
与其他算法相比,高斯过程不那么流行,但是如果你只有少量的数据,那么可以首先高斯过程。在这篇文章中,我将详细介绍高斯过程。并可视化和Python实现来解释高斯过程的数学理论。

多元高斯分布
多元高斯分布是理解高斯过程所必须的概念之一。让我们快速回顾一下。如果你已经熟悉多元高斯分布,可以跳过这一部分。
多元高斯分布是具有两个以上维度的高斯分布的联合概率。多元高斯分布具有以下的概率密度函数。
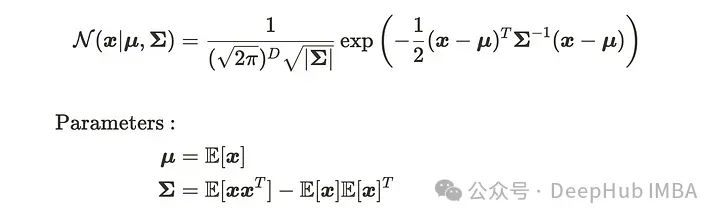
x 是具有 D × 1 维度的输入数据,μ 是具有与 x 相同维度的均值向量,Σ 是具有 D × D 维度的协方差矩阵。
多元高斯分布具有以下重要特性:
- 多元高斯分布的边缘分布仍然遵循高斯分布。
- 多元高斯分布的条件分布仍然遵循高斯分布。
让我们通过可视化来检验这些概念。假设 D 维数据遵循高斯分布。对于特性1,当我们将输入数据维度 D 分为前 L 维和其余的 D-L=M 维时,我们可以如下描述高斯分布。
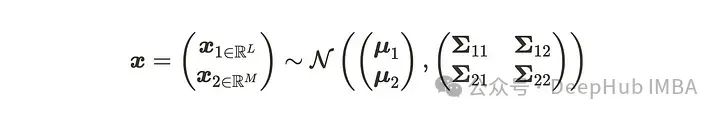
那么,当我们对x₁的分布进行边缘化时,x₁的概率分布可以写成:
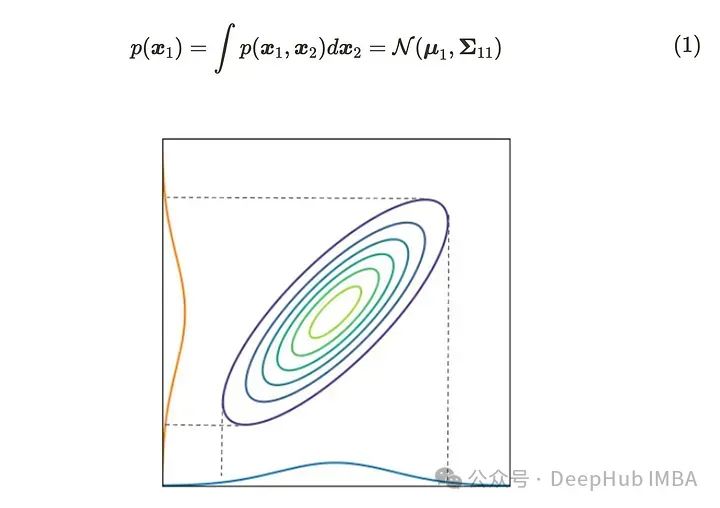
根据公式(1),在进行边缘化时,我们可以取消其他变量。上图表展示了二维高斯分布的情况。边缘化分布映射到每个轴上;其形式是高斯分布。当我们根据一个轴切割多元高斯分布时,截面的分布仍然遵循高斯分布。
对于特征 2,我们使用相同的 D 维多元高斯分布和两部分划分的输入数据 x₁ 和 x₂。多元高斯分布的条件概率可以写为:
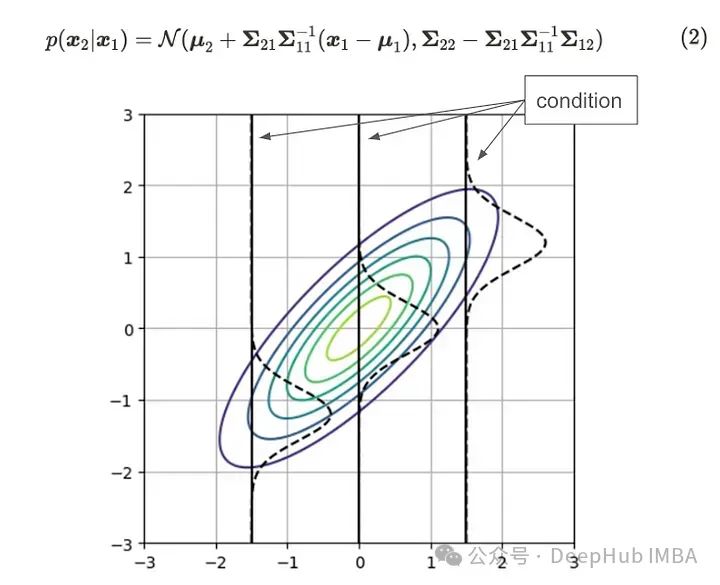
上图显示了二维高斯分布(等高线)和条件高斯分布(虚线)。在每种条件下,高斯分布的形状是不同的。
线性回归与维度诅咒
在深入研究高斯过程之前,首先需要说明线性回归模型的一个主要缺点。高斯过程与这一概念密切相关,并能克服这个缺点。
让我们回顾一下线性回归模型。线性回归模型可以使用基函数 𝝓(x) 灵活表达数据。
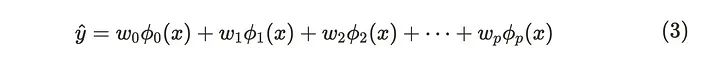
对于基函数,我们可以使用非线性函数,例如多项式项或余弦函数。因此通过将非线性基函数应用于 x,线性回归模型可以把握非线性关系。例如下入显示了使用径向基函数时的一个示例情况。
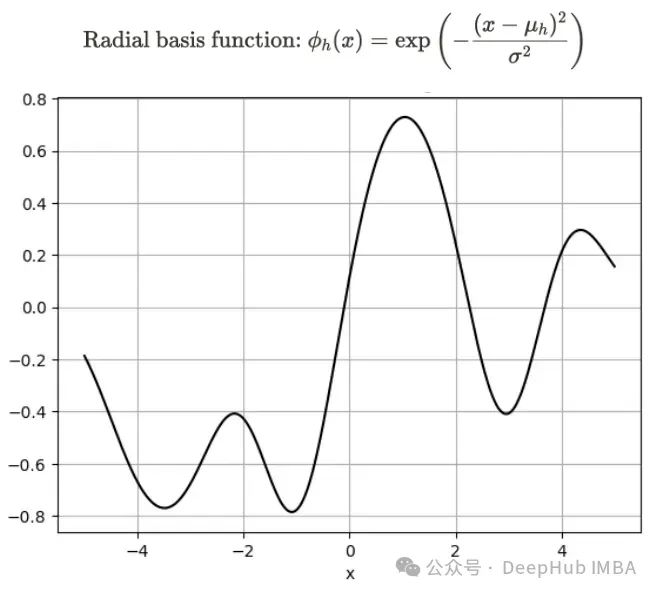
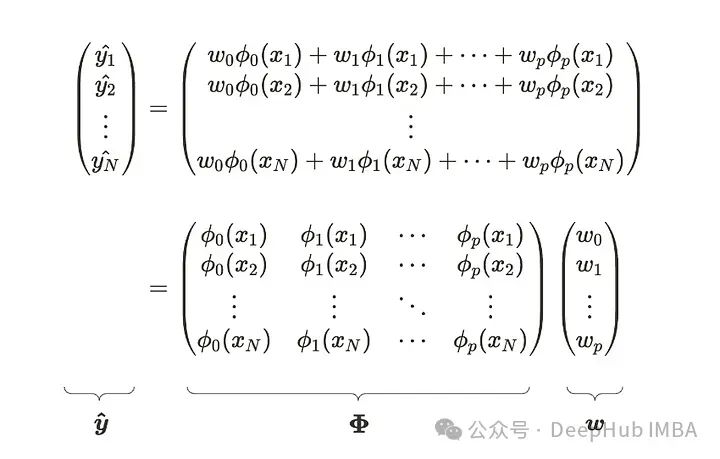
它能够把握复杂的数据结构。但我们仍然称之为线性回归模型,因为从参数 w 的角度看,这个方程仍然满足线性关系。我们也可以像多元线性回归一样推导参数。以下方程式是线性回归模型的矩阵和线性代数形式。我们假设有 N 个数据点和 p+1 个参数。
简化后
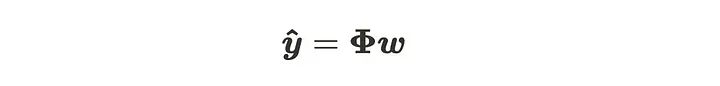
在将基函数应用于每个输入数据后,矩阵 𝚽 的值变成常数。这不是很像多元线性回归吗?实际上,参数的解析推导是相同的。
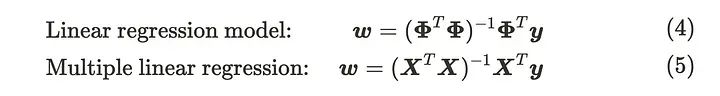
这里有一个陷阱,即线性回归模型在公式(4)中假设一个独立变量。因此当输入数据维度的数量增加时,参数的数量会呈指数级增长。如果我们增加基函数的数量,可以获得模型的灵活性,但计算量会不切实际地增加。这个问题被称为维度诅咒。有没有方法可以在不增加计算量的情况下提高模型的灵活性呢?可以应用高斯过程定理。下一节将介绍什么是高斯过程。
高斯过程的数学理论
上面已经看到,当参数数量增加时,线性回归模型存在维度诅咒问题。解决这个问题的方法是对参数进行期望处理,并创建一个不需要计算参数的情况。这是什么意思呢?继续上面的线性回归模型,公式如下。
现在我们假设参数 w 遵循高斯分布,输出 y 也将遵循高斯分布,因为矩阵 𝚽 只是一个常数值矩阵。我们假设参数遵循以下高斯分布:
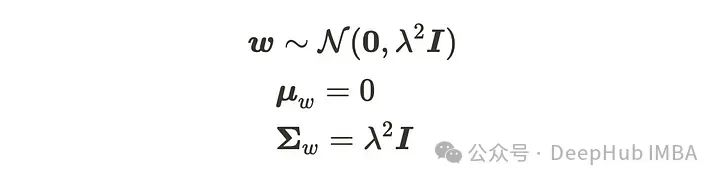
可以计算出输出分布的参数如下:

y的分布如下:
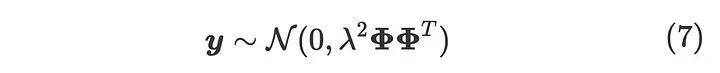
可以通过取其期望来取消参数的计算。因此即使有无限多的参数,它们也不会影响计算。x 和 y 之间的这种关系遵循高斯过程。高斯过程的定义是:

高斯过程是具有无限多参数的多元高斯分布。公式(7)指的是根据给定数据从高斯过程中得到的边缘高斯分布。它源于边缘元高斯分布仍然遵循高斯分布的特性。通过充分利用高斯过程,在考虑无限维度参数的同时构建模型。
这里还有一个问题,如何选择矩阵 𝚽?当关注上述公式中的协方差矩阵部分并将其设置为 K 时,每个元素可以写成:
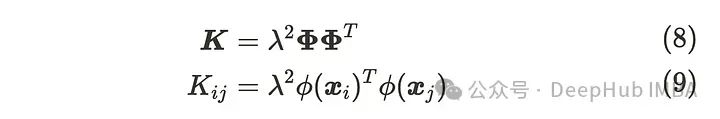
根据公式(9),协方差矩阵的每个元素都是 𝟇(xᵢ) 和 𝟇(xⱼ) 的内积的常数倍。由于内积类似于余弦相似性,当 xᵢ 和 xⱼ 相似时,公式(9)的值会变大。
为了满足协方差矩阵对称、正定且具有逆矩阵的特性,需要适当选择 𝟇(x)。为了实现这些特性,可以使用核函数来表示 𝟇(x)。
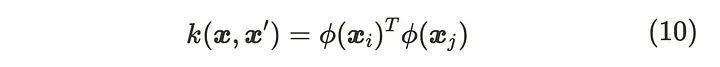
使用核函数的一个好处是,可以通过核函数获取 𝟇(x) 的内积,而无需显式计算 𝟇(x)。这种技术被称为核技巧。下面我们总结一些最常用的核函数:
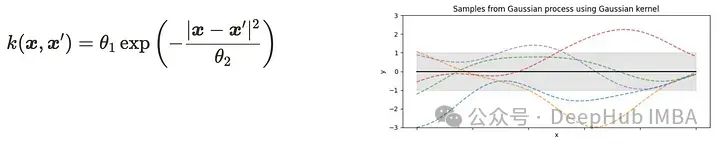
高斯核
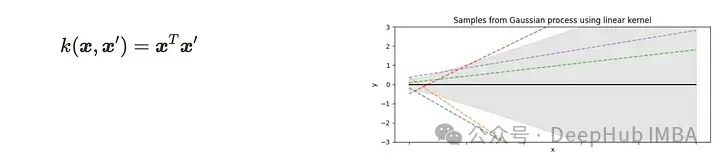
线性核
周期核(又称exp - sin平方核)
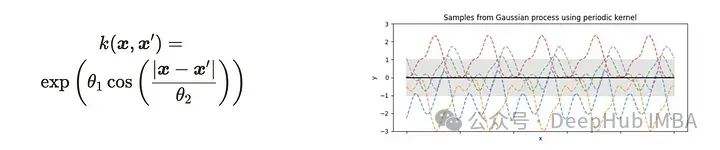
上面的可视化展示了使用每个核函数对一维高斯过程的采样。可以看到相应的核函数的特征。
最后让我们回顾一下高斯过程。使用核函数,可以重新写定义为:

高斯过程回归
最后我们将高斯过程应用于回归。
1、如何对高斯过程模型进行拟合和推理
假设有N个输入数据x和对应的输出数据y。
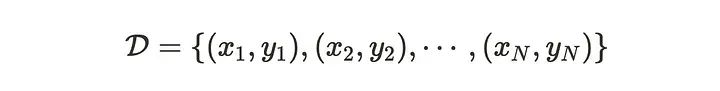
为简单起见我们对输入数据x应用归一化进行预处理,这意味着x的平均值为0。如果x和y的关系如下,f服从高斯过程。
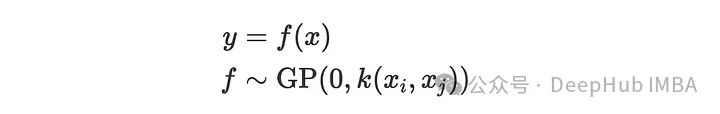
所以输出y遵循以下多元高斯分布。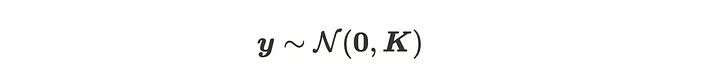
在拟合过程中,只需要通过核函数计算协方差矩阵,输出 y 分布的参数被确定为恰好为1。除了核函数的超参数外,高斯过程没有训练阶段。
在推理过程中,由于高斯过程没有像线性回归模型那样的权重参数,所以需要重新拟合(包括新数据)。但是可以利用多元高斯分布的特性来节省计算量。
设m个新数据点。
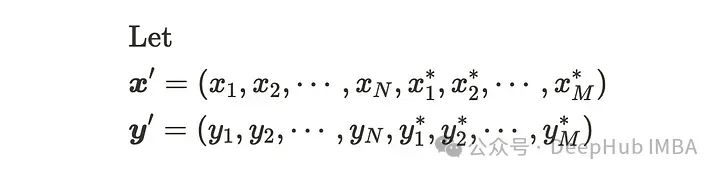
新数据点的分布也遵循高斯分布,因此我们可以将其描述为:
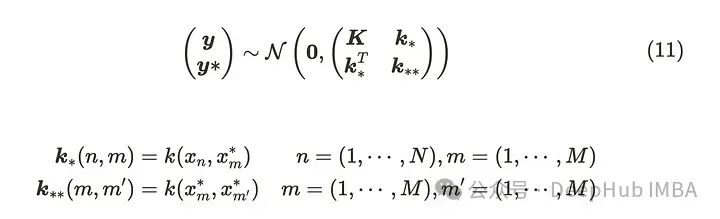
还记得最前面的公式(2),条件多元高斯分布的参数。
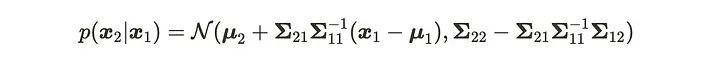
将此公式代入式(11),得到的参数为:
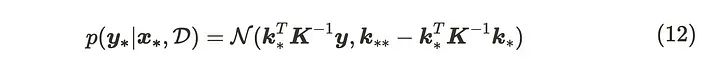
这是高斯过程回归模型的更新公式。当我们想要从中采样时,我们使用由Cholesky分解导出的下三角矩阵。

以上就是所有高斯过程的数学推导。但是在实际使用时不需要从头开始实现高斯过程回归,因为Python中已经有很好的库。
在将介绍如何使用Gpy库实现高斯过程。
2、高斯过程模型用于一维数据
我们将使用一个由带有高斯噪声的正弦函数生成的示例数据:
# Generate the randomized sample
X = np.linspace(start=0, stop=10, num=100).reshape(-1, 1)
y = np.squeeze(X * np.sin(X)) + np.random.randn(X.shape[0])
y = y.reshape(-1, 1)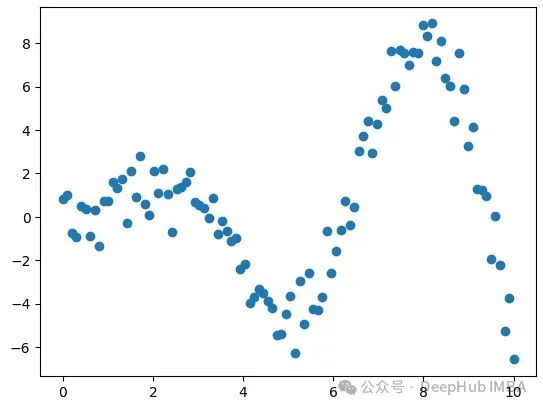
我们使用 RBF 核,因为它非常灵活且易于使用。我们使用GPy,只需几行代码就可以声明 RBF 核和高斯过程回归模型。
# RBF kernel
kernel = GPy.kern.RBF(input_dim=1, variance=1., lengthscale=1.)
# Gaussian process regression using RBF kernel
m = GPy.models.GPRegression(X, y, kernel)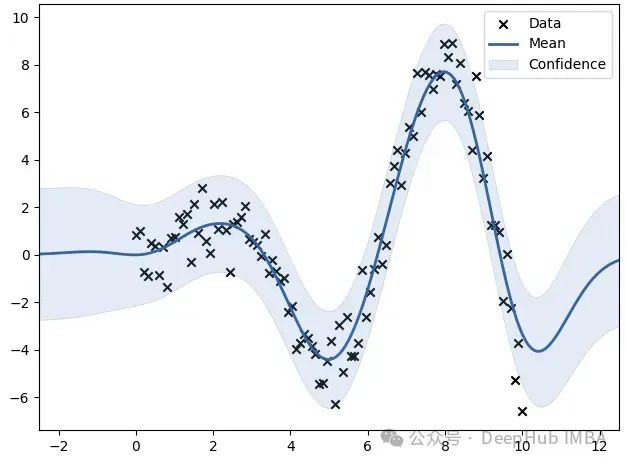
上面的x点是输入数据,蓝色曲线表示该点的高斯过程回归模型的预期值,浅蓝色阴影区域表示 95% 的置信区间。
数据点较多的区域具有较窄的置信区间,而数据点较少的区域则具有较宽的区间。
3、多维数据的高斯过程模型
我们将使用scikit-learn中的糖尿病数据集。
# Load the diabetes dataset and create a dataframe
diabetes = datasets.load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)这个数据集已经经过了预处理(归一化),所以可以直接实现高斯过程回归模型。
# dataset
X = df[['age', 'sex', 'bmi', 'bp']].values
y = df[['target']].values
# set kernel
kernel = GPy.kern.RBF(input_dim=4, variance=1.0, lengthscale=1.0, ARD = True)
# create GPR model
m = GPy.models.GPRegression(X, y, kernel = kernel)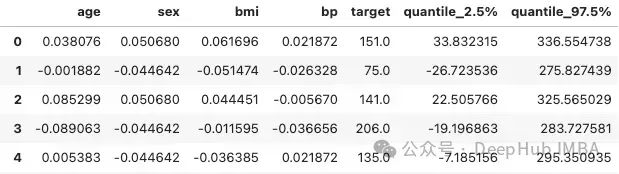
正如你所看到的,还有很大的改进空间。比如说更改内核的选择或超参数优化,或者收集更多的数据。
总结
本文讨论了高斯过程的数学理论和实际实现。当拥有少量数据时,这种技术是非常有帮助的。但是由于计算量取决于数据的数量,它不适合大数据。
https://avoid.overfit.cn/post/db2546da62d249fa9265f26e9f25bb87

