
传统检索增强生成(RAG)架构因依赖静态检索机制,在处理需要顺序信息搜索的复杂问题时存在效能限制。尽管基于代理的推理与搜索方法提供了更具适应性的解决方案,但现有方法大多过度依赖提示工程技术。
针对上述挑战,本文介绍了 RAG-Gym 框架,这是一种通过在搜索过程中实施细粒度过程监督来增强信息搜索代理的统一优化方法。该研究的主要贡献包括:提出 RAG-Gym 统一优化框架;设计 ReSearch 代理架构,实现答案推理与搜索协同;验证了经训练的过程奖励模型作为验证器能显著提升搜索代理性能;以及针对代理式 RAG 系统中过程监督来源、奖励模型可迁移性和性能扩展规律提供了系统性分析。
RAG-Gym 框架
框架概述
RAG-Gym 将知识密集型问答任务形式化为嵌套马尔可夫决策过程(MDP),构建了完整的过程监督体系。该框架通过在每个决策时间步骤随机采样动作候选项,并利用外部注释器选择最优动作来收集过程奖励数据。框架内实现了多种过程监督方法,为代理优化提供了统一的实验环境。

知识密集型问答的 MDP 形式化
为了系统化地表示知识密集型问题上的语言代理决策过程,RAG-Gym 构建了外部 MDP,其关键组成如下:
a) 状态空间(State Space) S
在时间步 t,状态$s_t \in S$包含原始问题 Q 和信息搜索历史$H_t$,形式化表示为:$s_t = (Q, H_t)$,其中$H_t = \{(q_1, D_1), \cdots, (q_{t-1}, D_{t-1})\}$表示信息搜索查询序列$q_1, \cdots, q_{t-1}$及其对应的环境返回检索文档集合$D_1, \cdots, D_{t-1}$。状态空间 S 包含所有可能状态:
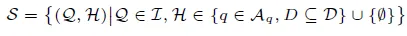
其中 I 表示问题空间,$A_q$表示所有可能搜索查询的空间,D 表示所有文档的空间。
b) 动作空间(Action Space) A
时间步 t 的动作$a_t$可以是搜索查询或针对原始问题的预测答案。动作空间定义为$A = A_q \cup A_p$,$A_q$代表所有可能查询的集合,$A_p$代表可能答案的集合。
c) 信息检索环境(IR Environment)
RAG-Gym 中的外部 MDP 环境由信息检索(IR)系统驱动,该系统接收搜索查询$q_t$作为输入,并返回相关文档集合$D_t$作为输出。IR 系统可表示为从$A_q$到$P(D)$的映射函数,其中$P(D)$是 D 的幂集。检索过程实际由底层文本检索器和特定检索参数(如返回文档数量)决定。
d) MDP 工作流程
对于给定问题 Q,MDP 从初始状态$s_1 = (Q, \emptyset)$开始。每个步骤 t,根据代理策略$\pi_{f(\theta)}(\cdot | s_t)$采样动作$a_t$,其中$\pi_{f(\theta)}: S \rightarrow \Delta(A)$定义了给定状态的动作分布。代理策略由参数 θ 组成,θ 表示基础语言模型参数,f 代表代理特定函数,表示如何利用基础 LLM 实现策略。
若$a_t \in A_q$,则历史更新为$H_{t+1}$,通过添加$(q_t, D_t)$,状态转换为$s_{t+1} = (Q, H_{t+1})$。若$a_t \in A_p$,则当前回合结束,MDP 终止。
e) 奖励机制
外部 MDP 中,回合奖励由最终预测的正确性决定。状态-动作对$(s_t, a_t)$的即时奖励定义为:
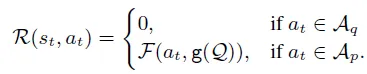
代理的优化目标是最大化轨迹上的预期累积奖励:
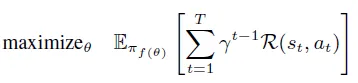
过程监督优化搜索代理
RAG-Gym 通过整合过程奖励机制,实现了对语言模型的高效调优,使 token 生成与高质量搜索行为保持一致。
a) 过程奖励数据收集
数据收集流程始于轨迹采样,语言代理基于当前策略生成一系列动作。在轨迹的每个步骤,系统提出多个候选动作,并根据预定义评估标准选择最佳动作。为确保评估一致性,采用基于排序的评估框架而非数值打分。执行选定动作后,轨迹转入下一状态,重复此过程直至轨迹终止。为保证质量,系统仅保留产生正确最终答案的轨迹。
b) 基于过程监督的代理优化
(1) 监督微调(SFT)
过程奖励筛选的优质动作用于训练语言代理。形式上,SFT 的目标是最小化给定状态下选定动作的负对数似然:
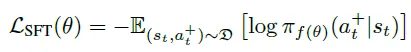
其中 D 表示过程奖励标记的状态-动作对数据集。
(2) 直接偏好优化(DPO)
系统引入对比学习框架,整合已选与未选动作信息。过程奖励数据重构为偏好对$(a^+_t, a^-_t)$,其中$a^+_t$为首选动作,$a^-_t$为次优选择。DPO 目标函数为最小化以下损失:
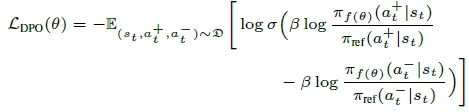
(3) 过程奖励建模(PRM)
系统训练独立奖励模型$r_\phi(s_t, a_t)$基于收集数据预测过程奖励。优化目标是最小化对比损失,评估首选动作相对次优动作的质量差异:
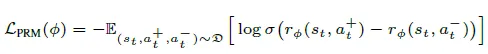
推理与搜索(ReSearch)代理架构
ReSearch 代理架构在统一的答案驱动框架中整合了推理与搜索功能,形成了一种高效的信息获取与处理机制。
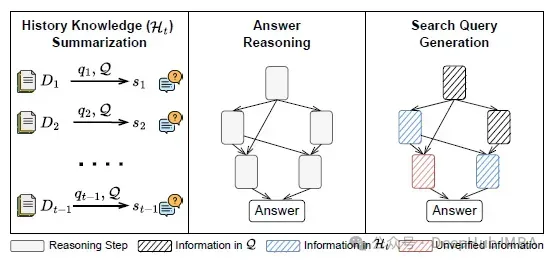
历史知识总结
给定状态$s_t$,包含原始问题 Q 和历史$H_t = \{(q_1, D_1), \ldots, (q_{t-1}, D_{t-1})\}$,代理首先将检索文档总结为对应查询的结构化响应,形成精炼知识表示$H'_t$:
$H'_t = \{(q_1, m_1), \ldots, (q_{t-1}, m_{t-1})\}$
此总结步骤有效过滤不相关信息,缓解长上下文处理挑战,使代理能聚焦于构建答案时最相关的事实。
答案推理
利用精炼知识$H'_t$,代理进行结构化推理以推导问题的候选答案。随后,系统检查推理步骤,判断所有声明是否具备充分的历史依据。若代理确认答案推理中的所有声明均有检索证据支持,则输出最终答案。否则,系统识别未经验证的声明,即那些缺乏基于可用证据充分理由的陈述。
搜索查询生成
未经验证的声明成为生成下一搜索查询的基础,该查询专门用于检索缺失信息。从此查询获取的文档被添加至$H_t$,并重复推理过程,直至所有声明获得验证或检索预算耗尽。
实验结果
过程监督方法比较
下表展示了使用 Llama-3.1-8B-Instruct 实现的各类代理性能,及其通过 RAG-Gym 不同过程监督方法调优后的表现:
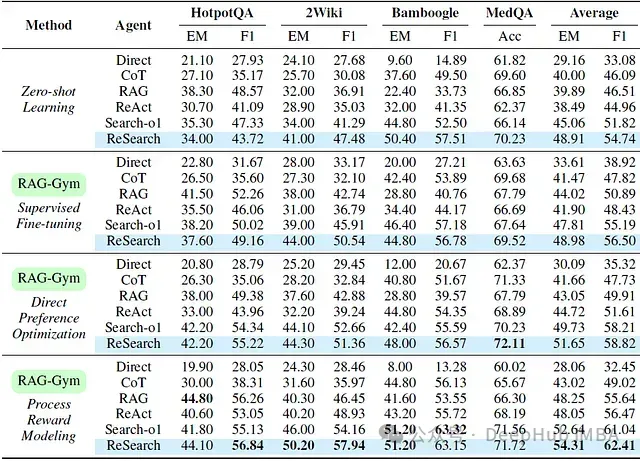
与零样本学习(ZSL)基线相比,过程监督显著提升了所有代理的性能,证明其在增强中间推理和查询生成方面的有效性。在三种过程监督算法中,PRM 整体表现最佳,相较 ZSL 基线提升高达 25.6%(ReAct 平均 F1)。
ReSearch 与其他代理比较
结果表明 ReSearch 在零样本设置和过程监督调优后均持续优于其他代理。无需调优时,ReSearch 展现了强大的零样本性能,证明了明确将答案推理与查询生成对齐的有效性。结合过程奖励模型后,ReSearch 实现了最先进的性能,在多个数据集上平均 EM(完全匹配)得分达 54.31%,平均 F1 得分达 62.41%。
奖励模型可迁移性
下图展示了使用基于 Llama-3.1-8B 训练的过程奖励模型对 GPT-4o-mini 的 ReSearch 代理性能提升:
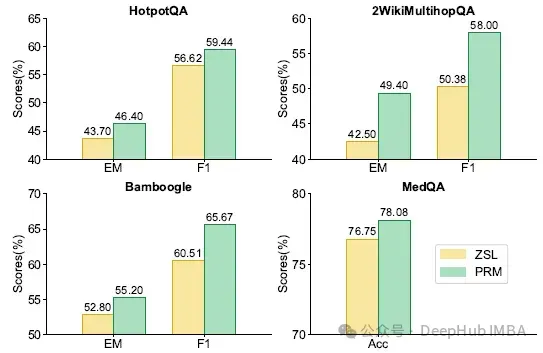
结果显示,使用奖励模型进行动作选择在所有任务中均带来一致收益,证明了 PRM 在有效筛选不同 LLM 高质量动作方面具备良好的可迁移性。
深入分析
不同奖励来源比较
研究中,四位领域专家对 200 个 MedQA 问题进行注释。奖励模型在剩余 800 个 GPT-4o 注释的训练问题上进行训练,并将其偏好与领域专家判断进行比较。下表显示了领域专家偏好与不同奖励来源在 MedQA 任务上的一致性:

使用 GPT-4o 注释训练的奖励模型与人类偏好达成最高一致性(85.85%),显著优于 Math-Shepherd 中引入的基于 rollout 方法(71.03%)。这表明在特定场景下,GPT-4o 的注释与人类推理和决策模式高度相关。
训练规模效应
下图展示了使用不同训练样本数量调优的过程奖励模型对 ReSearch 代理性能的影响:
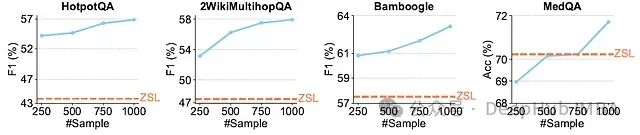
结果表明,ReSearch 性能随训练样本增加而提升,但随样本规模增长,边际收益趋于收敛,符合典型的机器学习规模律。
推理时间扩展分析
下图展示了推理时间扩展研究结果,其中 ReSearch 作为测试代理:
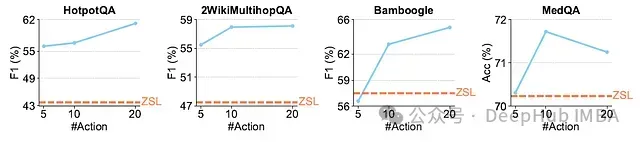
在多个基准测试中观察到一致趋势:增加采样动作数量通常能提升整体性能,表明更广泛的动作探索空间对复杂问题求解具有积极影响。
总结
论文介绍了 RAG-Gym,一个通过过程监督优化推理和搜索代理的统一框架,并提出 ReSearch 架构,有效整合答案推理与搜索查询生成。实验结果证明,RAG-Gym 显著提升了知识密集型任务中搜索代理的性能,而 ReSearch 架构在各种测试场景中均优于现有基线系统。
研究进一步验证了利用大型语言模型作为过程奖励判断的有效性、训练奖励模型在不同语言模型间的可迁移性,以及 ReSearch 在训练和推理过程中的性能扩展规律,为未来基于检索增强生成的智能系统研发提供了重要理论和实践参考。
论文:
https://avoid.overfit.cn/post/b8ca237f97614085955d55b3fda2d6e4

