
全球有 2,000 多万开发者基于 Arm 架构进行开发,而 Arm 也持续致力于赋能全球开发者先进的人工智能 (AI) 计算能力。而要实现这一目标,就需要在庞大的软硬件合作伙伴生态系统中开展关键的软件协作。
去年,Arm 推出了包含一系列开发者支持技术和资源的 Arm Kleidi ,旨在推动整个机器学习软件栈的技术协作和创新。其中包括提供优化软件例程的 Arm KleidiAI 软件库 ,当将 KleidiAI 集成到如 XNNPACK 等关键框架中时,能够帮助基于 Arm Cortex-A CPU 的开发者自动实现 AI 加速。而通过 XNNPACK 将 KleidiAI 集成到 ExecuTorch 中,可提升 Arm CPU 在移动端的 AI 工作负载性能。
得益于 Arm 和 Meta 工程团队的协作,AI 开发者可在具有 i8mm ISA 扩展的基于 Armv9 架构的 Arm Cortex-A CPU 上部署 Llama 量化模型,运行速度至高可提升 20%。与此同时,ExecuTorch 团队也已正式上线了测试 (Beta) 版本 。
这标志着双方合作中的一个重要里程碑。在本文中,我们将分享更多细节,包括 ExecuTorch 功能、Meta Llama 3.2 模型、按块 (per-block) 的 4 位整数量化,以及在 Arm CPU 上展现出的出色性能。我们在三星 S24+ 设备上运行 Llama 3.2 1B 量化模型,在预填充阶段实现了每秒超过 350 个词元 (token) 的速度,如以下图所示。
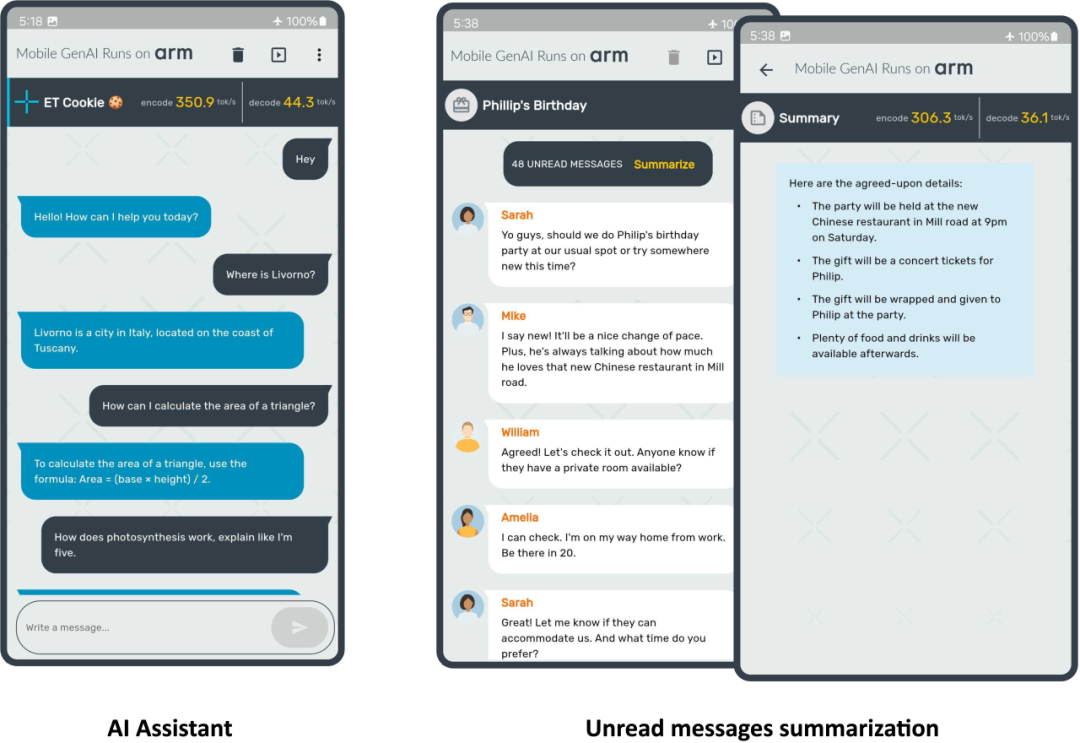
接下来,一起深入了解实现上图所示演示所需的关键组件。
Meta Llama 3.2
Meta 发布的首款轻量级 Llama 量化模型能够在主流的移动设备上运行。Meta 对 Llama 3.2 1B 和 3B 模型采用了两种量化技术:带有 LoRA 适配器的量化感知训练 (QAT) QLoRA 和先进的训练后量化方法 SpinQuant。这些量化模型在使用 PyTorch 的 ExecuTorch 框架作为推理引擎,并使用 Arm CPU 作为后端的情况下进行评估。这些经过指令调整的模型保留了原始 1B 和 3B 模型的质量和安全性,同时与原始 BF16 格式相比,实现了二至四倍的加速,模型大小平均减少了 56%,内存占用平均减少了 41%。
ExecuTorch
ExecuTorch 是一种用于在端侧部署 AI 模型的 PyTorch 原生框架,旨在增强隐私性并减少延迟。它支持部署前沿的开源 AI 模型,包括 Llama 模型系列及视觉和语音模型(如 Segment Anything 和 Seamless)。
这为广泛的边缘侧设备开辟了新的可能性,例如手机、智能眼镜、VR 头显和智能家居摄像头等。传统上,在资源有限的边缘侧设备上部署 PyTorch 训练的 AI 模型是一项具有挑战性且耗时的工作,通常需要转换为其他格式,过程中可能会出现错误和性能不理想的情况。此外,硬件和边缘侧生态系统中的不同工具链也影响了开发者体验,使开发通用解决方案变得不切实际。
为解决这些问题,ExecuTorch 提供了多个可组合的组件,包括核心运行时、算子库和代理 (delegation) 接口,支持可移植性和可扩展性。模型可以使用 torch.export() 导出,生成与 ExecuTorch 运行时原生兼容的图表,能够在大多数搭载 CPU 的边缘侧设备上运行,并可扩展到 GPU 和 NPU 等专用硬件以增强性能。
通过与 Arm 合作,ExecuTorch 现可利用 KleidiAI 库中经过优化的低比特矩阵乘法内核,通过 XNNPACK 提高端侧大语言模型 (LLM) 的推理性能。
为 AI 工作负载提升架构
自深度学习浪潮兴起以来,Arm 一直致力于投资开源项目并推进新的处理器技术,专注于提高 AI 工作负载的性能和能效。
例如,Arm 从 Armv8.2-A 架构开始引入 SDOT 指令,以加速 8 位整数向量之间的点积运算。目前移动设备上已广泛具备此特性,显著加快了 8 位量化模型的计算速度。继 SDOT 指令之后,Arm 引入了 BF16 数据类型和 MMLA 指令,进一步提升 CPU 的浮点和整数矩阵乘法性能,后来又宣布推出了可伸缩矩阵扩展 (SME)
,标志着机器学习能力的重大飞跃。
下图展示了过去十年中 Arm CPU 在 AI 领域持续创新的部分示例:
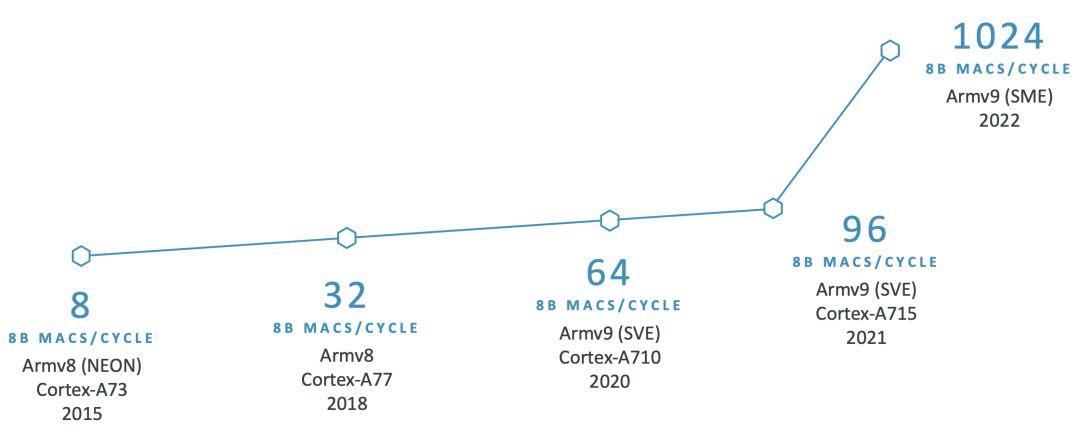
鉴于 Arm CPU 的广泛应用,AI 框架需要在关键算子中充分利用这些技术,以大幅提高性能。认识到这一点后,我们需要一个开源库来共享这些经过优化的软件例程。然而,我们也注意到将新库集成到 AI 框架中存在挑战,例如对库的大小、依赖项和文档的担忧,而且需要避免给开发者增加额外的负担。因此,我们努力收集合作伙伴的反馈意见,并确保集成过程顺利进行,并且不需要 AI 开发者使用额外的依赖项。这项工作促成了 KleidiAI 的诞生,这是一个开源库,为针对 Arm CPU 量身定制的 AI 工作负载提供了经过优化的性能关键例程。
Arm 与 Meta 的 ExecuTorch 团队合作,为创新的 4 位按块量化方案提供了软件优化,用于加速 Llama 3.2 量化模型的 Transformer 层的 torch.nn.linear 算子中的矩阵乘法内核。ExecuTorch 灵活的 4 位量化方案在针对端侧 LLM 的模型准确性和低比特矩阵乘法性能之间取得了平衡。
按块的 4 位整数量化
在 KleidiAI 中,我们引入了针对这种新的 4 位整数量化方案进行优化的微内核
(matmul_clamp_f32_qai8dxp_qsi4c32p
如下图所示,对权重参数(RHS 矩阵)采用这种 4 位按块量化策略,并对激活参数(LHS 矩阵)采用 8 位按行量化:
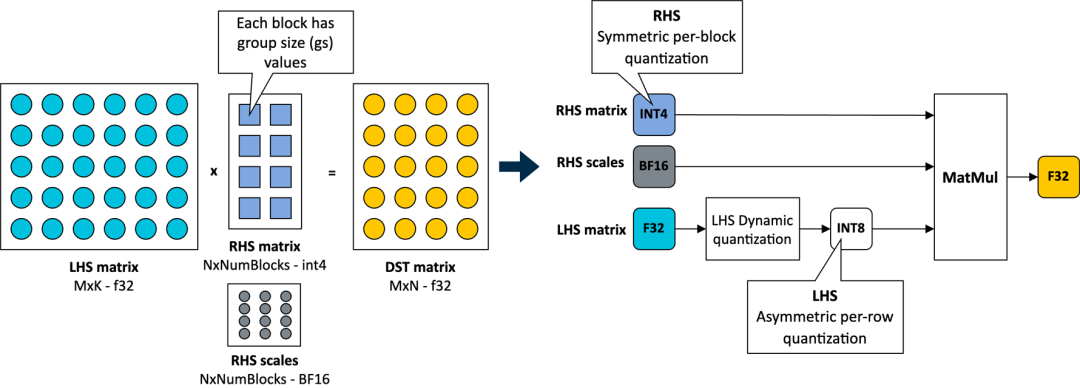
如上图所示,权重矩阵中的每个输出特征图 (OFM) 被划分为大小相等的块(组大小),每个块都有一个以 BF16 格式存储的比例因子。BF16 的优势在于它以一半的比特数维持了 32 位浮点 (FP32) 格式的动态范围,并且可以使用简单的移位运算轻松地与 FP32 进行转换。因而,BF16 非常适合用于节省模型空间、保持准确性,以及确保向后兼容缺少 BF16 硬件加速的设备。
为保证完整性,这个 4 位量化方案和我们在 KleidiAI 中的实现允许用户配置线性权重 (RHS) 的组大小;如果模型由用户进行量化,则允许用户在模型大小、模型准确性和模型性能之间进行权衡。
至此,我们已准备好来展示使用 ExecuTorch 在 Arm CPU 上运行 Llama 3.2 1B 和 Llama 3.2 3B。下面,先来介绍一下用于评估 LLM 推理性能的几个指标。
LLM 推理指标
通常,用于评估 LLM 推理性能的指标包括:
- 首词元延迟 (TTFT):
该指标测量的是用户提供提示词后生成第一个输出词元所花费的时间。这方面的延迟或响应时间对于良好的用户体验至关重要,尤其是在手机上。TTFT 也是提示词或提示词词元长度的函数。为了使该指标不受提示词长度的影响,我们在此使用“每秒预填充词元数”作为替代指标。它们之间呈反比关系:TTFT 越低,每秒预填充词元数就越高。 - 解码性能:
该指标是指每秒生成的平均输出词元数,因此以“词元/秒”为单位进行报告。它与生成的词元总数无关。对于端侧推理,重要的是使该指标高于用户的平均阅读速度。 - 峰值运行时内存:
该指标反映了运行模型时要达到预期性能(使用上述指标来衡量)所需的 RAM 大小。这是端侧 LLM 部署的关键指标之一,决定了可在设备上部署的模型类型。
结 果
Llama 3.2 1B 量化模型(SpinQuant 和 QLoRA)专为在各种 RAM 有限的手机上高效运行而设计。
我们展示的测量数据基于运行原生态安卓系统的三星 S24+ 手机。我们使用 Llama 3.2 1B 参数模型进行实验。虽然我们的演示仅使用了 1B 模型,但预计 3B 参数模型也会有类似的性能提升。实验设置包括进行一次预热运行,序列长度为 128,提示词长度为 64,使用八个可用 CPU 中的六个,并通过 adb 测量结果。
我们使用来自 GitHub 的 ExecuTorch 主分支,首先用已发布的检查点为每个模型生成 ExecuTorch PTE 二进制文件。然后,我们使用相同的代码仓库,为 Armv8 生成了 ExecuTorch 运行时二进制文件。我们将使用 KleidiAI 构建的二进制文件,比较不同的 1B 量化模型与 BF16 模型的性能。我们还将比较带有 KleidiAI 的二进制文件和不带有 KleidiAI 的二进制文件运行量化模型的性能提升幅度,以分析 KleidiAI 产生的影响。
我们的演示结果显示,Llama 3.2 1B 量化模型在预填充阶段每秒可生成超过 350 个词元,在解码阶段每秒可生成超过 40 个词元。这种级别的性能足以仅使用 Arm CPU,就可在端侧实现文本摘要功能,并提供良好的用户体验。为便于理解,可以参考的是,平均 50 条未读消息包含约 600 个词元。凭借这样的性能,响应时间(即生成的第一个单词出现在屏幕上所需的时间)约为两秒。
量化模型性能
与基线 BF16 模型相比,Llama 3.2 量化模型 SpinQuant 和 QLoRA 在提示词预填充和文本生成(解码)方面的性能显著提升。我们观察到,解码性能提高了二倍以上,预填充性能提高了五倍以上。
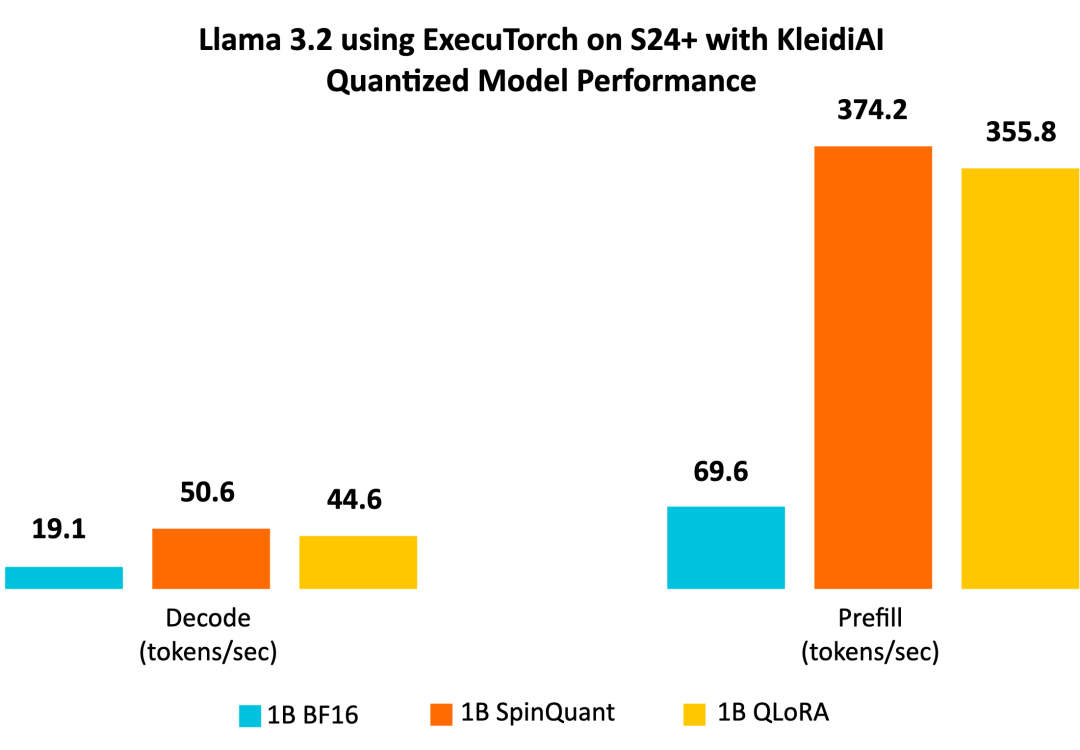
此外,量化模型的大小(以字节为单位的 PTE 文件大小)不到 BF16 模型的一半,前者为 1.1 GiB,后者为 2.3 GiB。虽然 INT4 的大小是 BF16 的四分之一,但是模型中的某些层是用 INT8 量化的,使得 PTE 文件大小比例增大。我们观察到,在最大序列长度为 2,048 时,在常驻内存集合大小 (RSS) 中测量,与 BF16 模型的 3.1 GiB 相比,SpinQuant 模型的运行时峰值内存占用减少近 40%,为 1.9 GiB。
通过全方位的提升,Llama 3.2 量化模型非常适合在 Arm CPU 上进行端侧部署。
KleidiAI 的影响
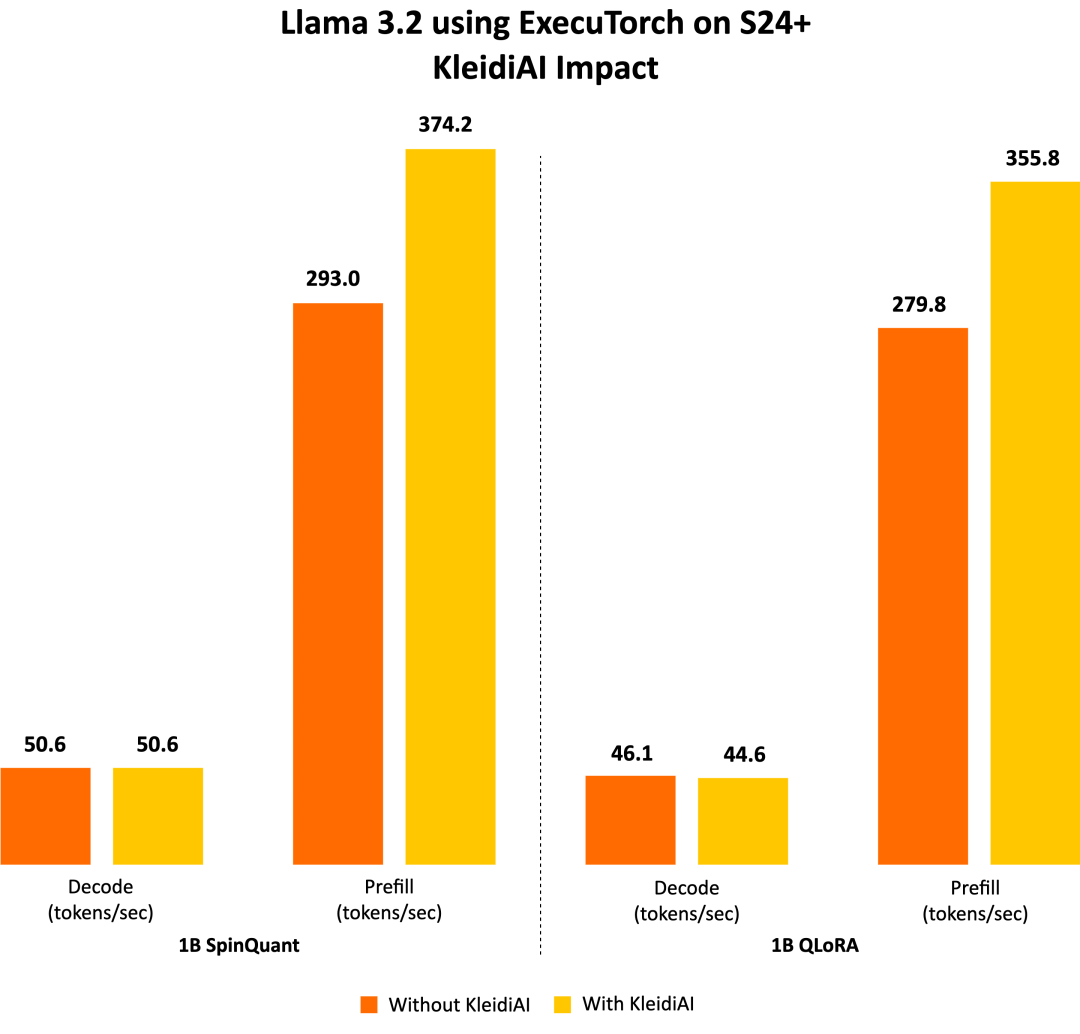
ExecuTorch 借助 KleidiAI 库,为具有先进 Armv8/Armv9 ISA 特性的新 Arm CPU 提供低比特高性能矩阵乘法内核。这些内核用于 ExecuTorch 中的端侧 Llama 3.2 量化模型推理。
为了评估 Kleidi 产生的影响,我们生成了两个针对 Cortex-A CPU 的 ExecuTorch 运行时二进制文件,并比较了它们的性能。第一个 ExecuTorch 运行时二进制文件通过 XNNPACK 库使用 KleidiAI 库构建。第二个二进制文件是在不使用 KleidiAI 库的情况下构建的,使用的是 XNNPACK 库中的原生内核。
如下图所示,与非 KleidiAI 内核相比,ExecuTorch 在 S24+ 上使用 KleidiAI 后,预填充性能平均提升了 20% 以上,同时保持相同的准确度。这种性能优势并不局限于特定的模型或设备,预计所有在 Arm CPU 上使用低比特量化矩阵乘法的 ExecuTorch 模型都将从中受益。
快来动手尝试吧!
准备好亲身体验性能改进了吗?在你的项目中试用 ExecuTorch 和 KleidiAI 提供的优化!访问 Arm Learning Paths,了解如何通过 ExecuTorch 和 KleidiAI 开发使用 LLM 的应用。
Arm Learning Paths:
https://learn.arm.com/learnin...
END
作者:Arm 工程部首席软件工程师 Gian Marco Iodice 及 Meta 公司 Digant Desai
文章来源:Arm社区
推荐阅读
- 加快 30 倍!Arm Kleidi 赋能端侧音频生成提速
- KleidiCV 更新详解!支持多线程,并实现 OpenCV 4.11 集成
- 如何在基于 Arm Neoverse 平台的 Kubernetes 集群上实现实时情绪分析
- Armv9 技术讲堂 | Arm A 系列架构 2024 进展
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区 Arm 技术专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

