
在大型语言模型(LLMs)相关的人工智能突破中,图神经网络(GNNs)与 LLMs 的融合已成为一个极具前景的研究方向。这两类模型的结合展现出显著的互补性,能够协同增强 LLMs 的推理能力和上下文理解能力。通过从知识图谱(KGs)存储的海量信息中进行智能化检索,该结合能够生成准确且不含幻觉的答案。
本文对面向知识图谱问答(Q&A)的 GNN-LLM 组合架构进行了多维度探索。研究重点关注了两种用于 LLM 检索增强生成(RAG)的 GNN 架构:He 等人提出的 G-Retriever,以及 Mavromatis 和 Karypis 提出的最新 GNN 检索增强生成(GNN-RAG)框架。后者采用 RAG 方式实现了基于 ReaRev GNN 架构的知识图谱问答。
我们首先运用 PyTorch Geometric 和 G-Retriever 构建 GNN-LLM 架构的探索性模型,从理论和实现两个维度建立对核心问题的基础认知。然后研究聚焦于最新提出的 GNN-RAG 架构,通过敏感性研究和架构改进,探索提升其知识图谱问答性能的方法。最后研究通过引入反思机制和教师网络的概念,对上述两种 GNN-LLM 架构的图推理能力进行了创新性扩展。这些概念基于 GNN 实现,并与近期语言模型研究中的思维链概念存在关联。本文主要聚焦于架构中 GNN 部分的优化与分析。
基线模型架构
在开始之前,我们首先简要概述 G-Retriever 和 ReaRev(GNN-RAG 模型的 GNN 组件)的原始架构,以此作为背景并引出本文的创新贡献。
G-Retriever

G-Retriever 是 He 等人开发的基于图的 LLM RAG 模型架构。该架构首先使用预训练语言模型对现有知识图谱的节点、边和子图进行嵌入表示。随后将这些嵌入向量索引并存储在数据结构中,以实现高效的近邻检索。此步骤被称为索引阶段。在检索阶段,系统使用相同的语言模型对问题 q 进行编码,并通过 k 近邻算法识别与该问题最相关的节点和边。在子图构建阶段,系统采用 PCST(Prize-Collecting Steiner Tree)优化算法进一步筛选这些选定的节点和边,构建与问题最相关的原始知识图谱的最优子图。
在最后的答案生成阶段,系统使用图神经网络(通常采用 Graph Attention Transformer)对构造的子图进行编码,得到子图的向量嵌入表示(即 GNN GAT 输出)。同时系统独立生成包含所有子图节点/边/文本及查询问题 q 的文本嵌入。最终系统将GNN GAT 输出的子图向量嵌入与文本嵌入组合,通过LLM 提示调优输入到Llama LLM中生成最终答案。
GNN-RAG
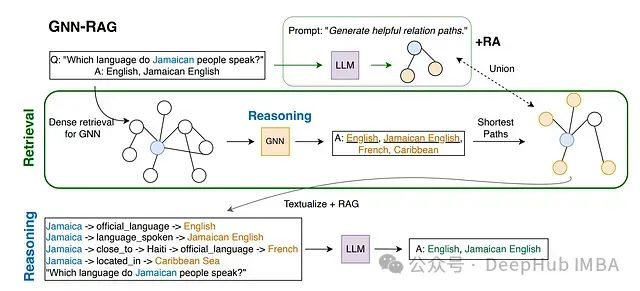
在原始 GNN-RAG 论文中,采用 ReaRev 模型作为架构的 GNN 组件。关于 ReaRev 架构的详细说明将在后续章节介绍。
ReaRev 模型的核心输入包含两个部分:(1)查询语句和(2)从大规模知识图谱中提取的与查询相关的子图。为实现输入的生成和预处理,ReaRev 整合了多种方法:采用 RelBERT 等预训练语言模型进行查询编码;应用 He 等(2021)的方法从大规模知识图谱中识别与目标查询相关的子图;对于 CWQ 数据集的查询(详细说明见后文),采用 Talmor 等(2018)的方法从子图中识别与查询相关的种子实体。基于这些信息,ReaRev 从子图中生成可能作为查询答案的候选实体集合。
系统使用现有的图处理算法(如 NetworkX 中实现的算法)从子图中提取种子查询实体到候选答案实体之间的最短路径。这些路径被转换为文本格式(如图左下角所示)并与经过优化的提示一起输入 LLM,该提示本质上要求 LLM 基于输入的推理路径生成查询答案。在图中所示的"+RA"(检索增强)可选步骤中,系统通过直接向 LLM 提交查询,并行生成额外的推理路径,以探索在不具备子图信息情况下 LLM 的推理结果。当启用 RA 时,系统将 GNN 生成的推理路径与 LLM 初步生成的推理路径合并,作为最终推理步骤的输入。
ReaRev
GNN 的核心计算过程可概括为三个主要步骤:
- 相邻节点间的消息传递
- 邻居消息的聚合运算
- 基于聚合后的邻居消息更新节点表示
ReaRev 通过引入针对深度知识图谱推理优化的注意力机制,增强了传统 GNN 结构(消息传递、聚合、层间组合/更新)的性能。
知识图谱(KG)通过事实三元组(v, r, v')进行编码,其中关系边 r 定义了两个节点实体 v 和 v'之间的关联。通常将 v'称为目标节点 v 的邻接节点。如前所述系统接收三个基本输入:(1)经预训练语言模型编码的问题 q,(2)与问题相关的子图,以及(3)子图中与问题相关的一个或多个种子问题实体。
ReaRev 的一个关键创新在于将初始问题表示为 K 个指令的集合,其中 K 为超参数(本文将对此进行深入探讨)。GNN 本身由 L 层组成(另一个超参数)。最后一个关键参数是自适应阶段数 T。本质上 ReaRev 将完整的 L 层 GNN 运行 T 次。在每个自适应阶段结束时,系统基于底层知识图谱的信息(特别是问题种子实体的嵌入)更新指令嵌入。这种设计的原因在于,仅基于问题的指令条件不足以生成必须从给定子图推导的准确答案。
在 GNN 的每一层中,消息传递、聚合和更新机制的具体实现如下:
- 对目标节点的每个邻接节点,系统为每条指令生成一条消息。特定于指令的消息是第 k 条指令、可学习参数以及连接节点 v 和 v'的关系嵌入的函数(详细说明见后文)。
- 这些消息通过加权和进行聚合,其中消息特定权重是上一层节点嵌入的可学习线性函数。
- 将所有指令的加权消息与目标节点上一层的嵌入进行拼接。
- 通过非线性函数处理拼接后的嵌入,得到更新后的目标节点嵌入。
在整个过程完成后,系统将子图的最终节点嵌入通过 softmax 函数处理,并基于预设的概率阈值识别相关实体作为候选答案。下图展示了原作者描述的 ReaRev 模型推理算法的伪代码。

性能评估指标
本文采用了多个知识图谱问答领域的标准评估指标来全面衡量模型性能。这些评估指标与 Mavromatis 和 Karypis 的研究保持一致。
Hit:表示真实答案是否出现在模型返回的答案集合中,用于评估模型的基本召回能力。
Hits@1(简写为H@1或H1):衡量模型预测置信度最高的答案的准确率,反映模型的精确预测能力。
精确率(Precision):量化模型正向预测的准确性,计算方式为正确预测为正的答案数量与预测为正的答案总数的比值。
召回率(Recall):也称为真阳性率,计算方式为正确预测为正的答案数量与实际正确答案总数的比值,反映模型发现正确答案的完整性。
F1 分数:精确率和召回率的调和平均值,提供了模型性能的综合评估指标。
第一部分:G-Retriever 探索性建模研究
为深入理解 GNN-LLM 架构,我们首先基于 PyTorch Geometric 开发了一个基于 G-Retriever 的基线 GNN-RAG 模型。在此框架下可以探索不同 GNN 编码器的性能表现(包括图注意力转换器(GAT)、GraphSAGE 和图同构网络(GIN)),采用 Tiny-Llama 作为 LLM 组件,并对网络层数进行了初步的敏感性分析。
数据集
第一部分采用 PyTorch Geometric 数据集模块提供的 WebQuestionsSP(WebQSP)数据集。WebQSP 是一个广泛应用于 KGQA 任务评估的标准数据集,源自 Freebase 知识图谱,包含需要最多 2 跳推理的简单问题。下表列举了本文中使用的 WebQSP 数据集的关键特征。

模型实现
下面的代码片段展示了 PyTorch Geometric 中 G-Retriever 模型的基本定义,包括 GNN 编码器的指定和 LLM 提示微调的配置。如前所述,研究在三种主流架构(GAT、GraphSAGE 和 GIN)之间进行了对比实验,并探索了不同的网络层数配置(2 层或 4 层)。
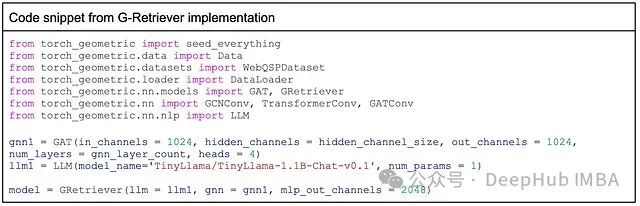
完整的实验代码会在最后给出。通过 Google Cloud Platform 的 Vertex AI Workbench 和 TensorDock 平台进行实验。在 A100 GPU 上,每个模型的训练时间约为 2-2.5 小时。为了完整加载训练数据集,需要将 GPU 内存从 24GB 升级至 80GB。
实验结果与分析
下表总结了 G-Retriever 模型的实验结果。所有模型配置均采用 WebQSP 数据集进行了 50 轮训练,批量大小设置为 4。
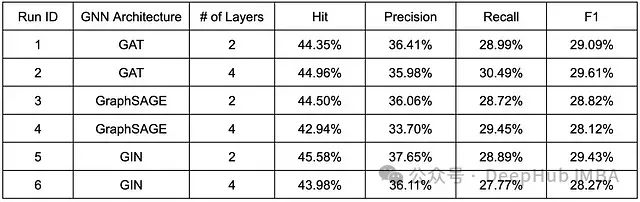
基于 G-Retriever 模型的实验结果(训练轮数:50 轮)
实验结果表明,在与 Tiny Llama 组合时,图同构网络(GIN)编码器在我们的 G-Retriever 框架中展现出最优性能。尽管这不是一个完整的敏感性研究,但实验数据揭示了层数增加对不同 GNN 架构的差异化影响:对于 GAT,从 2 层增加到 4 层导致 hit、recall 和 F1 指标的提升;对于 GraphSAGE,仅观察到 recall 的改善;而对于 GIN,未观察到显著改善。虽然"过度平滑"现象(将在第二部分详细讨论)是 GNN 中的普遍问题,但其影响程度因架构而异。
就整体性能而言,可以通过以下方式进一步优化上述结果:增加梯度下降过程中的批量大小,以及使用更强大的预训练 LLM(如 Google 的 Gemma 或标准的 7B 参数 Llama LLM)替代相对较小的 Tiny Llama(1B 参数)。
尽管 G-Retriever 是一个新发表的精细架构,但利用 PyG 的预置模型抽象了部分复杂性,这使我们能够专注于理解高层模型结构、超参数配置和标准数据集的应用。接下来,我们将深入探讨另一个最新发布的复杂架构 GNN-RAG,并在研究的后续部分对其性能进行更深入的分析。
第二部分:GNN-RAG 模型架构改进与敏感性研究
通过前期对 G-Retriever 的探索性研究,我们对 GNN-LLM 组合架构建立了基础认知。本文的第二阶段聚焦于 Mavromatis 和 Karypis 在 2024 年提出的 GNN-RAG 架构。GNN-RAG 在多个关键方面区别于 G-Retriever,包括 GNN 架构设计、相关子图生成方法,以及信息格式化和 LLM 输入策略。鉴于 GNN-RAG 方法声称具有优于 G-Retriever 的性能,本文选择深入探索其优化和扩展潜力。
数据集选择与处理
为便于与现有研究进行性能对比,我们采用了原始 GNN-RAG 论文作者预处理的 Complex Web Questions (CWQ)数据集。CWQ 数据集通过向 WebQSP 问题增加实体或向答案添加约束条件构建而成,包含需要最多 4 跳推理的复杂问题。该数据集提供了多样化的 KGQA 任务场景,适合用于模型性能的全面评估。本文的第二部分和第三部分均采用 CWQ 数据集进行实验。
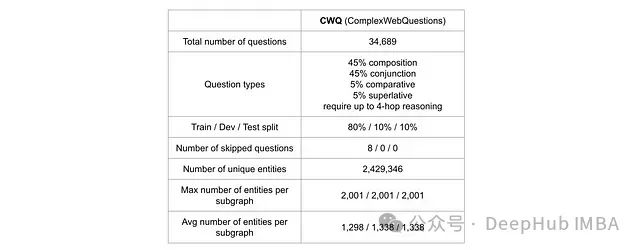
下图展示了经预处理的 CWQ 数据集样例。每个数据样本包含以下关键元素:唯一标识符、正确答案的标识符及完整文本、查询文本、知识图谱中对应查询的种子实体(图中橙色标注),以及由实体(节点)列表和关系(事实)元组列表描述的知识图谱子图。
数据集预处理主要包含两个核心步骤:
- 种子实体识别:针对每个查询,系统需要识别知识图谱中与查询相关的种子实体。这些种子实体在 GNN-RAG 框架中具有双重作用:一方面作为传递给 LLM 的推理路径的起点(终点为 GNN 生成的候选答案实体),另一方面在整个 GNN 架构中参与查询的嵌入表示(即指令)的更新过程。本文采用了 Talmor 和 Berant 的研究成果来获取种子实体。
- 子图构建:针对每个查询,系统需要从完整的 FreeBase 知识图谱中提取相关子图。本文遵循 He 等(2021)提出的方法,采用 Andersen 等(2006)的 PageRank-Nibble 算法,从知识图谱中选取与查询种子实体最相关的前 m 个实体。对于 CWQ 数据集,m 值设定为 2000。

预处理后的 CWQ 数据集示例。完整数据集可通过原始 GNN-RAG 作者的 GitHub 仓库获取。
基于现有架构的超参数优化研究
虽然 ReaRev GNN 模型的原作者在其发表的论文中提供了部分关键超参数的敏感性研究结果(主要基于 CWQ 以外的数据集),为了进一步扩展了这些研究,更全面地理解和探索原始架构的表达能力极限,为后续更深层次的架构改进奠定基础,我们研究设计了三类敏感性分析:
- GNN 层数(L)影响研究:增加 GNN 层数通常能提升模型的表达能力,但同时也会增加"过度平滑"的风险。本文重点探索 ReaRev 模型在 CWQ 数据集上的最优层数配置及其性能转折点。
- 自适应阶段数(T)影响研究:如前所述,在每个自适应阶段结束时,系统基于知识图谱信息更新查询指令的嵌入表示。原作者通过少量示例证明了较大的 T 值能提升模型性能。本文在 CWQ 数据集上系统性地验证和扩展了这一发现。
- 指令数量(K)影响研究:ReaRev 的一个创新点是将查询的嵌入表示(指令)数量 K 与 GNN 层数 L 解耦。理论上,更多的指令能够使 GNN 捕获查询信息的更多维度。本文对这一假设进行了实证分析。
ReaRev 架构改进研究
经过对 ReaRev 模型架构的深入分析,我们可以使用多项架构改进方案并检验了它们对模型性能的影响。本节详细阐述各项改进的理论基础和技术实现,相关性能分析将在后续"结果"部分展开讨论。
实验 1A:层级指令更新机制
根据对原始 ReaRev 架构的分析,将输入查询表示为 K 个指令嵌入的集合是决定模型性能的关键因素之一。在 ReaRev 框架中,自适应阶段的核心功能是迭代更新指令嵌入,使其能够反映用于答案推导的底层知识图谱信息。每个自适应阶段都需要将知识图谱通过完整的 GNN 模型(所有层)进行处理。因此如原作者指出,ReaRev 的计算复杂度与自适应阶段数 T 呈正比。原始研究表明 T=2 已能达到较好的效果。
基于这一观察,可以提出一个创新性假设:通过在每个 GNN 层之后(而非每个自适应阶段之后)更新指令嵌入,可能使较小的自适应阶段数(如 T=1,即单次 GNN 遍历)在性能上具有可行性。实验 1A 通过设置 T=1 并修改 ReaRev 代码实现了这一设想,具体实现如下所示:

实验 1B:指令更新的跳跃连接
对原始 ReaRev 架构中的指令更新机制提出了另一项改进。在原始架构中,更新后的指令是可学习参数和问题种子实体嵌入的函数,同时结合门控循环单元计算的输出门向量:
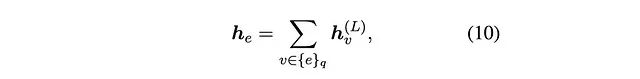
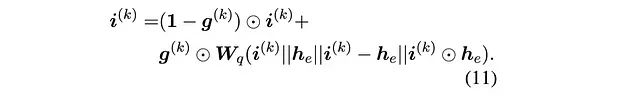
其中:
- i⁽ᵏ⁾ 表示第 k 个指令嵌入
- g⁽ᵏ⁾ 表示第 k 个指令的输出门向量
- W\_q 表示可学习参数张量
- h\_ᵥ⁽ᴸ⁾ 表示第 L 层末端的问题种子嵌入
实验 1B 提出引入跳跃连接机制来改进指令表示的更新方案。这一改进借鉴了 GNN 领域的经典思想:跳跃连接常用于缓解深层网络中的节点表示"过度平滑"问题,其核心思想是保留早期层的表示信息,因为这些信息可能包含在后续层处理中丢失的重要特征。将这一思想应用于自适应阶段间的指令嵌入更新过程。通过在指令更新中添加跳跃连接,系统可以保持早期阶段指令表示中的关键信息。具体实现如下,本质上是对前一阶段指令和新阶段指令进行加权平均:

实验 2A:增强型消息传递机制
实验 2A 和 2B 聚焦于改进 ReaRev 架构的消息传递机制。在原始模型中,从邻接节点 v'到目标节点 v 在 GNN 第 l 层对第 k 条指令的消息传递函数定义如下:
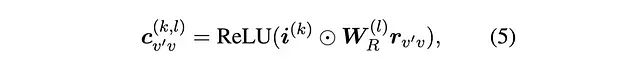
通过对整体架构的分析,可以认为在消息函数中纳入更多邻接节点信息可能是有益的。例如,目标节点可能与多个邻接节点通过相同类型的关系连接,此时邻接节点本身的嵌入信息对于消息传递可能具有重要价值。基于此,本文提出了如下改进的消息函数:
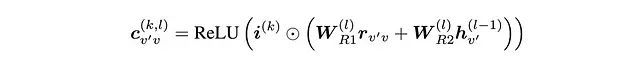
其中:
- h*ᵥ,⁽ˡ⁻¹⁾ 表示邻接节点 v'在 l-1 层的嵌入(维度与r*ᵥ,ᵥ 相同)
- 引入了两个可学习的线性投影矩阵
具体实现代码如下:

实验 2B:注意力增强的消息函数
基于实验 2A 的结果分析,还可以进一步提出了一个具有更强表达能力的消息函数改进方案:
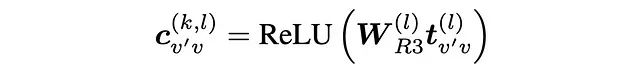
其中:
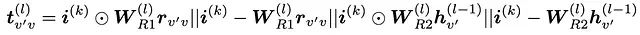
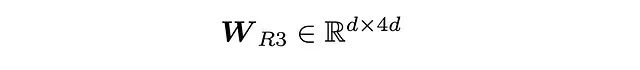
这里的||运算符表示垂直拼接操作,这一点从W\_R3 线性投影张量的维度设计中可以明确看出。这一改进的核心思想是为指令嵌入i⁽ᵏ⁾与关系嵌入和邻接节点嵌入的交互提供多样化的注意力计算方式,从而增强模型的表达能力。该设计部分受到了原始模型架构中其他融合/注意力计算(如实验 1B 中的等式(11))的启发。具体实现代码如下:

实验结果与分析
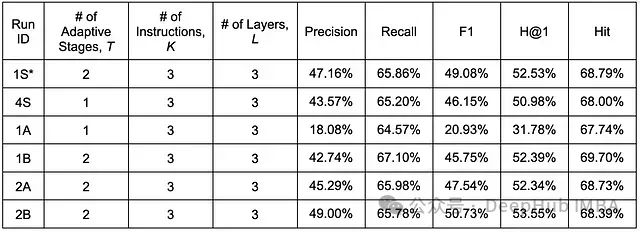
对所有模型配置均进行了 100 轮训练,在保持其他关键超参数不变的情况下,对敏感性研究和架构改进进行了系统性评估。表中以"S"结尾的实验标识表示敏感性研究,1A 至 2B 对应前述的架构改进实验。值得注意的是,实验 1S 来自原始 GNN-RAG 论文,作为本文的基准配置。(补充说明:本文第二部分的所有实验均采用 RelBERT 作为预训练语言模型来生成查询和关系相关的嵌入表示,而原作者使用 SBERT。RelBERT 因采用了更大的嵌入维度,在性能上略有优势。)
在第二部分进行的实验中,如下表所示,实验 1B 和 2B 在五个评估指标上均达到了最优表现。下文将对实验结果进行详细分析和讨论。
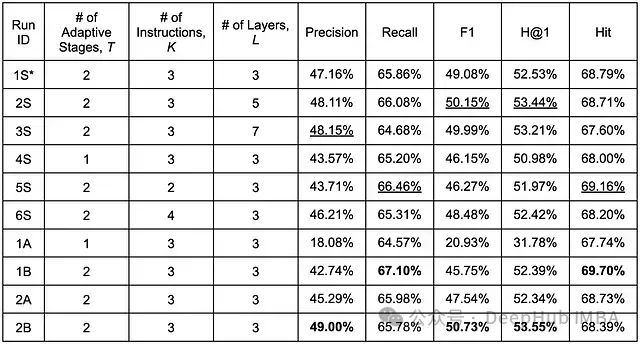
ReaRev 架构敏感性研究和改进实验的性能评估结果(训练轮数:100)。表中加粗值表示各指标的最优性能,下划线值表示次优性能。*注:S1 为原始 GNN-RAG 作者工作的基准配置。
实验结果详细分析
GNN 层数对模型性能的影响
下表和图表展示了 GNN 层数敏感性研究的详细结果。
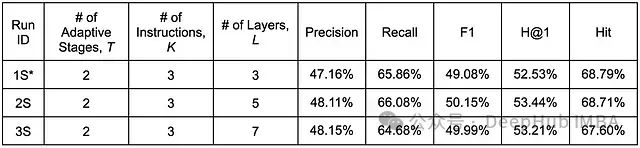
实验结果表明,更深的 GNN 架构具有更强的表达能力,这使得具有更多推理层的模型能够更快地定位相关实体并实现训练收敛。从整体性能指标(精确率、召回率、F1、H@1)来看,将 GNN 层数从 3 增加到 5 确实带来了性能提升。然而当层数从 5 增加到 7 时,观察到了"过度平滑"效应的影响,导致性能略有下降。这种现象在 GNN 研究中已有广泛认知:过深的 GNN 可能导致所有嵌入趋于相似,从而降低模型的表达能力和实用性。尽管原作者的设计中已经集成了减少过度平滑的技术手段,但在超过 5 层后,这种机制的效果似乎变得有限。
此外,计算成本也是一个重要的考虑因素。在 RTX 3090 显卡上进行实验时,将层数从 5 增加到 7 导致运行时间从 27 小时延长到 33 小时(约 20%的增加)。考虑到性能提升的边际效应,可能存在更高效的方法来实现同等程度的性能改进。

不同层数配置下的训练损失、F1 和 H1(H@1)指标演化曲线
自适应阶段数的影响分析
考虑到增加自适应阶段数所带来的显著计算开销,本文主要探索了减少自适应阶段数的可行性(这也为实验 1A 提供了有效的比较基准),结果如下表所示。

实验数据显示,当自适应阶段数从 2 减少到 1 时,模型性能出现了预期中的下降,这验证了原作者关于更新指令嵌入以反映底层知识图谱信息对提升答案质量的重要性的论述。特别值得注意的是,精确率的下降幅度明显大于召回率。这一现象从反面说明,增加自适应阶段数最显著的改进效果体现在提高模型的精确率和降低假阳性预测方面。然而,仅通过增加自适应阶段数似乎难以显著改善假阴性预测的问题。这一发现将在后续讨论实验 1A 时进行更深入的分析。
指令数量的影响研究
对原始 GNN-RAG 实现中指定的指令数量进行增减实验,结果如下表所示。
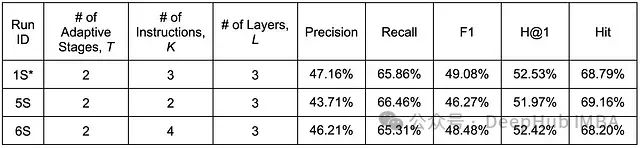
查询指令数量变化的敏感性研究结果汇总
根据实验数据,可以得出以下关键发现:
- 精确率、F1 和 H@1 指标在 K=3 时达到最优值,无论增加还是减少指令数量都会导致这些指标的下降。
- 召回率和命中率在 K=2(实验中尝试的最小指令数)时达到最优值,并随着指令数量的增加而降低。
这些结果揭示了指令数量对模型性能的多维度影响。根据现有数据,较少的指令数量有利于提高召回率,而精确率则随着指令数量的增加而提升,但这种提升存在上限。为深入理解这一现象,按问题类型(基于问题实体到真实答案实体的最短路径跳数)对性能进行了细分分析。下表分别展示了三组敏感性研究的精确率和召回率在不同问题类型上的表现。
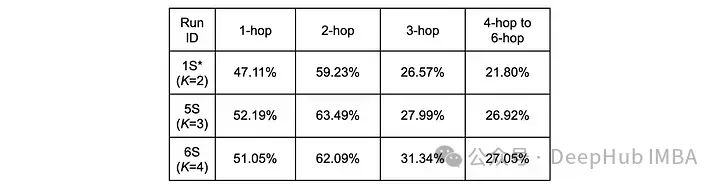
不同问题类型的精确率分析结果
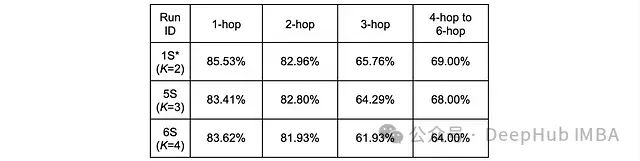
不同问题类型的召回率分析结果
在精确率方面,1 跳和 2 跳问题在 K=3 时表现最佳,而 3 跳及以上问题在 K=4 时达到最优。这表明,对于需要在知识图谱中遍历更长路径的查询,增加指令数量能带来更显著的益处。相比之下,召回率分析显示,对于所有跳数长度的问题,K=2 配置均能获得最佳性能。这一发现揭示了指令数量选择时需要权衡精确率和召回率的关系。研究表明,较大的指令数量主要有助于提高长路径查询的答案精确率。
架构改进实验的详细分析
为全面评估架构改进的效果,将实验 1A 和 1B(针对指令更新方案的改进)以及实验 2A 和 2B(针对消息传递方案的改进)的结果与关键敏感性研究进行对比分析,详细结果如下表所示:
指令更新机制的改进效果分析
实验 1A 与基准模型的对比
通过比较实验 4S(T=1 的敏感性研究)和实验 1A 的结果,可以发现实验 1A 导致了模型整体性能的下降,且在精确率相关指标上的下降幅度明显大于召回率相关指标。这一现象可能源于以下两个方面的原因:
- 在每个 GNN 层后更新指令查询可能导致指令中包含的信息出现混淆。
- 三层 GNN 结构可能不足以同时完成指令嵌入和节点嵌入的优化。
推测的原因可能是:通过额外的架构改进可能提升实验 1A 的性能,例如在每次更新时为指令添加跳跃连接(即结合 1A 和 1B 的设计理念)。然而,这种改进可能仍难以超越本文中其他模型配置的性能表现。
实验 1B 的性能分析
实验 1B 最适合与基准实验 1S 进行对比,因为两者采用了相同的超参数配置。实验结果显示,1B 相对于 1S 在召回率和命中率上实现了超过 1%的提升,但同时导致精确率和 F1 分数出现明显下降,而 H@1 指标仅有轻微降低。这表明在指令更新方案中引入跳跃连接确实能够保留有助于提高召回率的关键信息。尽管这种改进会导致精确率的一定损失,但对 H@1 指标的影响相对有限。这一发现启示我们,如果能将指令嵌入跳跃连接与其他提升精确率的改进措施相结合,可能为基准模型架构带来更全面的性能提升。
消息传递机制的改进效果分析
实验 2A 的性能评估
通过比较实验 2A 和基准实验 1S 的结果,可以观察到:在消息函数中直接引入邻居嵌入信息的初步尝试导致精确率和 F1 分数下降,仅在召回率上实现轻微改善,同时 H@1 和命中率出现小幅下降。这一结果表明,虽然邻居嵌入中确实包含有价值的信息可供消息函数利用,但实验 2A 中采用的具体实现方式可能不是最优的。
实验 2B 的突破性进展
基于实验 2A 的结果分析,实验 2B 重新设计了消息函数,旨在为指令嵌入与关系和邻居节点嵌入的交互提供更多样化的注意力计算方式。这一设计允许模型通过可学习的权重参数更灵活地选择和强调关系与邻居嵌入中的关键信息。实验结果有力地支持了这一设计理念:相比基准模型,精确率、F1 分数和 H@1 指标均提升了 1-1.5%以上,仅在召回率和命中率上出现轻微下降。
研究结论与未来展望
通过对 ReaRev GNN 模型架构(GNN-RAG 架构的核心组件)的深入研究,探索了模型的行为特征并提出了多项有效的改进方案。研究工作主要包括:
- 通过敏感性研究深入分析了 GNN 层数、自适应阶段数和指令数量这三个关键超参数对模型性能的影响
- 揭示了增加 GNN 层数导致的过度平滑现象及其对不同类型问题的差异化影响
- 提出并实现了四项架构改进方案,分别针对指令更新方案和消息传递方案进行优化
特别值得注意的是,实验 1B(指令跳跃连接)和实验 2B(增强型消息传递)分别在召回率和精确率方面取得了最佳表现,这为未来的研究指明了方向。
基于本文的发现,可以提出以下几个有价值的未来研究方向:
- 集成优势互补的改进方案:考虑到实验 1B 和 2B 在精确率和召回率方面的互补优势,研究它们的组合实现可能带来更优的综合性能。
- 深化层级指令更新研究:进一步探索更频繁的指令更新机制(如每层更新),同时结合跳跃连接等其他架构改进措施。
- 验证极小指令数配置:执行 K=1 的实验,以确认是否能够超越 K=2 配置的召回率表现。
- 探索多配置融合方案:研究如何结合不同 K 值配置的优势,以提升模型在各类问题类型和跳长度上的整体表现。
- 优化计算效率:探索提升模型计算效率和降低复杂度的方案。
- 架构整合评估:将改进后的 ReaRev GNN 重新整合到 GNN-RAG 架构中,评估对 LLM 性能的影响。
- 数据质量提升:尽管 CWQ 是广泛使用的标准数据集,但我们发现其测试样本中存在一小部分异常失败案例。虽然为保持与原始论文的可比性,本文未对数据进行清洗,但提升数据质量对未来研究的稳健性具有重要价值。
第三部分:GNN-RAG 架构的创新性扩展
本文的第三部分探索了通过反思机制和教师网络两种创新性概念来扩展 GNN-RAG 架构的可能性。这两种方法都旨在提升模型的推理能力和答案质量。
原始 GNN-RAG 模型在知识图谱中主要依赖问题和答案之间的单一最短路径进行推理。为增强这一基本假设,可以提出了三种可能的改进方向:
- 路径排序机制:为潜在的推理路径建立排序体系
- 多路径聚合策略:开发针对多个推理路径结果的聚合方法(可能采用注意力机制或池化方案)
- 反向推理增强:在 GNN 训练和推理过程中利用反向推理路径的信息(参考 He 等人 2021 的研究思路)
本文重点探索了第三种方案,并提出了一种创新性的"反思"或"反事实"推理机制,该机制可以在预训练模型上直接应用,无需额外的训练过程。如图所示,当系统确认某个答案错误时(例如在生产环境中通过用户反馈),该机制能够基于 GNN 的原始推理路径,指导模型从错误答案节点开始反向探索,在某个前序步骤启动束搜索,或利用原始答案路径的补集(即负采样)进行推理,这一过程仍然使用预训练模型完成。
值得注意的是,在本文的实验设置中,使用的是预处理数据集,其中每个正确答案都确保存在于传递给 GNN 的子图中。未来研究可以将这一机制扩展到开放集问题场景(即 GNN 需要在推理答案之前选择合适的子图),可能的方向包括通过比较不同采样子图中节点/实体嵌入的相似性来指导多重图上的遍历策略。
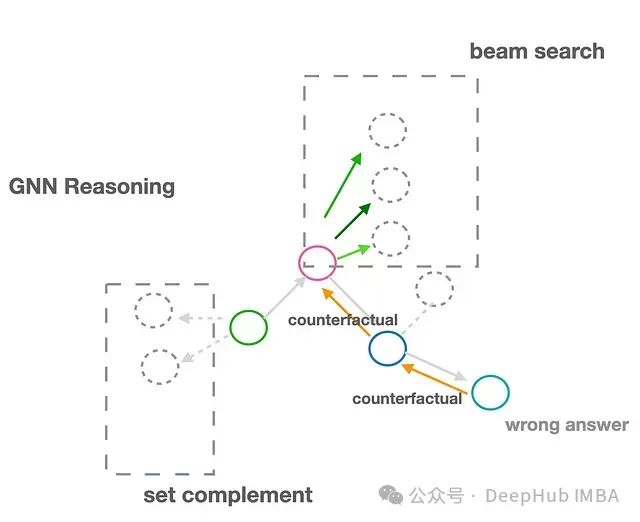
反思机制的实验实现
失败案例分析
为了有针对性地提升模型性能,首先对失败案例进行了系统性分析。重点考察了在不同 GNN 层配置下,错误候选答案到正确答案的(跳)距离分布。采用 networkX 库中的最短路径算法(类似 BFS 搜索)来计算这一距离指标。表中展示了跳距离的详细分布情况。实验数据显示,相比 L=3 和 L=5 的配置,L=7 的 GNN 模型生成的错误候选答案与正确答案之间的平均跳数更小。这一现象可以解释为:更深的 GNN 结构能够获取更远距离的节点信息,从而在推理过程中更接近正确答案。
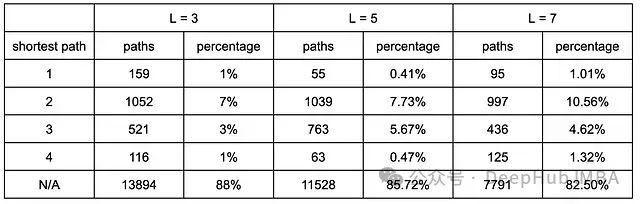
不同 GNN 层数配置下错误候选答案与正确答案间跳距离的对比分析
图结构上的反思实现
基于前述分析,我们针对 3、5 和 7 三种不同的 GNN 层数配置进行了实验,目标是在较小的(跳)距离范围内定位正确答案。考虑到大多数有价值的失败案例与正确答案之间仅相距几跳,采用了以下创新性方法:重用预训练 GNN 架构,保持查询文本不变,但将问题实体替换为当前错误候选答案的全局实体 ID。实验结果如表所示。
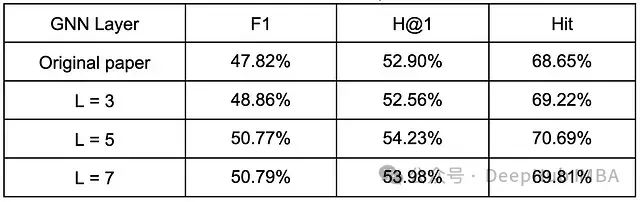
数据显示,3 层 GNN 配置在此项改进中获得了最显著的性能提升,提升幅度达 52%。为简化实验复杂度,在每个案例中仅选择一个与正确答案具有最短跳距离的错误候选答案进行分析。实验结果的合理性可以从以下角度理解:3 层 GNN 从第二次"反思"调用中获得最大收益,这是因为仅有 3 层的 GNN 结构无法像更深层的网络那样获取远距离的跳跃信息(3 层结构最多获取 3 跳信息),而 L=7 的配置本身就具备较强的远距离信息获取能力。这一解释与表中结果分布的趋势相符。

下表总结了引入反思机制后模型的整体性能表现。实验表明,L=5 的 GNN 配置达到了最优性能,这种结果可以类比于传统 BFS 和 DFS 算法的平衡点。这一发现也与第二部分中关于层数的敏感性研究所揭示的"过度平滑"效应相呼应。与原始论文的结果(使用作者发布的默认设置和 SBERT 重新运行)相比,本文提出的反思机制在 F1、H@1 和 Hit 三个指标上分别实现了 2.95%、1.33%和 2.04%的性能提升。
反思机制的潜在优化方向
基于当前研究成果,我们识别出两个可能的优化方向,有望进一步提升反思机制带来的性能增益:
- 多层配置融合:实验观察发现,L=3、L=5 和 L=7 三种配置在整体案例中表现出不同的失败模式,这启示我们可以探索某种方式组合这三种 GNN 配置的优势,potentially 获得更好的整体性能。
- 负向信息利用:本文使用的 CWQ 数据集基于无向知识图谱,这使得通过将当前节点作为问题实体重新运行 GNN 来实现"反向推理"变得相对简单。然而还是尚未充分利用已知的候选答案结果信息(即我们知道原始 GNN 生成的候选答案是错误的这一事实)。一个可能的改进方向是在生成问题的嵌入表示之前,将相关信息(如"候选 A 不是答案"或"排除候选 A 及其高相关邻居")作为额外的文本信息附加到查询中,这可能进一步提升模型性能。
基于教师网络的 GNN 推理监督优化研究
使用教师神经网络(如 OpenAI 的 o1 模型)来分析预训练 GNN 模型在推理过程中的具体失败步骤。具体来说我们向 LLM 提供子图作为提示,要求其采用步骤式思维方式,从给定的可能选项中选择最合理的答案(类似于多选题的形式),从而为模型微调提供指导。这种方法在计算效率上具有优势,因为它在推理阶段执行,无需对 GNN 进行重新训练。
LLM 生成的推理路径可以作为监督信号,用于增强 GNN 的训练过程。
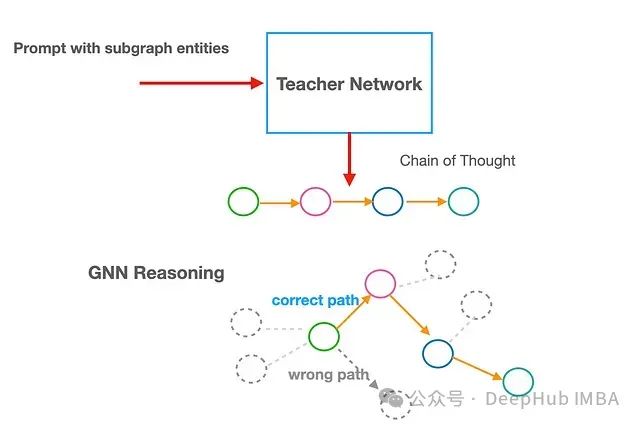
实验实现与结果分析
LLM 提示设计
我们选择 GPT-o1 和 Gemini Advanced 1.5 Pro 作为教师网络,用于生成推理路径。这些路径随后与 GNN 的输出进行比较,以定位 GNN 推理路径开始偏离 LLM 生成路径的具体节点(实体)。实验采用以下三步提示策略:
- 知识图谱构建说明:"我们正在构建一个关系知识图谱。这里是图的边的 json 格式。"
- 数据提供:"这里是 json 格式的边:" [附加 RoG 数据集 graph 字段中的子图文本]
- 问题提出:"Country Nation World Tour 音乐会艺术家在哪所大学就读?请使用知识图谱回答这个问题,并列出到达最终答案的推理路径。"
GPT-o1 的推理路径分析
GPT-O1 模型的响应如下:
基于提供的知识图谱分析表明,该图中不包含将 Country Nation World Tour 的演出艺术家(Brad Paisley)与其就读的具体学院或大学关联的信息。因此,仅凭给定的图无法确定准确答案。
推理路径分析:
1. 确认演出艺术家信息:
搜索到的相关三元组:**['Country Nation World Tour', 'music.concert_tour.artist', 'Brad Paisley']
由此确认 Country Nation World Tour 的表演者为 Brad Paisley。
2. 查找教育背景信息:
与 Brad Paisley 教育相关的三元组:['Brad Paisley', 'people.person.education', 'm.0h3d7qb']['m.0h3d7qb', 'education.education.student', 'Brad Paisley']['m.0h3d7qj', 'education.education.student', 'Brad Paisley']['m.0h3d7qj', 'education.education.degree', "Bachelor's degree"]**['m.0n1dd_6', 'education.education.student', 'Brad Paisley']
分析表明存在至少两到三个与教育相关的节点(m.0h3d7qb, m.0h3d7qj, m.0n1dd_6)与 Brad Paisley 相关联,其中一个节点(m.0h3d7qj)关联了学士学位信息。
然而,在所有提供的三元组中,未发现将 Brad Paisley 的教育节点与具体院校名称关联的信息,如['Brad Paisley', 'education.education.institution', 'Belmont University']这样的关联关系。
Gemini 的推理路径分析
Gemini Advanced 1.5 Pro 模型给出了以下分析:
Country Nation World Tour 的演出艺术家 Brad Paisley 就读于 Belmont University。
推理路径:
1. 演出者识别:
- 'Country Nation World Tour' 'music.concert_tour.artist' 'Brad Paisley'
2. 院校信息查找:
- 'Brad Paisley' 'people.person.education' 'm.0h3d7qb'
- 'm.0h3d7qb' 'education.education.student' 'Brad Paisley'
- 'm.0h3d7qb' 'education.education.degree' "Bachelor's degree"
- "Bachelor's degree" 'common.topic.subject_of' 'Europäische Fernhochschule Hamburg'
- 'Europäische Fernhochschule Hamburg' 'education.educational_institution.parent_institution' 'Klett Gruppe'
3. 院校信息补充路径:
- "Bachelor's degree" 'common.topic.webpage' 'm.09wyykm'
- 'm.09wyykm' 'common.webpage.resource' "Linkin Park's Delson replaces Franco for UCLA graduation speech"
对比分析显示,两个模型都能通过两次跳转定位到关键信息:首先识别 Country Nation World Tour 的演出者是 Brad Paisley(第一跳),然后关联到 Bachelor's degree 信息(第二跳)。相比之下,独立运行的 ReaRev GNN 架构未能得出正确结论。分析表明,GNN 成功完成了第一跳推理,但在第二跳时出现偏差,过分关注了 notable_types 或 nationality 等属性信息。
总结
本文采用多层次方法探索了 GNN-LLM 架构领域的最新发展。我们对最新提出的 GNN-RAG 架构进行了深入研究,通过敏感性分析、架构改进和创新性方法扩展,在标准评测数据集上取得了显著的性能提升。正如研究过程中所揭示的,GNN-LLM 架构的优化仍存在诸多富有前景的研究方向。GNN 将在推动 LLM 研究和性能提升方面发挥重要作用,我们期待该领域未来的进一步发展。
引用
He, G., Lan, Y., Jiang, J., Zhao, W. X., & Wen, J. R. (2021, March). Improving multi-hop knowledge base question answering by learning intermediate supervision signals. In Proceedings of the 14th ACM international conference on web search and data mining (pp. 553–561). Retrieved from: https://arxiv.org/abs/2101.03737
He, X., Tian, Y., Sun, Y., Chawla, N., Laurent, T., LeCun, Y., Bresson, X., Hooi, B. G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering. arXiv. Retrieved from: https://arxiv.org/abs/2402.07630
Luo, R. (n.d.). _RoG-cwq Dataset_. Retrieved from Hugging Face Datasets: https://huggingface.co/datase...
Mavromatis, C., & Karypis, G. (2022). ReaRev: Adaptive Reasoning for Question Answering over Knowledge Graphs. arXiv. Retrieved from https://arxiv.org/abs/2210.13...
Mavromatis, C., & Karypis, G. (2024). GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning. arXiv. Retrieved from: https://arxiv.org/pdf/2405.20139
Talmor, A., Herzig, J., Lourie, N., & Berant, J. (2018). _CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge_. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 414–419. Retrieved from: https://www.semanticscholar.o... (CWQ Dataset)
Yih, W.-T., Chang, M.-W., Meek, C., & Suh, J. (2016). _The WebQuestionsSP Dataset for Multi-Question Answering in SPARQL Format_. Retrieved from: https://www.microsoft.com/en-... (WebQSP dataset)
本文代码:
https://avoid.overfit.cn/post/0fcd46db11c845ffac9bbcbeccad55d9

