
❝ 随着深度神经网络的快速发展,加速器设计对于人工智能应用的部署来说是一个非常重要的问题,尤其是在边缘计算方面。本文提出了一种用于基于指令的卷积神经网络(CNN)加速器设计的通用编译器设计。我们的编译器整合了网络剪枝和量化能力以实现更好的性能。
基于控制数据流图(CDFG,即 Control and Data Flow Graph,一种用于表示神经网络计算流程的图结构)的层融合和调度被用于异构计算,同时考虑了 CPU 和加速器之间的数据转换和同步。我们使用设备文件来定义指令集和数据空间,以便我们的编译器能够统一支持各种加速器设计。我们的编译器在 FPGA(现场可编程门阵列,一种可编程的硬件设备)上实现了 VGG16 和 YOLOv2,并且取得了比现有设计更好的性能。


一、引言
❝ 深度神经网络在图像识别和目标检测方面取得了显著进展。然而,部署和加速器设计主要是手工工作,这非常耗时,尤其是考虑到卷积神经网络(CNN)算法的快速发展和变化。除了硬件设计,网络剪枝和量化也被提出用于性能增强。
本文提出了一种用于基于指令的卷积神经网络计算的通用编译器设计。设备配置文件用于指定特征图和权重数据的指令集和数据存储空间。基于分组的网络剪枝算法和量化算法被整合到我们的编译器中,以提供更高效的加速器设计支持。我们的编译器在 Xilinx ZCU104 FPGA 上实现了 YOLOv2,并且取得了约 832 GOPs(每秒 8320 亿次操作,一种衡量计算性能的单位)的性能,这比现有的先进设计[12]大约提高了 8 倍。
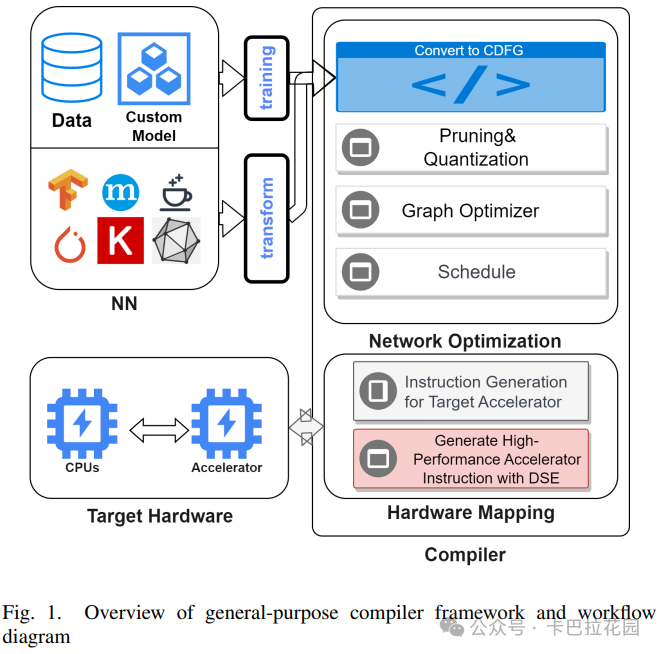
二、框架概述
我们编译器的整体架构如上面图 1 所示。编译器由两个组件组成:
- 第一个组件执行网络剪枝、量化、层操作和计算调度。
- 第二个组件负责根据设备配置生成指令。
编译器使用流行的控制数据流图(CDFG)来表示神经网络。基于训练的网络剪枝是在 Caffe[13]的基础上实现的。基于 Google 白皮书[9]的动态量化也被实现在我们的编译器中。
此外,我们的编译器还支持 CPU 和硬件加速器的异构计算。为了泛化支持各种加速器设计,我们使用设备配置文件来描述特征图和权重的指令集和数据空间。
设计了一种调度算法,用于在 CPU 节点和硬件节点之间对 CDFG 节点进行分区,对所有层进行计算调度和数据空间分配。
在接下来的两个部分中,我们将介绍我们的网络优化和指令生成方法的细节。
三、网络优化
A. 网络剪枝和量化
❝ 网络剪枝已被证明是一种用于性能增强的有效优化方法。在我们的编译器中,我们使用了基于分组的剪枝算法[8],以简化加速器设计。根据[8],我们将分组大小设置为 32,稀疏率设置为 75%。尽管我们注意到对于 YOLOv2,90%的稀疏率也能获得良好的精度,但我们认为如此高的稀疏率会对数据选择逻辑设计和总线带宽施加压力,并且在一般情况下并非必要。
我们在编译器中实现了两种量化方法:基于 Google 白皮书[9]的动态量化和基于训练的量化。默认情况下,我们将量化位宽设置为 8 位。
B. 层优化和计算调度
由于大多数加速器设计将卷积、激活和池化操作流水线化,我们的编译器也执行层融合,将卷积、激活和池化层合并为一个所谓的“大卷积”层。图 3(a)(b)(c)展示了我们的编译器支持的层优化。
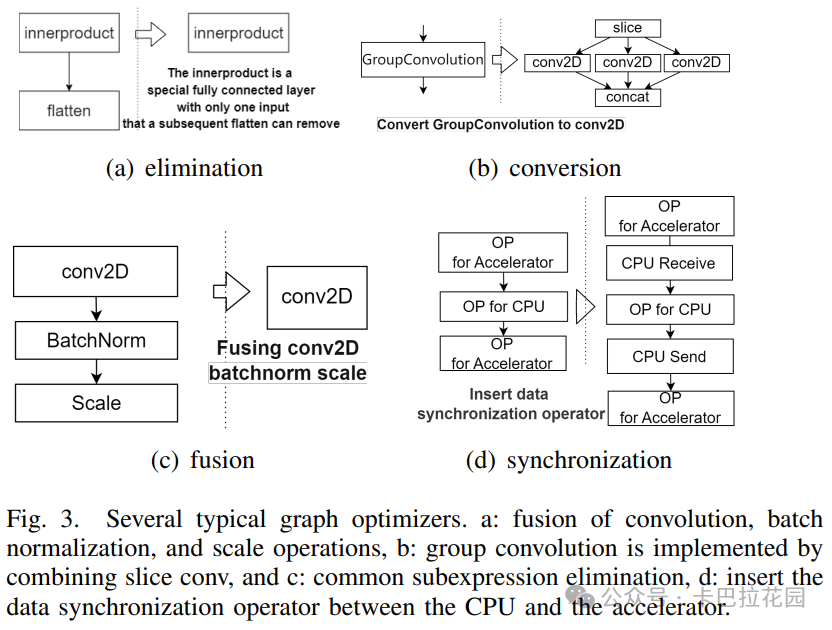

我们的调度算法(如下图算法 1 所示)将根据节点类型和硬件上的加速效果,将优化后的 CDFG 中的操作划分为 CPU 计算和硬件计算。

数据转换的成本也被考虑在内,一个调度结果如图 3(d)所示。除了计算调度外,我们的编译器还将为所有指令执行数据调度和数据空间分配(如下图算法 2 所示)。我们采用双端内存管理机制来管理输入和输出数据的存储地址。在内存分配过程中,输入特征图和输出特征图应该分布在两侧。

对于这样一组输出特征图,还应该有一个内部顺序。首先释放的特征图应该放置在靠近中间的未分配空白内存区域,最后释放的特征图应该放置在边缘,如下图 2 所示。
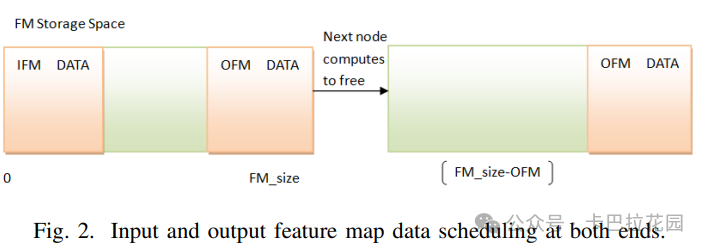
双端调度算法的详细流程如下:
- 步骤 1:根据每一层的维度和权重文件格式,计算权重和地址索引数据文件所需的存储空间,并将 DDR 存储空间的第一部分固定分配 给该文件。
- 步骤 2:遍历所有层的输入特征图数据(IFM)和输出特征图数据(OFM)的存储空间总和。将最大值设置为当前特征图存储空间 (Feature_Map_Size)。如果遇到分支结构,则优先计算空间较小的分支,以确保其他分支有足够的存储空间,最终确定内存空间分配大小。
- 步骤 3:根据确定的特征图数据存储空间大小,进行双端调度。
调度完成后,我们的编译器将为 CPU 计算生成 C 程序,并为硬件执行生成二进制代码。加速器设计的 RTL(寄存器传输级,一种硬件描述语言)将与二进制代码一起综合,形成一个比特流,下载到 FPGA 上。数据转换指令通过 PCIE 和 AXI4 总线接口的支持来实现。
四、指令生成
A. 指令定义
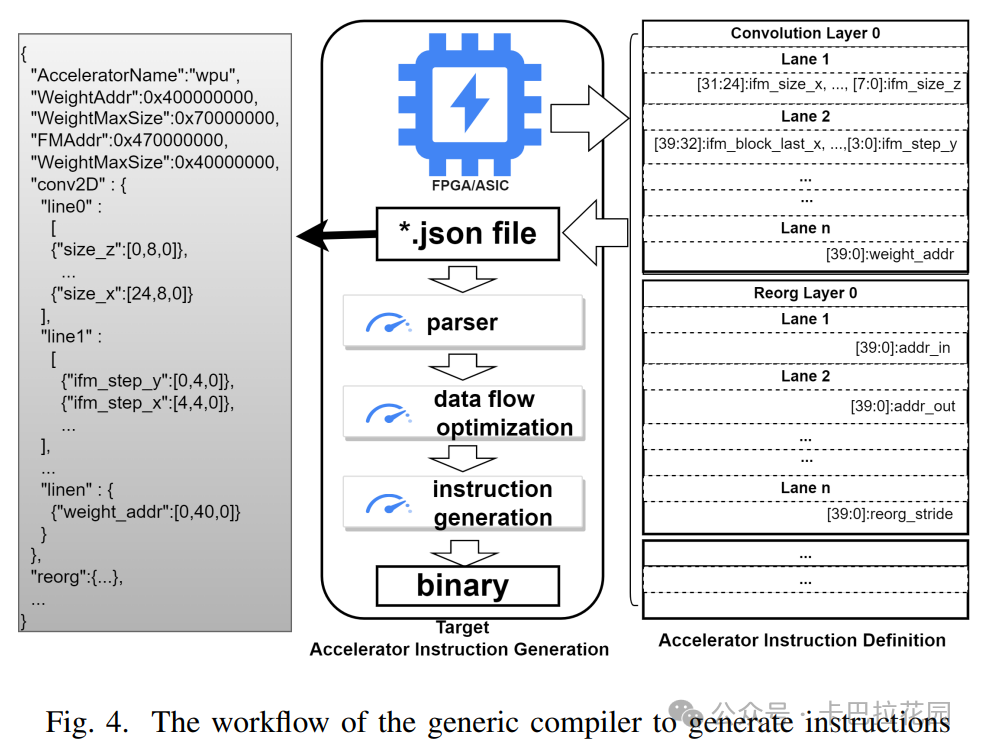
我们的指令集包括大卷积指令、连接(concat)、重组(reorg)和层减法。我们的大卷积指令可以配置为一起或单独计算卷积、ReLU 和池化。conv2D、concat 和 reorg 的定义如代码 1 所示。
conv2D : ifm_addr, weight_addr, ofm_addr, ifm_c, ifm_h, ifm_w, k_x, k_y, stride_x, stride_y, pad_t, pad_b, pad_r, pad_l, relu_en, pooling_en, <pooling_type, p_h, p_w, p_stride_x, p_stride_y, p_pad_t, p_pad_b, p_pad_r, p_pad_l, fm_bitwidth, fl_in, fl_out, ...>;
concat : ifm_addr1, ifm_addr2, ofm_addr, ifm1_c, ifm1_h, ifm1_w, ifm2_c, ifm2_h, ifm2_w, axis;
reorg : ifm_addr, ofm_addr, ifm_c, ifm_h, ifm_w, stride;
为了支持各种加速器设计,我们定义了一个全面的硬件指令集,包括主流加速器指令所需的所有参数。具体来说,加速器所需的参数格式可能会略有不同,因此我们还提供了一个 JSON 模板,如下图 4 所示。用户只需要根据模板格式描述相应的指令参数。编译器最终会根据自定义格式生成指令、权重数据以及相应的 CPU 控制程序,以便加速器能够识别。
B. 数据流优化
❝ 一般来说,加速器通常需要根据某些规则缓存权重和特征图数据,缓存数据的大小受到缓存单元设计的限制。数据缓存和计算被组织成流水线。以卷积为例,卷积操作涉及两个阶段:权重和特征图数据的传输以及卷积计算。
我们的编译器根据外部内存带宽和计算时间调整每次缓存的数据大小。这确保了数据传输和计算的重叠,最大化加速器的运行效率。

对于连续的图像处理任务,我们在CPU 端采用多线程技术来优化数据流。一个线程专门用于数据预处理,而另一个线程负责将数据传输到加速器。这种设置创建了一个三阶段流水线,用于数据预处理、传输和计算,从而提高了处理多幅图像的性能。
五、实验结果
为了验证我们编译器的有效性,我们在 YOLOv2 和 VGG16 上测试了我们的编译器。目标 FPGA 设备分别是 Xilinx ZCU104 和 ZC706。
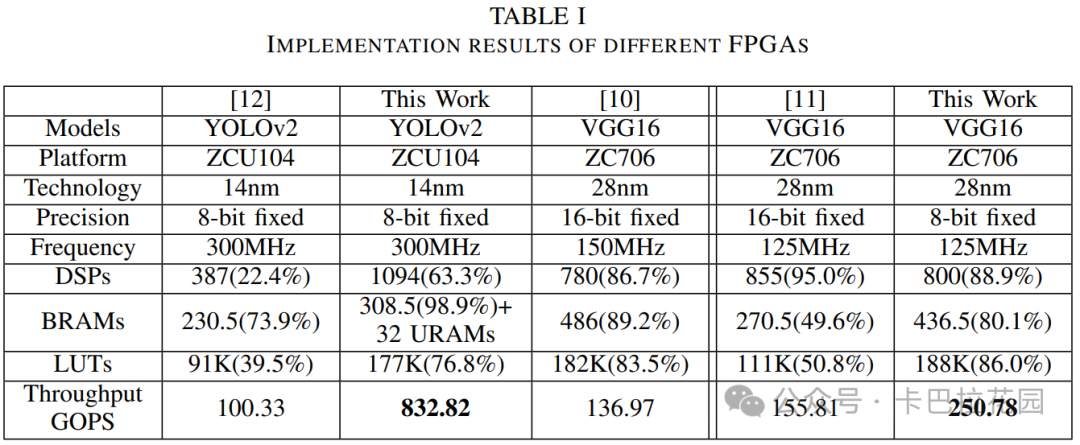
我们在表 I 中列出了我们的实现细节和性能数据,并与现有的先进 CNN 设计[10]–[12]进行了比较。结果显示,我们的自动生成解决方案比现有方法具有高达 8 倍的性能优势。这清楚地展示了我们自动网络优化和编译技术的优越性。
六、结论
本文介绍了一种用于基于指令的神经网络加速器设计的编译器。它包括各种优化和调度技术,用于自动化指令生成和性能提升。测试结果证明了我们自动网络优化和编译技术的优越性。
参考文献
- B. Yang, J. Lyu, S. Zhang, Y. Qi, and J. Xin, Channel Pruning for Deep Neural Networks Via a Relaxed Groupwise Splitting Method, in 2019 Second International Conference on Artificial Intelligence for Industries (AI4I), Sep. 2019, pp. 9798.
- C. L. Kuo, E. E. Kuruoglu, and W. K. V. Chan, Neural Network Structure Optimization by Simulated Annealing, Entropy, vol. 24, no. 3, Art. no. 3, Mar. 2022.
- J. CHENG, P. WANG, G. LI, Q. HU, and H. LU, Recent advances in efficient computation of deep convolutional neural networks, Frontiers of Information Technology & Electronic Engineering, vol. 19, no. 01, pp. 6477, 2018.
- S. Han, J. Pool, J. Tran, and W. J. Dally, Learning both Weights and Connections for Efficient Neural Networks. arXiv, Oct. 30, 2015. doi: 10.48550/arXiv.1506.02626.
- S. Han, H. Mao, and W. J. Dally, Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv, Feb. 15, 2016.
- P. Gysel, J. Pimentel, M. Motamedi, and S. Ghiasi, Ristretto: A Framework for Empirical Study of Resource-Efficient Inference in Convolutional Neural Networks, IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 11, pp. 57845789, Nov. 2018.
- S. Shin, K. Hwang, and W. Sung, Fixed-Point Performance Analysis of Recurrent Neural Networks, IEEE Signal Process. Mag., vol. 32, no. 4, pp. 158158, Jul. 2015.
- W. You and C. Wu, RSNN: A Software/Hardware Co-optimized Framework for Sparse Convolutional Neural Networks on FPGAs, IEEE Access, vol. PP, pp. 11, Dec. 2020.
- R. Krishnamoorthi, Quantizing deep convolutional networks for efficient inference: A whitepaper, arXiv, arXiv:1806.08342, Jun. 2018.
- J. Qiu et al., Going Deeper with Embedded FPGA Platform for Convolutional Neural Network, in Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, in FPGA 16. New York, NY, USA: Association for Computing Machinery, 2016, pp. 2635.
- S. I. Venieris and C. S. Bouganis, FpgaConvNet: Mapping Regular and Irregular Convolutional Neural Networks on FPGAs, IEEE Transactions on Neural Networks and Learning Systems, 2019.
- Z. Zhang, M. A. P. Mahmud, and A. Z. Kouzani, Resource-constrained FPGA implementation of YOLOv2, Neural Comput & Applic, vol. 34, no. 19, pp. 1698917006, Oct. 2022.
- Y. Jia et al., Caffe: Convolutional Architecture for Fast Feature Embedding, in Proceedings of the 22nd ACM international conference on Multimedia, in MM 14. New York, NY, USA: Association for Computing Machinery, 2014, pp. 675678.
END
作者:Fudan University
来源:卡巴拉花园
推荐阅读
- LLM技术报告系列 | Google团队正式放出Gemma 3技术报告
- CARL2010:一种利用领域特定语言可重构性的方法论
- Strong-Baseline架构,无特征增强问鼎反无人机挑战赛
- Tensor-001 矩阵乘法分块乘法概述
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区嵌入式AI专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

