
专用硬件可以显著加速应用程序。然而,设计专用硬件在人力和时间方面往往成本过高,使其仅适用于那些足够高产量以分摊这些成本的组件。
本文描述了一种利用可重构性来高效编译一类领域特定语言的方法。我们介绍了该方法、一个原型编译器,以及一个设计用于在 FPGA 上实现的 40Gb/秒网络处理器。

- https://users.ece.utexas.edu/...
- University of Texas at Austin
太长不看版
本文介绍了一种从领域特定语言(受限的 C 语言加上加速器功能)生成高效硬件的方法论,该方法论特别适用于具有显著数据并行性的应用。
文章提出了一个原型编译器,能够将用这种语言编写的应用程序转换为硬件,并以一个 40Gbps 的网络处理器 Magilla 作为案例研究,展示了该方法论的实际应用。Magilla 网络处理器能够处理 IPv4、IPv6 和 MPLS 数据包,其性能在模拟中达到了每秒 1 亿个数据包,且具有确定性性能和对抗恶意流量的弹性。
该方法论的优势在于能够利用 FPGA 的可重构性,实现高效、灵活的硬件设计,同时保持了软件编写的便利性。未来的工作包括在真实的 FPGA 平台上运行 Magilla 的一个子集,并将该方法论应用于其他领域。

本文目录
- 太长不看版
- 本文目录
- 介绍
- 方法论
- 2.1 代码
- 2.2 编译器输出
- 2.3 提高吞吐量
- 2.4 性能预测
- 2.5 高吞吐量功能单元
- 一个具体的例子:路由
- Magilla:一个 40Gbps 的网络处理器
- Magilla 的一个示例程序
- 验证过程
- 结论与未来工作
1. 介绍
在其他条件相同的情况下,为特定应用程序设计的专用硬件将胜过未针对该特定应用程序进行专门设计的硬件。专门化程度越高,带来的好处就越大。
然而,设计专用硬件的成本在人力和时间方面往往过高,使其仅适用于那些足够高产量以分摊这些成本的组件。此外,硬件的不可变性意味着应用程序的任何更改都可能使专用硬件过时。
在本文中,我们描述了一种从以稍微受限形式的 C 语言编写并调用一组固定加速器(功能单元)的应用程序生成高效硬件的方法。
该代码不需要任何特定于硬件的调整或注释,使其本质上与编写软件相同。
硬件是专门为应用程序生成的,因此不太可能有其他应用程序能在其上运行。然而,硬件是使用可重构逻辑实现的,特别是 FPGA,以实现应用程序的灵活性。该方法适用于广泛的应用,但在处理具有显著数据并行性的问题时特别有效,其中每个数据元素的处理可以在执行路径、计算时间和资源方面有所不同。
我们的原型应用是一个网络处理器,其吞吐量为 40Gbps(在 40 字节的数据包下每秒 1 亿个数据包),实现在一个中等大小的上一代 Xilinx Virtex 5TX240T FPGA 中。
这样的性能虽慢于 EZChip 和 Xelerated 今年宣布的最快基于 ASIC 的网络处理器(运行在 100Gbps),但与去年最先进的基于 ASIC 的网络处理器相当。使用大型现代 FPGA,我们的网络处理器至少应与最快的基于 ASIC 的网络处理器一样快。
我们所知的最快的并行化软件路由器在 32 个 Nehalem 核心(由四个系统组成,每个系统包含八个核心)上运行,速率为 12Gbps(每秒 2340 万个数据包)。
- 我们的解决方案支持单个 40Gbps 流量(40 字节的数据包),而软件版本仅支持四个 3Gbps 的流量,这是一个显著更简单的问题。
- 我们系统的可编程性使得适应新协议/算法变得相对容易。
- 我们的网络处理器还有其他优势,包括确定性性能和对抗恶意流量的弹性。
本文有三个贡献:
- 一种新颖的方法,使领域特定语言(稍微受限的 C 加上加速器功能)能够生成高效的硬件。
- 将用这种语言编写的应用程序转换为硬件的编译器。
- 一个案例研究,即使用该方法实现的 40Gbps 网络处理器,处理 IPv4、IPv6 和 MPLS 数据包。
2. 方法论
我们的方法论基于使用标准 C 语言编写的应用程序,这些程序调用用户定义的一组固定功能单元。这种方法与领域特定语言类似,后者为特定领域提供了专门的库。
程序员将执行其代码的机器视为一个具有并行功能单元的顺序机器,并相应地进行编码。代码被自动编译成可综合的 Verilog 代码,高效地实现该代码。反过来,Verilog 可以使用标准的商业工具编译为 FPGA 或 ASIC。
其中,功能单元封装了应用程序频繁执行的常见且昂贵的任务。例如,内容寻址存储器(CAM,一种可以根据存储内容进行快速查找的存储器)、Trie 查找(一种专门用于网络应用的指针追踪结构)、大量共享计数器,或向量乘法引擎可以被封装在一个功能单元中。用户期望提供硬件实现的功能单元。它们可以独立于应用程序代码进行优化以提高性能。数据元素之间的任何状态共享都通过功能单元进行。
我们的方法论能够容忍功能单元延迟的巨大变化而无需程序员付出努力。
2.1 代码
代码被结构化为指令序列,其中每个序列,包括分支,都被编写为处理单个数据元素。同时处理多个数据元素。提供了支持以确保在必要时按到达顺序完成数据元素的处理。每条指令包含对每个功能单元的最多一次调用、随机组合处理,以及确定下一条指令的计算。
一条指令不能依赖于在同一指令中执行的任何计算或功能单元调用,但可以访问所有以前指令生成的数据,以及通过在指令之间持续存在的变量处理的数据。只有在前一条指令完成,包括访问的所有功能单元的响应返回后,下一条指令才会被启用。
因此,
- 从软件的角度来看,这个系统类似于一个锁步的甚长指令字(VLIW,Very Long Instruction Word,一种处理器架构)架构。
- 然而,从硬件的角度来看,来自单条指令的不同功能单元调用在不同时间完成。提供了硬件以确保来自特定指令的所有功能单元调用在继续下一条指令之前已完成。
代码被我们的编译器自动编译成 Verilog 代码,该代码指定了实现代码所指定的应用程序的专用硬件“引擎”(图 1)。
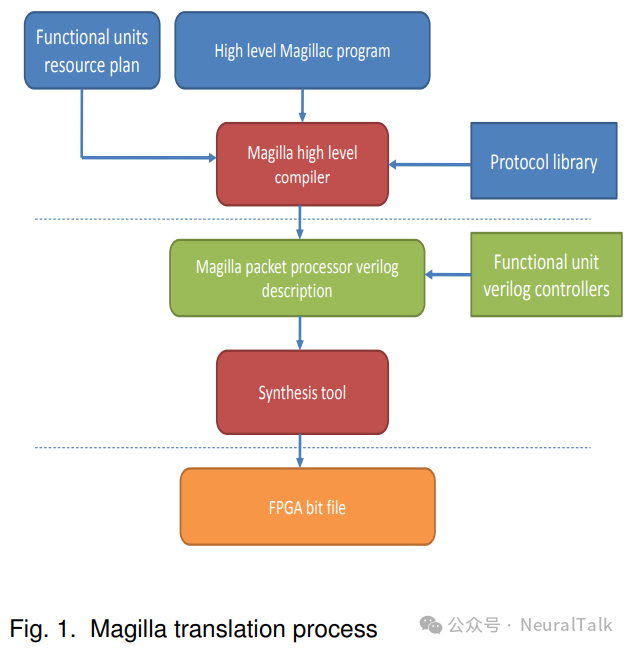
该编译器使用 ANTLR 工具编写。每个引擎执行一条指令,然后在功能单元
状态中等待,直到所有回复从所有在前一条指令中访问的功能单元返回。然后引擎根据每条指令中的显式跳转语句决定下一条指令。引擎包含专门的硬件,用于构建对功能单元的请求、处理功能单元的回复,并计算下一条指令。
引擎通过预先编写、可配置的基础设施连接在一起,该基础设施分发请求到功能单元,并收集从功能单元返回的结果,这些结果被写回到引擎可访问的状态。基础设施不特定于应用领域。假设功能单元是可用的,特定的应用领域将有其自己的功能单元集。
我们的方法与 C-to-gates 工作类似,例如 CatapultC 和 AutoESL,但在几个方面有所不同。C-to-gates 编译器通常被设计为支持任意 C 代码。然而,高质量的结果通常需要风格化的代码,有时包括特定于工具和特定于硬件的注释。我们的代码虽然不是完整的 C 代码,但遵循应用程序的自然流程,并且不需要特定于硬件的注释。
2.2 编译器输出
编译器为每条指令生成以下代码:
- 请求构建逻辑:请求构建逻辑计算功能单元请求参数
- 上下文编辑逻辑:上下文编辑逻辑使用功能单元的回复和以前指令更新的状态来更新全局变量
- 跳转逻辑:跳转逻辑根据当前指令中的计算结果确定下一条指令。逻辑在引擎状态机的适当状态中被激活。
2.3 提高吞吐量
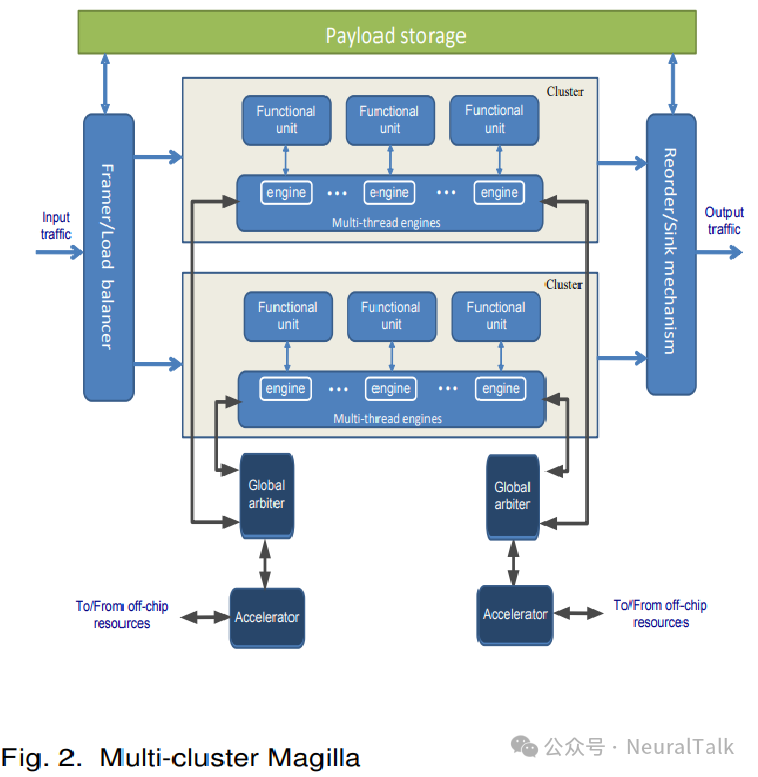
多个引擎允许我们提高数据包处理吞吐量。每个引擎可以访问仲裁逻辑,该逻辑分发请求到功能单元,并将回复返回给引擎。尽管使用多个引擎可以增加并行性,并帮助隐藏长延迟功能单元的延迟,但存在扩展问题。多个引擎消耗多套硬件资源。此外,在大量引擎之间进行仲裁并非易事。
为了更好地利用硬件资源,我们对引擎进行多线程处理。每个引擎支持多个硬件上下文,并切换线程以容忍功能单元的延迟。同一引擎中的所有线程使用相同的功能单元请求/回复接口。除了多个多线程引擎外,我们还将多个引擎组合成一个集群,并提供多个集群。一个单一集群共享数据包暂存存储器以提高这些宝贵资源的利用率。图 2 显示了一个具有两个集群的 Magilla 系统。
2.4 性能预测
这样一个系统的性能很容易预测,使得性能调优也很容易。性能由功能单元的吞吐量和应用程序对功能单元的需求定义。对于特定的应用程序,如果每个功能单元的动态吞吐量需求小于或等于功能单元的吞吐量,只要存在足够数量的数据元素可以并行处理,并且有足够的内部状态来保存这些数据元素和中间计算结果,就会实现全部性能。
如果功能单元的吞吐量不足,性能将受到瓶颈功能单元的限制。功能单元往往以每周期一个数据的吞吐量来实现,以消除混淆。因此,程序员只需确保可用的功能单元足以满足应用程序的需求和期望的性能。
2.5 高吞吐量功能单元
在FPGA 上实现的功能单元可以很容易地添加、移除或修改。功能单元的吞吐量可能是整个系统的限制因素。这是由于功能单元被多个处理引擎共享。
有几种常见的技术可以帮助提高功能单元的吞吐量。
- 更高的存储器频率:在许多情况下,功能单元不进行太多计算,但确实访问片上或片外存储器。由于通常可以以高于 FPGA 逻辑的频率运行存储器(片上和片外),提高存储器速度可以增加存储器带宽,通常导致更快的功能单元。
- 分行存储:在某些情况下,可以使用分行存储。例如,使用多个分行存储来增加数据包存储吞吐量。这种技术在下面描述的示例 IPv4 代码中被用来增加数据包存储吞吐量。
- 复制:如果资源可用,可以复制整个功能单元。例如,我们可能使用两个相同但独立的查找单元来将整体查找吞吐量翻倍。当然,如果查找单元使用片外存储器的话,我们需要有足够的 I/O 引脚和功能单元带宽进行这样的复制。
- 深度流水线:流水线在基于 Trie 数据结构的查找单元中被广泛使用。由于大多数片外存储器技术都是流水线的,这种技术允许我们使用高容量存储器系统,同时提供高吞吐量。深度流水线增加了功能单元的延迟,但也使功能单元能够以更高的频率运行。
3. 一个具体的例子:路由
路由是接收数据包、确定数据包类型、确定数据包应去往何处以及将数据包转发到该目的地的过程。路由器的可编程性一直被视为一个重要的目标,因为它使开发人员能够更轻松地实现新应用。新应用包括新协议、深度数据包检测、加密、测量和统计收集以及应用加速。
网络处理器是这种可编程性的重要组成部分。路由通常每数据包消耗数百条标准 RISC(精简指令集计算机,一种处理器类型)指令。例如,旨在支持 10Gb/秒的 Intel IXP2800 具有 16 个内核,运行在 1.4GHz,总指令预算为 22.4 BIPS(每秒十亿条指令),或大约每 40 字节数据包 900 条指令。思科 40Gbps 网络处理器包含 192 个定制的 500MHz Tensilica 内核,总指令预算为 96BIPS,或大约每 40 字节数据包 960 条指令。
如此高的指令数量源于每个数据包所需的众多位操作、数据包数据移动和片外访问数据。然而,即使有这样的高指令预算,也常常难以实现额定性能。当前的高端路由器每个接口处理数据包的速率为 40Gbps,这转化为假设 40 字节数据包则每秒超过 1 亿个数据包。
最近有几个项目为数据包处理系统增加了灵活性。
- 一个这样的项目是 Openflow,它将转发决策(控制平面)与转发本身(数据平面)分开。这种分离为开发人员提供了一些灵活性,但对路由器数据平面的完全可编程性支持很少。
- Routebricks 使用商用服务器和基于软件的路由器,通过四个各含 8 个内核的 Nehalem 服务器实现了 12Gbps 的路由吞吐量。他们使用了几种技术来提高单个服务器的转发能力,包括使用网卡的多队列特性以及数据包的批量处理。这些技术减少了与操作系统和商用服务器中通用硬件/软件包相关的每个数据包的处理开销。
- PacketShader 在一个包含两个四核 Nehalem 处理器、12GB 内存、两个 I/O 中心和两个 NVIDIA GTX480 显卡的系统上实现了 40Gbps 的性能。Packetshader 的性能依赖于智能网卡在内核之间平衡负载,目前受限于 PCIe 性能。这样的系统消耗相当多的电力,而路由器对电力非常敏感。
- 由于与 ASIC 相比开发时间更短,以及现代 FPGA 提供的资源(包括逻辑、存储器和高性能 I/O 资源),在路由器和其他通信平台中广泛使用 FPGA。NetFPGA 项目提供了用于数据包处理系统的硬件和软件基础设施,主要用于教育目的。NetFPGA 被成功用作各种网络应用的基础设施,证明了使用 FPGA 作为数据包处理系统的可编程基底的优越性。
4. Magilla:一个 40Gbps 的网络处理器
我们将我们的方法论应用于生成一个名为 Magilla 的网络处理器。我们的方法论能够为特定应用生成专用数据路径,同时支持高性能功能单元并容忍高度可变的延迟,这使得它非常适合网络处理器。
Magilla 的一个示例程序
在本节中,我们将介绍一个简化的 Magilla 程序,用于 IPv4 转发。该程序由五个 Magilla 指令组成:DISPATCH、ETHERNET、IP、IP CLASSIFY 和 EMIT。每个 Magilla 指令都以 C 风格的函数编写。每个 Magilla 程序的第一个指令都是 DISPATCH。
DISPATCH 假设数据包头已经复制并可在暂存存储器中访问。程序员通过访问暂存存储器来操作数据包数据,这里暂存存储器被组织为两个不同的功能单元 MEMX 和 MEMY。将此 C 风格程序转换为等效的 Verilog 代码的过程完全由我们的编译器自动化。
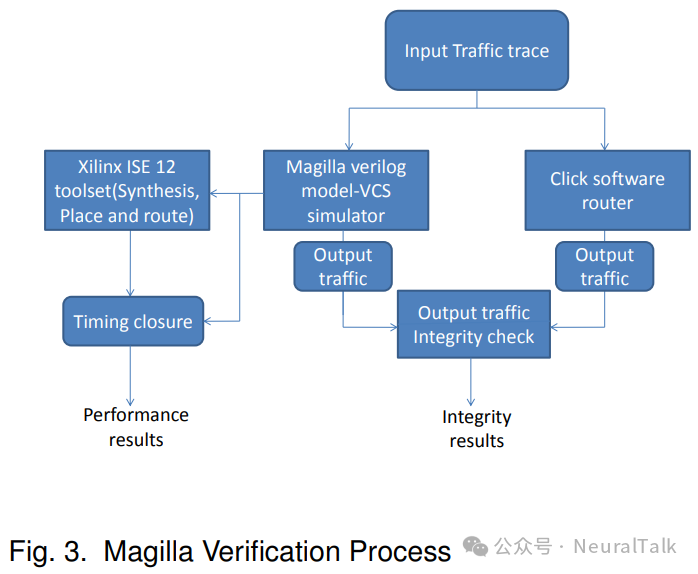
功能单元在程序开头使用 Pragma 指令指定。程序中的每条指令都包含对功能单元的多个 C 风格函数调用。在每条指令的末尾,我们有一个显式的跳转开关,指定下一条指令。为了验证我们路由器的功能,我们将 Magilla 的输出与 Click 软件路由器的输出逐包进行比较。我们使用了几个 Equinix-Chicago CAIDA 流量转储作为输入流量,分别输入到 Magilla 和 Click 路由器中。为了测量性能,我们从 CAIDA 流量跟踪中仅提取最小尺寸的数据包,并将它们用作验证过程的输入。图 3 显示了 Magilla 的验证过程。
#include"Packet.mag"
#include"ETHERNET.mag"
#include"IP.mag"
#pragmaNP_functional_unit(MEMX)
#pragmaNP_functional_unit(MEMY)
#pragmaNP_functional_unit(LOOKUPX)
#pragmaNP_functional_unit(LOOKUPY)
bit_vector PP[20];
bit_vector Da[32], Sa[32];
bit_vector Daport[8], Saport[8];
bit_vector Chksum[16];
bit_vector Packet_status[32];
bit_vector Rpd_status[8];
bit_vector Packet_size[16];
instr_addr_tNP_INSTR_DISPATCH(){
l2protocol_tl2protocol;
// Rbb和Rbi是数据包接收缓冲区的基址和索引
PP = MEMX.read(Rbb + Rbi);
Packet_status = MEMY.read(Rbb + Rbi);
// 提取第二层协议、数据包状态和数据包大小
l2protocol = Packet_status.L2PROTOCOL;
Rpd_status = Packet_status.RPD_STATUS;
Packet_size = Packet_status.PACKET_SIZE;
// 根据数据包的第二层协议跳转到适当的指令
NP_switch (l2protocol) {
casePPP: NP_INSTR_PPP;
caseETHERNET: NP_INSTR_ETHERNET;
default: NP_INSTR_EXCEPTION;
}
}
instr_addr_tNP_INSTR_ETHERNET(){
l3protocol_tl3protocol;
protocol_twordy;
// 提取第三层协议
wordy = MEMY.read(PP, ETHERNET_L3PROTOCOL_WORD);
l3protocol = wordy.L3protocol;
// 根据数据包的第三层协议跳转到适当的指令
NP_switch (l3protocol) {
caseIP: NP_INSTR_IP_ADDR;
default: NP_INSTR_EXCEPTION;
}
}
instr_addr_tNP_INSTR_IP(){
protocol_twordx;
protocol_twordy;
// 提取目的和源IP地址
wordx = MEMX.read(PP, ETHERNET_IP_DA_WORD);
wordy = MEMY.read(PP, ETHERNET_IP_SA_WORD);
Da = wordx.D_address;
Sa = wordy.S_address;
NP_switch () {
default: NP_INSTR_IP_CLASSIFY;
}
}
instr_addr_tNP_INSTR_IP_CLASSIFY(){
protocol_twordx;
packet_metadata_twordy;
router_port_tDa, Sa;
Daport = LOOKUPX.search(Da);
Saport = LOOKUPY.search(Sa);
wordx = MEMX.read(PP, ETHERNET_IP_TTL_WORD);
MEMY.write(Rbb + Rbi, STATUS_WORD) = Packet_status & RPB_AVAILABLE_MASK;
// 提取数据包的生存时间和校验和
Ttl = wordx.TTL;
Chksum = wordx.CHKSUM;
Status = OK;
if(NOT_VALID_ADDRESS(Daport)) Status = INVALID_D_ADDRESS;
if(NOT_VALID_ADDRESS(Saport)) Status = INVALID_S_ADDRESS;
NP_switch (Status) {
caseOK: NP_INSTR_EMIT;
default: NP_INSTR_EXCEPTION_ADDR;
}
}
instr_addr_tNP_INSTR_EMIT(){
protocol_tTtlword;
// 更新生存时间和校验和
Ttl = Ttl -1;
Chksum = Chksum +0x0100;
Chksum = Chksum +100;
Ttlword = {Ttl, Ttlword[23:16], Chksum[7:0], Chksum[15:8]};
// Fbb和Fbi是数据包转发缓冲区的基址和索引
MEMX.write(PP, ETHERNET_IP_TTL_WORD) = Ttlword;
MEMY.write(Fbb + Fbi) = {FPB_TAKEN, Dport, Packet_status[23:0]};
NP_switch (Status) {
default: NP_INSTR_DISPATCH_ADDR;
}
}
验证过程
为了验证 Magilla 的功能,我们将 Magilla 的输出与 Click 软件路由器的输出逐包进行比较。我们使用了几个 Equinix-Chicago CAIDA 流量转储作为输入流量,分别输入到 Magilla 和 Click 路由器中。为了测量性能,我们从 CAIDA 流量跟踪中仅提取最小尺寸的数据包,并将它们用作验证过程的输入。图 3 显示了 Magilla 的验证过程。
5. 结论与未来工作
在本文中,我们描述了一种从用领域特定语言编写的应用程序生成专用硬件的方法论。我们相信该方法论可以应用于广泛的应用领域。我们已经开发了一个能够接受高层应用程序作为输入并生成可综合 Verilog 代码的编译器。
我们已经编写了一个网络处理应用,并使用该编译器对其进行了编译。我们仍在生成实验结果的过程中。我们已经能够生成一个版本的网络处理器,该处理器在模拟中实现了每秒 1 亿个数据包的处理速度,占用了大约 85%的 Virtex 5 TX240T FPGA 资源,包括功能单元。
我们选择该 FPGA 是因为它是在最新 NetFPGA 板上使用的,并且是一个处于性能曲线拐点的 FPGA,而不是可用的最大 FPGA。该实现的数据包 I/O 接口不符合所选 FPGA 的引脚预算,但这是因为我们尚未整合 Xilinx 多千兆收发器(GTX)模块,该模块将提供从帧处理器接收数据包并发送到流量管理器的能力。
我们的结果是通过将 Magilla 源代码使用我们的编译器编译为 Verilog 代码,然后通过 Xilinx 综合和布局布线(ISE 10.3)工具,并使用布局布线信息来确定性能。我们计划在一个真实的 FPGA 平台上运行 Magilla 的一个子集(我们尚未获得具有适当接口的 FPGA 板)。然后,我们计划使用相同的方法论在其他领域实现应用。
END
作者:Maysam Lavasani
来源:NeuralTalk
推荐阅读
- Strong-Baseline架构,无特征增强问鼎反无人机挑战赛
- Tensor-001 矩阵乘法分块乘法概述
- 高分辨率特征+多分支交互注意力,先验增强攻克噪声模糊,3个数据集mAP全面领跑
- DeepSeek-V3+SGLang: 推理优化
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区嵌入式AI专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

