
在PyTorch中,FP8(8-bit 浮点数)是一个较新的数据类型,用于实现高效的神经网络训练和推理。它主要被设计来降低模型运行时的内存占用,并加快计算速度,同时尽量保持训练和推理的准确性。虽然PyTorch官方在标准发布中尚未全面支持FP8,但是在2.2版本中PyTorch已经包含了对FP8的“有限支持”并且出现了2个新的变量类型,
torch.float8_e4m3fn和
torch.float8_e5m2,而H100也支持这种类型,所以这篇文章我们就来介绍如何使用FP8来提高训练效率

模型架构
我们定义了一个Vision Transformer (ViT)支持的分类模型(使用流行的timm Python包版本0.9.10)以及一个随机生成的数据集。我们选择了ViT-Huge的有6.32亿个参数的最大的模型,这样可以演示FP8的效果。
import torch, time
import torch.optim
import torch.utils.data
import torch.distributed as dist
from torch.nn.parallel.distributed import DistributedDataParallel as DDP
import torch.multiprocessing as mp
# modify batch size according to GPU memory
batch_size = 64
from timm.models.vision_transformer import VisionTransformer
from torch.utils.data import Dataset
# use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=[index % 1000], dtype=torch.int64)
return rand_image, label
def mp_fn(local_rank, *args):
# configure process
dist.init_process_group("nccl",
rank=local_rank,
world_size=torch.cuda.device_count())
torch.cuda.set_device(local_rank)
device = torch.cuda.current_device()
# create dataset and dataloader
train_set = FakeDataset()
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size,
num_workers=12, pin_memory=True)
# define ViT-Huge model
model = VisionTransformer(
embed_dim=1280,
depth=32,
num_heads=16,
).cuda(device)
model = DDP(model, device_ids=[local_rank])
# define loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(train_loader):
# copy data to GPU
inputs = data[0].to(device=device, non_blocking=True)
label = data[1].squeeze(-1).to(device=device, non_blocking=True)
# use mixed precision to take advantage of bfloat16 support
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
outputs = model(inputs)
loss = criterion(outputs, label)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# capture step time
batch_time = time.perf_counter() - t0
if step > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 50:
break
print(f'average step time: {summ/count}')
if __name__ == '__main__':
mp.spawn(mp_fn,
args=(),
nprocs=torch.cuda.device_count(),
join=True)Transformer Engine
PyTorch(版本2.1)不包括FP8的数据类型。所以我们需要通过第三方的库Transformer Engine (TE),这是一个用于在NVIDIA gpu上加速Transformer模型的专用库。
使用FP8要比16float16和bfloat16复杂得多。这里我们不用关心细节,因为TE都已经帮我们实现了,我们只要拿来用就可以了。
但是需要对我们上面的模型进行一些简单的修改,需要将transformer变为TE的专用transformer层
import transformer_engine.pytorch as te
from transformer_engine.common import recipe
class TE_Block(te.transformer.TransformerLayer):
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_norm=False,
proj_drop=0.,
attn_drop=0.,
init_values=None,
drop_path=0.,
act_layer=None,
norm_layer=None,
mlp_layer=None
):
super().__init__(
hidden_size=dim,
ffn_hidden_size=int(dim * mlp_ratio),
num_attention_heads=num_heads,
hidden_dropout=proj_drop,
attention_dropout=attn_drop
)然后修改VisionTransformer初始化使用自定义层:
model = VisionTransformer(
embed_dim=1280,
depth=32,
num_heads=16,
block_fn=TE_Block
).cuda(device)最后一个修改是用te包裹模型前向传递。Fp8_autocast上下文管理器。此更改需要支持FP8的GPU:
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
with te.fp8_autocast(enabled=True):
outputs = model(inputs)
loss = criterion(outputs, label)下面我们就可以测试结果:
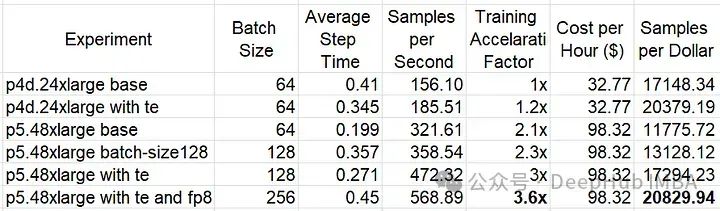
可以看到,使用TE块提高了p4d(~19%)和p5(~32%)的性价比。使用FP8可将p5上的性能额外提高约20%。在TE和FP8优化之后,基于h100的p5.48large的性价比优于基于a100的p4d.24large 。并且训练速度提高了3倍。
Pytorch的原生FP8
在2.2版本后,pytorch原生FP8支持已经是“有限支持”了,所以我们可以先学习一下如何使用了。
import torch
from tabulate import tabulate
f32_type = torch.float32
bf16_type = torch.bfloat16
e4m3_type = torch.float8_e4m3fn
e5m2_type = torch.float8_e5m2
# collect finfo for each type
table = []
for dtype in [f32_type, bf16_type, e4m3_type, e5m2_type]:
numbits = 32 if dtype == f32_type else 16 if dtype == bf16_type else 8
info = torch.finfo(dtype)
table.append([info.dtype, numbits, info.max,
info.min, info.smallest_normal, info.eps])
headers = ['data type', 'bits', 'max', 'min', 'smallest normal', 'eps']
print(tabulate(table, headers=headers))
'''
Output:
data type bits max min smallest normal eps
------------- ---- ----------- ------------ --------------- -----------
float32 32 3.40282e+38 -3.40282e+38 1.17549e-38 1.19209e-07
bfloat16 16 3.38953e+38 -3.38953e+38 1.17549e-38 0.0078125
float8_e4m3fn 8 448 -448 0.015625 0.125
float8_e5m2 8 57344 -57344 6.10352e-05 0.25
'''我们可以通过在张量初始化函数中指定dtype来创建FP8张量,如下所示:
device="cuda"
e4m3 = torch.tensor(1., device=device, dtype=e4m3_type)
e5m2 = torch.tensor(1., device=device, dtype=e5m2_type)也可以强制转换为FP8。在下面的代码中,我们生成一个随机的浮点张量,并比较将它们转换为四种不同的浮点类型的结果:
x = torch.randn(2, 2, device=device, dtype=f32_type)
x_bf16 = x.to(bf16_type)
x_e4m3 = x.to(e4m3_type)
x_e5m2 = x.to(e5m2_type)
print(tabulate([[‘float32’, *x.cpu().flatten().tolist()],
[‘bfloat16’, *x_bf16.cpu().flatten().tolist()],
[‘float8_e4m3fn’, *x_e4m3.cpu().flatten().tolist()],
[‘float8_e5m2’, *x_e5m2.cpu().flatten().tolist()]],
headers=[‘data type’, ‘x1’, ‘x2’, ‘x3’, ‘x4’]))
'''
The sample output demonstrates the dynamic range of the different types:
data type x1 x2 x3 x4
------------- -------------- -------------- -------------- --------------
float32 2.073093891143 -0.78251332044 -0.47084918620 -1.32557279110
bfloat16 2.078125 -0.78125 -0.4707031 -1.328125
float8_e4m3fn 2.0 -0.8125 -0.46875 -1.375
float8_e5m2 2.0 -0.75 -0.5 -1.25
------------- -------------- -------------- -------------- --------------
'''虽然创建FP8张量很容易,但FP8张量上执行一些基本的算术运算是不支持的。并且需要特定的函数,比如torch._scaled_mm来进行矩阵乘法。
output, output_amax = torch._scaled_mm(
torch.randn(16,16, device=device).to(e4m3_type),
torch.randn(16,16, device=device).to(e4m3_type).t(),
bias=torch.randn(16, device=device).to(bf16_type),
out_dtype=e4m3_type,
scale_a=torch.tensor(1.0, device=device),
scale_b=torch.tensor(1.0, device=device)
)那么如何进行模型的训练呢,我们来做一个演示
import torch
from timm.models.vision_transformer import VisionTransformer
from torch.utils.data import Dataset, DataLoader
import os
import time
#float8 imports
from float8_experimental import config
from float8_experimental.float8_linear import Float8Linear
from float8_experimental.float8_linear_utils import (
swap_linear_with_float8_linear,
sync_float8_amax_and_scale_history
)
#float8 configuration (see documentation)
config.enable_amax_init = False
config.enable_pre_and_post_forward = False
# model configuration controls:
fp8_type = True # toggle to change floating-point precision
compile_model = True # toggle to enable model compilation
batch_size = 32 if fp8_type else 16 # control batch size
device = torch.device('cuda')
# use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 256, 256], dtype=torch.float32)
label = torch.tensor(data=[index % 1024], dtype=torch.int64)
return rand_image, label
# get data loader
def get_data(batch_size):
ds = FakeDataset()
return DataLoader(
ds,
batch_size=batch_size,
num_workers=os.cpu_count(),
pin_memory=True
)
# define the timm model
def get_model():
model = VisionTransformer(
class_token=False,
global_pool="avg",
img_size=256,
embed_dim=1280,
num_classes=1024,
depth=32,
num_heads=16
)
if fp8_type:
swap_linear_with_float8_linear(model, Float8Linear)
return model
# define the training step
def train_step(inputs, label, model, optimizer, criterion):
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
outputs = model(inputs)
loss = criterion(outputs, label)
optimizer.zero_grad(set_to_none=True)
loss.backward()
if fp8_type:
sync_float8_amax_and_scale_history(model)
optimizer.step()
model = get_model()
optimizer = torch.optim.Adam(model.parameters())
criterion = torch.nn.CrossEntropyLoss()
train_loader = get_data(batch_size)
# copy the model to the GPU
model = model.to(device)
if compile_model:
# compile model
model = torch.compile(model)
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(train_loader):
# copy data to GPU
inputs = data[0].to(device=device, non_blocking=True)
label = data[1].squeeze(-1).to(device=device, non_blocking=True)
# train step
train_step(inputs, label, model, optimizer, criterion)
# capture step time
batch_time = time.perf_counter() - t0
if step > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 50:
break
print(f'average step time: {summ / count}')这里需要特定的转换函数,将一些操作转换为支持FP8的版本,需要说明的是,因为还在试验阶段所以可能不稳定
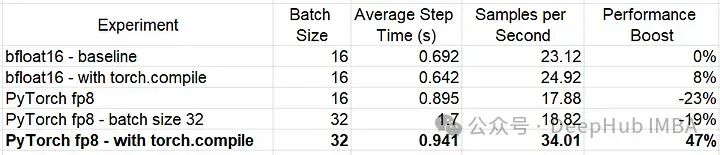
FP8线性层的使用使我们的模型的性能比我们的基线实验提高了47%(!!)
对比TE

未编译的TE FP8模型的性能明显优于我们以前的FP8模型,但编译后的PyTorch FP8模型提供了最好的结果。因为TE FP8模块不支持模型编译。所以使用torch.compile会导致“部分编译”,即它在每次使用FP8时将计算分拆为多个图。
总结
在这篇文章中,我们演示了如何编写PyTorch训练脚本来使用8位浮点类型。TE是一个非常好的库,因为它可以让我们的代码修改量最小,而PyTorch原生FP8支持虽然需要修改代码,并且还是在试验阶段(最新的2.3还是在试验阶段),可能会产生问题,但是这会让训练速度更快。
不过总的来说FP8的确可以加快我们的训练速度,提高GPU的使用效率。这里要提一句TE是由NVIDIA开发的,并对其gpu进行了大量定制,所以如果是N卡的话可以直接用TE
https://avoid.overfit.cn/post/0dd1fba546674b48b932260fa8742971

