
驱动大型语言模型(LLM)的 Transformer 架构因其注意力机制而成为基础。随着这些模型的规模不断扩大,导致计算资源需求激增、实时性要求提高,让高效的 GPU 注意力内核对于实现高吞吐量和低延迟的推理变得至关重要。
多样的 LLM 应用需要灵活且高性能的注意力解决方案。我们提出了 FlashInfer:一个用于 LLM 推理服务的可定制且高效的注意力引擎。
FlashInfer 通过块稀疏格式和可组合格式解决了键值缓存(KV-cache)存储的异构性问题,以优化内存访问并减少冗余。它还提供了一个可定制的注意力模板,通过即时编译(JIT Compilation)实现在多种设置中的适应性。
此外,FlashInfer 的动态感知编译器和运行时能够有效处理输入的动态性,同时保持对静态配置的需求,以兼容 CUDA 图(CUDAGraph)。FlashInfer 已被集成到领先的 LLM 服务框架中,如 SGLang、vLLM 和 MLC-Engine。
全面的内核级和端到端评估表明,FlashInfer 在多样化的推理场景中显著提升了内核性能:与现有的 LLM 服务解决方案相比:
- FlashInfer 在LLM 服务基准测试中实现了 29-69%的 token 间延迟减少
- 在长上下文推理中实现了 28-30%的延迟减少
- 在并行生成的 LLM 服务中实现了 13-17%的加速 。


NeuralTalk 知识补充
【1】. 什么是 KV 缓存(Key-Value Cache)?
KV 缓存是大型语言模型(LLM)推理中用于存储历史上下文信息的
一种数据结构。它包含键(Key)和值(Value)两部分,键通常
用于标识特定的上下文位置,而值则存储与该位置相关的特征向量。
在 LLM 推理过程中,KV 缓存用于快速检索和更新历史上下文
信息,从而提高推理效率。例如,在生成文本时,模型会根据
当前的查询(Query)与 KV 缓存中的键进行匹配,计算注意力
分数,并生成输出。
【2】. 什么是块稀疏格式(Block Sparse Format)?
一种数据存储方式,将矩阵划分为固定大小的块(Block),并只存储
非零块。这种方式可以有效减少存储空间,同时提高内存访问效率。
块稀疏格式特别适用于处理 KV 缓存,因为它可以灵活地表示不同
大小的稀疏模式,减少冗余存储,并提高计算效率。例如,对于长序列
数据,块稀疏格式可以将连续的非零元素组织成块,减少内存访问次数。
【3】. 什么是多查询注意力(Multi-Query Attention, MQA)?
一种优化的注意力机制,它通过减少查询的数量来提高计算效率。
在标准的多头注意力中,每个头都有自己的查询、键和值向量;
而在 MQA 中,多个头共享一组键和值向量,从而减少内存占用
和计算量。
MQA 特别适用于处理大规模数据,因为它可以显著减少 KV 缓存的
大小,同时保持较高的推理性能。例如,在处理长序列数据时,MQA
可以减少内存访问次数,提高推理速度。
一、引言
Transformer 架构已成为大型语言模型(LLM)的主要骨干架构,其最显著的组件是注意力机制(Vaswani et al., 2017)。
随着 LLM 在各个领域的快速发展和应用,对高效 GPU 注意力内核的需求不断增长,目标是实现可扩展且响应迅速的模型推理。在LLM 推理的核心是注意力计算,它在处理历史上下文和基于查询向量生成输出方面起着关键作用。在 LLM 服务中,注意力机制从存储历史上下文的 KV 缓存中读取,并根据当前查询计算输出。注意力操作符的效率对 LLM 推理系统的整体性能至关重要。然而,为 LLM 服务量身定制高性能注意力内核带来了传统训练环境中不常遇到的挑战。
在为 LLM 系统构建高效的注意力支持时,出现了两个主要挑战:
LLM 应用展现出多样化的工作负载模式和输入动态性。
- LLM 服务涉及多种注意力计算模式,从用于上下文处理的预填充计算到服务期间的批量解码(Yu et al., 2022)。随着多个请求的处理,出现了前缀重用的机会,而在推测性场景中引入的树解码又创造了额外的注意力模式(Cai et al., 2024; Miao et al., 2024; Chen et al., 2024)。
- 此外,查询长度和 KV 缓存会在批次内和随时间变化,如果实现不当,可能会导致负载不平衡问题,因此需要内核动态适应以实现最佳性能。
现代硬件实现需要定制注意力操作符。
- 在内存方面,高效的存储格式(如分页注意力(Kwon et al., 2023)和基数树(Zheng et al., 2023b))对于管理不断增长的 KV 缓存大小和多样化的存储模式至关重要。
- 在计算方面,为充分利用每个 GPU 架构的性能潜力,打造硬件特定的流水线和模板是不可或缺的(Dao, 2023; arXiv:2501.01005v2 [cs.DC] 21 Apr 2025)。
- 此外,设计必须适应现代 LLM 中日益多样化的注意力机制,如分组注意力头(Ainslie et al., 2023; Shazeer, 2019)、专用掩码(Beltagy et al., 2020)和自定义注意力分数计算(Rivière et al., 2024; xAI, 2023; Ramapuram et al., 2024),这需要灵活且可扩展的实施策略。
工作负载多样性和硬件异构性的复杂性增加了开发全面注意力解决方案的难度。目前,每个系统都基于这些特性的一个子集实现专门化的注意力解决方案,导致维护开销高和潜在的效率低下。
为应对这些挑战,我们引入了 FlashInfer,这是一个基于代码生成的注意力引擎,旨在加速 LLM 中的注意力计算。我们的方法包含几个关键设计:
- FlashInfer采用块稀疏格式来应对 KV 缓存存储异构性问题。这种格式作为各种 KV 缓存配置的统一数据结构,可调整的块大小允许细粒度的稀疏性,例如向量级稀疏性(Chen et al., 2021; Li et al., 2022)。这种方法统一了多样化的 KV 缓存模式,并提升了内存访问效率。
- FlashInfer提供了一个可定制的注意力模板,支持不同的注意力变体。FlashInfer 为用户提供了可定制的编程接口,以实现他们的注意力变体。FlashInfer使用即时编译(JIT Compilation)将这些变体转化为高度优化的块稀疏实现,确保快速适应不同的注意力配置。
- FlashInfer采用了动态负载均衡调度框架,以有效处理输入动态性。它将编译时的瓦片(tile)大小选择与运行时调度分开,提供了轻量级 API,以适应推理期间 KV 缓存长度的变化,同时保持与 CUDAGraph 对静态配置要求的兼容性(Gray, 2019; Nguyen et al., 2021)。
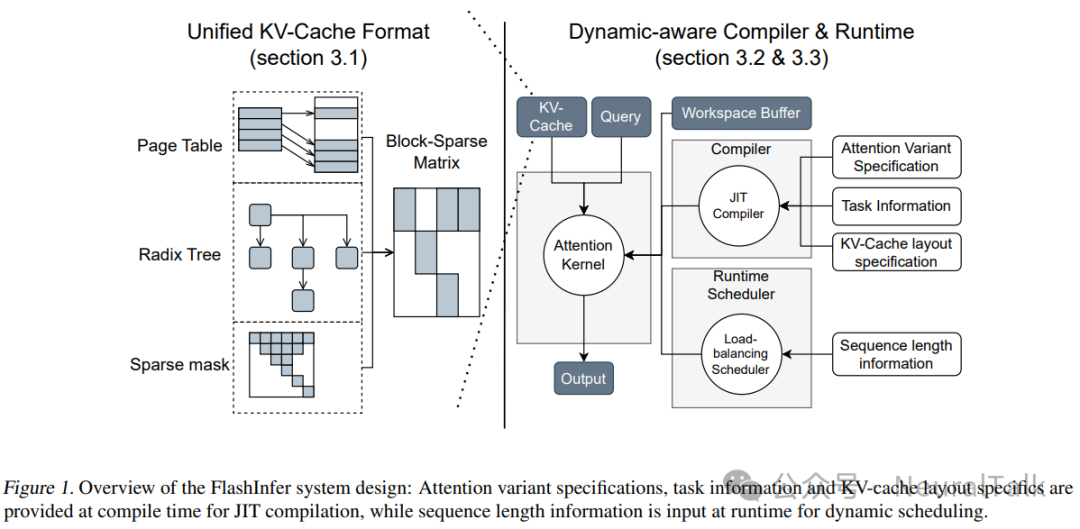
图 1 展示了我们的系统设计。我们在标准 LLM 服务环境和创新场景(包括前缀共享和推测解码)中评估了 FlashInfer 的性能。
FlashInfer 已被集成到主流的 LLM 服务引擎中,包括 vLLM(Kwon et al., 2023)、MLC-Engine(MLC Community, 2024; Lai et al., 2023)和 SGLang(Zheng et al., 2023b)。
我们评估了其对端到端延迟和吞吐量改进的影响,显示出在标准 LLM 服务基准测试和新应用(如长上下文推理和并行生成)中的显著提升。
我们的贡献包括:
- 提出灵活的块稀疏和可组合格式,解决 KV 缓存存储异构性问题,实现高效内存管理和访问。
- 开发了可定制的注意力模板,适应多样的注意力变体,并通过 JIT 编译确保高性能执行。
- 设计了动态调度框架,管理输入动态性,同时保持与 CUDAGraph 的兼容性,最大化硬件利用率。
- 全面评估表明,在内核和端到端性能方面均有显著提升。
二、背景知识
2.1 FlashAttention
- FlashAttention(Dao et al., 2022)是一种计算精确注意力并减少内存使用的高效算法。在前向传播过程中,它采用在线 softmax 技巧(Milakov & Gimelshein, 2018),使用固定数量的片上内存在线更新注意力输出,从而避免在 GPU 全局内存中显式存储注意力矩阵。
- FlashAttention2&3(Dao, 2023; Shah et al., 2024)通过优化循环顺序和流水线设计,进一步提升了 Ampere 和 Hopper GPU 上的性能。具体来说,优化后的循环顺序减少了内存访问延迟,提高了数据的局部性,使得 GPU 能够更高效地访问内存中的数据。同时,流水线设计提高了计算单元的利用率,通过将计算任务分解为多个阶段,并在不同的阶段并行执行,从而减少了计算过程中的空闲时间,提高了整体的计算效率。
FlashInfer 在此基础上进行了改进。
FlashAttention 的操作强度由公式:
$$O\left(\frac{1}{1/l_{qo} + 1/l_{kv}}\right) $$其中,$ l*{qo} $ 和 $ l*{kv} $ 分别是查询和键值缓存的长度。在 LLM 服务中,查询长度要么等于(预填充)要么小于(解码/增量预填充)键值缓存长度,这将操作强度简化为 $ O(l\_{qo}) $。
操作强度是衡量计算效率的一个重要指标,较高的操作强度意味着在单位时间内可以完成更多的计算工作,从而提高模型的性能。在 LLM 服务中,优化操作强度对于提升推理速度和降低延迟具有重要意义。
像批量处理(Yu et al., 2022)这样的技术不会改变这种操作强度。多查询注意力(MQA)(Shazeer, 2019)和分组查询注意力(GQA)(Ainslie et al., 2023)通过分组查询和共享相同的键值缓存条目来优化键值缓存大小。
对于多查询注意力(MQA)和分组查询注意力(GQA),操作强度提升为 $ O(g \cdot l*{qo}) $,其中 $ g = H*{qo}/H\_{kv} $ 是组大小。
2.2 注意力组合
块并行 Transformer(BPT)(Liu & Abbeel, 2023)证明,对于相同的查询和不同的键/值,可以通过保留注意力输出及其比例来组合注意力输出。设 $q$ 为查询,$\mathcal{I}$ 为索引集合。我们通过 log-sum-exp 操作定义 $\mathcal{I}$ 上的注意力比例:
$$LSE(\mathcal{I}) = \log \sum_{i \in \mathcal{I}} \exp(q \cdot k_i) $$其中 $k_i$ 是第 $i$ 个键向量。对应的注意力输出 $O(\mathcal{I})$ 则为:
$$O(\mathcal{I}) = \sum_{i \in \mathcal{I}} \frac{\exp(q \cdot k_i)}{\exp(LSE(\mathcal{I}))} \cdot v_i $$我们将 $\mathcal{I}$ 的注意力状态定义为一个包含注意力输出和注意力比例的元组:$\begin{bmatrix} \mathbf{O}(\mathcal{I}\cup\mathcal{J}) \\ \mathbf{LSE}(\mathcal{I}\cup\mathcal{J}) \end{bmatrix}$。这里的元组可以理解为一个包含两个部分的组合:
- 第一个部分是注意力输出,表示模型对输入数据的关注程度;
- 第二个部分是注意力比例,用于衡量不同输入数据之间的相对重要性。
这种表示方法使得我们能够更灵活地处理注意力计算的结果,并为后续的组合操作提供了便利。
关键的是,$\mathcal{I}\cup\mathcal{J}$ 的注意力状态可以通过组合 $\mathcal{I}$ 和 $\mathcal{J}$ 的状态来推导。具体来说,引入一个操作符 $\oplus$:
$$\begin{bmatrix} \mathbf{O}(\mathcal{I}\cup\mathcal{J}) \\ \mathbf{LSE}(\mathcal{I}\cup\mathcal{J}) \end{bmatrix} = \begin{bmatrix} \mathbf{O}(\mathcal{I}) \\ \mathbf{LSE}(\mathcal{I}) \end{bmatrix} \oplus \begin{bmatrix} \mathbf{O}(\mathcal{J}) \\ \mathbf{LSE}(\mathcal{J}) \end{bmatrix} = \begin{bmatrix} \frac{\exp(\mathbf{LSE}(\mathcal{I}))\mathbf{O}(\mathcal{I})+\exp(\mathbf{LSE}(\mathcal{J}))\mathbf{O}(\mathcal{J})}{\exp(\mathbf{LSE}(\mathcal{I}))+\exp(\mathbf{LSE}(\mathcal{J}))} \\ \log(\exp(\mathbf{LSE}(\mathcal{I})) + \exp(\mathbf{LSE}(\mathcal{J}))) \end{bmatrix} $$>
操作符 $\oplus$ 的作用是将两个注意力状态进行高效组合。通过这种方式,可以在不重新计算整个注意力矩阵的情况下,快速得到多个注意力状态的组合结果。这种组合方式不仅减少了计算量,还降低了内存访问的频率,从而显著提高了硬件的效率。特别是在处理大规模数据时,这种优化能够显著提升模型的性能。
由于 $\oplus$ 操作符是结合的和可交换的,因此可以以任意顺序组合多个注意力状态。RingAttention(Liu et al., 2023)和 Flash-Decoding(Dao et al., 2023)利用这一特性将部分注意力计算卸载到其他地方,从而减少内存使用并提高硬件效率。
在 FlashInfer 中,注意力状态被采用作为注意力操作的规范输出,$\oplus$ 作为这些状态上的标准归约操作符(类似于 GEMM 中的加法)。
FP8-FP16 混合精度注意力
最近的 LLMs(大型语言模型)经常采用 FP8 KV-Cache(键值缓存)来减少内存带宽和存储成本(Mickevicius 等人,2022)。
在FlashInfer 中,我们实现了混合精度的注意力内核,其中查询和输出保持在 FP16格式,而KV-Cache 存储在 FP8格式。
我们利用了 Gupta(2024)提出的快速数值数组转换器和片段洗牌器来加速去量化处理,并有效处理位宽不匹配。这种设计允许减少内存占用并提高带宽利用率,而不会显著影响数值精度。
2.3 块/向量稀疏性
块压缩稀疏行(BSR)是一种硬件高效的稀疏格式,它将非零元素分组成大小为 (br, bc) 的连续矩阵,与随机分散的非结构化稀疏性相比,这种格式在 GPU 和 NPU 上的硬件矩阵乘法单元中具有更好的兼容性。
与标准的压缩稀疏行(CSR)格式相比,BSR 在寄存器重用效率(Im et al., 2004; Buluç et al., 2009)方面表现出色,并且可以跳过空块,减少计算开销。当子计算与 GPU 上的张量核心指令(如 NVIDIA 的 mma 指令)对齐时,BSR 的效率尤为显著。
传统上,为了与张量核心的最小维度(16 或更新 GPU 型号的更大值)对齐,大多数块稀疏内核使用 br 和 bc 的倍数为 (16, 16) 的块大小。这种方法是为了与张量核心的最小维度对齐,从而最大化硬件矩阵乘法单元的效率。张量核心是现代 GPU 中用于加速矩阵运算的专用硬件单元,其最小维度通常为 16。通过将块大小设置为张量核心的最小维度的倍数,可以确保每个块都能够充分利用张量核心的计算能力,从而提高整体的计算效率。
然而,这种方法并不总是适用于具有细粒度稀疏模式的应用(Wang et al., 2023)。
最近的研究(Chen et al., 2021; Li et al., 2022)表明,通过将行/列收集到共享内存中,然后对这些共享内存数据应用密集张量核心,可以实现对张量核心的有效利用,即使对于更小的块大小(如矩阵 B 中的 (16, 1) 或矩阵 A 中的 (1, 16),也称为向量稀疏性)。这种技术对于具有细粒度稀疏模式的应用特别有用。
向量稀疏性相对于传统块稀疏格式的优势在于其灵活性和内存效率。体现在如下三个方面:
- 向量稀疏性能够更灵活地处理不同大小的稀疏块,减少内存浪费。
- 在处理具有复杂稀疏结构的应用时,向量稀疏性可以更好地适应不同的数据分布,从而提高计算效率。
- 此外,向量稀疏性还能够更好地利用 GPU 的内存带宽,进一步提升模型的性能。
FlashInfer 基于这些技术,支持任意列大小的块,提供更大的灵活性和效率,以处理多样化的稀疏模式。
三、系统设计
在本节中,我们将介绍 FlashInfer 的系统设计。
- 我们首先介绍FlashInfer 中使用的数据结构,展示块稀疏行 (BSR)格式如何作为注意力内核中KV 缓存存储的通用抽象。
- 接下来,我们讨论 FlashInfer 编译器如何支持各种注意力变体,以及动态感知运行时调度程序如何实现负载均衡的注意力内核调度。
- 最后,我们描述了用户级 API,用于将 FlashInfer与现有的 LLM 服务系统集成。
3.1 KV 缓存存储
3.1.1 块稀疏矩阵作为统一格式
最近在 KV 缓存存储方面的进展,如分页注意力(Kwon et al., 2023)和基数树注意力(Zheng et al., 2023b),采用了非连续内存存储,最小粒度为一个块(或称为 token )的 (H, D) 张量,其中 H 表示头数,D 表示隐藏维度。
这些结构经过优化,以最小化内存碎片并增强内存重用和缓存命中率。我们在下图图 2 中展示了如何将这些多样化的数据结构统一到一个块稀疏格式下。图中展示了不同 KV 缓存存储结构(分页注意力)如何通过索引指针数组映射到块稀疏格式。这种映射方式使得不同存储结构的数据能够以统一的格式进行处理,从而简化了后续的计算和优化过程。

页面表和稀疏矩阵之间的概念等价性在 SPGrid(Setaluri et al., 2014)中已有探索,该研究利用硬件的翻译后备缓冲区(TLB)进行高效稀疏结构索引。除了页面表和基数树外,稀疏矩阵还可以有效地表示各种注意力机制,例如在推测解码(Cai et al., 2024; Miao et al., 2024; Chen et al., 2024)中使用的树注意力,以及应用到 KV 缓存的重要性掩码(Tang et al., 2024)。
在 FlashInfer 中,我们实现了数据表示的统一策略。查询和输出矩阵被高效地存储为非规则张量(也称为锯齿数组)(Tensorflow Developers, 2018),无需填充,从而将来自不同请求的查询和输出紧凑地打包到单个张量中。索引指针数组在这里起到了关键作用,它用于快速定位块稀疏矩阵中的非零块。通过这种方式,我们可以高效地访问和操作 KV 缓存中的数据,提高内存访问效率。
最初,键和值保持在使用与查询相同的索引指针的非规则张量中,因为它们来自应用于相同输入的投影矩阵 $W_q, W_k, W_v$。这些键和值随后被纳入 KV 缓存,并带有新更新的条目。KV 缓存采用块稀疏行(BSR)格式,块大小由应用程序需求定义:$B_r$ 对应于查询瓦片大小(稍后部分将详细介绍),$B_c$ 由 KV 缓存管理算法指定。FlashInfer 内核实现支持任意 $(B_r, B_c)$ 值。
3.1.2 可组合格式以提高内存效率
受到 SparseTIR(Ye et al., 2023)的启发,我们通过可组合格式增强注意力计算效率。这种方法利用多个块稀疏格式而不是单一格式来存储稀疏矩阵,提供更大的灵活性和内存效率。
单一的块稀疏格式受限于固定的块大小,这限制了基于块中的行数($B_r$)的内存效率。较大的 $B_r$ 值可以提高同一块内请求的共享内存和寄存器重用,但也会增加碎片化。相反,不同块中的请求无法访问彼此的共享内存。
我们的可组合格式设计允许根据先验知识对 KV 缓存稀疏矩阵进行分解。例如,如果某些请求共享前缀,那么 KV 缓存中的相应行和列形成一个密集子矩阵。我们可以使用较大 $B_r$ 的块稀疏矩阵来高效地存储这些子矩阵。
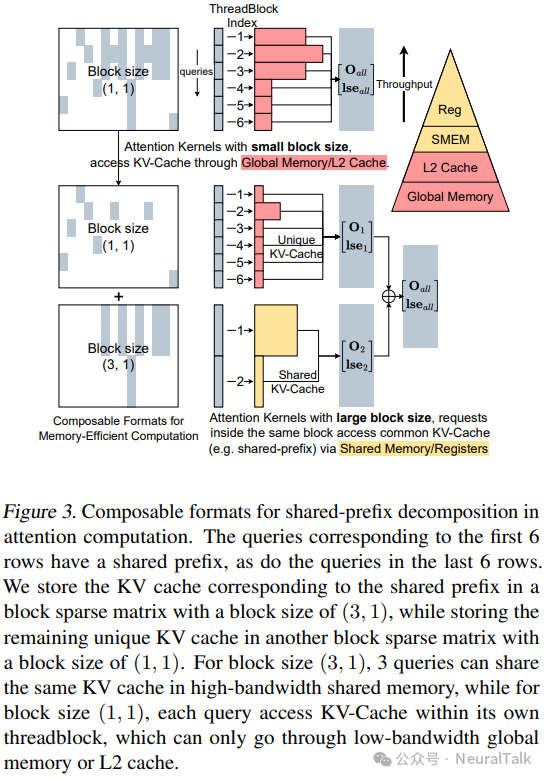
图 3 展示了如何利用可组合格式优化共享前缀。。在图中,我们可以看到在有共享前缀的情况下,KV 缓存被划分为不同大小的块。通过这种方式,我们可以更高效地处理共享前缀的数据,减少内存访问的次数,从而提高内存效率。
这种方法不需要在 KV 缓存中移动数据;相反,我们计算稀疏子矩阵的索引和索引指针数组。具有较大块大小的注意力计算可以通过快速共享内存和寄存器访问共享的 KV 缓存条目,显著提高内存效率。
3.2 计算抽象
我们为 FlashAttention 开发了 CUDA/CUTLASS(Thakkar et al., 2023)模板,专门针对密集和块稀疏矩阵设计,并兼容从图灵到霍珀(sm75 到 sm90a)的 NVIDIA GPU 架构。
我们的实现采用 FlashAttention2(FA2,简称)算法(Dao, 2023)用于 Ada(sm89)及之前的架构,以及 FlashAttention3(FA3,简称)算法(Shah et al., 2024)用于霍珀架构。
关键改进包括增强的稀疏瓦片(tile)加载到共享内存、扩展的瓦片大小配置、针对分组查询注意力的优化内存访问模式,以及可定制的注意力变体。
3.2.1 全局到共享内存的数据移动
FlashInfer 的注意力模板支持任意块大小,这需要专门的数据加载方法,因为块可能无法与张量核心形状对齐。如第 2.3 节所述,我们通过将分散的全局内存中的瓦片(tile)转移到共享内存中以进行密集的张量核心操作来解决这些挑战。对于单个 MMA 指令的张量核心输入,可以从块稀疏矩阵中的不同块中获取。
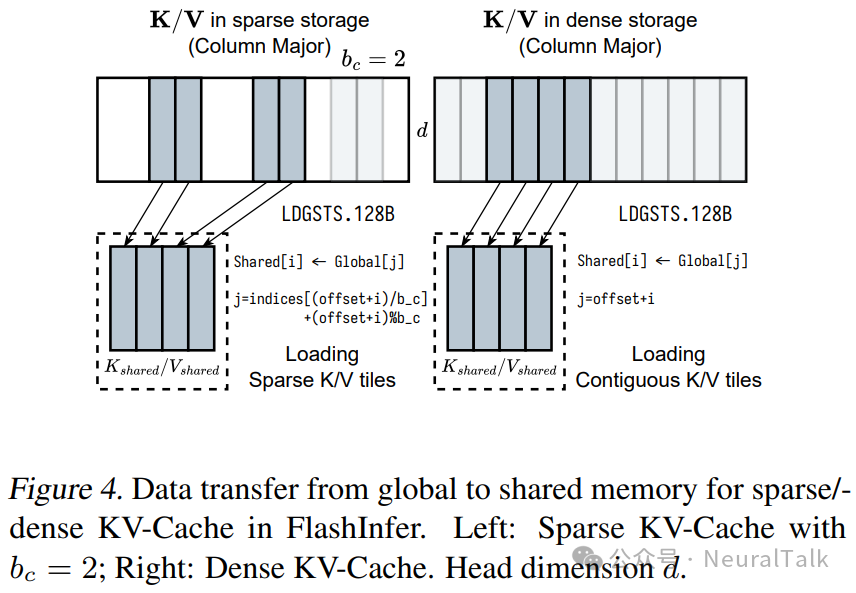
图 4 展示了 FlashInfer 如何从稀疏/密集 KV 缓存中加载瓦片到共享内存中:稀疏 KV 缓存地址的计算使用 BSR 矩阵的索引数组,而密集存储则使用行索引仿射变换。
KV 缓存的最后一维保持连续(大小为头维度 d,通常为 128 或 256),以维持与 GPU 缓存行大小一致的合并内存访问。我们使用宽度为 128B 的异步复制指令 LDGSTS 来最大化内存带宽。
尽管 Hopper 架构中的张量内存加速器(TMA)可以进一步加速数据移动,但它不支持非仿射内存访问模式。因此,我们仅在 Hopper GPU 上对连续 KV 缓存使用 TMA,而对其他不适合 TMA 设置的情况则回退到 Ampere 风格的异步复制。
在转移到共享内存后,稀疏和密集的 FlashAttention 实现汇聚,允许一致地使用内核,变化仅在于数据加载模块。
3.2.2 不同瓦片大小(tile size)的微内核(micro kernel)
为了适应 LLM 应用中变化的操作强度,FlashInfer 在多个大小上实现了 FA2 算法(FlashAttention2 的简称)。传统的 FA2 使用有限的瓦片大小(例如,(128, 64)),这对于 A100 上的预填充是最佳的,但在较短查询长度的解码中效率低下。一个架构的理想瓦片大小可能不适合其他架构;例如,Ada(sm89)的共享内存有限,大瓦片会影响带有大瓦片的 SM 资源占用。
FlashInfer 提供具有瓦片大小(1, 16, 32, 64, 128)×(32, 64, 128)的 FA2 内核,并使用基于硬件资源和工作负载强度的启发式方法进行选择,选择策略如下:
- 确定每批次的平均查询长度(对于分组查询注意力,查询长度与头组维度融合,详见附录 A),选择最小的查询瓦片大小以满足或超过它。
- 将寄存器和共享内存约束表示为 K/V 瓦片大小的函数,以最大化 SM 资源占用率。
3.2.3 注意力变体的 JIT 编译器
最近的 LLM 模型使用标准注意力算法的变体。在 CUDA 库中支持各种注意力变体是不可持续的,因为我们为每个变体专门化内核以实现最大性能,而变体的数量正在迅速增长。然而,大多数注意力变体与标准注意力具有相似的结构,因此我们可以使用与标准注意力相同的骨架,但带有小修改的 FlashAttention 内核去适配兼容。
受到FlexAttention(He et al., 2024)的启发,我们设计了一个可定制的 CUDA 模板和一个 JIT 编译器,该编译器以注意力变体规范作为输入并生成优化的内核代码。变体规范包括以下函数:
- QueryTransform, KeyTransform, ValueTransform:在注意力计算之前应用于查询/键/值张量的转换。
- OutputTransform:在返回之前应用于注意力输出张量的转换。
- LogitsTransform, LogitsMask:在 softmax 计算之前应用于 logits 张量的转换,以及应用于 logits 张量的掩码。
每个函数都有一个固定的签名,接收内核参数、输入和当前查询/键/头索引作为输入,并返回输出。这些变体函数作为用户定义的变体类的成员,创建变体函数的闭包。这些函数的具体实现方式需要根据不同的注意力变体需求进行设计。例如,在实现自定义掩码时,需要注意掩码的维度和应用方式,以确保其与标准注意力计算的兼容性。
其中,LogitsTransform 和 LogitsMask 函数受到 FlexAttention(He et al., 2024)的启发,可用于实现具有自定义掩码、logits 软上限(Rivière et al., 2024; xAI, 2023)和滑动窗口注意力(Beltagy et al., 2020)等自定义 logits 后处理的注意力变体。
FlashInfer 在其注意力变体规范中提供了使用 softmax 或不使用 softmax 的选项,使其能够支持不使用 softmax 的注意力变体,例如 FlashSigmoid(Ramapuram et al., 2024)。
FlashInfer 的查询和键转换函数使其能够将归一化、RoPE(Su et al., 2024)和投影(DeepSeek-AI et al., 2024)融合到注意力内核中。

图 5 展示了 FlashInfer 如何将 FlashSigmoid 的注意力规范映射到 FlashInfer 的 CUDA 模板的不同部分。注意力规范接受一段 CUDA 代码以定义变体函数,这样的设计还允许用户使用高级 PTX 指令或甚至他们自己的库。
JIT 编译器通过将变体类和其他信息插入模板中生成 CUDA 代码,生成的 CUDA 代码使用 PyTorch 的 JIT 编译器进行编译,并注册为自定义操作符。我们还支持通过框架不可知的 DLPack 接口编译到其他运行时系统。
3.3 动态感知运行时
在本节中,我们介绍 FlashInfer 的运行时设计,包括动态调度框架和可组合格式以实现内存高效的注意力计算。
3.3.1 负载均衡调度
FlashInfer 的负载均衡调度算法旨在通过在所有 SM 上均匀分布工作负载来最小化 SM 的空闲时间。
它以查询/输出和键/值维度的序列长度信息为输入,并生成工作负载与协同线程阵列(CTA)之间的映射,以及部分和最终输出之间的索引映射。该算法如下:

我们的方法受到 Stream-K(Osama et al., 2023)的启发;然而,由于 LLM 服务需要确定性输出,我们没有在 Stream-K 实现中引入原子聚合以避免非确定性行为。调度算法在提供相同的序列长度信息时生成确定性的聚合顺序。
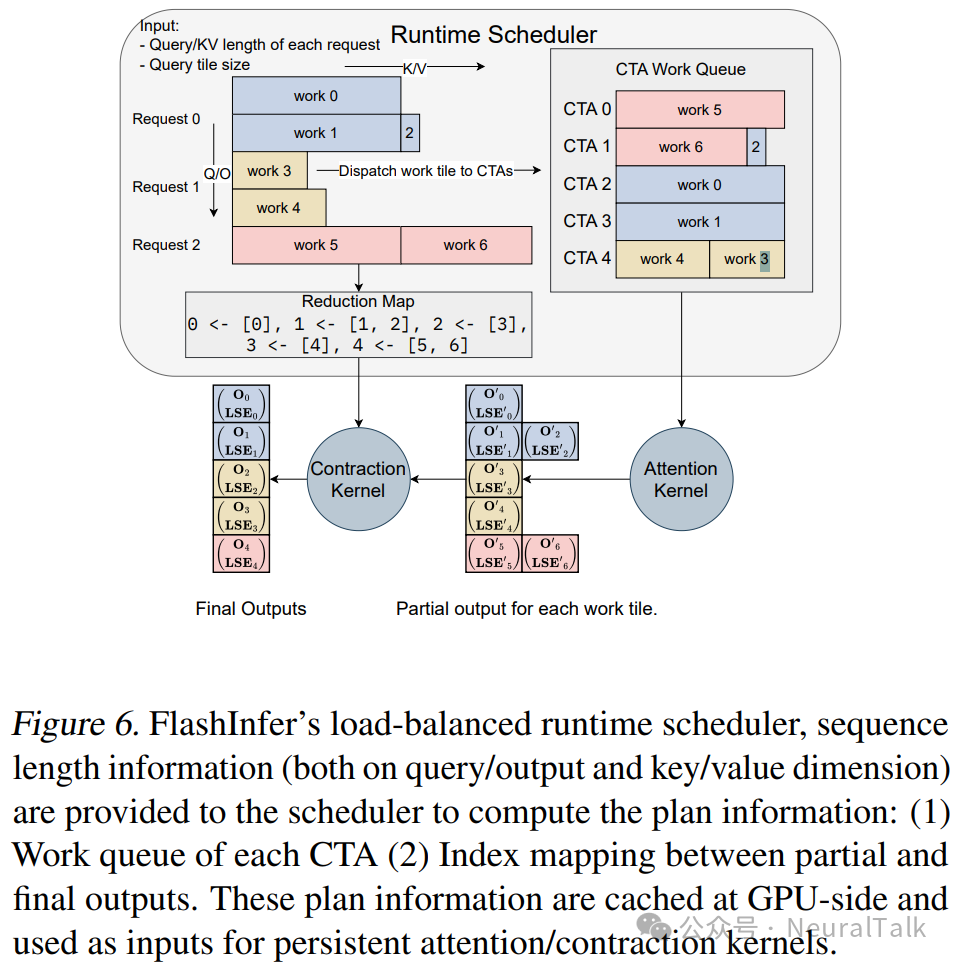
图 6 展示了 FlashInfer 的运行时调度程序的工作流程。注意力内核不会直接产生最终输出,因为某些长 KV 被分成多个块,最终输出是所有块的部分输出的收缩(使用第 2.2 节中提到的注意力组合操作符)。部分输出存储在用户提供的工作区缓冲区中(见第 3.4 节)。
FlashInfer 实现了能够处理可变长度聚合的高效注意力组合操作符。每个 CTA 的工作队列和部分到最终输出的索引映射需要由调度程序计划
。一旦在 CPU 上计算出计划信息,FlashInfer 会将计划信息异步复制到 GPU 上的工作区缓冲区中的特定区域,并且计划信息作为持续注意力/组合内核的输入。调度程序在每一代生成步骤中运行以产生计划信息,因为每个生成步骤的序列长度会变化,开销可以在多个层中分摊,因为所有层都可以重用相同的工作区缓冲区。
FlashInfer 确保注意力和组合阶段都与 CUDA 图(CUDAGraphs)(Gray, 2019; Nguyen et al., 2021)兼容。注意力和组合阶段都使用持续内核,且网格大小在编译时固定,这意味着每个生成步骤都以相同的网格大小启动内核。我们为工作区缓冲区的每个部分设置固定的偏移量,以存储部分输出和计划信息,以确保传递给内核的指针在每个生成步骤中相同,满足 CUDA 图的要求(详见附录 D.1)。我们将两个阶段合并为一个持续内核,消除了内核内的开销。
3.4 编程接口
FlashInfer 提供了与现有 LLM 服务框架(如vLLM(Kwon et al., 2023)、MLC-Engine(MLC Community, 2024)和SGLang(Zheng et al., 2023b))无缝集成的编程接口。
下面的代码展示了 FlashInfer 的 PyTorch 编程接口。
# Create workspace buffer
workspace = torch.empty(...)
seqlen_info.init()
# Compile: create CUDAGraphs
graphs = []
for task_info in task_infos:
# Init: compile kernels according to spec
attn = AttentionWrapper(attn_spec, task_info, workspace)
g = torch.cuda.CUDAGraph()
# Dummy plan
attn.plan(seqlen_info)
# Capture CUDA graphs
with torch.cuda.graph(g):
for i, layer in enumerate(layers):
...
attn.run(...)
...
graphs.append(g)
# Runtime: select the best CUDAGraph
g = select_graph(graphs)
finished = False
# Text generation loop
whilenot finished:
seqlen_info.update()
# Plan per generation step
attn.plan(seqlen_info)
# Replay CUDA−Graph
g.replay()
用户通过提供注意力变体规范、任务信息和用户分配的工作区 buffer(详见附录 D)来初始化包装器,以存储 FlashInfer 动态调度的部分输出和计划信息。
工作区 Buffer
FlashInfer 管理一个页面锁定(page-locked,固定)的主机 buffer 和一个设备工作空间 buffer,用于存储调度器元数据和拆分 $K$ 的中间输出。
我们将设备工作空间 buffer 划分为多个部分,每个部分对应于调度器元数据或拆分 K 中间输出的数组。对于调度器中的每个计划调用,我们在固定的主机 buffer 上计算调度器元数据,然后发起一个 cudaMemcpyAsync 操作,将这些数据传输到设备工作空间 buffer 的相应部分。
内核在初始化时通过 JIT 编译并缓存以供重用。对于可组合格式(见第 3.1.2 节),FlashInfer 创建多个注意力包装器,每个包装器具有不同的块大小。根据平均查询长度和可组合格式配置编译内核,并在不同的 CUDA 图中捕获。在运行时,服务框架根据当前 KV 缓存配置选择最合适的 CUDA 图,以确保针对变化的工作负载特性实现最佳性能。
计划函数通过处理序列长度数据来激活动态调度程序,以生成负载均衡的调度计划。这些计划是可缓存的,允许具有匹配序列长度规范的运算符重用,例如生成步骤中的所有解码注意力。
运行函数使用查询、键、值和缓存的计划数据作为输入执行注意力计算,并输出注意力结果。CUDA 图可以捕获对运行函数的调用,并将整个注意力生成步骤编译为单个图。然而,计划函数不会被捕获到 CUDA 图中,因为它是在 CPU 上运行的。计划和运行的分离受到 Inspector-Executor(IE)模型(Mirchandaney et al., 1988; Saltz & Mirchandaney, 1991; Ponnusamy et al., 1993)的启发,该模型广泛用于并行化不规则工作负载。
四、评估
在本节中,我们在内核级和端到端性能方面评估 FlashInfer v0.2,展示 FlashInfer 的设计如何应对 LLM 服务中的挑战。
与现有的 LLM 服务解决方案相比,FlashInfer 在 LLM 服务基准测试中实现了 29-69%的 token 间延迟减少,在长上下文推理中实现了 28-30%的延迟减少,在并行生成的 LLM 服务中实现了 13-17%的加速。
我们在 NVIDIA A100 40GB SXM 和 H100 80GB SXM GPU 上进行实验,使用 CUDA 12.4 和 PyTorch 2.4.0,并采用 f16 精度进行存储和计算。
4.1 端到端 LLM 服务性能
我们在 SGLang v0.3.4(Zheng et al., 2023b)上评估 FlashInfer,并将其性能与两种设置进行对比:一种是使用 Triton v3.0(Tillet et al., 2019)的 SGLang。Triton 是针对 NVIDIA GPU 优化的领先 LLM 服务引擎;然而,其注意力内核是封闭源码的,这限制了透明度和社区驱动的改进潜力。
为了确保全面评估,我们使用了两个数据集:广泛使用的 ShareGPT 数据集和一个合成工作负载(Variable),其中序列长度在 512 到 2048 个 token 之间均匀分布。我们在延迟敏感的在线服务设置中测量了首次 token 时间(TTFT)和 token 间延迟(ITL),调整请求速率以保持 P99 TTFT 低于 200 毫秒。
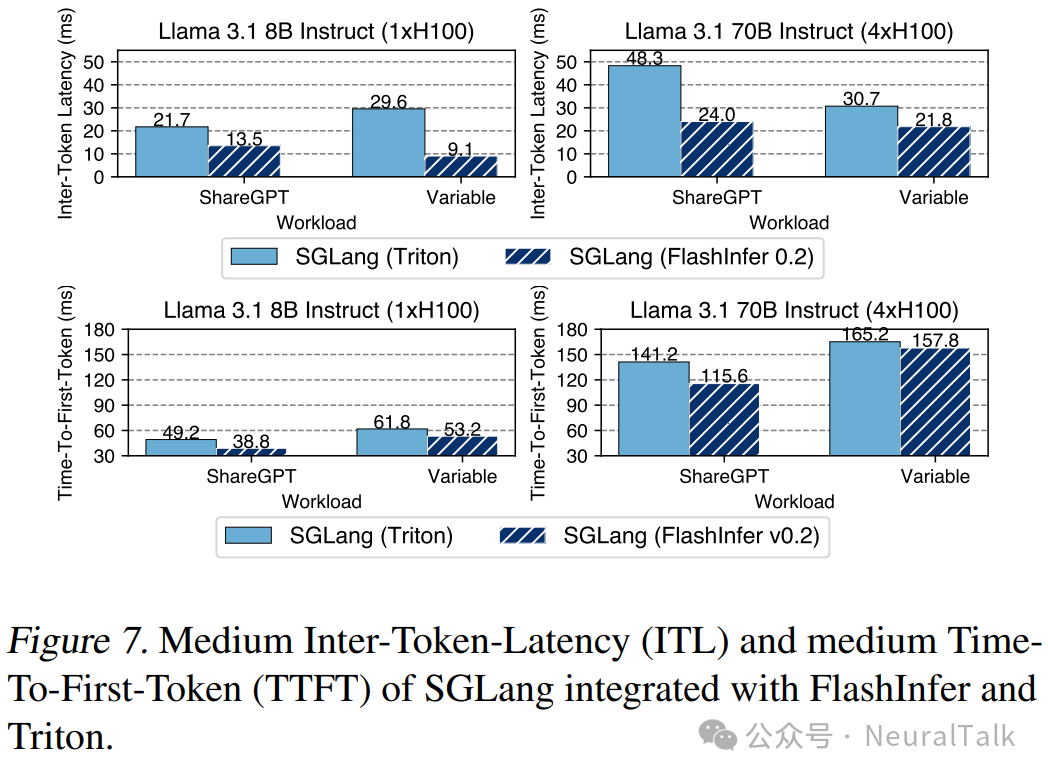
图 7 展示了在 1xH100 上的 Llama 3.1(Dubey et al., 2024)8B 和在 4xH100 上的 Llama 3.1 70B 模型的 ITL 和 TTFT。与使用 Triton 后端的 SGLang 相比,FlashInfer 后端在所有设置中均显示出一致的加速效果。
4.2 输入动态性的内核性能
在本节中,我们测量 FlashInfer 生成的内核性能,并与最新的开源 FlashAttention 库进行对比,后者同时包含 FlashAttention2 和 FlashAttention3 内核。我们将批量大小固定为 16,并选择三种不同的序列长度分布:恒定(1024)、均匀(512 到 1024)和偏斜(Zipf 分布,平均长度为 1024)。对于预填充内核,我们启用了因果掩码,因为这是 LLM 服务中的常见设置。
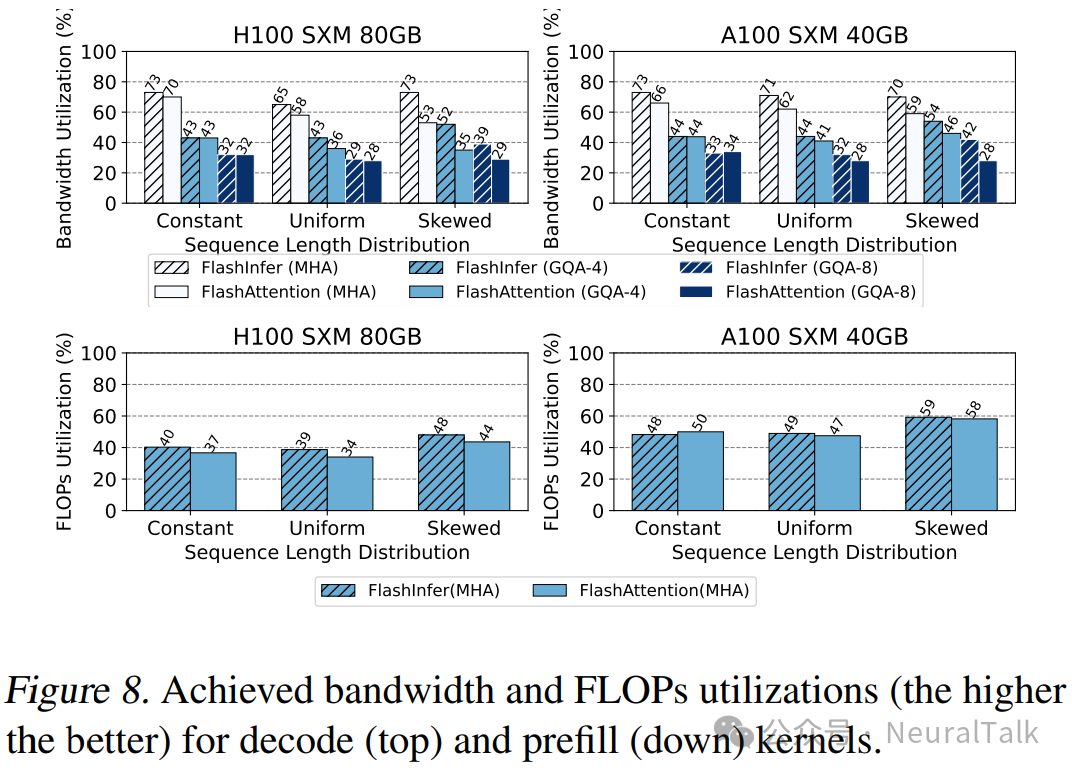
图 8 展示了预填充和解码内核的带宽利用率和 FLOPs 利用率。在均匀和偏斜的序列长度分布中,FlashInfer 的内核显著优于 FlashAttention 内核,这归功于我们针对输入动态性的负载均衡动态调度器(见第 3.3.1 节)。
FlashInfer 的解码注意力性能优于 FlashAttention 内核,因为我们的灵活瓦片大小选择(见第 3.2.2 节)使 FlashInfer 在解码中表现更佳,而 FlashAttention 在解码中使用的瓦片大小并不理想。
4.3 长上下文推理的可定制性
在本节中,我们展示 FlashInfer 的自定义注意力内核如何显著加速 LLM 推理。
我们重点关注 Streaming-LLM(Xiao et al., 2023),这是一种能够以恒定的 GPU 内存使用量进行百万 token 推理的最新算法。Streaming-LLM 需要专用的注意力内核才能实现最佳性能,特别是将 RoPE(Su et al., 2024)与注意力融合的内核。
FlashInfer 仅需额外 20 行代码即可生成这样的融合内核,用于查询/键转换。我们将 FlashInfer 生成的融合内核与未融合内核(FlashInfer 和 FlashAttention 的)进行对比,并量化将 FlashInfer 内核集成到 StreamingLLM 中的端到端延迟减少。
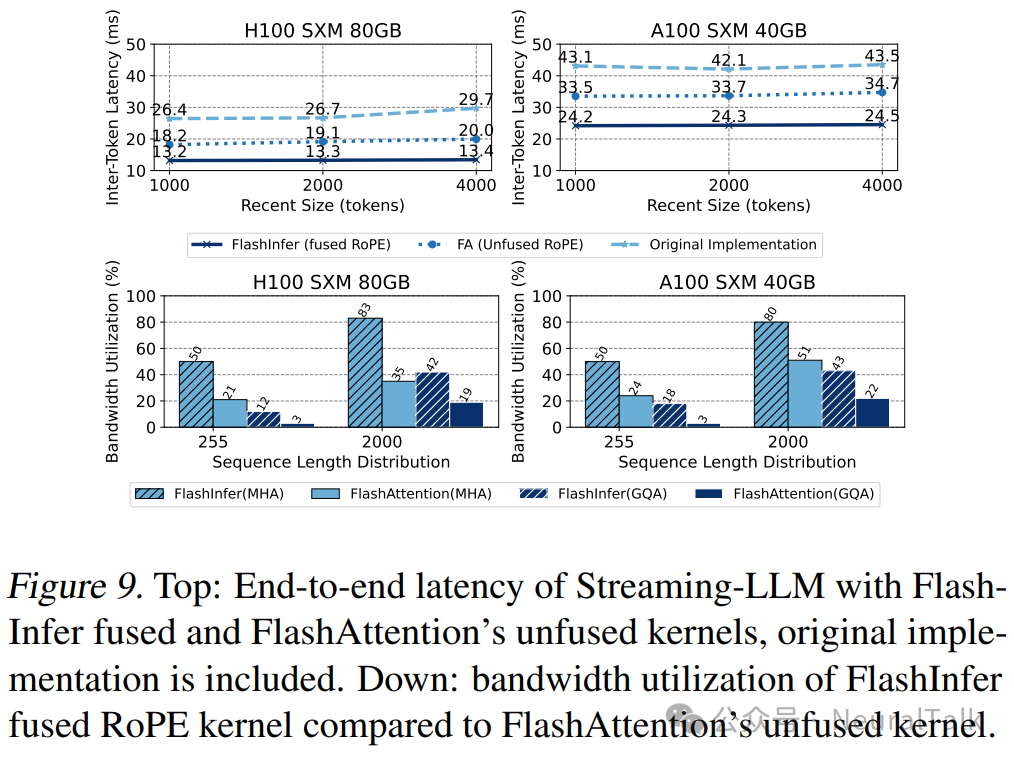
对于端到端性能,我们在 MT-Bench(Zheng et al., 2023a)数据集上运行 Vicuna-13B(Chiang et al., 2023)推理,并测量 Streaming-LLM 在集成 FlashInfer 内核前后的 ITL。图 9 展示了在优化的 Streaming-LLM 实现中,带有和不带有 FlashInfer 融合内核的 ITL。
FlashInfer 的融合 RoPE 内核可以在不同的设置下(通过更改 Streaming-LLM 的最近窗口大小)实现 28-30%的延迟减少。我们还将原始实现作为基线参考。
我们还展示了 FlashInfer 融合 RoPE 内核与 FlashAttention 的 RoPE 内核和注意力内核组合之间的内核级性能对比。FlashInfer 的融合 RoPE 内核在带宽利用率上比未融合注意力与 RoPE 高出 1.6-3.7 倍,这凸显了注意力内核可定制性的重要性。
4.4 并行生成性能
在本节中,我们展示了 FlashInfer 的可组合格式如何增强并行解码。
随着并行生成在 LLM 服务中的重要性日益增加,它在 LLM 代理中具有巨大的实用性。OpenAI API 提供了“n”参数来支持同时生成多个 token。由于共享前缀通常存在,前缀缓存可以显著提高并行生成的效率。FlashInfer 的可组合格式(见第 3.1.2 节)允许将共享前缀和后续后缀的注意力计算解耦,这可以用来加速并行解码。
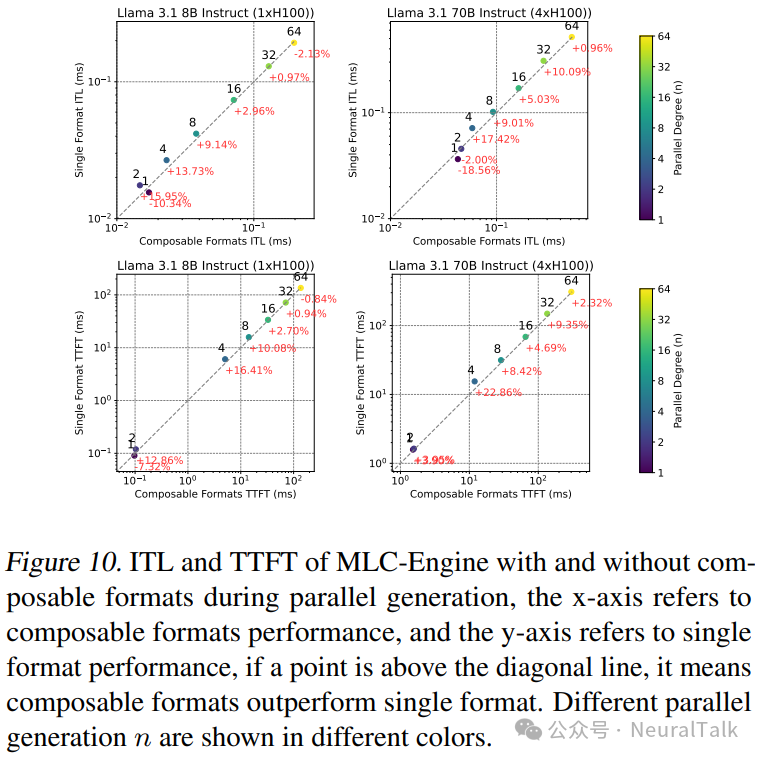
我们在 MLC-Engine(MLC Community, 2024)中实现了带有前缀缓存配置的可组合格式,并在 ShareGPT 数据集上评估了其在并行生成中的性能。在固定请求速率为 16 的情况下,我们改变了并行 token 的数量,并与未启用可组合格式的 MLC-Engine 配置进行了对比。图 10 展示了在启用和禁用可组合格式时的 ITL(推理延迟)和 TTFT(首次 token 时间)结果。
对于中等程度的并行生成(4 ≤ n ≤ 32),FlashInfer 的可组合格式在 ITL 和 TTFT 方面均显示出一致的加速效果。在 n=4 时,8B 模型的 ITL 减少了 13.73%,70B 模型减少了 17.42%,而 8B 模型的 TTFT 减少了 16.41%,70B 模型减少了 22.86%。对于较小的 n 值,由于块大小的增加不足以提高效率,因此不会从可组合格式中受益。对于较大的 n 值,由于计算不再由注意力过程主导(特别是在 ShareGPT 的短序列长度情况下),可组合格式的优势趋于平稳。
五、相关工作
5.1 注意力优化
多头注意力(MHA)(Vaswani et al., 2017)在计算和 IO 方面面临挑战。NVIDIA 的 FasterTransformer(2021)通过融合多头注意力(FMHA)减少全局内存占用,但无法扩展到长上下文,因为共享内存占用与序列长度成线性关系。
ByteTransformer(Zhai et al., 2023)优化了可变长度输入的 FMHA。FlashAttention(Dao et al., 2022)使用在线 softmax 技巧(Milakov & Gimelshein, 2018)将共享内存占用减少到常量大小,从而支持长上下文。
FlashAttention2&3(Dao, 2023; Shah et al., 2024)通过改进循环结构和重叠 softmax 与 GEMM 进一步优化 FlashAttention。FlashDecoding(Dao et al., 2023)将 Split-K 应用于解码注意力内核。LeanAttention(Sanovar et al., 2024)使用 StreamK(Osama et al., 2023)减少注意力中的波浪量化。
FlashInfer 扩展了 FlashAttention2&3 的模板以支持稀疏注意力内核,同时在可变长度序列上应用了类似 StreamK 的优化。Nanoflow(Zhu et al., 2024a)引入了水平融合 GEMM、注意力和通信操作,而 POD-Attention(Kamath et al., 2024)专注于优化分块预填充注意力。FlashInfer 的 JIT 编译框架可以扩展以生成支持这些融合技术的内核。
FlashDecoding++(Hong et al., 2024)利用注意力比例统计预先定义统一的最大值,将注意力组合(见第 2.2 节)转换为求和操作,从而启用 TMA 存储减少(Colfax, 2024)。这一过程与 FlashInfer 的贡献正交,我们将其留作未来工作。
5.2 GPU 上的稀疏优化
FusedMM(Rahman et al., 2021)探索了稀疏-稠密矩阵乘法(SpMM)的融合,但未包含 softmax 计算,限制了其直接加速注意力的能力。
Zhang et al.(2022)探索了图注意力网络(GAT)内核的融合,SAR(Mostafa, 2022)将稀疏注意力聚合序列化,类似于 FlashAttention,但这些工作均未探索张量核心的应用。
Blocksparse 库(Gray et al., 2017)实现了支持张量核心的 BSR GEMM。Chen et al.(2021)、TC-GNN(Wang et al., 2023)和 Magicube(Li et al., 2022)提出了向量稀疏格式以有效利用张量核心。
FlashInfer 改进了这些技术,支持任意块大小(br, bc)的 FlashAttention。
5.3 注意力编译器
FlexAttention(He et al., 2024)提供了用户友好的接口用于编程注意力变体,并将其编译为 Triton(Tillet et al., 2019)实现的块稀疏 flashattention。
它使用 PyTorch 编译器自动生成反向传播。FlashInfer 扩展了 FlexAttention 的编程接口以支持查询/键转换,并专注于向量稀疏性和 LLM 服务中的负载均衡。
FlashInfer 生成 CUDA 代码而非 Triton 代码,因为在许多用例中,Triton 在性能上仍落后于 CUDA 和 CUTLASS。FlashInfer 可以作为 FlexAttention 的前馈传递的后端。
Mirage(Wu et al., 2024)使用概率等价验证器优化 GEMM 和 FlashAttention 的瓦片策略,依赖 Triton 和 CUTLASS 进行代码生成。然而,它缺乏对可变长度和稀疏数据结构的支持,且不包括安全 softmax,与 FlashInfer 相比,FlashInfer 更直接适用于 LLM 服务。
5.4 LLM 服务系统
- Orca(Yu et al., 2022)引入了连续批处理以增强吞吐量。
- PagedAttention(Kwon et al., 2023)使用页表管理 KV 缓存。
- Sarathiserve(Agrawal et al., 2024)通过将解码操作与分块预填充 piggyback 来提高效率
- SGLang(Zheng et al., 2023b)利用基数树实现更好的前缀缓存和 KV 管理。
FlashInfer 通过块稀疏注意力内核为这些注意力机制提供统一的解决方案。
vAttention(Prabhu et al., 2024)展示了 GPU 虚拟内存可以管理页表中的地址转换而无需专用内核。然而,动态 KV 缓存稀疏性等挑战仍然存在,如 Quest(Tang et al., 2024)所示。在此背景下,FlashInfer 的块稀疏内核依然有效。
此外,FlashInfer 可以与 vAttention 结合使用,为连续 KV 缓存存储生成内核。
六、讨论
目前,FlashInfer 仅支持注意力计算的前向传递。为了将 FlashInfer扩展到训练应用,需要开发可定制的后向注意力内核模板,这是我们未来工作的计划。
关于 FlashInfer 的通用性,我们的方法将计算与瓦片(tile)调度解耦,允许多样化的瓦片策略,如 FlashDecoding(Hong et al., 2024)和 Lean Attention(Sanovar et al., 2024),通过将调度委托给运行时调度器而非将其嵌入注意力模板中。
此设计推广了调度算法,如第 3.3.1 节中的算法,用于负载均衡和波浪量化减少,同时针对不同 GPU 架构(例如,针对 Turing/Ampere/Ada 的 FlashAttention2(Dao, 2023)和针对 Hopper 的 FlashAttention3(Shah et al., 2024))实现最佳 GPU 性能。
尽管像Triton(Tillet et al., 2019)这样的框架提供了 GPU 不可知的接口,但它们在采用新硬件特性方面往往滞后;我们的模板设计空间,表示为 fepilogue(scan(flogits(fq(Q)· fk(K))) · fv(V)),涵盖了大多数注意力函数,包括最近的变体,如多头潜在注意力(MLA)(DeepSeek-AI et al., 2024)和线性注意力的内部注意力组件(Yang et al., 2024)。
七、结论与未来工作
本文介绍了 FlashInfer,一个用于 LLM 服务的灵活高效的注意力引擎。
我们提出了统一的块稀疏存储和可组合格式以实现内存效率,JIT 编译以实现可定制性,以及动态感知运行时以处理输入动态性。我们在多样化的推理场景中评估了 FlashInfer 的性能,展示了在内核级和端到端 LLM 服务指标中的强大性能。
在未来,我们计划探索将更高级别的 DSL(Wu et al., 2024; He et al., 2024)编译为 FlashInfer 中的注意力规范,以及将代码生成扩展到其他后端(Ozen, 2024; Spector et al., 2024; Tillet et al., 2019)。
FlashInfer 项目是开源的,可在https://github.com/flashinfer...获取,并已在生产级系统中大规模部署。
参考文献
- Agrawal, A., Kedia, N., Panwar, A., Mohan, J., Kwatra, N., Gulavani, B. S., Tumanov, A., and Ramjee, R.Taming throughput-latency tradeoff in llm inference with sarathiserve . Proceedings of 18th USENIX Symposium on Operating Systems Design and Implementation, 2024, Santa Clara, 2024.
- Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebrón, F., and Sanghai, S.GQA: training generalized multi-query transformer models from multi-head checkpoints . In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pp. 4895–4901. Association for Computational Linguistics, 2023. doi:10.18653/V1/2023.EMNLP-MAIN.298. URL https://doi.org/10.18653/v1/2...
- Ansel, J., Yang, E., He, H., Gimelshein, N., Jain, A., Voznesensky, M., Bao, B., Bell, P., Berard, D., Burovski, E., Chauhan, G., Chourdia, A., Constable, W., Desmaison, A., DeVito, Z., Ellison, E., Feng, W., Gong, J., Gschwind, M., Hirsh, B., Huang, S., Kalambakar, K., Kirsch, L., Lazos, M., Lezcano, M., Liang, Y., Liang, J., Lu, Y., Luk, C. K., Maher, B., Pan, Y., Puhrsch, C., Reso, M., Saroufim, M., Siraichi, M. Y., Suk, H., Zhang, S., Suo, M., Tillet, P., Zhao, X., Wang, E., Zhou, K., Zou, R., Wang, X., Mathews, A., Wen, W., Chanan, G., Wu, P., and Chintala, S.Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’24, pp. 929–947, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 9798400703850. doi:10.1145/3620665.3640366. URL https://doi.org/10.1145/36206...
- Beltagy, I., Peters, M. E., and Cohan, A.Longformer: The long-document transformer . CoRR, abs/2004.05150, 2020. URL https://arxiv.org/abs/2004.05...
- Buluç, A., Fineman, J. T., Frigo, M., Gilbert, J. R., and Leiserson, C. E.Parallel sparse matrix-vector and matrix-transpose-vector multiplication using compressed sparse blocks. In auf der Heide, F. M. and Bender, M. A. (eds.), SPAA 2009: Proceedings of the 21st Annual ACM Symposium on Parallelism in Algorithms and Architectures, Calgary, Alberta, Canada, August 11-13, 2009, pp. 233–244. ACM, 2009. doi:10.1145/1583991.1584053. URL https://doi.org/10.1145/15839...
- Cai, T., Li, Y., Geng, Z., Peng, H., Lee, J. D., Chen, D., and Dao, T.Medusa: Simple LLM inference acceleration framework with multiple decoding heads. CoRR, abs/2401.10774, 2024. doi:10.48550/ARXIV.2401.10774. URL https://doi.org/10.48550/arXi...
- Chen, Z., Qu, Z., Liu, L., Ding, Y., and Xie, Y.Efficient tensor core-based GPU kernels for structured sparsity under reduced precision. In de Supinski, B. R., Hall, M. W., and Gamblin, T. (eds.), International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2021, St. Louis, Missouri, USA, November 14-19, 2021, pp. 78. ACM, 2021. doi:10.1145/3458817.3476182. URL https://doi.org/10.1145/34588...
- Chen, Z., May, A., Svirschevski, R., Huang, Y., Ryabinin, M., Jia, Z., and Chen, B.Sequoia: Scalable, robust, and hardware-aware speculative decoding . CoRR, abs/2402.12374, 2024. doi:10.48550/ARXIV.2402.12374. URL https://doi.org/10.48550/arXi...
- Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J. E., Stoica, I., and Xing, E. P.Vicuna: An open-source chatbot impressing gpt-4 with 90% chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-0...
- Colfax.Cutlass tutorial: Mastering the nvidia tensor memory accelerator (TMA) , 2024. URL https://research.colfax-intl....
- Dao, T.Flashattention-2: Faster attention with better parallelism and work partitioning . CoRR, abs/2307.08691, 2023. doi:10.48550/ARXIV.2307.08691. URL https://doi.org/10.48550/arXi...
- Dao, T., Fu, D. Y., Ermon, S., Rudra, A., and Ré, C.Flashattention: Fast and memory-efficient exact attention with io-awareness . In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_f...
- Dao, T., Haziza, D., Massa, F., and Sizov, G.Flash-decoding for long-context inference , 2023.
- DeepSeek-AI, Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Deng, C., Ruan, C., Dai, D., Guo, D., Yang, D., Chen, D., Ji, D., Li, E., Lin, F., Luo, F., Hao, G., Chen, G., Li, G., Zhang, H., Xu, H., Yang, H., Zhang, H., Ding, H., Xin, H., Gao, H., Li, H., Qu, H., Cai, J. L., Liang, J., Guo, J., Ni, J., Li, J., Chen, J., Yuan, J., Qiu, J., Song, J., Dong, K., Gao, K., Guan, K., Wang, L., Zhang, L., Xu, L., Xia, L., Zhao, L., Zhang, L., Li, M., Wang, M., Zhang, M., Zhang, M., Tang, M., Li, M., Tian, N., Huang, P., Wang, P., Zhang, P., Zhu, Q., Chen, Q., Du, Q., Chen, R. J., Jin, R. L., Ge, R., Pan, R., Xu, R., Chen, R., Li, S. S., Lu, S., Zhou, S., Chen, S., Wu, S., Ye, S., Ma, S., Wang, S., Zhou, S., Yu, S., Zhou, S., Zheng, S., Wang, T., Pei, T., Yuan, T., Sun, T., Xiao, W. L., Zeng, W., An, W., Liu, W., Liang, W., Gao, W., Zhang, W., Li, X. Q., Jin, X., Wang, X., Bi, X., Liu, X., Wang, X., Shen, X., Chen, X., Chen, X., Nie, X., and Sun, X.Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. CoRR, abs/2405.04434, 2024. doi:10.48550/ARXIV.2405.04434. URL https://doi.org/10.48550/arXi...
- Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Rodriguez, A., Gregerson, A., Spataru, A., Rozière, B., Biron, B., Tang, B., Chern, B., Caucheteux, C., Nayak, C., Bi, C., Marra, C., McConnell, C., Keller, C., Touret, C., Wu, C., Wong, C., Ferrer, C. C., Nikolaidis, C., Allonsius, D., Song, D., Pintz, D., Livshits, D., Esiobu, D., Choudhary, D., Mahajan, D., Garcia-Olano, D., Perino, D., Hupkes, D., Lakomkin, E., AlBadawy, E., Lobanova, E., Dinan, E., Smith, E. M., Radenovic, F., Zhang, F., Synnaeve, G., Lee, G., Anderson, G. L., Nail, G., Mialon, G., Pang, G., Cucurell, G., Nguyen, H., Korevaar, H., Xu, H., Touvron, H., Zarov, I., Ibarra, I. A., Kloumann, I. M., Misra, I., Evtimov, I., Copet, J., Lee, J., Geffert, J., Vranes, J., Park, J., Mahadeokar, J., Shah, J., Fu, J., Chi, J., Huang, J., Liu, J., Yu, J., Bitton, J., Spisak, J., Park, J., Rocca, J., Johnstun, J., Saxe, J., Jia, J., Alwala, K. V., Upasani, K., Plawiak, K., Li, K., Heafield, K., Stone, K., and et al.The llama 3 herd of models . CoRR, abs/2407.21783, 2024. doi:10.48550/ARXIV.2407.21783. URL https://doi.org/10.48550/arXi...
- Gray, A.Getting Started with CUDA Graphs | NVIDIA Technical Blog. https://developer.nvidia.com/..., 2019. [Accessed 19-102024].
- Gray, S., Radford, A., and Kingma, D. P.Gpu kernels for block-sparse weights. arXiv preprint arXiv:1711.09224, 3(2):2, 2017.
- Gupte, M.Mixed-input matrix multiplication performance optimizations. https://research.google/blog/..., January 2024. Google Research Blog, Accessed: 2024-01-26.
- He, H., Guessous, D., Liang, Y., and Dong, J.Flexattention: The flexibility of pytorch with the performance of flashattention, Aug 2024. URL https://pytorch.org/blog/flex...
- Hong, K., Dai, G., Xu, J., Mao, Q., Li, X., Liu, J., chen, k., Dong, Y., and Wang, Y.Flashdecoding++: Faster large language model inference with asynchronization, flat gemm optimization, and heuristics. In Gibbons, P., Pekhimenko, G., and Sa, C. D. (eds.), Proceedings of Machine Learning and Systems, volume 6, pp. 148–161, 2024. URL https://proceedings.mlsys.org...
- Im, E., Yelick, K. A., and Vuduc, R. W.Sparsity: Optimization framework for sparse matrix kernels . Int. J. High Perform. Comput. Appl., 18(1):135–158, 2004. doi:10.1177/1094342004041296. URL https://doi.org/10.1177/10943...
- Juravsky, J., Brown, B. C. A., Ehrlich, R. S., Fu, D. Y., Ré, C., and Mirhoseini, A.Hydragen: High-throughput LLM inference with shared prefixes . CoRR, abs/2402.05099, 2024. doi:10.48550/ARXIV.2402.05099. URL https://doi.org/10.48550/arXi...
- Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J., Zhang, H., and Stoica, I.Efficient memory management for large language model serving with pagedattention. In Flinn, J., Seltzer, M. I., Druschel, P., Kaufmann, A., and Mace, J. (eds.), Proceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, Koblenz, Germany, October 23-26, 2023, pp. 611–626. ACM, 2023. doi:10.1145/3600006.3613165. URL https://doi.org/10.1145/36000...
- Lai, R., Shao, J., Feng, S., Lyubomirsky, S. S., Hou, B., Lin, W., Ye, Z., Jin, H., Jin, Y., Liu, J., Jin, L., Cai, Y., Jiang, Z., Wu, Y., Park, S., Srivastava, P., Roesch, J. G., Mowry, T. C., and Chen, T.Relax: Composable abstractions for end-to-end dynamic machine learning.
- Liu, H. and Abbeel, P.Blockwise parallel transformers for large context models. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_f...
- Liu, H., Zaharia, M., and Abbeel, P.Ring attention with blockwise transformers for near-infinite context. CoRR, abs/2310.01889, 2023. doi:10.48550/ARXIV.2310.01889. URL https://doi.org/10.48550/arXi...
- Miao, X., Oliaro, G., Zhang, Z., Cheng, X., Wang, Z., Zhang, Z., Wong, R. Y. Y., Zhu, A., Yang, L., Shi, X., Shi, C., Chen, Z., Arfeen, D., Abhyankar, R., and Jia, Z.Specinfer: Accelerating large language model serving with tree-based speculative inference and verification . In Gupta, R., Abu-Ghazaleh, N. B., Musuvathi, M., and Tsafrir, D. (eds.), Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ASPLOS 2024, La Jolla, CA, USA, 27 April 2024- 1 May 2024, pp. 932–949. ACM, 2024. doi:10.1145/3620666.3651335. URL https://doi.org/10.1145/36206...
- Micikevicius, P., Stosic, D., Burgess, N., Cornea, M., Dubey, P., Grisenthwaite, R., Ha, S., Heinecke, A., Judd, P., Kamalu, J., Mellempudi, N., Oberman, S. F., Shoeybi, M., Siu, M. Y., and Wu, H.FP8 formats for deep learning. CoRR, abs/2209.05433, 2022. doi:10.48550/ARXIV.2209.05433. URL https://doi.org/10.48550/arXi...
- Milakov, M. and Gimelshein, N.Online normalizer calculation for softmax . CoRR, abs/1805.02867, 2018. URL http://arxiv.org/abs/1805.02867.
- Mirchandaney, R., Saltz, J. H., Smith, R. M., Nicol, D. M., and Crowley, K.Principles of runtime support for parallel processors. In Lenfant, J. (ed.), Proceedings of the 2nd international conference on Supercomputing, ICS 1988, Saint Malo, France, July 4-8, 1988, pp. 140–152. ACM, 1988. doi:10.1145/55364.55378. URL https://doi.org/10.1145/55364...
- MLC Community.Optimizing and characterizing high-throughput low-latency LLM inference in MLCEngine, Oct 2024. URL https://blog.mlc.ai/2024/10/1... [Online; accessed April 23, 2025].
- Mostafa, H.Sequential aggregation and rematerialization: Distributed full-batch training of graph neural networks on large graphs. In Marculescu, D., Chi, Y., and Wu, C. (eds.), Proceedings of Machine Learning and Systems 2022, MLSys 2022, Santa Clara, CA, USA, August 29 - September 1, 2022. mlsys.org, 2022. URL https://proceedings.mlsys.org...
- Narang, S., Undersander, E., and Diamos, G. F.Blocksparse recurrent neural networks . CoRR, abs/1711.02782, 2017. URL http://arxiv.org/abs/1711.02782.
- Nguyen, V., Carilli, M., Eryilmaz, S. B., Singh, V., Lin, M., Gimelshein, N., Desmaison, A., and Yang, E.Accelerating PyTorch with CUDA Graphs. https://pytorch.org/blog/acce..., 2021. [Accessed 19-10-2024].
- NVIDIA.FasterTransformer. https://github.com/NVIDIA/Fas..., 2021.
- NVIDIA.Nvidia hopper architecture in-depth , 2022. URL https://developer.nvidia.com/...
- NVIDIA.NVIDIA TensorRT-LLM, 2023a. URL https://docs.nvidia.com/tenso... [Online; accessed April 23, 2025].
- NVIDIA.Matrix multiplication background user’s guide , 2023b. URL https://docs.nvidia.com/deepl...
- NVIDIA.Spatial partitioning (also known as warp specialization), 2024a. URL https://docs.nvidia.com/cuda/...
- NVIDIA.New xqa-kernel provides 2.4x more llama-70b throughput within the same latency budget, 2024b. URL https://github.com/NVIDIA/Ten...
- Osama, M., Merrill, D., Cecka, C., Garland, M., and Owens, J. D.Stream-k: Work-centric parallel decomposition for dense matrix-matrix multiplication on the GPU. In Dehnavi, M. M., Kulkarni, M., and Krishnamoorthy, S. (eds.), Proceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, PPoPP 2023, Montreal, QC, Canada, 25 February 2023 - 1 March 2023, pp. 429–431. ACM, 2023. doi:10.1145/3572848.3577479. URL https://doi.org/10.1145/35728...
- Ozen, G.Nvdsl: Simplifying tensor cores with pythondriven mlir metaprogramming. In Efficient Systems for Foundation Models (ES-FoMo) Workshop at ICML 2024, 2024.
- Ponnusamy, R., Saltz, J. H., and Choudhary, A. N.Runtime compilation techniques for data partitioning and communication schedule reuse. In Borchers, B. and Crawford, D. (eds.), Proceedings Supercomputing ’93, Portland, Oregon, USA, November 15-19, 1993, pp. 361–370. ACM, 1993. doi:10.1145/169627.169752. URL https://doi.org/10.1145/16962...
- Prabhu, R., Nayak, A., Mohan, J., Ramjee, R., and Panwar, A.vattention: Dynamic memory management for serving llms without pagedattention, 2024.
- Press, O., Smith, N. A., and Lewis, M.Train short, test long: Attention with linear biases enables input length extrapolation . In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?...
- PyTorch-Labs.attention-gym. https://github.com/pytorch-la..., 2024.
- Rahman, M. K., Sujon, M. H., and Azad, A.Fusedmm: A unified sddmm-spmm kernel for graph embedding and graph neural networks. In 35th IEEE International Parallel and Distributed Processing Symposium, IPDPS 2021, Portland, OR, USA, May 17-21, 2021, pp. 256–266. IEEE, 2021. doi:10.1109/IPDPS49936.2021.00034. URL https://doi.org/10.1109/IPDPS...
- Ramapuram, J., Danieli, F., Dhekane, E. G., Weers, F., Busbridge, D., Ablin, P., Likhomanenko, T., Digani, J., Gu, Z., Shidani, A., and Webb, R.Theory, analysis, and best practices for sigmoid self-attention. CoRR, abs/2409.04431, 2024. doi:10.48550/ARXIV.2409.04431. URL https://doi.org/10.48550/arXi...
- Rivière, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ramé, A., Ferret, J., Liu, P., Tafti, P., Friesen, A., Casbon, M., Ramos, S., Kumar, R., Lan, C. L., Jerome, S., Tsitsulin, A., Vieillard, N., Stanczyk, P., Girgin, S., Momchev, N., Hoffman, M., Thakoor, S., Grill, J., Neyshabur, B., Bachem, O., Walton, A., Severyn, A., Parrish, A., Ahmad, A., Hutchison, A., Abdagic, A., Carl, A., Shen, A., Brock, A., Coenen, A., Laforge, A., Paterson, A., Bastian, B., Piot, B., Wu, B., Royal, B., Chen, C., Kumar, C., Perry, C., Welty, C., Choquette-Choo, C. A., Sinopalnikov, D., Wei, G., Cameron, G., Martins, G., Hashemi, H., Klimczak-Plucinska, H., Batra, H., Dhand, H., Nardini, I., Mein, J., Zhou, J., Svensson, J., Stanway, J., Chan, J., Zhou, J. P., Carrasqueira, J., Iljazi, J., Becker, J., Fernandez, J., van Amersfoort, J., Gordon, J., Lipschultz, J., Newlan, J., Ji, J., Mohamed, K., Badola, K., Black, K., Millican, K., McDonell, K., Nguyen, K., Sodhia, K., Greene, K., Sjösund, L. L., Usui, L., Sifre, L., Heuermann, L., Lago, L., and McNealus, L.Gemma 2: Improving open language models at a practical size. CoRR, abs/2408.00118, 2024. doi:10.48550/ARXIV.2408.00118. URL https://doi.org/10.48550/arXi...
- Saltz, J. H. and Mirchandaney, R.The preprocessed doacross loop. In Proceedings of the International Conference on Parallel Processing, ICPP ’91, Austin, Texas, USA, August 1991. Volume II: Software, pp. 174–179. CRC Press, 1991.
- Sanovar, R., Bharadwaj, S., Amant, R. S., Rühle, V., and Rajmohan, S.Lean attention: Hardware-aware scalable attention mechanism for the decode-phase of transformers. CoRR, abs/2405.10480, 2024. doi:10.48550/ARXIV.2405.10480. URL https://doi.org/10.48550/arXi...
- Setaluri, R., Aanjaneya, M., Bauer, S., and Sifakis, E.Spgrid: a sparse paged grid structure applied to adaptive smoke simulation. ACM Trans. Graph., 33(6):205:1–205:12, 2014. doi:10.1145/2661229.2661269. URL https://doi.org/10.1145/26612...
- Shah, J., Bikshandi, G., Zhang, Y., Thakkar, V., Ramani, P., and Dao, T.Flashattention-3: Fast and accurate attention with asynchrony and low-precision. CoRR, abs/2407.08608, 2024. doi:10.48550/ARXIV.2407.08608. URL https://doi.org/10.48550/arXi...
- Shazeer, N.Fast transformer decoding: One write-head is all you need. CoRR, abs/1911.02150, 2019. URL http://arxiv.org/abs/1911.02150.
- Spector, B., Singhal, A., Arora, S., and Re, C.ThunderKittens: A Simple Embedded DSL for AI kernels, May 2024. URL https://hazyresearch.stanford...
- Su, J., Ahmed, M. H. M., Lu, Y., Pan, S., Bo, W., and Liu, Y.Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063, 2024. doi:10.1016/J.NEUCOM.2023.127063. URL https://doi.org/10.1016/j.neu...
- Tillet, P., Kung, H. T., and Cox, D.Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, MAPL 2019, pp. 10–19, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450367196. doi:10.1145/3315508.3329973. URL https://doi.org/10.1145/33155...
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I.Attention is all you need. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 5998–6008, 2017. URL https://proceedings.neurips.c...
- Wang, Y., Feng, B., Wang, Z., Huang, G., and Ding, Y.TC-GNN: bridging sparse GNN computation and dense tensor cores on gpus. In Lawall, J. and Williams, D. (eds.), 2023 USENIX Annual Technical Conference, USENIX ATC 2023, Boston, MA, USA, July 1012, 2023, pp. 149–164. USENIX Association, 2023. URL https://www.usenix.org/confer...
- Wu, M., Cheng, X., Padon, O., and Jia, Z.A multi-level superoptimizer for tensor programs. CoRR, abs/2405.05751, 2024. doi:10.48550/ARXIV.2405.05751. URL https://doi.org/10.48550/arXi...
- xAI.Open Release of Grok-1. https://x.ai/blog/grok-os, 2023. [Accessed 24-06-2024].
- Xiao, G., Tian, Y., Chen, B., Han, S., and Lewis, M.Efficient streaming language models with attention sinks . arXiv, 2023.
- Yang, S., Wang, B., Shen, Y., Panda, R., and Kim, Y. G.Gated linear attention transformers with hardware-efficient training, 2024. URL https://arxiv.org/abs/2312.06...
- Ye, L., Tao, Z., Huang, Y., and Li, Y.Chunkattention: Efficient self-attention with prefix-aware KV cache and two-phase partition. In Ku, L., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pp. 11608–11620. Association for Computational Linguistics, 2024. doi:10.18653/V1/2024.ACLLONG.623. URL https://doi.org/10.18653/v1/2...
- Yu, G., Jeong, J. S., Kim, G., Kim, S., and Chun, B.Orca: A distributed serving system for transformer-based generative models. In Aguilera, M. K. and Weatherspoon, H. (eds.), 16th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2022, Carlsbad, CA, USA, July 11-13, 2022, pp. 521–538. USENIX Association, 2022. URL https://www.usenix.org/confer...
- Zhai, Y., Jiang, C., Wang, L., Jia, X., Zhang, S., Chen, Z., Liu, X., and Zhu, Y.Bytetransformer: A high-performance transformer boosted for variable-length inputs. In IEEE International Parallel and Distributed Processing Symposium, IPDPS 2023, St. Petersburg, FL, USA, May 15-19, 2023, pp. 344–355. IEEE, 2023. doi:10.1109/IPDPS54959.2023.00042. URL https://doi.org/10.1109/IPDPS...
- Zheng, L., Chiang, W., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I.Judging llm-as-a-judge with mt-bench and chatbot arena . In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023a. URL http://papers.nips.cc/paper_f...
- Zheng, L., Yin, L., Xie, Z., Huang, J., Sun, C., Yu, C. H., Cao, S., Kozyrakis, C., Stoica, I., Gonzalez, J. E., Barrett, C. W., and Sheng, Y.Efficiently programming large language models using sglang. CoRR, abs/2312.07104, 2023b. doi:10.48550/ARXIV.2312.07104. URL https://doi.org/10.48550/arXi...
- Zhu, K., Zhao, Y., Zhao, L., Zuo, G., Gu, Y., Xie, D., Gao, Y., Xu, Q., Tang, T., Ye, Z., Kamahori, K., Lin, C., Wang, S., Krishnamurthy, A., and Kasikci, B.Nanoflow: Towards optimal large language model serving throughput. CoRR, abs/2408.12757, 2024a. doi:10.48550/ARXIV.2408.12757. URL https://doi.org/10.48550/arXi...
- Zhu, L., Wang, X., Zhang, W., and Lau, R. W. H.Relayattention for efficient large language model serving with long system prompts . In Ku, L., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pp. 4945–4957. Association for Computational Linguistics, 2024b. doi:10.18653/V1/2024.ACLLONG.270. URL https://doi.org/10.18653/v1/2...
END
作者:FlashInfer
来源:NeuralTalk
推荐阅读
- FP4DiT:扩散 Transformer 模型 FP4 量化的革命性突破,开启边缘部署新时代
- 在 96 个 H100 GPU 上部署具有 PD 分解和大规模专家并行性的 DeepSeek
- 在 SGLang 中实现 Flash Attention 后端 - 基础和 KV 缓存
- 3.5 倍能效突破,Attention 和 Softmax 的 AI 加速器实现
- Qwen3:思深,行速
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区嵌入式AI专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

