
本文继续深入探讨蒙特卡罗 (MC)方法。这些方法的特点是能够仅从经验中学习,不需要任何环境模型,这与动态规划(DP)方法形成对比。
这一特性极具吸引力 - 因为在实际应用中,环境模型往往是未知的,或者难以精确建模转移概率。以21点游戏为例:尽管我们完全理解游戏规则,但通过DP方法解决它将极为繁琐 - 因为需要计算各种条件概率,例如给定当前已发牌的情况下,"21点"出现的概率,再抽到一张7的概率等。而通过MC方法,可以绕过这些复杂计算,直接从游戏体验中学习。
由于不依赖模型,MC方法是无偏的。它们在概念上简单明了,易于理解,但表现出较高的方差,且不能采用迭代方式求解(即无法进行自举)。
本文结构如下:首先介绍MC方法和"预测"问题,接着我们讨论"控制"问题。将展示一个基于两个(不太实际的)假设的初始MC控制算法:我们将观察到无限多的情节,且每个状态-动作对将被访问无限多次(探索性启动)。
文章的后半部分将讨论如何移除这些假设:第一个假设相对容易处理,但后者需要更多考虑。我们首先介绍一种on-policy方法,其中最优策略保持ε-greedy,然后转向涉及重要性采样的off-policy方法。
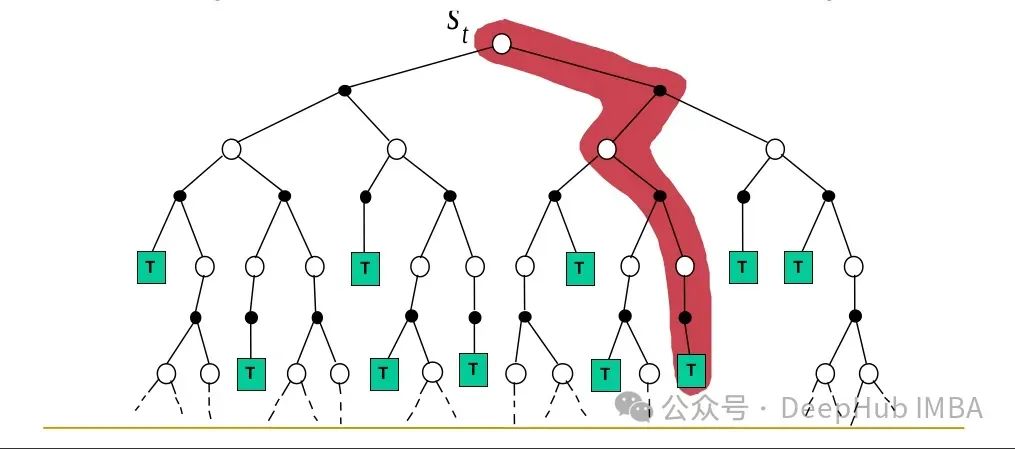
Monte Carlo预测
我们首先讨论预测问题 - 即估计给定策略的价值函数。MC方法的核心思想是采样情节,收集并平均跟随状态的回报来计算价值函数 - 在极限情况下,这将收敛到期望值。这一原理是所有MC方法的共同特征,也是这类方法名称的由来(因Monte Carlo地区赌博盛行而得名)。
我们可以定义两种略有不同的计算平均值的方法:首次访问MC方法和每次访问MC方法。在生成情节时,某个状态可能被多次访问。首次访问MC方法仅对第一次出现后的回报进行平均来估计状态的值,而每次访问MC方法对所有访问后的回报进行平均。这两种方法具有略微不同的理论特性,但本文我们将主要关注首次访问MC。其伪代码如下:

这种方法在当前情境下并非最优:在基于模型的方法中,当估计价值函数时,可以对任何状态探索所有可能的动作,然后选择导向最高价值状态的动作。在无模型的情况下,估计状态-动作对的值(即动作-价值函数)更为合适。这可以按照上面为价值函数所示的方式进行,但存在一个关键问题:很可能有些状态-动作对从未被访问过,没有结果可以平均,导致其价值估计无法改善。
这会涉及到探索-利用权衡的问题,以及如何持续保持探索。一个保证这一点的假设是在随机状态/动作组合中开始每个情节,并要求所有动作都有非零概率被选择。这被称为探索性启动假设。我们将在下一节MC控制中结合其实现。
Monte Carlo控制
与动态规划文章中一样,我们将使用广义策略迭代(GPI) - 策略评估和策略改进的迭代步骤。
这个过程本身在这里并无特别之处 - 除了我们必须做两个(不太实际的)假设才能使其工作:我们需要探索性启动的假设,并且要求策略评估的内部循环进行无限多步。
后一个假设可以相对容易地移除:允许提前终止策略评估循环是可以的,只需让策略的值更接近最优值而不必达到它 。
目前,我们将保留探索性启动假设,并展示一个基于此假设的控制算法 - 在文章的最后部分,我们将展示如何移除这个假设。
带有探索性启动的Monte Carlo控制
以下是带有探索性启动(ES)的MC控制的伪代码:

现在让我们将其转换为Python代码:
这里遇到的第一个挑战是如何保证ES假设:gymnasium [2]和一般的RL环境并不设计用于跳转到任意状态。我们初始化环境,然后从初始状态开始行动(例如,一个问题是历史信息:如果跳转到随机状态,如何生成可能需要的历史帧?)。
也许可以修改gymnasium,或实现允许生成随机状态的自定义环境,但这里实现一个函数来生成环境的几个可能状态,然后从这个列表中采样。
这个函数会被多次调用(对每个生成的情节),所以我们希望缓存这个计算成本高的生成过程。我在测试时发现functools.lrucache装饰器在确定gymnasium环境的相等性时存在问题,所以自己实现了一个自定义缓存装饰器,忽略第一个(环境)参数(另一个选择是重写环境的equals方法):
defcall_once(func):
"""自定义缓存装饰器
忽略第一个参数。
"""
cache= {}
defwrapper(*args, **kwargs):
key= (func.__name__, args[1:])
assertnotkwargs, "We don't support kwargs atm"
ifkeynotincache:
cache[key] =func(*args)
returncache[key]
returnwrapper
@call_once
defgenerate_possible_states(
env: ParametrizedEnv, num_runs: int=100
) ->list[tuple[int, ParametrizedEnv]]:
"""生成环境的可能状态。
为此,通过选择随机状态并从该状态开始
遵循随机策略,记录新状态,
迭代地增加已知状态集。
Args:
env: 使用的环境
num_runs: 发现循环的次数
Returns:
包含发现状态的列表 - 这些是状态(观察)
和表示该状态的gym环境的元组
"""
_, action_space=get_observation_action_space(env)
observation, _=env.env.reset()
possible_states= [(observation, copy.deepcopy(env))]
for_inrange(num_runs):
observation, env=random.choice(possible_states)
env=copy.deepcopy(env)
terminated=truncated=False
whilenotterminatedandnottruncated:
action=np.random.choice([aforainrange(action_space.n)])
observation, _, terminated, truncated, _=env.env.step(action)
ifobservationinset([stateforstate, _inpossible_states]):
break
else:
ifnotterminatedandnottruncated:
possible_states.append((observation, env))
returnpossible_states
defgenerate_random_start(env: ParametrizedEnv) ->tuple[int, ParametrizedEnv]:
"""选择一个随机起始状态。
为此,首先生成所有可能的状态(缓存),
然后从这些状态中随机选择一个。
"""
possible_states=generate_possible_states(env)
observation, env=random.choice(possible_states)
returncopy.deepcopy(observation), copy.deepcopy(env)这个
generate_possible_states函数迭代地构建一组可能的状态:它首先从已知状态中选择一个,然后遵循随机动作,同时记录所有新状态。
另外还实现了一个辅助函数来生成遵循特定策略的情节:
defgenerate_episode(
env: ParametrizedEnv,
pi: np.ndarray,
exploring_starts: bool,
max_episode_length: int=20,
) ->list[tuple[Any, Any, Any]]:
"""生成一个遵循给定策略的情节。
Args:
env: 使用的环境
pi: 要遵循的策略
exploring_starts: 当为True时遵循探索性启动假设(ES)
Returns:
生成的情节
"""
_, action_space=get_observation_action_space(env)
episode= []
observation, _=env.env.reset()
ifexploring_starts:
# 如果是ES,选择随机起始状态
observation, env=generate_random_start(env)
terminated=truncated=False
initial_step=True
whilenotterminatedandnottruncated:
ifinitial_stepandexploring_starts:
# 如果是ES,初始时选择随机动作
action=np.random.choice([aforainrange(action_space.n)])
else:
action=np.random.choice(
[aforainrange(action_space.n)], p=pi[observation]
)
initial_step=False
observation_new, reward, terminated, truncated, _=env.env.step(action)
episode.append((observation, action, reward))
# 终止智能体陷入死循环的情节
iflen(episode) >max_episode_length:
break
observation=observation_new
returnepisode当使用ES调用时,第一个动作选择是完全随机的 - 否则在每一步根据策略分布采样动作。提前终止"陷入死循环"的情节很重要:由于在MC方法中完整地执行情节并且只在之后更新策略,可能会发生策略陷入某个非理想动作导致循环访问序列的情况(例如,在左上角不断向左转 - 这个动作没有任何实际效果)。为了避免无限等待(或直到环境自行终止),我们需要在达到一定步数后主动中断。
有了这些辅助函数,就可以可以实现上面介绍的MC ES算法:
defmc_es(env: ParametrizedEnv) ->np.ndarray:
"""通过带有探索性启动的Monte Carlo方法
求解传入的Gymnasium环境。
Args:
env: 包含问题的环境
Returns:
找到的策略
"""
observation_space, action_space=get_observation_action_space(env)
pi= (
np.ones((observation_space.n, action_space.n)).astype(np.int32) /action_space.n
)
Q=np.zeros((observation_space.n, action_space.n))
returns=defaultdict(list)
num_steps=1000
fortinrange(num_steps):
episode=generate_episode(env, pi, True)
G=0.0
fortinrange(len(episode) -1, -1, -1):
s, a, r=episode[t]
G=env.gamma*G+r
prev_s= [(s, a) for (s, a, _) inepisode[:t]]
if (s, a) notinprev_s:
returns[s, a].append(G)
Q[s, a] =statistics.fmean(returns[s, a])
ifnotall(Q[s, a] ==Q[s, 0] forainrange(action_space.n)):
forainrange(action_space.n):
pi[s, a] =1ifa==np.argmax(Q[s]) else0
returnnp.argmax(pi, 1)从Python代码到上面的伪代码的映射应该相对直观 - 但需要做一个重要的补充,即在更新策略之前进行相等性检查:在生成情节时可能没有遇到非零奖励,所以策略更新最初会在缺乏信息的情况下最大化某个动作。
无探索性启动的Monte Carlo控制
上面我们已经看到了一个基于ES假设的初始MC控制方法。但这种方法在实际应用中存在局限性 - 因此在后面部分,我们将介绍两种不依赖这个假设的方法。
总的来说,为了使这些方法有效,必须确保所有状态-动作对都能被无限次探索(*),有两类方法可以帮助我们实现这一点:on-policy方法和off-policy方法。On-policy方法试图改进生成数据的策略,而off-policy方法可以改进目标策略,同时从不同的行为策略生成数据。
这里我们首先介绍一个on-policy方法,然后再介绍一个off-policy方法。到目前为止我们考虑的所有方法都是on-policy方法,因为只涉及一个策略 - 我们用它来生成数据,同时也直接优化它。为了在on-policy方法中满足条件(*),核心思想是保持策略"软性",而不是像我们在上面做的那样进行"硬性"更新。也就是说,当更新策略朝向最大
Q值的动作时,我们不会直接转向确定性策略,而是仅仅朝着这样一个确定性策略移动,同时保持
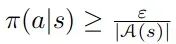
对于所有状态和动作成立。
除此之外,与上面介绍的MC ES算法没有太大区别,结构上的相似性应该很明显:

Python实现:
defon_policy_mc(env: ParametrizedEnv) ->np.ndarray:
"""通过on-policy Monte Carlo控制方法
求解传入的Gymnasium环境。
Args:
env: 包含问题的环境
Returns:
找到的策略
"""
observation_space, action_space=get_observation_action_space(env)
pi= (
np.ones((observation_space.n, action_space.n)).astype(np.int32) /action_space.n
)
Q=np.zeros((observation_space.n, action_space.n))
returns=defaultdict(list)
num_steps=1000
for_inrange(num_steps):
episode=generate_episode(env, pi, False)
G=0.0
fortinrange(len(episode) -1, -1, -1):
s, a, r=episode[t]
G=env.gamma*G+r
prev_s= [(s, a) for (s, a, _) inepisode[:t]]
if (s, a) notinprev_s:
returns[s, a].append(G)
Q[s, a] =statistics.fmean(returns[s, a])
ifnotall(Q[s, a] ==Q[s, 0] forainrange(action_space.n)):
A_star=np.argmax(Q[s, :])
forainrange(action_space.n):
pi[s, a] = (
1-env.eps+env.eps/action_space.n
ifa==A_star
elseenv.eps/action_space.n
)
returnnp.argmax(pi, 1)Off-Policy Monte Carlo控制
要介绍off-policy方法,我们需要更深入的讨论。这类方法的提出源于在on-policy方法中所做的折衷:希望学习一个最优策略,但同时还必须保持探索。到目前为止介绍的on-policy方法正是解决了这样一个折衷:它们学习一个近似最优的策略,该策略仍然保持一定程度的探索。使用两个策略似乎更为直观:优化一个目标策略,同时使用另一个策略来探索和生成数据。
正是由于这个原因,off-policy方法实际上更加通用和强大(一些最著名的RL算法,如Q-Learning,都是off-policy方法) - 但它们通常具有更高的方差,收敛速度也较慢。
大多数off-policy方法的共同特点是使用重要性采样:因为我们想计算目标策略的期望,但实际上是从不同的策略采样,所以直接计算的期望是有偏的。重要性采样通过适当地缩放观察到的值,使得得到的估计重新变得无偏。由于篇幅限制,这里不做更详细的介绍。
要将这应用于强化学习,我们再次从预测问题开始。首先看一下遵循策略π时状态-动作轨迹出现的概率:
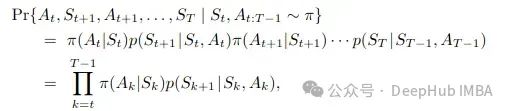
现在我们引入两个策略:π是我们的目标策略,即我们想要优化的策略,
b是我们的行为策略 - 用于生成数据的策略。我们需要满足覆盖性假设:如果在π下可能采取某个动作,那么在
b下该动作也必须有非零概率 - 这意味着
b需要在与π不同的状态下是一个随机策略。
接下来计算轨迹在π和
b下出现的概率比:
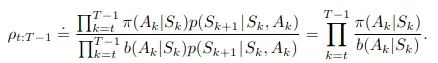
值得注意的是,环境本身的任何属性,如状态转移概率都被约掉了,只剩下策略比率。
所以需要这个比率来进行off-policy预测,因为我们想从
b收集的数据中估计策略π的值 - 这意味着直接计算的期望
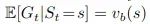
会是有偏的。但是,通过重要性采样可以修正这个偏差:
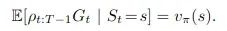
具体应用到RL预测问题得到: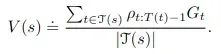
这个形式应该看起来很熟悉:一个状态的预测值只是(重要性采样修正的)平均回报(除以用于计算期望的状态数 - 这是典型的Monte Carlo期望估计)。
但对于我们的算法,实际上会使用加权重要性采样:
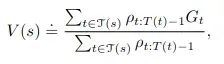
也就是说,它在分母中也包含了重要性采样权重,即计算加权平均值(注意分子和分母的权重通常不会相互抵消,因为它们出现在求和中)。
如果我们只观察到一个回报,加权重要性采样的权重会相互抵消。期望会是有偏的(它会得出
v_b),但这似乎是合理的,因为我们只观察到这一个样本。对于普通重要性采样,期望总是无偏的,但它可能会非常极端 - 例如,想象重要性采样权重是10或100。总的来说,加权重要性采样是有偏的(尽管随着样本数增加,偏差趋向于0),但比普通重要性采样具有更低的方差,后者可能具有无界(无限)方差。
回到off-policy MC预测,我们想要形成的估计是:
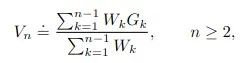
理论上,可以在每一步单独计算这个测量值 - 也就是保留一个权重和回报的列表并计算相应的值。
但是我们可以引入一种增量方法来节省内存。在这种方法中只需要存储先前的估计,并使用新值来更新它
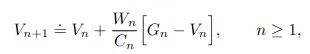
此外还需要保持对迄今为止累积权重的运行估计:
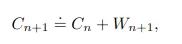
乍看之下,可能不太明显这些公式确实是加权重要性采样的增量版本。但它们是正确的。在这里省略了证明以保持文章的简洁,并且因为我认为它对理解核心概念并不是至关重要的。但是我们这里想象一个更简单的,非增量版本的这个算法可能有助于理解。
使用这个增量更新方案,MC off-policy预测算法如下:

转到off-policy MC控制算法:

我们看到完全相同的重要性采样更新模式,只是现在还更新了一个策略。注意上面的
W != 0检查现在被"break"替代,只要选择的动作不对应于π(这意味着
W = 0,因为π是确定性的)。出于同样的原因,更新规则也是
1/b(…)而不是
π(…)/b(…)。
这个算法可以直接翻译成Python代码:
defoff_policy_mc(env: ParametrizedEnv) ->np.ndarray:
"""通过off-policy Monte Carlo控制方法
求解传入的Gymnasium环境。
Args:
env: 包含问题的环境
Returns:
找到的策略
"""
observation_space, action_space=get_observation_action_space(env)
Q=np.zeros((observation_space.n, action_space.n))
C=np.zeros((observation_space.n, action_space.n))
pi=np.argmax(Q, 1)
num_steps=1000
for_inrange(num_steps):
b=np.random.rand(int(observation_space.n), int(action_space.n))
b=b/np.expand_dims(np.sum(b, axis=1), -1)
episode=generate_episode(env, b, False)
G=0.0
W=1
fortinrange(len(episode) -1, -1, -1):
s, a, r=episode[t]
G=env.gamma*G+r
C[s, a] +=W
Q[s, a] +=W/C[s, a] * (G-Q[s, a])
pi=np.argmax(Q, 1)
ifa!=np.argmax(Q[s]):
break
W*=1/b[s, a]
returnpi我们将展示一个增量算法的"更简单"和更直观的版本 - 将实现"纯"重要性采样,而不使用增量更新。这有助于理解,它清晰地展示了重要性采样是如何真正使用的,一步一步地形成所有需要的项:
defoff_policy_mc_non_inc(env: ParametrizedEnv) ->np.ndarray:
"""通过on-policy MonteCarlo控制方法求解传入的Gymnasium环境 -
但不使用Sutton的增量算法来更新重要性采样权重。
Args:
env: 包含问题的环境
Returns:
找到的策略
"""
observation_space, action_space=get_observation_action_space(env)
Q=np.zeros((observation_space.n, action_space.n))
num_steps=10000
returns=defaultdict(list)
ratios=defaultdict(list)
for_inrange(num_steps):
b=np.random.rand(int(observation_space.n), int(action_space.n))
b=b/np.expand_dims(np.sum(b, axis=1), -1)
episode=generate_episode(env, b, False)
G=0.0
ratio=1
fortinrange(len(episode) -1, -1, -1):
s, a, r=episode[t]
G=env.gamma*G+r
# 创建当前目标策略,
# 它是Q函数的argmax,
# 但对于Q值相等的情况给予相等的权重
pi=np.zeros_like(Q)
pi[np.arange(Q.shape[0]), np.argmax(Q, 1)] =1
uniform_rows=np.all(Q==Q[:, [0]], axis=1)
pi[uniform_rows] =1/action_space.n
ratio*=pi[s, a] /b[s, a]
ifratio==0:
break
returns[s, a].append(G)
ratios[s, a].append(ratio)
Q[s, a] =sum([r*sforr, sinzip(returns[s, a], ratios[s, a])]) /sum(
[sforsinratios[s, a]]
)
Q=np.nan_to_num(Q, nan=0.0)
returnnp.argmax(Q, 1)更深入地分析这个实现,的目标是收集并平均所有状态-动作对的回报 - 不同之处在于这里我们使用every-visit MC而不是first-visit MC(因此没有检查该对是否已经在情节中出现过)。因此通过生成情节并平均收集的回报来构建
Q函数 - 这里也不是简单地平均,而是使用(加权)重要性采样,所以需要计算的量是:
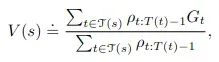
集合τ表示访问状态
s的所有时间步 - 对于first-visit MC,它只包括首次访问
s的所有时间步(使用状态-动作对)。忽略重要性采样权重,这个公式将得到与MC ES完全相同的结果 - 对于状态的每次出现,我们收集其相应的回报
G_t,并取平均值。现在,还需要重要性采样权重s来修正我们的有偏估计。这些权重是:
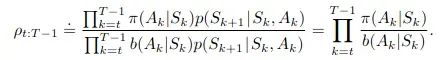
因此,除了跟踪每个访问的状态-动作对的回报之外,还用这个量填充ratios。为了生成它,当反向遍历一个情节时,我们迭代地计算
p_{T-1:T-1}、
p_{T-2:T-1}等,并将这个运行计算存储在
ratio中 - 在每一步都将其附加到ratios中。即时计算当前目标策略π以估计正确的权重 - 它只是从当前
Q获得的确定性策略。
这种方法是有效的(就像所有其他方法一样),但它需要大约10倍的情节数才能保证收敛,相比增量off-policy MC控制算法而言 - 这是非常奇怪的。我的理解是在这里只是实现了一个具有完全相同功能的非增量版本。所以这个额外的实现能更清楚地说明off-policy MC控制是如何工作的,但是并不能在实际应用中保证快速的运行。如果您有任何问题、评论或建议/解决方案 - 特别是关于为什么结果会有差异 - 请随时让我知道!
总结
MC方法的独特之处在于它们仅从经验中学习,不需要环境模型 - 这为解决复杂问题提供了令人兴奋的可能性。
我们首先介绍了一个基于探索性启动(ES)假设的MC控制算法 - 即每个状态-动作对都以非零概率被无限探索。之后,我们尝试移除ES假设 - 最后,我们还提供了一个非增量off-policy MC控制算法的实现 - 这可能有助于更深入地理解算法的工作原理,并展示了如何以直观的方式实现off-policy MC控制,而不需要任何优化技巧。
参考文献
[1] Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press. http://incompleteideas.net/bo... 注:公式都是从这里截图的
[2] Farama Foundation. (2022). Gymnasium: A Python Library for Reinforcement Learning Environments. https://github.com/Farama-Fou...
https://avoid.overfit.cn/post/400bebe168ab407e95c73580c331f6da

