
联邦学习是一种分布式的机器学习方法,其中多个客户端在一个中央服务器的协调下合作训练模型,但不共享他们的本地数据。一般情况下我们对联邦学习的理解都是大模型和深度学习模型才可以进行联邦学习,其实基本上只要包含参数的机器学习方法都可以使用联邦学习的方法保证数据隐私。
所以本文将以高斯朴素贝叶斯分类器为例创建一个联邦学习系统。我们将深入探讨联邦学习的数学原理,并将代码分解成易于理解的部分,配以丰富的代码片段和解释。
高斯朴素贝叶斯简介
高斯朴素贝叶斯(GaussianNB)是一种分类算法,它假设特征遵循高斯分布。之所以称之为“朴素”,是因为它假设给定类标签的特征是独立的。使用贝叶斯定理计算样本属于某类的概率。
对于给定类别 y 的特征 Xi,高斯分布的概率密度函数是:

其中 μy 和 σy^2 是类别 y 的特征的均值和方差。
后验概率 P(y∣X) 的计算公式为:

其中 P(y) 是类别的先验概率。
联邦学习工作流程
- 数据分配:将训练数据分配给多个客户端。
- 本地训练:每个客户端训练一个本地高斯NB模型。
- 参数聚合:服务器从客户端聚合模型参数。
- 全局模型评估:服务器在测试数据上评估聚合模型。
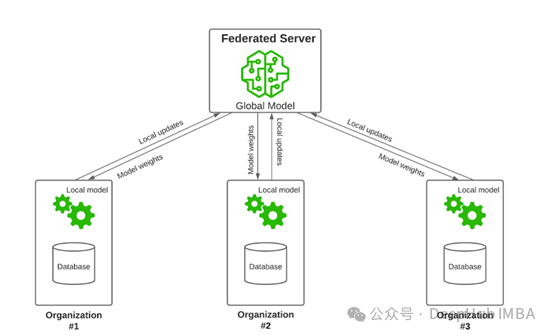
可以看到这里最主要的部分就是参数聚合,也就是说,只要能够进行参数聚合操作,并且保证聚合的方法有效,那么模型就可以进行联邦学习。
代码示例
我们加载Iris数据集并将其分成训练集和测试集。
importnumpyasnp
fromsklearn.datasetsimportload_iris
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.naive_bayesimportGaussianNB
fromsklearn.metricsimportaccuracy_score, classification_report
# Load the Iris dataset
iris=load_iris()
X=iris.data
y=iris.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.3, random_state=42将训练数据分成几个子集,每个子集代表一个客户端,在客户端之间分发数据。
# Number of clients
num_clients=5
# Split the training data among the clients
client_data=np.array_split(np.column_stack((X_train, y_train)), num_clients)每个客户端训练一个本地的GaussianNB模型并返回它的参数。
# Function to train a local model and return its parameters
deftrain_local_model(data):
X_local=data[:, :-1]
y_local=data[:, -1]
model=GaussianNB()
model.fit(X_local, y_local)
returnmodel.theta_, model.var_, model.class_prior_, model.class_count_
# Train local models and collect their parameters
local_params= [train_local_model(data) fordatainclient_data]服务器端聚合本地模型的参数以形成全局模型。
# Aggregate the local model parameters
defaggregate_parameters(local_params):
num_features=local_params[0][0].shape[1]
num_classes=len(local_params[0][2])
# Initialize global parameters
global_theta=np.zeros((num_classes, num_features))
global_sigma=np.zeros((num_classes, num_features))
global_class_prior=np.zeros(num_classes)
global_class_count=np.zeros(num_classes)
# Sum the parameters from all clients
fortheta, sigma, class_prior, class_countinlocal_params:
global_theta+=theta*class_count[:, np.newaxis]
global_sigma+=sigma*class_count[:, np.newaxis]
global_class_prior+=class_prior*class_count
global_class_count+=class_count
# Normalize to get the means and variances
global_theta/=global_class_count[:, np.newaxis]
global_sigma/=global_class_count[:, np.newaxis]
global_class_prior=global_class_count/global_class_count.sum()
returnglobal_theta, global_sigma, global_class_prior
# Aggregate the model parameters
global_theta, global_sigma, global_class_prior=aggregate_parameters(local_params)这里我们可以看到,因为模型只有 theta, sigma, class_prior, class_count这几个参数,并且我们对参数取了平均值(最简单的方法),然后进行了Normalize.
注意,在sklearn1.0以前版本使用的是sigma_参数,之后版本改名为var_ 所以如果代码报错,请检查slearn版本和官方文档,本文代码在sklearn1.5上运行通过
然后就可以用聚合后的参数创建一个全局的GaussianNB模型,并在测试数据上对其进行了评估。
# Create a global model with aggregated parameters
global_model=GaussianNB()
global_model.theta_=global_theta
global_model.var_=global_sigma
global_model.class_prior_=global_class_prior
global_model.classes_=np.arange(len(global_class_prior))
# Evaluate the global model
y_pred=global_model.predict(X_test)
accuracy=accuracy_score(y_test, y_pred)
report=classification_report(y_test, y_pred, target_names=iris.target_names)
print("Accuracy:", accuracy)
print("Classification Report:\n", report)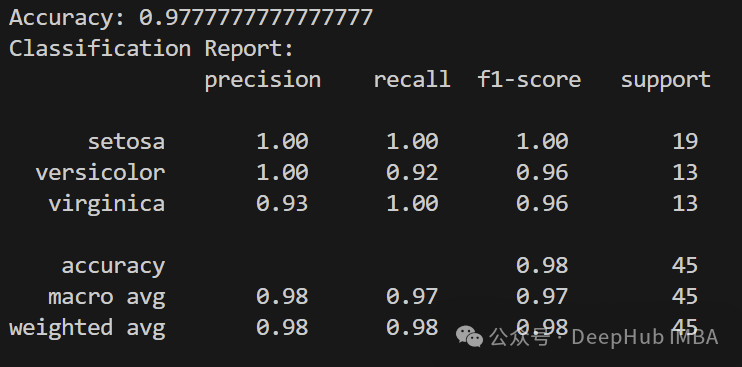
可以看到,聚合模型是没有问题的。
总结
在本文中我们介绍了使用高斯Naïve贝叶斯创建一个联邦学习系统。包括了一些简单的GaussianNB的数学基础,在客户端之间分布训练数据,训练局部模型,汇总参数,最后评估全局模型。这种方法在利用分布式计算资源的同时保护了数据隐私。
联邦学习在不损害数据隐私的情况下为协作机器学习开辟了新的可能性。这里演示只是提供了一个基础,可以使用更高级的技术和隐私保护机制进行扩展。
https://avoid.overfit.cn/post/fcb204a39906412cbca818e9969e2deb

