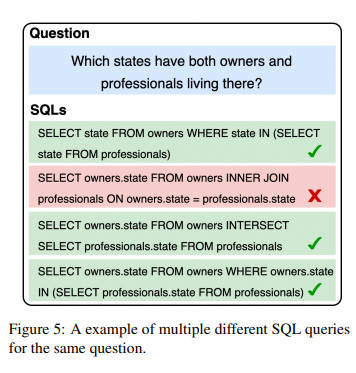
Self-consistency的动机是,在复杂的推理问题中,存在多个不同的推理路径可以得出唯一正确的答案。它首先对多个不同的推理路径进行抽样,然后选择最一致的答案,显著提高输出的质量。Text-to-SQL问题类似于推理问题,在其中有多种编写SQL查询的方式可以表示相同的含义,如图5所示。因此,我们实施了基于执行的自一致性。
具体而言,我们首先对多个推理路径进行抽样,生成多样化的SQL答案。然后,在数据库上执行这些SQL查询并收集执行结果。在从所有结果中删除错误之后,我们通过对这些执行结果应用投票机制,确定最一致的SQL作为最终SQL。例如,在图5中,我们根据执行结果对SQL查询进行分类,并用不同的颜色表示它们。然后,我们比较这些类别,确定哪个类别包含更多的SQL查询,并从该类别中选择一个SQL作为最终SQL。这种方法使我们能够利用从这些多个路径中得出的集体知识,在生成SQL查询时产生更可靠的结果。
2.5 最终Prompt 样例

当然从工程化角度看调用了太多模型,会导致性能偏低
3.DIAL-SQL 2023.11.20
论文链接:https://arxiv.org/pdf/2308.15...
大型语言模型(LLMs)已成为Text-to-SQL任务的一种新范式。然而,缺乏系统性的基准限制了设计有效、高效和经济的以大型语言模型为基础的 Text-to-SQL 解决方案的发展。为了应对这一挑战,本文首先对现有的提示工程方法进行了系统和广泛的比较,包括问题表示、示例选择和示例组织,并通过这些实验结果阐述了它们的优缺点。基于这些发现,我们提出了一种新的综合解决方案,名为 DAIL-SQL,它在 Spider 排行榜上以 86.6% 的执行准确性刷新了纪录,树立了新的标杆。为了挖掘开源大规模语言模型的潜力,我们在各种场景中探讨它们的表现,并通过有监督的微调进一步优化它们的性能。我们的研究揭示了开源大规模语言模型在Text-to-SQL 领域的潜力,以及有监督微调的优缺点。此外,为了实现高效且经济的大规模语言模型为基础的Text-to-SQL解决方案,我们强调了提示工程中的token效率,并以此为准则比较了先前的研究。我们希望我们的工作能加深对大规模语言模型中Text-to-SQL 的理解,并激发进一步的研究和广泛的应用。
3.1 研究方法
3.1.1 基础方法
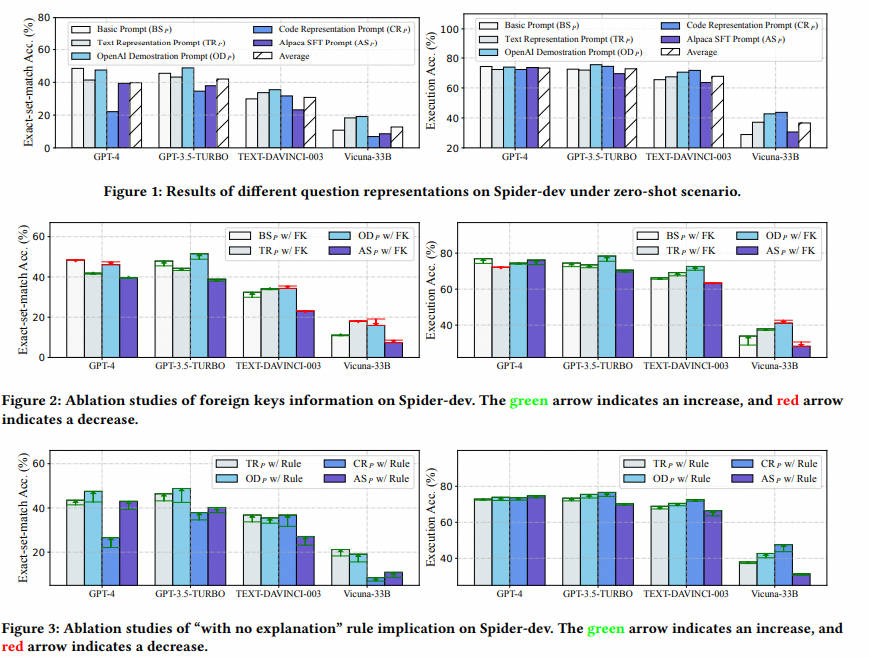
• Basic Prompt ( B S P \mathrm BS_P BSP). Basic Prompt [31] is a simple representation shown in Listing 1. It is consisted of table schemas, natural language question prefixed by “Q: ” and a response prefix “A: SELECT” to prompt LLM to generate SQL. In this paper we named it as Basic Prompt due to its absence of instructions.
基本提示 ( B S P \mathrm BS_P BSP)。基本提示 [31] 是一个简单的表示,如 Listing 1 所示。它由表模式、前缀为 “Q:” 的自然语言问题和提示 LLM 生成 SQL 的响应前缀 “a:SELECT” 组成。在本文中,由于它没有指令,我们将其命名为基本提示。

- 文本表示法提示 ( T R P \mathrm TR_P TRP)。如 Listing 2 所示,文本表示提示 [25] 表示自然语言中的模式和问题。与基本提示相比,它在提示的最开始就添加了指导 LLM 的指令。在 [25] 中,在零样本场景中,它在 Spider-dev 上实现了 69.0% 的执行准确率。
- OpenAI 演示提示 ( O D P \mathrm OD_P ODP)。OpenAI 演示提示(Listing 3)首次在 OpenAI 的官方文本到 SQL 演示 [28] 中使用,并在 [22,31] 中进行了评估。它由指令、表模式和问题组成,其中所有信息都用磅号 “#” 进行注释。与文本表示提示相比,OpenAI 演示提示中的指令更具体,有一条规则,“仅完成 sqlite SQL 查询,无需解释”,我们将在第 4.3 节中进一步讨论,并结合实验结果。

- 代码表示提示( C R P \mathrm CR_P CRP)。代码表示提示 [5,25] 以 SQL 语法表示文本到 SQL 任务。具体来说,如 Listing 4 所示,它直接呈现“CREATTABLE”SQL,并在注释中用自然语言问题提示 LLM。与其他表示相比, C R P \mathrm CR_P CRP它之所以引人注目,是因为它能够提供创建数据库所需的全面信息,例如列类型和主键 / 外键。有了这样的表示,[25] 使用 LLM CODE-DAVINCI-002 正确预测了约 75.6% 的 SQL。

Alpaca SFT 提示 ( A S P \mathrm AS_P ASP)。Alpaca SFT 提示是一种用于监督微调的提示 [38]。如 Listing 5 所示,它提示 LLM 按照指示并根据 Markdown 格式的输入上下文完成任务。我们将其包括在内,以检查其在即时工程和监督微调场景中的有效性和效率。

如表 1 所示,不同的表示用不同的 LLM 进行实验,并集成在不同的框架中,这使得很难公平有效地进行比较。此外,外国关键信息和规则含义等个别组成部分所扮演的具体角色仍不清楚。因此,有必要进行系统的研究,以更好地理解问题表征,并通过公平的比较来考察它们的优缺点。
3.2 Text-to-SQL 的上下文学习
3.2.1 示例选择
我们先总结一下先前研究中各种示例选择策略如下。
随机选择。此策略随机采样𝑘 可用候选人的示例。先前的工作 [11,24,25] 已经将其作为示例选择的基线。
问题相似性选择(QTS𝑆)。QTS𝑆 [24] 选择与目标问题𝑞最相似的𝑘个示例。具体来说,它使用预训练的语言模型将示例问题 Q 和目标问题𝑞嵌入在一起。然后,它对每个示例 - 目标对应用预定义的距离度量,如欧氏距离或负余弦相似度。最后,利用𝑘近邻(KNN)算法从 Q 中选择𝑘个与目标问题𝑞相近的示例。
遮蔽问题相似性选择(MQS 𝑆)。对于跨领域文本到 SQL,MQS 𝑆 [11] 通过使用掩码标记替换所有问题中的表名、列名和值,消除了领域特定信息的负面影响,然后使用最近邻算法计算其嵌入的相似性。
查询相似性选择 (QRS 𝑆)。与使用目标问题𝑞相比,QRS 𝑆 [25] 不使用目标问题 ,而是旨在选择与目标 SQL 查询 𝑠∗ 相似的𝑘个示例。具体来说,它使用初步模型根据目标问题𝑞和数据库𝐷生成 SQL 查询𝑠′,其中这个生成的 𝑠′ 可以视为对 𝑠∗ 的近似。然后,它根据关键词将示例中的查询编码为二进制离散语法向量。然后,通过考虑与近似查询 𝑠′ 的相似性和所选示例之间的多样性,选择了𝑘个示例。
上述策略重点是仅使用目标问题或查询来选择示例。然而,上下文学习本质上是通过类比进行学习。在文本到 SQL 的情况下,目标是生成与给定问题匹配的查询,因此大型语言模型应该学习从问题到 SQL 查询的映射。因此,我们指出在示例选择过程中,考虑问题和 SQL 查询可能有助 Text2SQL 任务。
3.2.2 示例组织
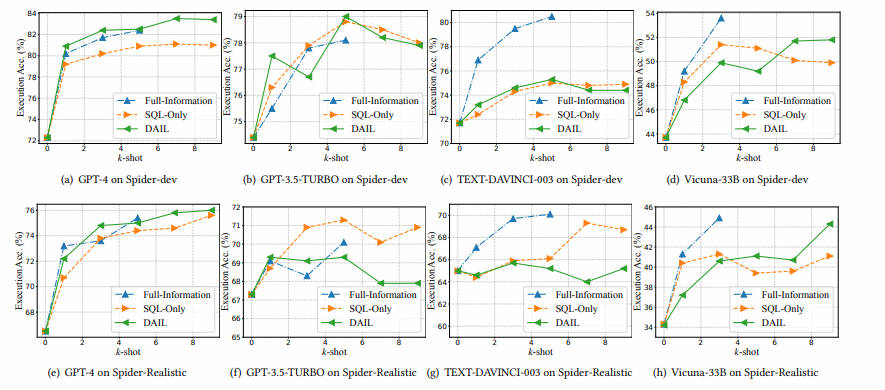
示例组织在决定上述选定示例的哪些信息将被组织到提示中方面发挥了关键作用。我们将先前研究中的现有策略总结为两个类别,即 Full-Information Organization 和 SQL-Only Organization,如 Listing 6 和 Listing7 所示。在这些示例中,${DATABASE_SCHEMA} 表示数据库模式,${TARGET_QUESTION} 代表清单 4 中的问题表示。

Full-Information Organization
完整信息组织( F I O FI_O FIO): F I O FI_O FIO [5, 25] 将示例组织成与目标问题相同的表示形式。如 listing 6 所示,示例的结构与目标问题完全相同,唯一的区别是,选定的示例在 “SELECT” 后有相应的 SQL 查询,而不是在最后有 “SELECT” 标记。
SQL-Only Organization
仅 SQL 组织( S O O SO_O SOO): S O O SO_O SOO在提示中包括选定示例的仅 SQL 查询,并在前缀中附加指示,如 listing 7 所示。这种组织旨在最大程度地利用有限的令牌长度来包括示例数量。然而,它去除了问题和相应 SQL 查询之间的映射信息,而这些信息可能很有用,我们将在后面加以证明。
3.3 DAIL-SQL
为了解决示例选择和组织中的上述问题,在本小节中,我们提出了一种新的文本到 SQL 方法,名为 DAIL-SQL。
对于示例选择,受到 MQS 𝑆 和 QRS 𝑆 的启发,我们提出了 DAIL 选择(DAIL 𝑆 ),考虑了问题和查询来选择候选示例。具体来说,DAIL 选择首先屏蔽了目标问题𝑞𝑖和候选集 Q 中的示例问题𝑞中的领域特定词。然后,它根据屏蔽的 𝑞和𝑞𝑖的嵌入之间的欧几里得距离对候选示例进行排名。同时,它计算了预测的 SQL 查询 𝑠′ 和 Q 中的𝑠𝑖之间的查询相似度。最后,选择标准通过问题相似度对排序后的候选示例进行优先排序,同时,其中查询相似度大于预定义的阈值𝜏。通过这种方式,选择的前𝑘个示例在问题和查询上都具有很好的相似性。
为了保留问题和 SQL 查询之间的映射信息并提高令牌效率,我们提出了一种新的示例组织策略,DAIL 组织(DAIL 𝑂),以在质量和数量方面进行权衡。具体来说,DAIL 𝑂呈现了示例的问题𝑞𝑖和相应的 SQL 查询 ,如 listing 8 所示。作为 FI 𝑂和 SO 𝑂之间的折中,DAIL 𝑂保留了 question-SQL 映射,并通过去除具有 token 成本的数据库模式来减少示例的 token 长度。
在 DAIL-SQL 中,我们采用 CR 𝑃作为问题表示形式。原因是,与其他表示形式相比,CR 𝑃包含了数据库的全部信息,包括主键和外键,这可能会为 LLMs 提供更多有用的信息,例如用于 “JOIN” 子句预测的外键。此外,在广泛的编码语料库上进行预训练,LLMs 可以更好地理解 CR 𝑃中的提示,而无需太多额外的工作。
总之,DAIL-SQL 使用 CR 𝑃作为问题表示,根据问题和查询的信息选择示例,并组织它们以保持问题到 SQL 的映射。在这种提示设计中,LLM 可以更好地应对 Text-to-SQL 任务,而在 Spider 排行榜中,提出的 DAIL-SQL 通过 86.2% 的执行准确性刷新了性能。
3.4 Text-to-SQL 的监督微调
为了在 zero-shot 场景中提高 LLM 的性能,现有的文本到 SQL 方法普遍采用的策略是上下文学习,这在上述小节中有讨论。作为一种替代但富有前景的选项,监督微调至今还鲜有探讨。与各种语言任务的监督微调类似,我们也可以将其应用于文本到 SQL 领域,以提高 LLM 在这个下游任务的性能。为了进一步了解监督微调如何应用于文本到 SQL,我们首先简要介绍一下如下形式。
对于 Text-to-SQL 任务,考虑一个大型语言模型 M \mathcal M M,以及一组 Text-to-SQL 的训练数据 T = { ( q i , s i , D i ) } \mathcal T = {(q_i, s_i, \mathcal D_i)} T={(qi,si,Di)},其中𝑞𝑖和𝑠𝑖分别是自然语言问题和其在数据库 D i \mathcal D_i Di上的相应查询,监督微调的目标是最小化以下损失:
其中, L \mathcal L L 是用来衡量生成的查询与真实查询之间差异的损失函数。与问题表示一样, 𝜎 确定了具有来自数据库 D \mathcal D D 的有用信息的问题表示。在这个定义中,文本到 SQL 的监督微调包括两个子任务,包括使用监督数据 T \mathcal T T 微调给定的 LLM M \mathcal M M,以获得最佳的 M ∗ \mathcal M^* M∗,以及寻找最佳的问题表示 。由于问题表示 𝜎已经讨论过,因此本节将主要集中在数据准备 T \mathcal T T 和微调上。
对于通用领域,监督数据 T = { ( p i , r i ) } \mathcal T = {(p_i, r_i)} T={(pi,ri)} 中的每个项目包含一个输入提示 𝑝𝑖和来自 LLM 的期望响应𝑟𝑖。为了确保与推理过程的一致性,我们使用监督微调并从给定的文本到 SQL 数据集生成提示 - 响应对。具体来说,给定一个文本到 SQL 数据集 T = { ( q i , s i , D i ) } \mathcal T = {(q_i, s_i,\mathcal D_i)} T={(qi,si,Di)} ,我们使用生成的微调数据通过使用目标问题和给定的数据库作为提示来微调 LLM,将 LLM 的期望查询视为响应,即 T = { ( p i = σ ( q i , D i ) , r i = s i ) } \mathcal T = {(p_i = \sigma(q_i,\mathcal D_i), r_i = s_i)} T={(pi=σ(qi,Di),ri=si)}。一旦数据准备就绪,我们可以根据可用的计算资源,使用现有的工具包通过全面微调 [29] 或参数高效微调 [13] 来调整给定的 LLM M \mathcal M M。微调完成后,优化的 LLM M ∗ \mathcal M^* M∗ 可以用于进行推理,即要求它通过自然语言问题生成查询。请注意,我们在微调和推理过程中使用相同的问题表示 𝜎。我们将进行一系列实验,讨论监督微调在 Text-to-SQL 领域的巨大潜力。
更多请参考论文原文
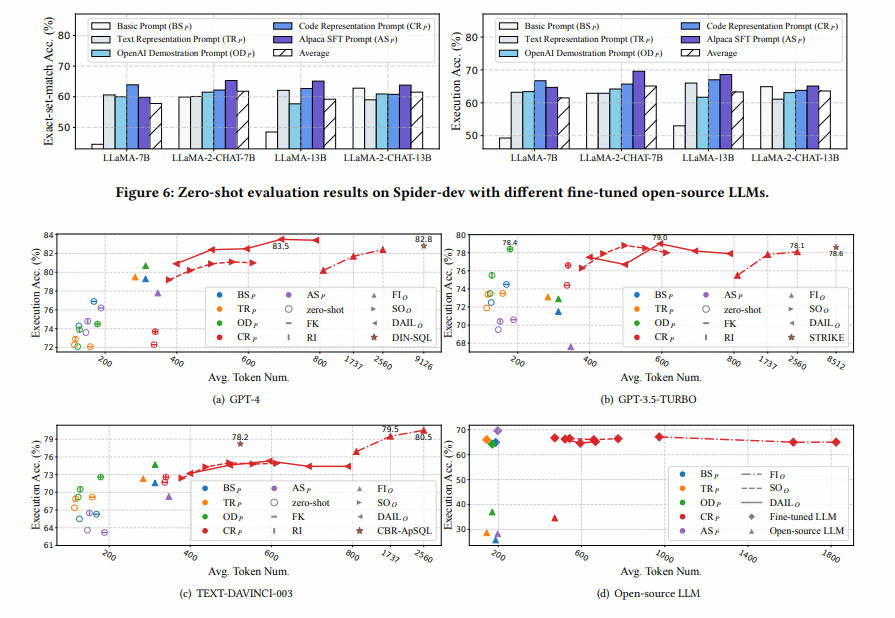
3.SQL-PaLM V4--2024.03.30 [V1 2023.3.26]
SQL-PaLM: Improved large language model adaptation for Text-to-SQL (extended) 论文链接:https://arxiv.org/abs/2306.00739
- [v1] Fri, 26 May 2023 21:39:05 UTC (315 KB)
- [v2] Wed, 7 Jun 2023 07:23:56 UTC (389 KB)
- [v3] Sun, 25 Jun 2023 06:44:48 UTC (389 KB)
- [v4] Sat, 30 Mar 2024 17:22:44 UTC (1,204 KB)
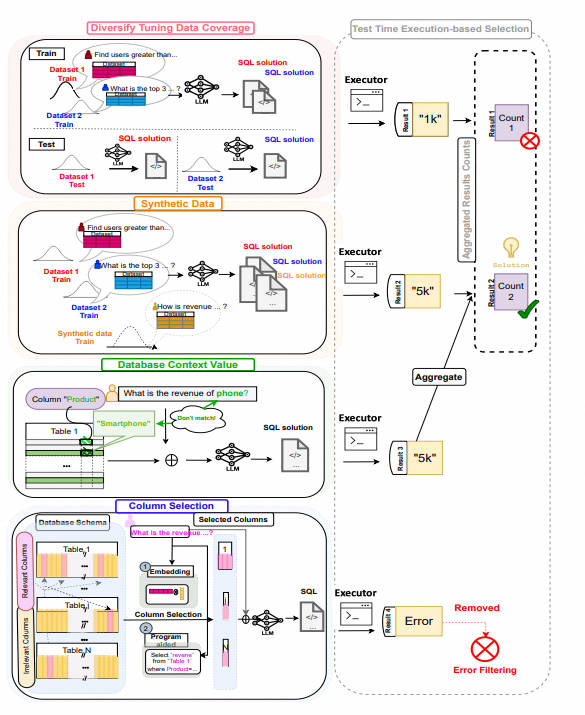
文本到SQL,将自然语言翻译成结构化查询语言(SQL)的过程,代表了大型语言模型(LLMs)的变革性应用,有可能彻底改变人类与数据的交互方式。本文介绍了SQL-PaLM框架,这是一个使用LLMs理解和增强文本到SQL的综合解决方案,用于少样本提示和指令微调的学习体制。通过少样本提示,我们探索了基于执行错误过滤的一致性解码的有效性。通过指令微调,我们深入了解了影响调优LLMs性能的关键范式。特别是,我们研究了如何通过扩大训练数据覆盖率和多样性、合成数据增强和集成特定查询的数据库内容来提高性能。我们提出了一种测试时间选择方法,通过以执行反馈为指导,集成来自多个范式的SQL输出,进一步提高准确性。此外,本文还解决了导航具有大量表和列的复杂数据库的实际挑战,提出了准确选择相关数据库元素以增强文本到SQL性能的有效技术。我们的整体方法在文本到SQL方面取得了实质性的进展,这在两个关键的公共基准测试Spider和BIRD上得到了证明。通过全面的消融和错误分析,我们揭示了框架的优势和弱点,为文本到SQL未来的工作提供了有价值的见解。
推荐参考:☆☆NL2SQL进阶系列(5):论文解读业界前沿方案(DIN-SQL、C3-SQL、DAIL-SQL)、新一代数据集BIRD-SQL解读
和以上两种方案不同的是,SQL-Palm没有进行问题拆解,而是直接基于few-shot prompt进行sql的推理生成,并且尝试了微调方案,微调后的模型会显著超越DIN-SQL。
指令构建和以上的C3有两点相似
- Self-consistency: 同样使用了基于执行结果的多路投票来选择sql
- clean prompt:同样实验了偏向于人类自然表达的表结构表述和符号化的简洁表结构描述,结论和以上C3相同。在有few-shot样本时,指令长啥样影响都不大,在zero-shot指令下,符号化的简洁表结构描述效果显著更好。对比如下上图是符号化表结构,下图是自然语言式的表结构描述

例子:




4.BIRD-SQL
- 论文:https://arxiv.org/abs/2305.03111
- 主页:https://bird-bench.github.io
- 代码:https://github.com/AlibabaRes...
这是一篇 text2sql 领域比较新的文章,23 年 5 月发布,由多位作者联合创作,一作是港大,二作是阿里达摩院,还有来自其他多位大学的作者,作者们既有学校也有公司,相信他们的研究是可以促进学界与工业界的。
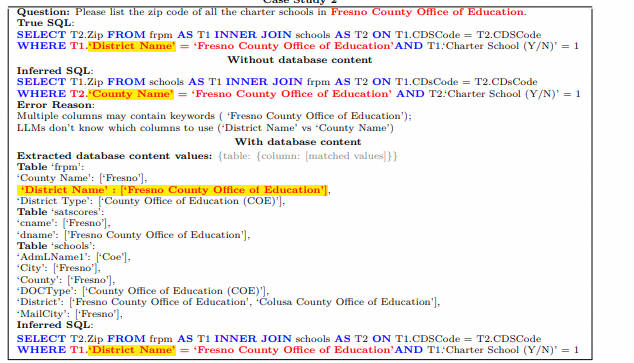
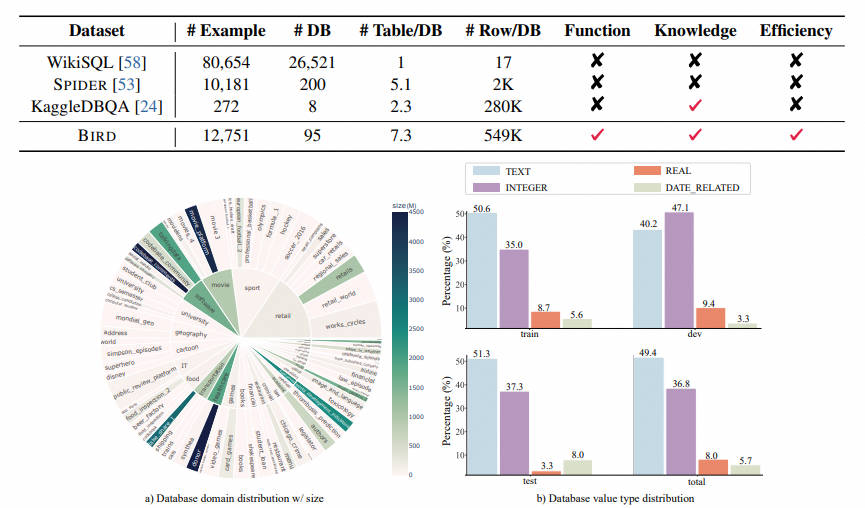
text2sql 这是近年来备受关注的领域,尤其是Codex和ChatGPT在这个任务上展示了令人印象深刻的结果。但是大多数流行的基准测试,如Spider(https://github.com/taoyds/spider)和WikiSQL(GitHub - salesforce/WikiSQL: A large annotated semantic parsing corpus for developing natural language interfaces.),主要关注的是具有少量数据库内容行的数据库模式,这使得学术研究与实际应用之间存在差距。为了缩小这个差距,作者们提出了BIRD(a BIg Bench for LaRge-Scale Database),这是一个大规模数据库中基于文本到SQL任务的大型基准测试,包含了12,751 个SQL样本和95个数据库,总大小为33.4 GB,涵盖了37个专业领域。这个基准测试强调了数据库值的新挑战,包括脏数据库内容、自然语言问题和数据库内容之间的外部知识,以及在大型数据库环境下的SQL效率。为了解决这些问题,text2sql 模型除了语义解析之外,还必须具备数据库中对数据的理解能力。实验结果表明,对于大型数据库,数据库的值在生成准确的SQL中也是非常重要的。当下,即使是最强模型如ChatGPT,其执行准确率也只有40.08%,远低于人类的92.96%,这说明了仍然存在挑战。此外,他们还做了效率分析,以提供 text2sql 的深入见解,这对于工业界是有益的。我们相信,BIRD将有助于推动 text2sql 的实际应用。
该研究主要面向真实数据库的 Text-to-SQL 评估,过去流行的测试基准,比如 Spider 和 WikiSQL,仅关注具有少量数据库内容的数据库 schema,导致学术研究与实际应用之间存在鸿沟。BIRD 重点关注海量且真实的数据库内容、自然语言问题与数据库内容之间的外部知识推理以及在处理大型数据库时 SQL 的效率等新三个挑战。
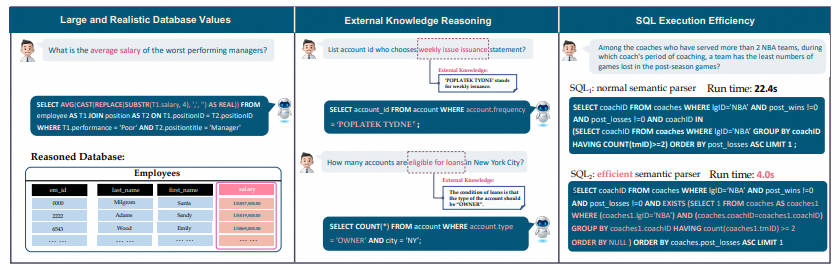
- 首先,数据库包含海量且嘈杂数据的值。在左侧示例中,平均工资的计算需要通过将数据库中的字符串(String)转化为浮点值 (Float) 之后再进行聚合计算(Aggregation);
- 其次,外部知识推断是很必要的,在中间示例中,为了能准确地为用户返回答案,模型必须先知道有贷款资格的账户类型一定是 “拥有者”(“OWNER”),这代表巨大的数据库内容背后隐藏的奥秘有时需要外部知识和推理来揭示;
- 最后,需要考虑查询执行效率。在右侧示例中,采用更高效的 SQL 查询可以显著提高速度,这对于工业界来讲具有很大价值,因为用户不仅期待写出正确的 SQL,还期待 SQL 执行的高效,尤其是在大型数据库的情况下;
4.1数据标注
BIRD 在标注的过程中解耦了问题生成和 SQL 标注。同时加入专家来撰写数据库描述文件,以此帮助问题和 SQL 标注人员更好的理解数据库。
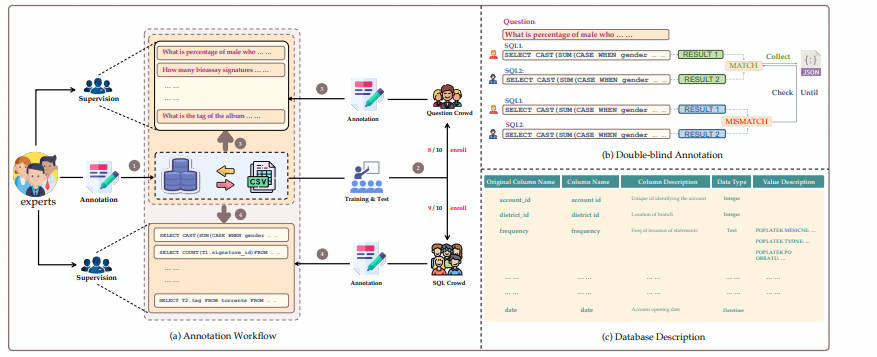
- 数据库采集:作者从开源数据平台(如 Kaggle 和 CTU Prague Relational Learning Repository)收集并处理了 80 个数据库。通过收集真实表格数据、构建 ER 图以及设置数据库约束等手动创建了 15 个数据库作为黑盒测试,来避免当前数据库被当前的大模型学习过。BIRD 的数据库包含了多个领域的模式和值, 37 个领域,涵盖区块链、体育、医疗、游戏等。
- 问题收集:首先作者雇佣专家先为数据库撰写描述文件,该描述文件包括完整的表明列名、数据库值的描述,以及理解值所用到的外部知识等。然后招募了 11 个来自美国,英国,加拿大,新加坡等国家的 native speaker 为 BIRD 产生问题。每一位 speaker 都至少具备本科及以上的学历。
- SQL 生成:面向全球招募了由数据工程师和数据库课程学生组成的标注团队为 BIRD 生成 SQL。在给定数据库和参考数据库描述文件的情况下,标注人员需生成 SQL 以正确回答问题。采用双盲(Double-Blind)标注方法,要求两位标注人员对同一个问题进行标注。双盲标注可以最大程度减少单一标注人员所带来的错误。
- 质量检测:质量检测分为结果执行的有效性和一致性两部分。有效性不仅要求执行的正确性,还要求执行结果不能是空值(NULL)。专家将逐步修改问题条件,直至 SQL 执行结果有效。
- 难度划分:text-to-SQL 的难度指标可以为研究人员提供优化算法的参考。Text-to-SQL 的难度不仅取决于 SQL 的复杂程度,还与问题难度、额外知识易理解程度以及数据库复杂程度等因素有关。因此作者要求 SQL 标注人员在标注过程中对难易程度进行评分,并将难度分为三类:简单、适中和具有挑战性。
4.2 数据统计
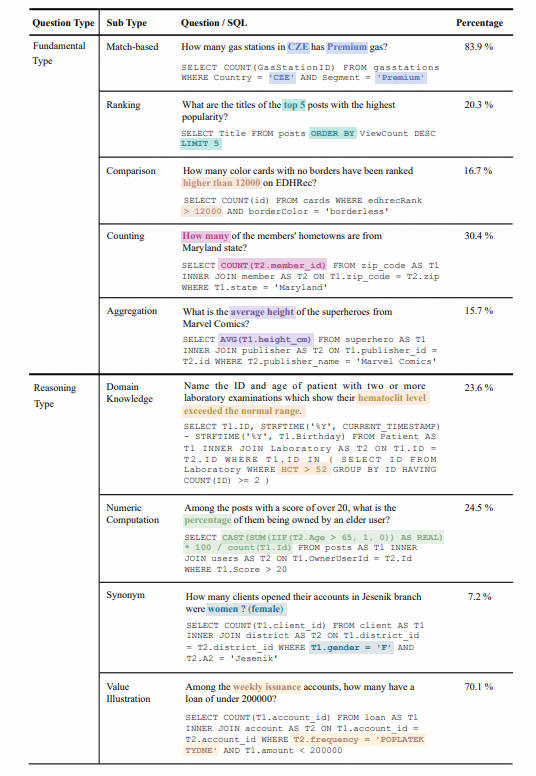
- 问题类型统计:问题分为两大类,基础问题类型(Fundamental Type)和推理问题类型(Reasoning Type)。基础问题类型包括传统 Text-to-SQL 数据集中涵盖的问题类型,而推理问题类型则包括需要外部知识来理解值的问题:
- 数据库分布:作者用 sunburst 图显示了数据库 domain 及其数据量大小之间的关系。越大的半径意味着,基于该数据库的 text-SQL 较多,反之亦然。越深的颜色则是指该数据库 size 越大,比如 donor 是该 benchmark 中最大的数据库,所占空间: 4.5GB。
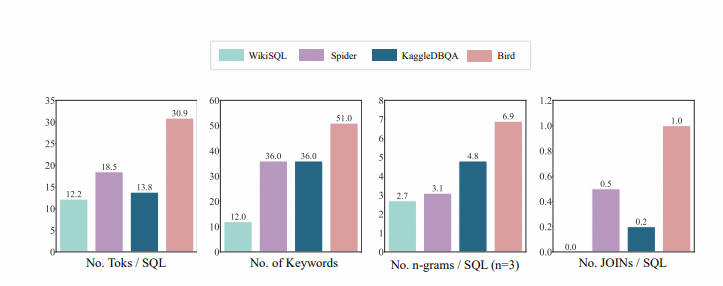
- SQL 分布:作者通过 SQL 的 token 数量,关键词数量,n-gram 类型数量,JOIN 的数量等 4 个维度来证明 BIRD 的 SQL 是迄今为止最多样最复杂的。
- 评价指标
- 执行准确率:对比模型预测的 SQL 执行结果与真实标注 SQL 执行结果的差异;
- 有效效率分数:同时考虑 SQL 的准确性与高效性,对比模型预测的 SQL 执行速度与真实标注 SQL 执行速度的相对差异,将运行时间视为效率的主要指标。
4.3 实验分析
作者选择了在之前基准测试中,表现突出的训练式 T5 模型和大型语言模型(LLM)作为基线模型:Codex(code-davinci-002)和 ChatGPT(gpt-3.5-turbo)。为了更好地理解多步推理是否能激发大型语言模型在真实数据库环境下的推理能力,还提供了它们的思考链版本(Chain-of-Thought)。并在两种设置下测试基线模型:一种是完全的 schema 信息输入,另一种是人类对涉及问题的数据库值的理解,总结成自然语言描述(knowledge evidence)辅助模型理解数据库。
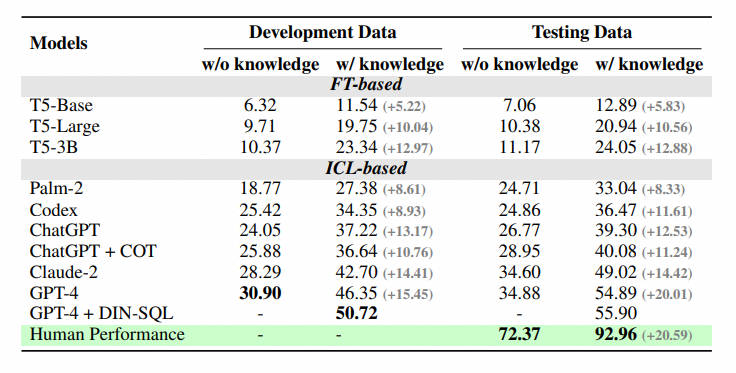
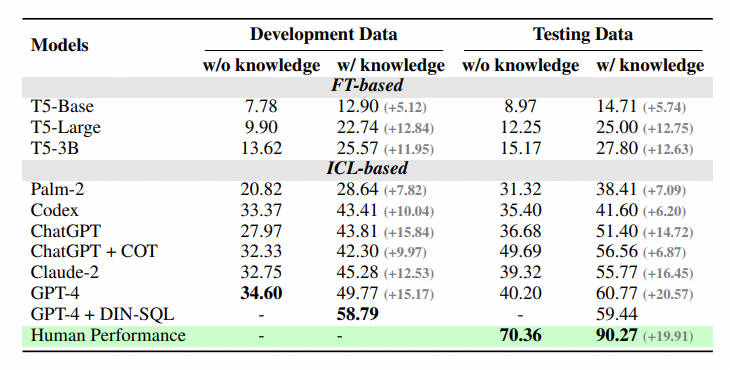
作者给出了一些结论:
- 额外知识的增益:增加对数据库值理解的知识(knowledge evidence)有明显的效果提升,这证明在真实的数据库场景中,仅依赖语义解析能力是不够的,对数据库值的理解会帮助用户更准确地找到答案。
- 思维链不一定完全有益:在模型没有给定数据库值描述和零样本(zero-shot)情况下,模型自身的 COT 推理可以更准确地生成答案。然而,当给定额外的知识(knowledge evidence)后,让 LLM 进行 COT,发现效果并不显著,甚至会下降。因此在这个场景中, LLM 可能会产生知识冲突。如何解决这种冲突,使模型既能接受外部知识,又能从自身强大的多步推理中受益,将是未来重点的研究方向。
- 与人类的差距:BIRD 还提供了人类指标,作者以考试的形式测试标注人员在第一次面对测试集的表现,并将其作为人类指标的依据。实验发现,目前最好的 LLM 距离人类仍有较大的差距,证明挑战仍然存在。作者执行了详细的错误分析,给未来的研究提供了一些潜在的方向。

5. 更多前沿论文推荐
| 序号 | 类型 | 标题 |
| 1 | Main | Benchmarking and Improving Text-to-SQL Generation under Ambiguity |
| 2 | Main | Evaluating Cross-Domain Text-to-SQL Models and Benchmarks |
| 3 | Main | Exploring Chain of Thought Style Prompting for Text-to-SQL |
| 4 | Main | Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations |
| 5 | Main | Non-Programmers Can Label Programs Indirectly via Active Examples: A Case Study with Text-to-SQL |
| 6 | Findings | Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison |
| 7 | Findings | Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies |
| 8 | Findings | Error Detection for Text-to-SQL Semantic Parsing |
| 9 | Findings | ReFSQL: A Retrieval-Augmentation Framework for Text-to-SQL Generation |
| 10 | Findings | Selective Demonstrations for Cross-domain Text-to-SQL |
| 11 | Findings | Semantic Decomposition of Question and SQL for Text-to-SQL Parsing |
| 12 | Findings | SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data |
正会论文(Main Conference)
中稿的这 5 篇正会论文来看,主要还是围绕着 Text-to-SQL 的评测、实际系统交互和 LLM 在 Text-to-SQL 任务的应用为主。
5.1 Benchmarking and Improving Text-to-SQL Generation under Ambiguity -2023.10.20
- 链接:https://arxiv.org/pdf/2310.13659v1.pdf
- 摘要:在文本到 SQL 转换的研究中,大多数基准测试都是针对每个文本查询对应一个正确的 SQL 的数据集。然而,现实生活中的数据库上的自然语言查询经常由于模式名称的重叠和多个令人困惑的关系路径,而涉及对预期 SQL 的显著歧义。为了弥合这一差距,我们开发了一个名为 AmbiQT 的新基准,其中包含超过 3000 个示例,每个文本都可以由于词汇和 / 或结构上的歧义而被解释为两个合理的 SQL。 面对歧义时,理想的 top-k 解码器应该生成所有有效的解释,以便用户可能的消歧(Elgohary 等,2021 年;Zhong 等,2022 年)。我们评估了几个文本到 SQL 系统和解码算法,包括那些使用最先进的大型语言模型(LLMs)的系统,发现它们距离这一理想还很远。主要原因是流行的束搜索算法及其变体将 SQL 查询视为字符串,并在 top-k 中产生无益的令牌级别多样性。 我们提出了一种名为 LogicalBeam 的新解码算法,该算法使用基于计划的模板生成和受限填充的混合方法来导航 SQL 逻辑空间。逆向生成的计划使模板多样化,而仅在模式名称上分支的束搜索填充提供了值多样性。LogicalBeam 在生成 top-k 排名输出中的所有候选 SQL 方面,比最先进的模型高出 2.5 倍的效果。它还提高了 SPIDER 和 Kaggle DBQA 上的前 5 名精确匹配和执行匹配准确率。
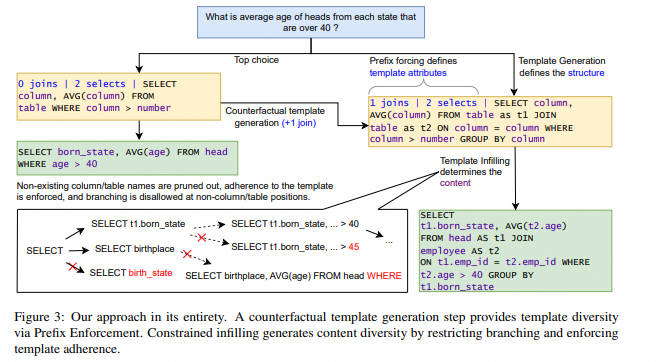
- 要点:主要关注于自然语言到 SQL 转换时的歧义现象,作者先是自己设计了一个评测基准 AmbiQT,然后针对性设计了一种 LogicalBeam 的新解码算法,改善原有的 beam-search 带来的 token-level 的 beam 差异。
5.2 Evaluating Cross-Domain Text-to-SQL Models and Benchmarks--2023.10.27
- 链接:https://arxiv.org/pdf/2310.18538v1.pdf
- 摘要:文本到 SQL 的基准测试在评估该领域的进展和不同模型的排名方面起着关键作用。然而,由于各种原因,比如自然语言查询的不明确、模型生成的查询和参考查询中固有的假设、以及在某些条件下 SQL 输出的非确定性特性,导致基准测试中模型生成的 SQL 查询与参考 SQL 查询的准确匹配失败。在本文中,我们对几个著名的跨领域文本到 SQL 基准测试进行了广泛的研究,并对这些基准测试中表现最佳的一些模型进行了重新评估,包括手动评估 SQL 查询和用等效表达式重写它们。我们的评估揭示,由于可以从提供的样本中得出多种解释,所以在这些基准测试中达到完美表现是不可行的。此外,我们发现这些模型的真实性能被低估了,而且在重新评估后它们的相对性能发生了变化。最值得注意的是,我们的评估揭示了一个令人惊讶的发现:在我们的人类评估中,一种基于最新 GPT4 模型的模型超越了 Spider 基准测试中的金标准参考查询。这一发现突显了谨慎解读基准测试评估的重要性,同时也认识到进行额外独立评估在推动该领域进步中的关键作用。
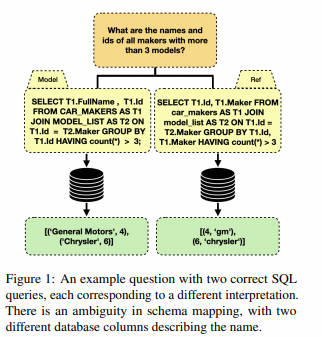
- 要点:主要讨论了现有 Text-to-SQL 评测基准中存在的语言不明确、数据值不明确等导致的评估标准失真的现象,作者对部分存在上述问题的 Question-SQL Pair 进行重写后对现有的一些 SOTA 模型进行了再评估。
5.3 Exploring Chain of Thought Style Prompting for Text-to-SQL 2023.10.27
- 链接:https://arxiv.org/abs/2305.14215
- 摘要:使用大型语言模型(LLMs)进行上下文学习由于在各种任务上的卓越的少样本表现,近来引起了越来越多的关注。然而,其在文本到 SQL 解析上的表现仍有很大的提升空间。在本文中,我们假设改善 LLMs 在文本到 SQL 解析上的一个关键方面是其多步推理能力。因此,我们系统地研究了如何通过思维链(CoT)风格的提示来增强 LLMs 的推理能力,包括原始的思维链提示(Wei 等,2022b)和最少到最多提示(Zhou 等,2023)。我们的实验表明,像 Zhou 等(2023)中的迭代提示可能对文本到 SQL 解析来说并不必要,而使用详细的推理步骤往往会有更多的错误传播问题。基于这些发现,我们提出了一种新的 CoT 风格的提示方法,用于文本到 SQL 解析。与不带推理步骤的标准提示方法相比,它在 Spider 开发集和 Spider 真实集上分别带来了 5.2 和 6.5 点的绝对提升;与最少到最多提示方法相比,分别带来了 2.4 和 1.5 点的绝对提升。
- 要点:本文探索了应用 LLM 解决 Text-to-SQL 任务时的 Prompt Engineering。作者设计了一种 “问题分解” 的 Prompt 格式并结合每个子问题中的表列名进行融合,实现了与 RASAT+PICARD 模型相当的表现。


5.4 Non-Programmers Can Label Programs Indirectly via Active Examples: A Case Study with Text-to-SQL --2023.10.23
- 链接:https://arxiv.org/abs/2205.12422
- 摘要:非程序员能否通过自然语言标注来间接地表示其含义的复杂程序?我们介绍了 APEL 框架,其中非程序员通过选择由种子语义解析器(例如 Codex)生成的候选程序来进行标注。由于他们无法理解这些候选程序,我们要求他们通过检查程序的输入输出示例来间接选择。对于每个表达,APEL 会主动搜索一个简单的输入,在此输入上候选程序倾向于产生不同的输出。然后,我们仅要求非程序员选择合适的输出,从而推断出哪个程序是正确的,并可以用来微调解析器。作为一个案例研究,我们招募了非程序员人类使用 APEL 重新标注 SPIDER,一个文本到 SQL 数据集。我们的方法达到了与原始专家标注者相同的标注准确率(75%),并揭露了原始标注中的许多微妙错误。
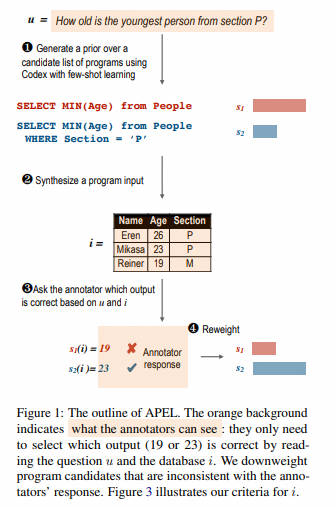

- 要点:本文提出了 APEL 框架,使非程序员能通过选择候选程序的示例输出来注释文本到 SQL 的语义。这一方法在文本到 SQL 数据集 SPIDER 上达到了与专家相当的注释准确性,并揭示了原始注释中的一些错误。
5.5 Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations
- 链接:https://arxiv.org/abs/2305.07372
- 摘要:关系数据库在这个大数据时代扮演着重要角色。然而,对于非专家来说,由于他们不熟悉 SQL 等数据库语言,充分释放关系数据库的分析能力是具有挑战性的。虽然已经提出了许多技术来自动从自然语言生成 SQL,但它们存在两个问题:(1)特别是对于复杂查询,它们仍然会犯许多错误,(2)它们没有为非专家用户提供一种灵活的方式来验证和修正错误的查询。为了解决这些问题,我们引入了一种新的交互机制,允许用户直接编辑不正确的 SQL 的逐步解释来修复 SQL 错误。在 Spider 基准测试上的实验表明,我们的方法在执行准确性方面至少比三种最先进的方法高出 31.6%。另外,一项包括 24 名参与者的用户研究进一步表明,我们的方法帮助用户在更少的时间内以更高的信心解决了更多的 SQL 任务,展示了其拓宽数据库访问,特别是对于非专家的潜力。
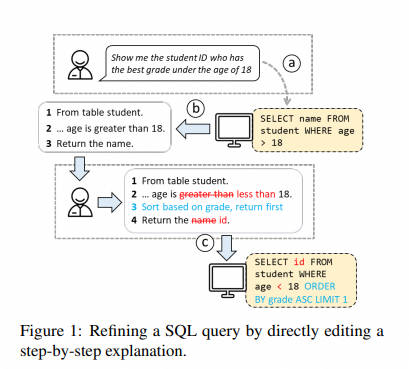
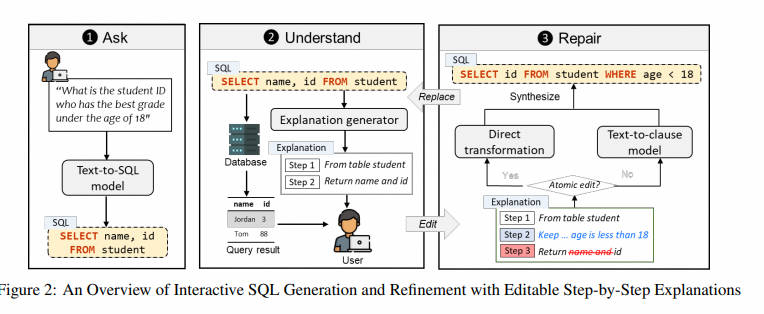
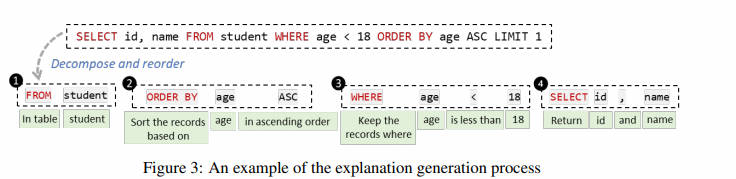
- 要点:提出了一个名为 STEPS 的交互式文本到 SQL 系统,允许用户通过直接编辑逐步解释来修正错误的 SQL 查询。Spider 上实验显示,STEPS 在提高任务完成速度、准确性和用户自信度方面相比现有方法有显著优势。
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
参考链接:
- 论文阅读:DIN-SQL: Decomposed In-Context Learning of Text-to-SQL withSelf-Correction:https://blog.csdn.net/qq_4268...
- 【论文阅读】《Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation:https://blog.csdn.net/weixin_...
- DAIL-SQL:LLM在Text-to-SQL任务中的详细评估 https://zhuanlan.zhihu.com/p/...

