
选择性自我监督微调(Selective Self-to-Supervised Fine-Tuning,S3FT)是一种创新的大语言模型微调方法,该方法通过部署专门的语义等价性判断器来识别训练集中模型自身生成的正确响应。在微调过程中,S3FT 策略性地结合这些正确响应与剩余样本的标准答案(或其释义版本)来优化模型。与传统监督微调(SFT)相比,S3FT 不仅在特定任务上表现出更优的性能,还显著提升了模型的跨域泛化能力。通过充分利用模型自身生成的高质量响应,S3FT 有效减缓了微调阶段中常见的模型过度专门化问题。

S3FT 技术原理与实现机制
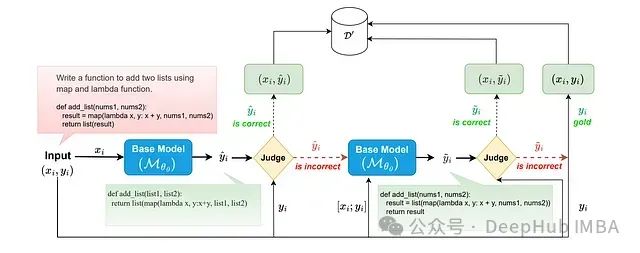
选择性自我监督微调(S3FT)旨在解决大型语言模型(LLM)特定任务微调过程中的一个核心挑战:如何在提升模型在目标任务上的表现的同时,最大程度地保留其通用能力。这一问题在标准监督微调(SFT)中尤为突出。S3FT 的设计基于两项关键发现:
自然语言处理任务通常存在多种有效响应现象,即对同一输入可能存在多个语义等价但表述不同的正确答案。此外,利用模型自身生成的语言形式进行训练有助于保持模型原始分布特性,从而减轻灾难性遗忘现象(即模型丢失先前获取的知识)。
初始预测阶段:
S3FT 首先针对训练样本(输入 xi 与标准答案 yi)让基础模型 Mθ0(已经过预训练和指令调整)生成预测结果 ˆyi = Mθ0(xi)。
等价性评估阶段:
系统随后评估生成的预测 ˆyi 与标准答案 yi 之间的语义等价性。这一评估可通过两种方式实现:一是采用启发式方法,如关键信息比对或整体一致性验证;二是调用更强大的语言模型作为判断器,对 ˆyi 和 yi 之间的语义等价性进行评估。
训练数据选择策略:
当 ˆyi 与 yi 语义等价时,系统将采用(xi, ˆyi)对作为训练样本,这种方式强化了模型现有知识结构,并有助于维持其原始分布特性。当 ˆyi 与 yi 不等价时,基础模型 Mθ0 会对标准答案 yi 进行自主释义,生成 ˜yi = Mθ0([xi; yi]),这一步骤旨在缩小标准答案与模型自身语言风格之间的差距。
二次等价性验证:
对于需要释义的情况,系统会再次验证 ˜yi 是否与 yi 语义等价。
最终训练数据确定:
如果 ˜yi 与 yi 语义等价,则使用(xi, ˜yi)对进行训练,这种方法在传授模型所需输出的同时,保持了其自身的"语言风格",最大限度减少与原始分布的偏离。如果 ˜yi 与 yi 不等价,则回退到标准 SFT 方式,使用原始(xi, yi)对进行训练,这是当模型无法生成合适释义时的兜底策略。
实验中采用 Mistral-instruct-v2 (7B)同时作为基础模型和判断模型。所有微调实验均采用低秩适应(Low-Rank Adaptation,LoRA)技术,其中秩设为 8,缩放因子为 16,dropout 率为 0.1。
性能评估与实验结果
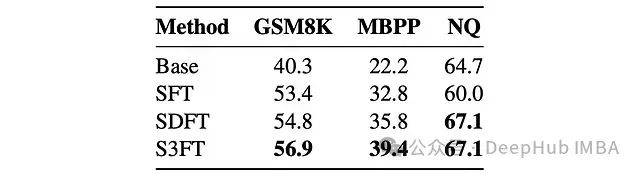
上图展示了不同微调技术在准确率(%)指标下的性能对比。
领域内性能提升: 实验结果表明,S3FT 在领域内数据集(如 GSM8K、MBPP 和 NQ)上的表现显著优于基础模型和传统 SFT 方法。特别是在阅读理解任务(NQ 数据集)上,S3FT 达到了与 SDFT 相当的性能水平。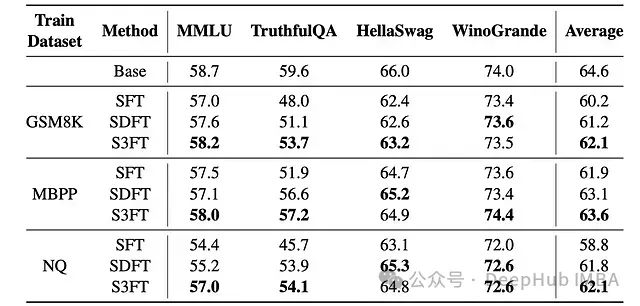
上图展示了各方法在其他基准测试上的泛化能力。
灾难性遗忘缓解效果: 与传统 SFT 相比,S3FT 展现出更强的泛化能力,在微调后的领域外基准测试中性能下降幅度明显减小。相比之下,SFT 在这些基准上出现了显著的性能降低,表明存在严重的灾难性遗忘问题。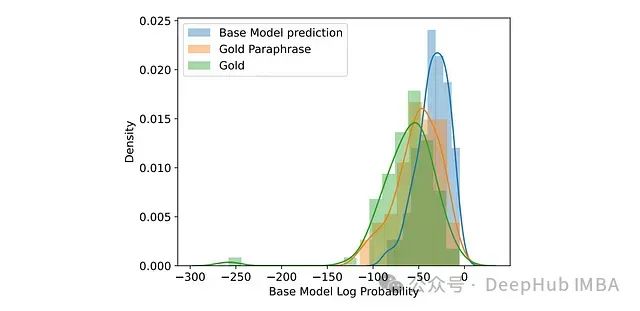
上图为 Mistral-7B-Instruct-v0.2 对标准响应、标准响应释义和模型自身预测分配的对数概率直方图。
标准响应释义的影响分析: 研究发现,将模型自身的正确响应作为训练目标(如 S3FT 中采用的策略)能带来更优的性能和泛化能力。这一现象可归因于模型生成的响应通常比标准响应甚至释义后的标准响应更接近模型自身的分布特性。直接训练标准响应会导致模型分布发生改变,从而对泛化能力产生负面影响。
总结
S3FT(选择性自监督微调)代表了一种解决大语言模型微调中固有问题的创新方法。通过智能地选择和整合模型自身生成的高质量响应,S3FT 成功地在两个看似矛盾的目标之间取得了平衡:提升特定任务的性能,同时保留模型的泛化能力。实验结果清晰地表明,与传统监督微调相比,S3FT 不仅在目标领域内取得了更好的性能,还显著减轻了灾难性遗忘现象,维持了模型在领域外任务上的表现。
这种方法的核心优势在于尊重模型原有的语言分布特性,使微调过程更加和谐,避免了强制模型适应可能与其内部表征不一致的外部标准答案。此外,S3FT 的实现相对简单,不需要复杂的架构修改或额外的训练阶段,这使其成为一种实用且有效的微调策略。
未来工作可以探索更高效的等价性判断机制,以及 S3FT 在更广泛任务类型和更大规模模型上的应用效果。此外,将 S3FT 与其他微调技术(如参数高效微调方法)结合的潜力也值得研究。总体而言,S3FT 为大语言模型的微调提供了一种平衡特定任务性能和通用能力的新范式,为 AI 系统的实际应用提供了重要价值。
论文地址:
https://avoid.overfit.cn/post/da816d0257eb4600a132a6da935b3cd9

