
随着大语言模型的快速发展,如何在不消耗大量计算资源的情况下优化模型性能成为业界关注焦点。模型权重合并技术提供了一种零训练成本的高效解决方案,能够智能整合多个专业微调模型的优势,无需额外训练即可显著提升性能表现。本文系统剖析 11 种前沿权重合并策略的理论基础与数学原理,从简单的线性插值到复杂的几何映射方法,并通过开源工具 MergeKit 提供详细的实战配置示例。无论您是 AI 研究人员寻求最优参数组合,企业开发者追求成本效益的模型优化方案,还是对 LLM 内部机制感兴趣的技术爱好者,本文都将为您提供全面且实用的技术指南,助您在资源受限条件下实现大语言模型的高效优化与融合。

1、线性权重平均:Model Soup
Model Soup 技术基于一个简洁而有效的思想:对多个微调模型的权重进行加权平均。该方法的核心假设是,从相同预训练骨干网络(针对相关任务或领域)微调的模型在参数空间中处于"连通"区域,因此它们的线性组合可以产生具有更强泛化能力的模型。
对于一组模型,给定一组非负系数 (α₁, α₂, …, αₙ),且这些系数的总和为 1,合并后的模型可表示为: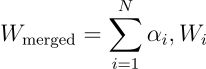
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
models:
- model: meta-llama/Llama-3.1-8B-Instruct
parameters:
weight: 0.5
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.15
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.35
merge_method: linear
dtype: float162、Spherical Linear Interpolation - SLERP
SLERP 方法在归一化权重向量球面上的大圆弧上执行插值计算。与直线(欧几里得)插值不同,它保留了向量间的角度关系。当权重向量经过归一化处理时,这一特性尤为重要,能够确保插值生成的模型仍然"保持在流形上"。
对于两个权重向量 (a) 和 (b) 以及插值参数 (t∈[0,1]),SLERP 的计算公式为: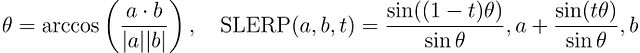
参数配置
- t (插值因子) — 控制在两个模型之间大圆弧上的插值位置
models:
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
merge_method: slerp
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
t: 0.5
dtype: float163、近邻交换 (Nearswap)
Nearswap 技术旨在识别并利用参数空间中两个模型在"接近"(即相似度高)区域的特性进行合并。该方法首先对模型参数(或层)进行分区处理,然后仅对差异值在指定阈值范围内的参数执行"交换"或平均操作。
其实现过程包括:
计算距离: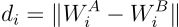
基于阈值 τ 执行参数合并: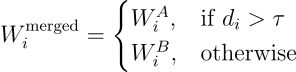
参数配置
- t (相似度阈值) — 定义参数被视为"接近"并符合交换条件的距离阈值
models:
- model: meta-llama/Llama-3.1-8B-Instruct
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
merge_method: nearswap
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
t: 0.5
dtype: float164、任务算术 (Task Arithmetic)
任务算术技术基于一个关键见解:模型参数通常会编码与特定任务相关的"方向性信息"。通过减去共同(共享)表示并添加特定于任务的组件,可以构建出能更有效执行复合任务的模型。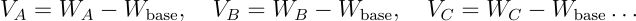
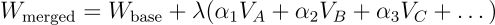
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.3
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.7
merge_method: task_arithmetic
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
lambda: 0.5
dtype: float165、修剪、选择符号和合并 (TIES-Merging)
TIES-MERGING 算法通过三步处理流程解决了合并多个特定任务模型时的参数干扰问题:修剪、选择符号和不相交合并。该方法旨在创建一个有效整合各个特定任务模型知识的合并模型,同时减轻冲突参数更新的负面影响。
具体实现步骤:
- 对每个任务向量,保留幅度最高的前 k% 参数,并将其余(底部 (100−k)%)置零,形成修剪后的任务向量。
- 对每个参数位置,计算所有修剪后任务向量中正负符号的总幅度,将具有较大总幅度的符号分配给合并模型的符号向量。
- 对每个参数,定义一个包含修剪后任务向量中符号与所选符号一致的任务索引集合,通过求取参数均值计算不相交平均值。
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- density (k) — 与基础模型差异中需保留的权重比例
models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.3
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.7
merge_method: ties
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
lambda: 0.5
density: 0.7
dtype: float166、丢弃和重新缩放 (DARE)
DARE(丢弃和重新缩放)算法旨在减少大型语言模型增量参数(从预训练到微调的变化)中的冗余信息。该方法随机将一部分增量参数置零,并将剩余参数按 1/(1-p) 倍重新缩放,其中 p 表示丢弃率,然后将处理后的参数加回预训练参数中。
实现流程:
- 给定预训练模型(权重为 W_PRE)和针对任务 t 微调的模型(权重为 W_SFT_t),计算增量参数 Δ_t。
- 使用伯努利分布,随机将 p 比例的增量参数置零。对 Δ_t 中的每个元素,从 Bernoulli(p) 抽取随机变量 m_t。
- 将保留的非零增量参数按因子 1/(1−p) 进行重新缩放,以补偿丢弃值造成的影响。
- 最后,将重新缩放的增量参数 Δ̂_t 加回预训练权重 W_PRE,得到 DARE 适应后的权重 W_DARE_t。
DARE 技术可以与 TIES 的符号共识算法结合使用 (dare_ties),也可以独立使用 (dare_linear)。
参数配置 (dare_ties)
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- density (k) — 与基础模型差异中需保留的权重比例
models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.3
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.7
merge_method: dare_ties
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
lambda: 0.5
density: 0.7
dtype: float16参数配置 (dare_linear)
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.3
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.7
merge_method: dare_linear
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
lambda: 0.5
dtype: float167、Model Breadcrumbs
Model Breadcrumbs 是任务算术的扩展技术,它通过丢弃与基础模型差异中既小又极大的部分来优化合并效果。该算法可以与 TIES 的符号共识算法结合使用 (breadcrumbs_ties),也可以独立使用 (breadcrumbs)。
实现过程包括四个主要步骤:
- 任务向量创建:对于每个针对特定任务微调的模型,计算其权重与原始预训练基础模型权重之间的差异,构成任务向量。
- 异常值和可忽略扰动移除:定义两个百分比阈值,β(左尾)和 γ(右尾)。在每层排序权重中屏蔽(置零)底部 β% 和顶部 (100-γ)% 的权重,以消除大异常值和可忽略扰动。
- 组合任务向量:通过求和聚合所有任务的屏蔽任务向量。
- 缩放与整合:将聚合后的任务向量按强度参数 (α) 缩放,然后添加至原始预训练模型的权重中。
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- density — 与基础模型差异中需保留的权重比例
- gamma — 要移除的最大幅度差异的比例
注意:gamma 参数对应论文中描述的参数 β,而 density 表示稀疏化张量的最终密度(通过 density = 1−γ−β 与 γ 和 β 相关)。
models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.3
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.7
merge_method: breadcrumbs
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
lambda: 0.5
density: 0.9
gamma: 0.01
dtype: float16 models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.3
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.7
merge_method: breadcrumbs_ties
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
lambda: 0.5
density: 0.9
gamma: 0.01
dtype: float168、Model Stock
Model Stock 算法提供了一种经济高效的权重合并方法,旨在通过使用预训练模型作为锚点和少量微调模型来近似权重分布的中心 (μ),从而提高模型性能。该技术利用权重向量的几何特性,特别是各向量间的角度关系,来确定最佳合并比例。
主要实现步骤:
- 平面定义:使用预训练模型的权重向量 (w0) 和两个微调模型的权重向量 (w1 和 w2) 定义一个平面,该平面构成了合并权重的搜索空间。
- 垂足计算:算法寻找该平面上最接近权重分布中心 (μ) 的点 (wH),即 μ 到该平面的垂足。
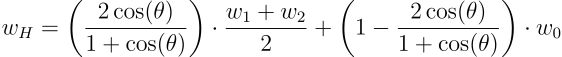
其中:
- θ 表示两个微调模型权重向量(w1 和 w2)之间的角度
- wH 表示合并后的权重向量
- w0 表示预训练模型的权重向量
- (w1 + w2)/2 表示两个微调权重向量的平均值,对应原文中的 w12
- 插值比例计算:插值比例 t = 2 * cos(θ) / (1 + cos(θ)) 决定了平均微调权重与预训练权重对合并权重的贡献比例。该比例仅取决于角度 θ,角度越小,对预训练模型的依赖性越低。
- 扩展到 N 个微调模型:
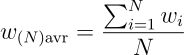
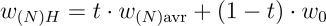
其中 t = N cos(θ) / (1 + (N−1) cos(θ)),θ 表示预训练模型与 N 个微调模型之间的角度,w(N)H 表示合并后的权重向量。
参数配置
- filter_wise:若设为 true,权重计算将按行而非按张量进行(不推荐)
models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
merge_method: model_stock
base_model: meta-llama/Llama-3.1-8B-Instruct
dtype: float169、归一化球面线性插值 (NuSLERP)
NuSLERP 通过在执行插值前显式归一化权重向量,对标准 SLERP 方法进行了改进。当模型使用不同缩放系数进行训练时(例如,由于自适应归一化层),这种"归一化"版本尤为有用,可避免插值过程中混合不兼容的尺度问题。
参数配置
- weight:指定张量的相对权重
- nuslerp_flatten:设为 false 可执行逐行/逐列插值,而非将张量作为整体向量处理
- nuslerp_row_wise:对行向量而非列向量应用 SLERP 算法
models:
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.5
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.5
merge_method: nuslerp
base_model: meta-llama/Llama-3.1-8B-Instruct
dtype: float1610、通过幅度采样进行丢弃和重新缩放 (DELLA)
DELLA 方法可以与 TIES 的符号选择步骤结合使用 (della),也可以独立使用 (della_linear)。该方法包含以下核心步骤:
丢弃 (Drop):采用基于幅度的创新修剪方法 MAGPRUNE:
- 根据神经网络中每个节点增量参数的幅度(绝对值)进行排序
- 为每个参数分配一个与其幅度成反比的丢弃概率 (Pd),幅度较大的参数被丢弃的概率较低,由超参数 ∆ 控制概率步长
- 超参数 'p' 控制平均丢弃概率,'ϵ' 影响最小丢弃概率 (pmin = p−ϵ/2)
- 根据分配的概率随机丢弃增量参数,丢弃的参数被置零
- 将剩余(未丢弃)的增量参数重新缩放 1/(1−pi),其中 pi 是第 i 个参数的丢弃概率,以补偿丢弃参数的影响,确保模型输出嵌入得以保留
选择 (Elect):通过计算所有专家对应增量参数之和的符号,确定每个参数位置的主导方向,仅选择与主导方向符号相同的增量参数。
融合 (Fuse):计算每个位置选定增量参数的平均值。
获取合并模型:将融合后的增量参数(按因子 λ 缩放)添加到基础模型的参数中。
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- density — 与基础模型差异中要保留的权重比例
- epsilon — 基于幅度的丢弃概率的最大变化范围。分配的丢弃概率将在 density−epsilon 到 density+epsilon 的范围内变化(选择 density 和 epsilon 值时,请确保概率范围在 0 到 1 之内)
models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.3
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.7
merge_method: della
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
lambda: 0.5
density: 0.7
epsilon: 0.01
dtype: float16 models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.3
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.7
merge_method: della_linear
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
lambda: 0.5
density: 0.7
epsilon: 0.01
dtype: float1611、选择、计算和擦除 (SCE)
SCE(选择、计算、擦除)是一种用于合并多个目标 LLM 的技术,这些 LLM 共享相同的架构和规模,但已使用来自不同源 LLM 的知识分别进行了微调。该方法作用于"融合向量",即表示枢轴 LLM 和每个目标 LLM 在成对知识融合阶段后的权重差异。
实现过程包含以下四个步骤:
- 对于融合向量集中的每个参数矩阵,选择在不同目标 LLM 之间具有最高方差的前 k% 元素。
- 对于每个参数矩阵,计算每个目标 LLM 的合并系数,即其对应过滤融合向量中所选元素的平方和,并按该矩阵所有目标 LLM 的总平方和进行归一化。
- 对于过滤融合向量中的每个参数,对所有目标 LLM 的值求和。如果给定参数的和为正(或负),则将该参数的所有负(或正)值置零,以消除冲突的更新方向。
- SCE 处理后,最终合并 LLM 的参数矩阵通过任务算术方法计算得出。
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- select_topk — 要保留的增量参数中具有最高方差的元素比例
models:
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
weight: 0.3
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
parameters:
weight: 0.7
merge_method: sce
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
lambda: 0.5
select_topk: 0.7
dtype: float16总结
本文系统介绍了 11 种先进的 LLM 权重合并策略,从简单的线性权重平均到复杂的几何映射方法,全面揭示了如何在零训练成本下优化大语言模型性能。这些方法各具特色:Model Soup 通过简单加权平均实现模型融合;SLERP 保持角度关系确保插值质量;任务算术聚焦方向性信息;TIES-Merging 通过修剪减轻参数干扰;Model Stock 利用几何特性寻找最佳合并比例;而 SCE 则专注于消除冲突更新方向。MergeKit 工具让这些先进算法变得触手可及,通过简明的 YAML 配置即可实现复杂的权重融合。在算力资源受限、无法进行完整微调的情况下,权重合并技术为研究人员和开发者提供了一种经济高效的方案,让模型优化更加灵活高效,为 LLM 生态系统的发展提供了新的可能性。
引用
- Model Soups: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy Without Retraining 2203.05482
- Editing Models with Task Arithmetic 2212.04089
- TIES-Merging: Resolving Interference When Merging Models 2306.01708
- Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch 2311.03099
- Model Breadcrumbs: Scaling Multi-Task Model Merging with Sparse Masks 2312.06795
- Model Stock: All we need is just a few fine-tuned models 2403.19522
- DELLA-Merging: Reducing Interference in Model Merging through Magnitude-Based Sampling 2406.11617
- FuseChat: Knowledge Fusion of Chat Models 2408.07990
https://avoid.overfit.cn/post/161535f4639f41809589f36b57b16bc7

