
大语言模型的指令遵循能力需要模型能够准确识别指令中的细微要求,并在输出中精确体现这些要求。现有方法通常采用偏好学习进行优化,在创建偏好对时直接从模型中采样多个独立响应。但是这种方法可能会引入与指令精确遵循无关的内容变化(例如,同一语义的不同表达方式),这干扰了模型学习识别能够改进指令遵循的关键差异。
针对这一问题,这篇论文提出了 SPAR 框架,这是一个集成树搜索自我改进的自对弈框架,用于生成有效且具有可比性的偏好对,同时避免干扰因素。通过自对弈机制,大语言模型采用树搜索策略,基于指令对先前的响应进行改进,同时将不必要的变化降至最低。
主要创新点:
- 发现从独立采样响应中获得的偏好对通常包含干扰因素,这些因素阻碍了通过偏好学习提升指令遵循能力
- 提出 SPAR,一个创新的自对弈框架,能够在指令遵循任务中实现持续性自我优化
- 构建了包含 43K 个复杂指令遵循提示的高质量数据集,以及一个能够提升大语言模型指令遵循能力的监督微调数据集
方法论
整体框架
SPAR 迭代训练框架如图所示:

- 在形式化定义中,每次迭代时,给定提示集中的指令 x,执行模型生成响应 y
- 改进模型负责识别未能准确遵循指令的响应,将其标记为负面响应
- 框架的核心目标是将负面响应优化为符合要求的正确响应
- 收集生成的改进对,通过直接偏好优化(DPO)来优化执行模型
- 同时,应用拒绝采样微调(RFT)提升改进模型性能,为下一轮自我优化做好准备
数据构建方法
提示构建
- 种子提示:基于 Infinity-Instruct 数据集构建初始种子提示集,该数据集包含一千万条高质量对话。经过基于长度、关键词和自我-BLEU 的规则过滤,最终获得约 50k 条种子提示
- 分类法驱动的提示构建:采用基于分类法的机制确保约束类型的全面性和平衡性。在建立约束分类体系后,基于种子提示构建复杂指令遵循任务,最终生成约 43k 条提示
模型初始化
- 执行模型数据构建: 首先收集高性能语言模型对复杂提示的响应,生成用于执行模型的监督微调(SFT)数据(x, y) ∈ DActor,其中 x 表示复杂指令,y 表示高性能模型的响应。随后对基础模型进行微调,得到初始执行模型 M0
- 改进模型数据构建: 为使改进模型具备高质量的判断和改进能力,从初始执行模型 M0 中采样响应。收集高性能语言模型的判断结果,形成数据集(x, y, j) ∈ DJSFT。识别并收集被判定为未能准确遵循指令的响应作为负面样本。对这些负面响应,使用高性能语言模型进行最小化修正,避免引入无关变化
- 训练策略: 执行模型和改进模型均采用标准监督微调,损失函数定义如下:
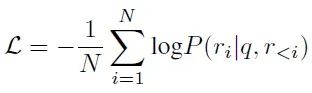
其中 q 代表输入,r 代表目标响应,N 代表 r 的长度。执行模型训练中,输入 q = x,目标 r = y。改进模型训练中,对于 DJSFT,输入 q = (x, y),目标 r = j;对于 DRSFT,输入 q = (x, ynegative, j),目标 r = yrefined。
集成树搜索的自对弈训练机制
a) 负面数据采集流程
- 对每个提示 x,首先从执行模型中采样 K 个响应{y1, y2, . . . , yK}
- 对每组提示-响应对,利用改进模型生成判断结果,包含两个核心要素:指令遵循程度的标签判定和详细的评估说明
- 为提高判断准确性,引入自一致性机制,通过从改进模型获取多个判断结果并采用多数投票确定最终标签
- 在完成多数投票后,随机选取一个与投票标签一致的判断作为最终结果,这使论文提出的方法能够识别出那些会导致指令遵循失败的高难度提示,形成(x, ynegative, j)格式的数据元组,其中 ynegative 表示不合格响应,j 为对应判断结果
b) 树搜索优化方法
- 考虑到直接改进往往导致较低的成功率,本研究采用树搜索方法,实现了广度优先搜索(BFS)和深度优先搜索(DFS)策略
- 以 BFS 为例,从不合格的指令-响应对及其判断结果作为根节点出发,逐层扩展搜索树,直至找到符合要求的响应
- 在每个中间节点,为当前响应生成潜在的改进方案,并由改进模型评估其正确性。生成的改进方案数量即为分支数
- 在树的每一层,改进模型执行以下操作:1). 为当前层的所有节点生成潜在的改进方案;2). 评估这些改进方案的正确性。由此生成包含新响应及其对应判断的子节点集合
- 搜索过程持续进行,直到获得数据元组(x, ynegative, yrefined),其中 yrefined 为经过改进的合格响应
c) 执行模型训练方法
- 利用改进对数据进行偏好学习,采用 DPO 方法优化执行模型
- 在第 t 次迭代中,使用改进对(ynegative, yrefined)训练执行模型 Mt,将 ynegative 作为被拒绝样本(yl),yrefined 作为被选择样本(yw)
- 训练数据集记为 Dtdpo,DPO 损失函数定义如下:
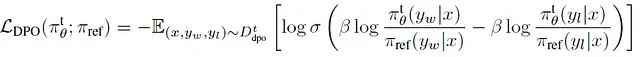
其中 π tθ 表示执行模型 Mt,参考模型 π ref 使用 Mt 初始化并在训练过程中保持不变。这一过程产生新的执行模型 Mt+1,用于下一轮迭代
d) 改进模型训练方法
鉴于改进模型的输入具有模板化特征,论文采用拒绝采样微调(RFT)方法获取新的改进模型 Rt+1。RFT 训练数据包含两个主要组成部分:
(1) 改进训练数据集
- 改进训练数据集由记录不合格响应改进过程的数据元组构成
- 对于树搜索改进过程中的每个不合格响应,收集(x, yp, jp, yrefined)格式的数据元组,其中(x, yp, jp)代表改进树中最终合格响应的父节点,yrefined 为经过改进的合格响应
(2) 判断训练数据集
- 判断训练数据来源于负面数据采集过程和树搜索过程中的节点
- 该数据集由(x, yi, ji)格式的元组组成,其中 x 为提示,yi 为对应响应,ji 为与多数投票结果一致的判断
- 随后,基于构建的训练数据进行监督微调
- 对于改进数据集 Dtrefine,采用数据元组(x, yp, jp, yrefined),输入 q = (x, yp, jp),目标 r = yrefined。对于判断数据集 Dtjudge,采用数据元组(x, yi, ji),输入 q = (x, yi),目标 r = ji。
实验研究
执行模型评估结果
SPAR 在指令遵循能力方面的显著提升
下表展示了经过迭代训练的大语言模型在指令遵循基准测试上的核心性能指标
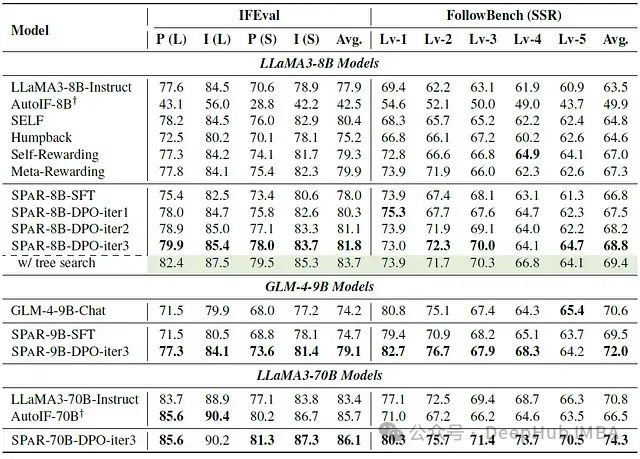
经过三轮迭代训练后,SPAR-8B-DPO-iter3 模型在 IFEval 评测中的表现超越了 GPT-4-Turbo(后者的平均准确率为 81.3%)。此外,在推理阶段引入树搜索优化技术后,模型性能获得显著提升
值得注意的是,SPAR 在模型规模扩展方面表现出优异的特性,这极大地增强了 LLaMA3-70B-Instruct 模型的指令遵循能力
SPAR 对模型通用能力的影响分析
下表呈现了在通用基准测试上的性能数据

实验数据表明,SPAR 不仅保持了模型的通用能力,在某些场景下还带来了性能提升,尤其是在 GSM8k 和 HumanEval 基准测试中。这证实了增强的指令遵循能力有助于提升大语言模型的整体对齐效果
SPAR 相较于基线方法的优势
下图展示了各轮训练迭代在 IFEval 评测中的进步情况
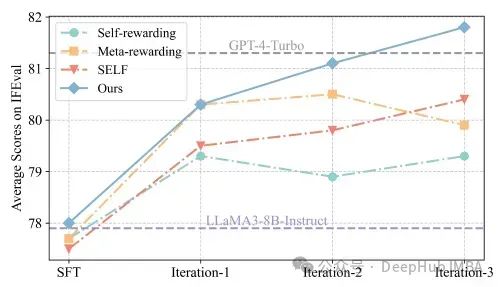
在每轮迭代中,SPAR 都展现出明显的优势。特别值得注意的是,其他方法即使经过三轮迭代,其性能仍未能达到 SPAR 首轮迭代的水平
改进模型评估结果
SPAR 在判断能力方面的迭代提升
下表展示了经过迭代训练的大语言模型在 LLMBar 评测中的判断能力表现
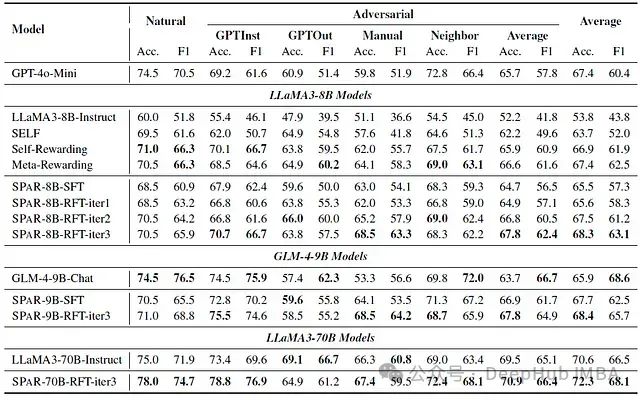
实验结果显示,SPAR 迭代训练显著提升了模型评估指令遵循任务的能力
在第三轮迭代后,改进模型 SPAR-8B-RFT-iter3 的性能超越了用于构建判断 SFT 数据集的 GPT-4o-Mini 模型
SPAR 在改进能力方面的持续优化
下表呈现了改进能力的评估结果。其中 Acc-GPT 采用 GPT-4o 作为评判标准;Acc-SPAR 则使用 SPAR-8B-RFT-iter3 进行评估

数据显示,LLaMA3-8B-Instruct 模型的改进准确率在每轮训练迭代中均呈现稳定提升趋势,最终达到了与用于 SFT 数据构建的高性能模型 GPT-4o-Mini 相当的水平
总结
本研究提出了创新性的自对弈框架 SPAR,通过改进对训练提升大语言模型的指令遵循能力。研究发现,与传统方法采用独立采样响应构建偏好对相比,通过最小化外部因素并突出关键差异的改进对方法,能在指令遵循任务上实现显著性能提升。采用本框架进行迭代训练的 LLaMA3-8B-Instruct 模型在 IFEval 评测中展现出超越 GPT-4-Turbo 的性能。通过推理计算能力的扩展,模型性能还有进一步提升的空间
https://avoid.overfit.cn/post/34fe841bb20f40e898570f8b81cf7ad6

