
一、引言
1.1 扩散模型的背景与挑战
❝ 扩散模型(DM)在文本到图像生成任务中取得革命性进展,能生成高质量、多样化的图像内容。然而,模型通常具有庞大的计算成本和模型规模,这使得实际应用中难以部署,尤其是在边缘设备上。例如,基于卷积 U-Net 结构的稳定扩散模型(如 Stable Diffusion 1.5、Stable Diffusion XL)在生成图像时需大量计算资源和内存,这限制了它们在资源受限环境中的应用。
本文提出创新的浮点量化方法 FP4DiT,优化 Transformer 模型量化策略,提升性能并降低硬件成本。实验结果表明,FP4DiT 在多个指标上优于现有方法,为扩散 Transformer 模型的高效部署和广泛应用提供了新思路。
1.2 量化技术的引入
为了减轻扩散模型的计算和存储负担,量化技术被引入作为一种轻量级的方法。量化技术通过减少神经网络权重和激活的位精度来压缩模型,从而降低模型的计算复杂度和内存占用。
常见的量化方法包括后训练量化(PTQ)和量化感知训练(QAT)。其中,PTQ 无需重新训练或微调,仅需少量数据来校准量化尺度,因此更加轻量化和高效。然而,现有的大多数量化方法主要针对传统的卷积神经网络(如 U-Net),对于新兴的扩散 Transformer(DiT)模型,这些方法可能并不适用,因为 DiT 模型采用了不同的 Transformer 架构,其权重和激活的分布特性与卷积网络存在显著差异。

1.3 FP4DiT 的研究意义
FP4DiT 方法的提出正是为了应对上述挑战,为扩散 Transformer 模型的量化提供一种更有效的解决方案。
- FP4DiT 通过采用浮点量化(FPQ) 而非传统的整数量化(INT),能够更好地匹配 DiT 模型的权重和激活分布 ,从而在低比特量化设置下实现更高的量化性能 。
- 此外,FP4DiT 还针对 DiT 模型的特性进行了优化,如提出混合格式的 FPQ 方法以保护 GELU 激活函数的敏感区间,并引入了针对 FP 权重量化的自适应舍入机制,以及实现有效的在线激活量化方案。
这些创新使得 FP4DiT 能够在不显著牺牲生成质量的前提下,大幅减少模型的计算和存储成本,为扩散 Transformer 模型在边缘设备上的部署和应用提供了新的可能性。
二、相关工作
2.1 扩散模型的发展
扩散模型(DM)在生成式人工智能领域迅速崭露头角,成为文本到图像生成任务中的强大工具。早期的扩散模型主要采用卷积 U-Net 架构,例如 Stable Diffusion 1.5 和 Stable Diffusion XL,它们通过迭代去噪过程生成高质量图像。
然而,随着技术的进步,研究人员开始探索基于 Transformer 的架构,即扩散 Transformer(DiT),以提高生成性能和效率。PixArt 系列(如 PixArt-α、PixArt-Σ)、Hunyuan 和 Stable Diffusion 3 等模型采用了这种基于补丁的 Transformer 架构,能够生成更高分辨率的图像。这些 DiT 模型在生成任务中表现出色,但仍然面临计算成本高昂和模型体积庞大的挑战,限制了它们在边缘设备上的应用。
2.2 量化技术概述
量化技术是神经网络压缩的重要手段,旨在通过降低权重和激活的位精度来减少模型的计算和存储需求。量化技术主要分为两大类:量化感知训练(QAT)和后训练量化(PTQ)。
- QAT 在训练过程中模拟量化效果,使模型适应量化后的参数,但需要重新训练,成本较高。
PTQ 则无需重新训练,直接对预训练模型进行量化,更适合实际应用。PTQ 进一步分为均匀量化和非均匀量化,
- 其中整数量化(INT)属于均匀量化,其值在量化范围内均匀分布;
- 浮点量化(FPQ)属于非均匀量化,能够根据权重和激活的实际分布灵活调整量化级别,从而在低比特设置下更好地匹配神经网络的权重和激活分布。
2.3 现有扩散模型量化的局限性
尽管现有的扩散模型量化方法取得了一定进展,但仍存在一些局限性。
- 首先,大多数方法主要针对传统的卷积 U-Net 架构设计,对于新兴的扩散 Transformer(DiT)模型并不适用。DiT 模型采用不同的 Transformer 架构,其权重和激活的分布特性与卷积网络存在显著差异 ,因此需要专门的量化策略。
- 其次,整数量化(INT)在扩散模型量化中的应用较为普遍,但其均匀分布的特性与现代神经网络中权重和激活的非均匀分布不匹配,可能导致量化性能不佳。
- 此外,一些量化方法在处理扩散模型的特定挑战时存在不足,例如未能充分考虑扩散过程中的时间步依赖性和激活范围变化等 。
这些局限性促使研究人员探索更适合 DiT 模型的量化方法,以提高量化效率和保持生成质量。
三、FP4DiT 方法论
3.1 均匀与非均匀量化
3.1.1 INT 量化原理
整数量化(INT)是一种常见的均匀量化方法,通过将高精度数值映射到低精度的整数表示来减少数据量。具体而言,对于一个张量 X,INT 量化过程可以表示为:

3.1.2 FPQ 量化原理
浮点量化(FPQ)采用标准的浮点数表示,允许非均匀的量化级别分布。其基本形式如下:

指数部分决定了不同区间的量化尺度,而尾数部分则在每个区间内提供均匀的量化级别。这种结构使得 FPQ 能够根据数值的大小灵活调整量化精度,从而在低比特设置下更好地匹配神经网络权重和激活的实际分布。
3.1.3 INT 与 FPQ 的对比
INT 量化具有均匀分布的量化级别,适用于权重和激活分布较为均匀的情况,但其固定的量化间隔可能无法很好地适应神经网络中常见的非均匀分布。
相比之下,FPQ 通过指数部分提供了多个不同尺度的量化区间,每个区间内再进行均匀量化,从而能够更灵活地适应权重和激活的实际分布,尤其在低比特量化时能够保留更多的数值信息和分布特性。

图 1 直观地展示了 INT4 和不同 FP4 格式下离散值的分布情况,可以看出FP4 的值更趋向于原点附近,这与神经网络中常见的权重和激活分布模式更为契合。
3.2 FP4DiT 的量化策略
3.2.1 优化的 FP 格式在 DiT 块中的应用
扩散 Transformer(DiT)模型中的每个 DiT 块包含独特的结构,其中点态前馈网络(Pointwise Feedforward)尤为特殊,它由线性层和 GELU 激活函数组成。GELU 激活函数存在一个敏感区间,如图 3 所示,该区间内函数会返回负值。
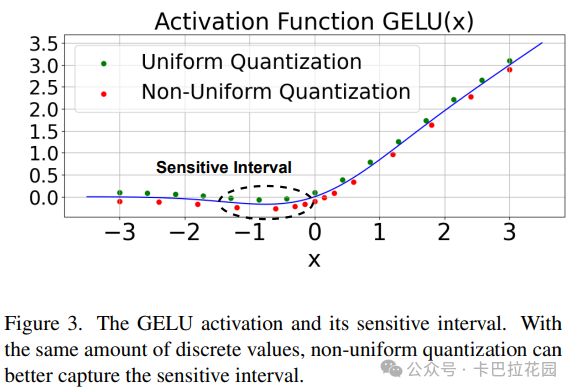
研究表明,关注这一敏感区间有助于减少使用查找表(LUT)或断点近似 GELU 时的均方误差。基于此,FP4DiT 采用更密集的浮点格式(如 E3M0)应用于点态前馈网络的第一个线性层。这种格式将更多的值集中在接近零的地方,即 GELU 敏感区间所在的位置,从而提高近似的精度。
3.2.2 适配 AdaRound 的 FP 量化
AdaRound 是一种用于提升量化性能的技术,它通过二次泰勒展开来优化权重扰动引起的损失。默认情况下,量化采用四舍五入的方式,但 AdaRound 显示,这种方法并不总是最优的。AdaRound 通过优化目标函数来最小化全精度输出与量化输出之间的差异,并引入了可微分的正则化项以鼓励变量收敛。然而,AdaRound 最初是为整数量化设计的,直接应用于浮点量化(FPQ)可能会遇到问题。
具体来说,AdaRound 假设量化尺度在不同量化值之间是一致的,但这在 FPQ 中并不成立,因为 FPQ 具有多个尺度。为了解决这一问题,FP4DiT 提出了 scale-aware AdaRound,它通过修改量化权重的表达式,引入了尺度感知的修正机制,使得优化过程更加稳定,从而提高了 FPQ 的性能。
3.2.3 逐 token 激活量化
在扩散模型的量化过程中,激活量化的处理方式对模型性能有重要影响。传统的基于时间步的激活量化方法假设激活范围会随着时间步的推进而缩小,这一假设适用于 U-Net 架构的扩散模型。然而,对于 DiT 模型,研究表明这一假设并不成立。
DiT 模型的激活范围在不同时间步上保持稳定,但会随着时间步的变化而发生偏移。此外,不同图像块(token)的激活范围差异显著,即使在同一时间步内也是如此。基于这些观察,FP4DiT 采用了逐 token 的在线激活量化方法。这种方法通过最小最大量化策略,针对每个图像块单独进行量化,能够更好地适应 DiT 模型的激活特性,从而提高量化后的模型性能。
3.3 方法的创新点与优势
FP4DiT 方法在扩散 Transformer 模型的量化上做出了多项创新,带来了显著的优势:
- 创新的 FP 格式优化:针对 DiT 块中的点态前馈网络,采用了更密集的浮点格式(如 E3M0),集中更多值于 GELU 激活函数的敏感区间,提升近似精度,更好地捕捉激活特性。
- scale-aware AdaRound 机制:传统 AdaRound 在 FPQ 中表现不佳,因它假设量化尺度一致。FP4DiT 提出 scale-aware AdaRound,修改量化权重表达式,引入尺度感知修正,使优化稳定,提升 FPQ 性能,降低校准成本达 8 倍。
- 逐 token 激活量化策略:DiT 模型的激活范围在不同时间步上稳定但会偏移,且不同图像块差异大。FP4DiT 采用逐 token 在线激活量化,用最小最大量化策略单独处理每个图像块,适应激活特性,提升性能。
- 显著的性能提升与成本降低:FP4DiT 在多个 T2I 任务中表现出色,如在 PixArt-α、PixArt-Σ 和 Hunyuan 模型上,以 W4A6 和 W4A8 精度水平,在 HPSv2 基准和 MS-COCO 数据集上均优于现有方法,还通过用户偏好研究验证了生成图像质量的优越性。同时,模型大小和计算复杂度大幅降低,BOPs 计算复杂度减少,硬件成本降低。
- 硬件友好的设计:FP4DiT 的 FPQ 方法与现代 GPU 的计算特性相契合,如最新的 Nvidia Blackwell 系列 GPU 对 FP4 和 FP6 的计算吞吐量与 FP8 和 INT8 相同,确保了 FP4DiT 在实际应用中不会引入额外的计算开销,同时 FP6 相比 FP8 节省了内存,提升了 DiT 模型的推理效率。
四、实验结果与分析
4.1 实验设置
为了验证 FP4DiT 方法的有效性,研究者进行了全面的实验。实验中使用了三种文本到图像的扩散 Transformer 模型:PixArt-α、PixArt-Σ 和 Hunyuan。这些模型代表了当前扩散 Transformer 技术的先进水平,具有不同的架构和特性,能够充分检验 FP4DiT 方法的通用性和有效性。
在量化设置方面,研究者采用了 HuggingFace Diffusers 库来实例化基础 DiT 模型,并使用默认的推理参数,如去噪步骤的数量和分类器自由引导(CFG)比例。权重被量化为 4 位精度的 FP 格式,其中点态前馈网络的第一个线性层的权重格式设置为 E3M0。其他权重的量化格式根据模型的不同有所调整:PixArt-α 和 Hunyuan 的其他权重被量化为 E2M1,而 PixArt-Σ 的其他权重被量化为 E1M2。此外,权重量化采用组量化的方式,沿输出通道维度进行,组大小为 128。激活量化则采用 ZeroQuant 的最小最大量化策略,将精度降低到 8 位或 6 位。
校准数据方面,研究者从 MS-COCO 2017 训练集中选取了 128 张(Hunyuan 为 64 张)图像-文本对,进行 2.5k 次迭代的权重量化校准。激活量化则基于这些校准数据,在不同时间步上对输入潜变量进行采样,以确保量化参数的准确性。
4.2 主要结果
4.2.1 定量评估
定量评估结果如表 2 所示,FP4DiT 方法在 PixArt-α、PixArt-Σ 和 Hunyuan 三个模型上均显著优于其他基线方法。
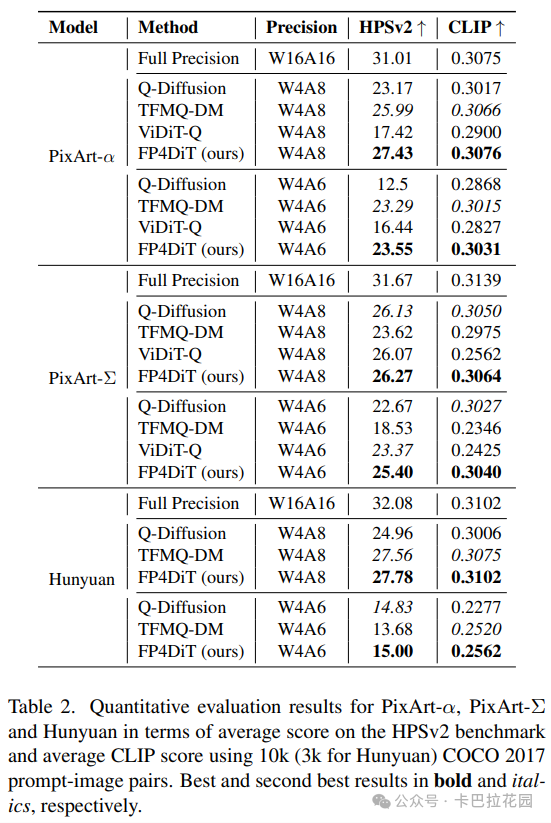
在 PixArt-α 模型上,FP4DiT 在 W4A8 精度下取得了 27.43 的 HPSv2 分数和 0.3076 的 CLIP 分数,相比 Q-Diffusion、TFMQ-DM 和 ViDiT-Q 等基线方法有明显提升。即使在更具挑战性的 W4A6 精度下,FP4DiT 依然保持了 23.55 的 HPSv2 分数和 0.3031 的 CLIP 分数,远超其他方法。类似的趋势也出现在 PixArt-Σ 和 Hunyuan 模型上,证明了 FP4DiT 方法在不同模型和精度水平下的稳定性和优越性。
进一步的定量评估结果见表 9,FP4DiT 在 Fréchet Inception Distance(FID)和 CLIP 分数上同样表现出色。
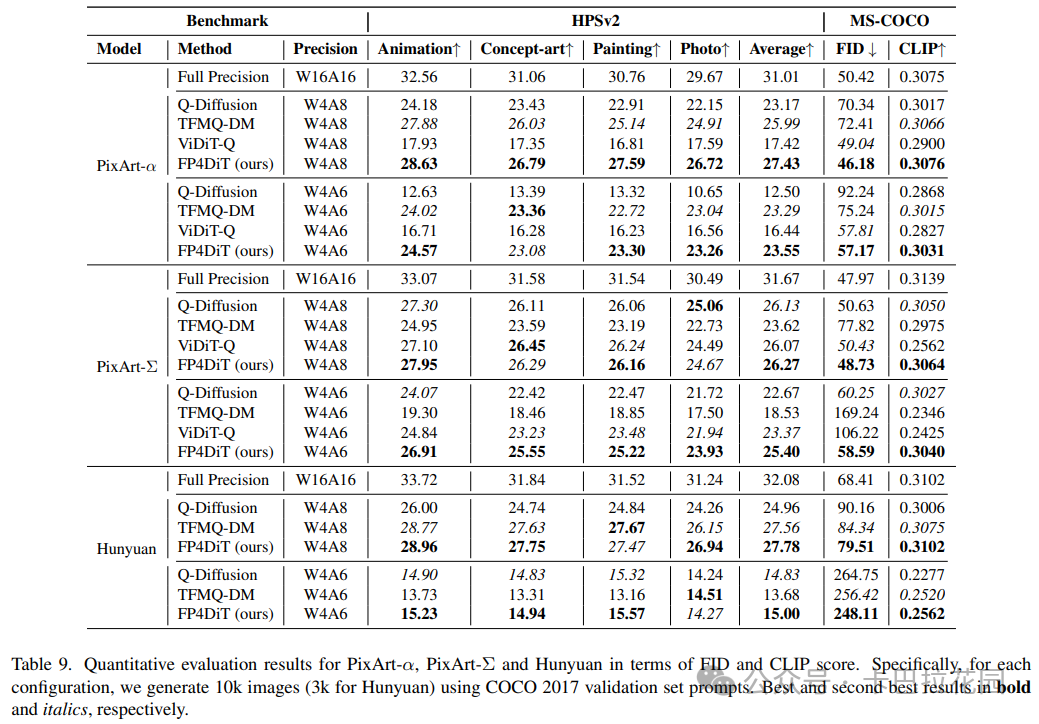
例如,在 PixArt-α 的 W4A8 配置下,FP4DiT 的 FID 为 46.18,CLIP 分数为 0.3076,显著优于其他基线方法。这些结果从多个角度验证了 FP4DiT 在保持生成图像质量方面的优势。
4.2.2 定性评估
定性评估通过生成图像的可视化来直观展示 FP4DiT 方法的效果。如图 7 和图 8 所示,FP4DiT 生成的图像在细节和整体质量上均优于其他基线方法。


在 PixArt-α 和 PixArt-Σ 模型上,FP4DiT 生成的图像不仅在 W4A8 精度下接近全精度模型的水平,即使在 W4A6 精度下也能保持较高的图像质量,细节丰富且与文本提示高度相关。例如,FP4DiT 生成的图像在描绘动物、风景等细节时更加逼真,颜色和纹理更加自然。在 Hunyuan 模型上,FP4DiT 同样展现出优势,生成的图像细节清晰,背景和主体的处理更加合理,避免了其他方法中可能出现的噪声和模糊问题。
4.3 用户偏好研究
为了从用户体验的角度评估 FP4DiT 方法生成图像的质量,研究者设计并开展了一项用户偏好研究。在实验中,随机选取了 75 个文本提示,并邀请了 15 名参与者。对于每个提示,参与者会看到由不同量化方法(FP4DiT、Q-Diffusion 和 TFMQ-DM)在 W4A8 和 W4A6 精度下生成的图像。参与者需要根据图像与文本提示的匹配度、图像的细节丰富度、整体美观度等方面,选择他们最偏好的一张图像。
实验结果显示,在 A8 精度下,FP4DiT 生成的图像被选中的比例为 56.58%,显著高于 Q-Diffusion 的 6.58%和 TFMQ-DM 的 36.84%。这表明用户对 FP4DiT 生成图像的偏好程度远超其他方法。即使在更具挑战性的 A6 精度下,FP4DiT 仍获得了 38.81%的偏好率,而 Q-Diffusion 和 TFMQ-DM 分别为 32.84%和 28.36%。这一结果进一步验证了 FP4DiT 在生成图像质量上的优越性,不仅在客观指标上表现突出,也能更好地满足用户的主观审美需求。
4.4 硬件成本比较
FP4DiT 方法在降低模型硬件成本方面也表现出显著优势。通过采用组量化策略,FP4DiT 在量化后模型的存储大小和计算复杂度上均实现了大幅减少。以 PixArt-α 模型为例,全精度模型(W16A16)的存储大小为 610.86 MB,BOPs 计算复杂度为 35.72 TB。在量化为 W4A8 后,模型大小减少至 152.87 MB,BOPs 降低至 4.474 TB。若进一步量化为 W4A6,模型大小保持不变,但 BOPs 进一步降低至 3.358 TB。
此外,FP4DiT 的 FPQ 方法与现代 GPU 的计算特性高度适配。例如,最新的 Nvidia Blackwell 系列 GPU(如 RTX 5090、HGX B100 和 B200)对 FP4 和 FP6 的计算吞吐量与 FP8 和 INT8 相同,这意味着 FP4DiT 在实际应用中不会引入额外的计算开销**FP6 相比 FP8 节省了 25%的内存**,这对于在推理过程中往往受内存限制的 Transformer 模型尤为重要,进一步提升了 DiT 模型的推理效率。
五、结论与展望
5.1 研究总结
本文提出的 FP4DiT 方法在扩散 Transformer 模型的量化方面取得了显著成果。通过引入浮点量化(FPQ)技术,FP4DiT 成功地解决了现有扩散模型量化方法在处理扩散 Transformer(DiT)模型时的不足。
具体而言,FP4DiT 采用混合 FP 格式策略,针对 DiT 块中的特定结构优化量化格式,如在点态前馈网络的第一个线性层应用 E3M0 格式,以更好地匹配 GELU 激活函数的敏感区间。同时,提出了 scale-aware AdaRound 机制,解决了传统 AdaRound 在 FPQ 应用中的性能限制,提高了权重量化精度并降低了校准成本。此外,FP4DiT 还创新性地采用了逐 token 激活量化策略,适应了 DiT 模型激活特性的变化,进一步提升了量化模型的性能。
实验结果充分证明了 FP4DiT 方法的有效性和优越性。
- 在定量评估中,FP4DiT在多个 T2I 任务上均优于现有量化方法,如在 PixArt-α、PixArt-Σ 和 Hunyuan 模型上,以 W4A6 和 W4A8 精度水平在 HPSv2 基准和 MS-COCO 数据集上取得了最佳成绩 。
- 定性评估也显示,FP4DiT 生成的图像在细节和质量上均优于其他基线方法 。
用户偏好研究进一步验证了 FP4DiT 在主观视觉效果上的优势,表明其生成的图像更受用户青睐。在硬件成本方面,FP4DiT 通过减少模型大小和计算复杂度,显著降低了部署成本,同时与现代 GPU 的计算特性高度适配,确保了计算效率。
5.2 未来工作方向
尽管 FP4DiT 在扩散 Transformer 模型量化方面取得了重要进展,但仍有许多值得进一步研究和改进的方向。
- 首先,可以进一步优化 FP4DiT 的量化策略,探索更高效的量化格式和算法,以在更低比特精度下保持模型性能,例如研究 W4A4 甚至 W2A4 的可行性。
- 其次,将 FP4DiT 方法扩展到其他类型的扩散模型和生成任务中,如视频生成、3D 内容生成等,验证其通用性和可扩展性。
- 此外,结合新兴的硬件架构和技术,如专门的 AI 芯片和异构计算平台,进一步优化 FP4DiT 的实现,提高计算效率和能源利用率。
- 最后,从理论上更深入地分析 FPQ 对模型性能的影响,为量化方法的设计提供更坚实的理论基础,推动量化技术在生成模型中的应用和发展。
END
作者:无双
来源:卡巴拉花园
推荐阅读
- 在 96 个 H100 GPU 上部署具有 PD 分解和大规模专家并行性的 DeepSeek
- 在 SGLang 中实现 Flash Attention 后端 - 基础和 KV 缓存
- 3.5 倍能效突破,Attention 和 Softmax 的 AI 加速器实现
- Qwen3:思深,行速
- 猛击OpenAI o1、DeepSeek-R1!刚刚,阿里Qwen3登顶全球开源模型王座,深夜爆火
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区嵌入式AI专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

