
大语言模型的发展让研究人员专注于建立尽可能大的模型。但是其实较小的模型在某些任务中表现会优于较大的模型时,例如:Llama 3-8B在MMLU任务上的表现优于较大的Llama 2-70B !
这就说明大模型并不是万能的,在一些特定任务中,小模型表现得可能会更出色。所以IBM的研究人员就推出了一个轻量级模型Tiny Time Mixers[1],并且在M4数据集上优于大型SOTA模型(包括MOIRAI),并且它还是开源的!
Tiny Time Mixer (TTM)
TTM是一个轻量级的,基于mlp的基础TS模型(≤1M参数),在零样本预测方面表现出色,甚至优于较大的SOTA模型。
TTM非常快:因为它没有注意机制——它只使用完全连接的神经网络层。
TSMixer Foundation: TTM在其架构中利用TSMixer[2]。
丰富的输入:TTM具有多元预测能力,可以接受额外的信息、外生变量和已知的未来输入,增强了其预测的通用性。
快速而强大:使用6个A100 gpu,在不到8小时的时间内对Monash数据集的244M个样本进行了TTM预训练。
优越的零样本预测:经过预训练的TTM,可以很容易地用于零概率预测,在未见过的数据上超过较大的SOTA模型。
说明:Google也有一个类似的模型叫TSMixer——是这篇论文几个月后发布!并且Google的TSMixer也是一个基于mlp的模型,并且实现了显著的性能!我们最后的引用是IBM的TSMixer[2]。
IBM的TSMixer (TTM的基础)在线性投影后应用softmax来计算重要性权重——然后将其与隐藏向量相乘,以提高或降低每个特征的规模。作者称这种操作为“门控注意力”。虽然也叫注意力,但它通常不是传统的多头注意力,没有查询、键、值和多个头部。因此,TSMixer(或TTM)都不是基于transformer的模型。
TTM创新
TTM引入了几个突破性的特性:
多级建模:TTM首先以通道独立的方式(单变量序列)进行预训练,并在微调期间使用跨通道混合来学习多变量依赖关系。
自适应补丁:TTM不是使用单一的补丁长度,而是学习不同层的不同补丁长度。由于每个时间序列在特定的补丁长度下表现最佳,自适应补丁有助于模型更好地泛化不同的数据。
频率前缀调整:不同的频率(例如,每周、每天的数据)对基础时间序列模型具有挑战性。TTM使用一个额外的嵌入层来编码时间序列频率,使模型能够根据信号的频率准确地调整其预测。
TTM架构
TSMixer是TTM的前身。TSMixer是一个实体模型,但它不能用作基础模型或处理外部变量。
TTM使用TSMixer作为构建块,通过引入新特性作者创建了一个非transformer模型,可以泛化未见过的数据。
TTM的体系结构如下所示。我们将描述这两个阶段,预训练(左)和微调(右):
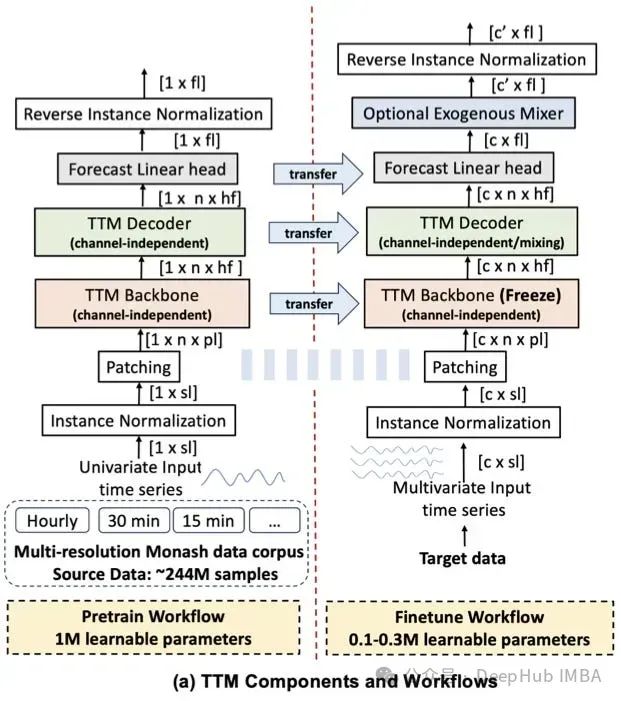
sl=context_size, fl=forecasting_length, c =通道数(输入特征),c ' =预测通道数。
如果我们有5个输入时间序列,但其中2个在未来是已知的(例如time_of_week, holiday),那么我们有c=5和c ' =5-2 = 3,因为它们两个是已知的,不需要估计。
1、Pretraining
在预训练过程中,模型只使用单变量时间序列进行训练。对每个时间序列进行归一化。最后的最终输出是反向规范化的。还使用了时间序列中广泛成功的分段技术。单变量序列被分成n个大小为pl的小块。TTM骨干模块采用自适应补丁,将大小从p到hf的补丁进行投影。TTM解码器具有与TTM主干相同的架构,但它要小得多,参数减少了80%。Forecast线性头部包含1个完全连接的层,并产生最终的预测(然后反向归一化)。最后MSE损失是在预测fl上计算的。
2、Fine-Tuning
TTM主干保持冻结状态,只更新TTM解码器和预测线性头部的权重。这样可以执行少样本预测(只训练5%的训练数据)或全样本预测(在整个数据集上)。在微调阶段使用多元数据集。在这种情况下,信道混合在TTM解码器中启用。模型在预训练期间以信道无关的方式学习时间动态,在微调期间学习时间序列之间的内部相关性。
TTM的核心组件是TTM骨干网,它支持分辨率前缀调优和自适应补丁。
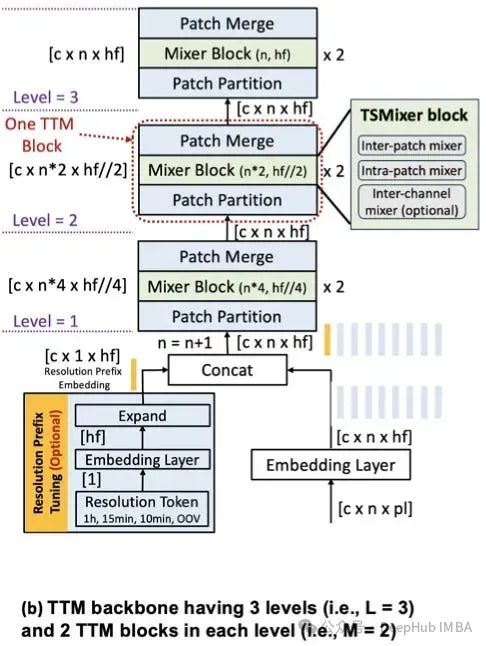
嵌入层将大小为pl的patch投影到大小为hf的输入嵌入中。Resolution Prefix Tuning模块创建大小为hf的嵌入,表示时间-频率/粒度,然后将其与输入嵌入连接(图中的n=n+1操作)。TTM块包含3个子模块:补丁分区模块、普通TSMixer块和补丁合并块。
补丁分区模块将补丁数量增加K个,补丁长度再减少K个。例如,在第一级中,大小为[c,n, hf]的输入变为[c, 4*n, hf//4]。
TSMixer块应用于变换后的输入,patch merge块将[c, 4*n, hf//4]输入重塑为[c,n, hf]。
通过在每个级别使用不同的K,通道混合应用于不同长度的不同补丁。这就是自适应补丁过程,它可以帮助模型对未见过的数据进行泛化。
外生混合器
如果我们有未来已知的变量,可以激活外生混合器。模块如下所示:
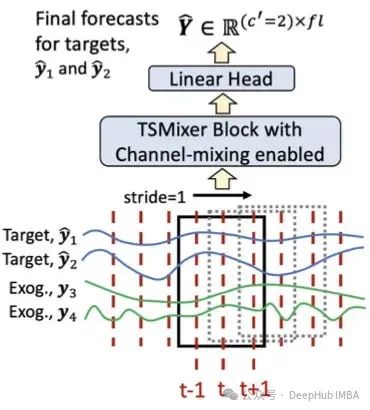
外生混合器块很简单,当时间序列的未来值已知时(上图中的y3和y4,绿色),它们被用来指导目标变量的预测(y1和y2墨蓝色)。
训练细节和数据集
作者为不同的上下文sl和预测长度fl创建了5个TTM版本。它们是(512,96),(512,192),(512,336),(512,720)和(96,24)。
对于任何上述预训练模型,都可以使用更短的预测长度
在训练方面,作者使用Monash存储库的一个子集(244k样本)对模型和Informer数据集进行预训练,以评估调优性能。作者使用另一个数据集来评估外生性混合器块的功效,并研究通过添加已知的未来变量,性能提高了多少。
下面是原始论文中(512,96)变体的训练超参数:
- pl(patch_length) = 64
- number of backbone levels = 6
- number of TTM blocks per level = 2
- batch_size = 3K
- epochs = 20
关于训练和微调配置的更多细节,原始论文中都有详细描述,但是这里我们能看到 这个3K的BS可能是一个关键。
基准评估
TTM和SOTA模型
作者将两种版本的TTM (Zero-shot和5% Few-shot)与其他SOTA模型(包括基础模型)进行了比较。评价指标为MSE。结果如表1所示:
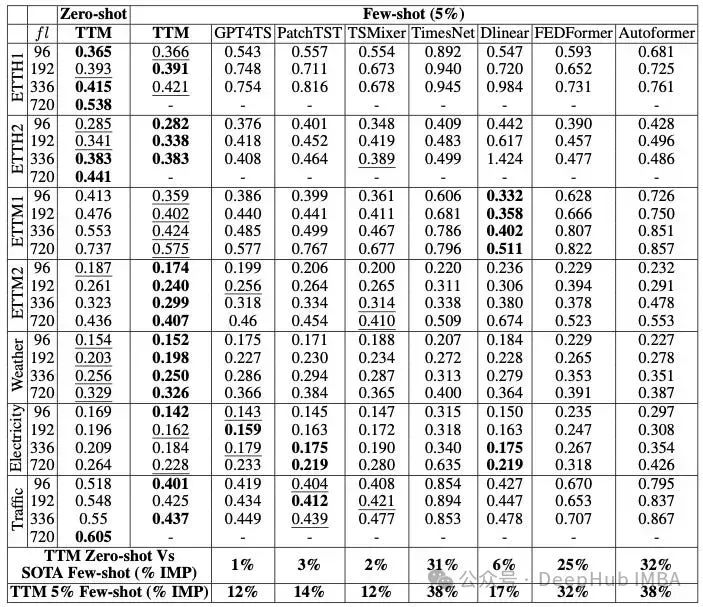
平均而言,Few-shot TTM超过了所有其他模型。即使是Zero-shot TTM也能够超越一些模型!别忘了Zero-shot TTM可是在没有经过这些数据训练的情况下产生预测。TTM也超过了去年推出的新的时间序列模型GPT4TS。
除了TTM之外,排名最高的型号是GPT4TS, PatchTST和TSMixer,这些模型都使用补丁技术,也就是说最近对时间序列预测的研究表明,补丁是一种非常有益的技术。
TTM与基础模型
LLMTime使用GPT-3和LLaMa-2,并为时间序列预测量身定制了特定的修改。GPT4TS是用于许多任务(预测、分类等)的通用时间序列模型,并使用GPT-2作为基本模型。
对比结果如表2 (LLMTime)和表3 (GPT4TS)所示:
将Zero-Shot TTM与LLMTime进行比较,显示比LLMTime平均提高29%
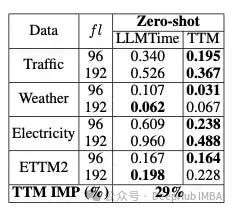
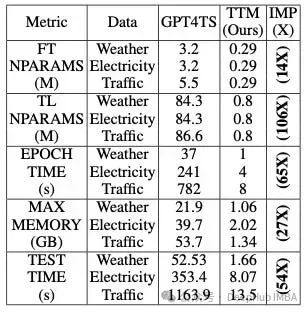
比较10%Few-Shot ,TTM与GPT4TS在MSE方面的差异。nx表示跨基准数据集的MSE平均改进(IMP)的n倍。
外生变量的有效性
现实世界的数据集尽可能地使用外生变量,因此在预测应用程序中利用它们是有意义的。
TTM的作者还研究了如何通过使用这些变量(如果适用)来改进TTM。他们比较了Zero-Shot TTM,普通TTM和使用外生变量的信道混合(TTM- cm)的TTM。他们还评估了TSMixer及其信道混合变体。
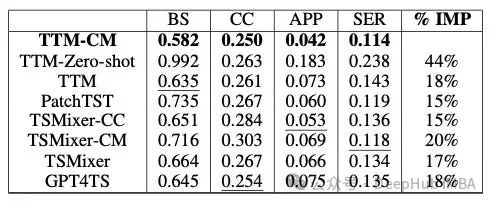
结果非常有趣:首先,TTM-CM排名第一,这意味着外生变量确实有助于模型。使用通道混合属性的TSMixer变体排在第二位。Zero-Shot TTM表现最差。也就是说当辅助变量存在时,应该使用它们来提高模型性能。
如何使用TTM
我们可以在HuggingFace上下载512-96和1024-96版本的模型权重,并进行如下微调:
!gitclonehttps://github.com/IBM/tsfm.git
!pipinstalltransformers
!pipinstalldatasets
importnumpyasnp
importpandasaspd
importmatplotlib.pyplotasplt
fromtsfm_public.models.tinytimemixer.utilsimport (
count_parameters,
plot_preds,
)
fromtsfm_public.models.tinytimemixerimportTinyTimeMixerForPrediction
fromtsfm_public.toolkit.callbacksimportTrackingCallback
zeroshot_model=TinyTimeMixerForPrediction.from_pretrained("ibm/TTM", revision='main')
finetune_forecast_model=TinyTimeMixerForPrediction.from_pretrained("ibm/TTM", revision='main', head_dropout=0.0,dropout=0.0,loss="mse")因此,我们可以使用transformers中熟悉的Trainer模块来微调TTM:
但是不要尝试在流行的公共数据集(如solar)上微调TTM ,因为TTM是在它们上进行预训练的。论文中有说TTM使用了哪些数据集进行预训练,所以请仔细阅读论文。因为是对私有数据集进行了微调,所以我们省略了一些部分,所以大致代码如下:
finetune_forecast_trainer=Trainer(
model=finetune_forecast_model,
args=finetune_forecast_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
callbacks=[early_stopping_callback, tracking_callback],
optimizers=(optimizer, scheduler))
# Fine tune
finetune_forecast_trainer.train()
然后进行预测:
predictions_test = finetune_forecast_trainer.predict(test_dataset)
总结
TTM是一个采用不同方法的新模型,为更小但更高效的模型铺平了道路。TTM证明了没有使用注意力仍然可以建立一个强大的TS基础模型。他继承了第一个只使用mlp的具有元学习能力的时间序列模型N-BEATS和N-HITS的优点。
最后,本文的基准测试不包含任何统计模型或基于树的模型,这些才是目前强有力的基线模型。但是作者在Github中提供了一个笔记本,展示了TTM在M4上优于统计集合(AutoARIMA, AutoETS, AutoCES, DynamicOptimizedTheta, Seasonal Naive)。
https://github.com/ibm-granit...
如果我没记错的话 M4的Top都是用的xgboost,所以大家也可以自行对比
引用
[1] Ekambaram et al., * Tiny Time Mixers (TTMs): Fast Pre-trained Models for Enhanced Zero/Few-Shot Forecasting of Multivariate Time Series
https://arxiv.org/pdf/2401.03955
[2] Ekambaram et al., *TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting
https://arxiv.org/pdf/2306.09364
https://avoid.overfit.cn/post/d7c8ea6e69e94a39930241a7c17059b7

