
文档理解与转换技术已成为现代数字化流程中的核心组成部分。SmolDocling 作为该领域的前沿发展,代表了一种专为端到端文档转换设计的超紧凑视觉模型。该技术创新由 HuggingFace 与 IBM 联合研发,相关论文已于 2025 年 3 月发表。本文将深入分析 SmolDocling 的核心技术架构及其实现机制。

SmolDocling 基于 Hugging Face SmolVLM-256M 模型开发而来,是一款体积显著小于同类产品的紧凑型模型。与主流视觉模型相比,其体积减小了 5-10 倍,仅包含 2.56 亿个参数。尽管规模较小,其性能水平却足以与参数量为其 27 倍的大型视觉模型相媲美。
SmolDocling 的关键技术优势在于其全面表示文档页面内容与结构的能力。该模型不仅能够精确捕获文本内容,还能识别文档的整体结构以及页面元素的空间位置关系,为文档理解提供了更为完整的解决方案。
DocTags 格式详解
SmolDocling 采用名为"DocTags"的专用格式进行文档转换。DocTags 本质上是一种类 XML 标记语言,专门用于定义文档元素的核心属性。该格式具有以下技术特性:
DocTags 定义了文档元素的三个基本属性:元素类型、页面位置和内容。元素类型涵盖文本、图像、表格、代码、标题、脚注等内容组件;页面位置精确标识元素在页面上的空间坐标;内容则表示元素所包含的实际信息,可为文本或结构化数据。
DocTags 中的基本文档元素均由 XML 风格的标签封装。每个元素可附带额外的位置标签,用于表示其在页面上的精确位置。这种位置信息以边界框形式呈现,采用
<loc_x1><loc_y1><loc_x2><loc_y2>格式,其中:
- x1, y1:表示边界框左上角的坐标
- x2, y2:表示边界框右下角的坐标
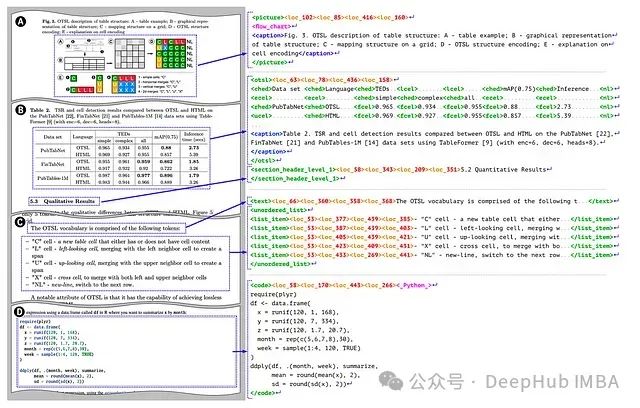
DocTags 通过标签嵌套提供多层级信息表示。图像和表格可包含由专用标题标签表示的标题信息;表格结构由 OTSL 标签定义,用于精确表达表格数据的组织形式;列表可嵌套列表项,实现信息的层次化组织;代码块和图像可携带分类信息(如编程语言或内容类型),为视觉或代码内容提供上下文语义。
相较于 HTML 或 Markdown 等标准格式,DocTags 具有显著技术优势。其清晰的标签结构减少了文档元素定义的歧义性;结构与内容的明确分离提高了处理效率;位置标签精确保留了原始页面布局;令牌优化机制最小化了总令牌数,提升了处理效率;此外,其结构化的一致数据格式显著增强了图像到序列模型的建模性能,实现了更高质量的输出生成。
架构设计
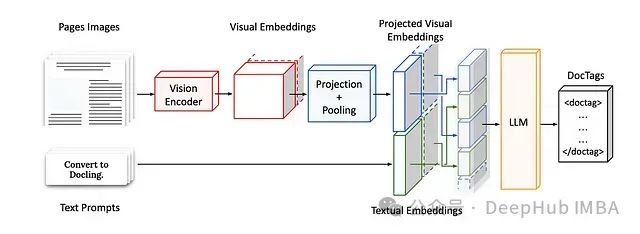
SmolDocling 采用了全面的端到端处理架构,用于将文档图像精确转换为 DocTags 格式。该架构包含以下关键技术模块:
输入处理模块接收页面图像(待处理的文档页面)和文本提示(提供转换指令,如"转换为 Docling")。视觉处理模块利用专用视觉编码器将页面图像转换为视觉嵌入表示,随后通过投影和池化操作将这些视觉嵌入转换为更为紧凑的数据格式。
嵌入集成模块将经投影处理的视觉嵌入(即视觉信息的结构化表示)与从文本提示生成的文本嵌入进行融合,生成模型的综合输入表示。输出生成模块采用语言模型(LLM)处理这些嵌入,生成 DocTags 格式的结构化输出。
此架构有效整合了图像理解与文本生成能力,通过端到端处理流程保留了文档的内容与结构特性。特别值得注意的是,LLM 的自回归特性使系统能够精确地将复杂文档结构转换为 DocTags 格式,确保了高质量的输出。
应用领域分析
SmolDocling 的技术架构适用于多种文档理解任务。其文档分类功能支持自动对不同类型文档进行精确分类;光学字符识别(OCR)能力实现了图像中文本的机器编码转换;布局分析功能可识别文档的结构组织及各部分之间的关联关系;表格识别功能能够保留结构完整性的同时提取表格数据。
在高级应用方面,SmolDocling 在键值提取任务中表现出色,能够识别文档中的关键信息对;其图形理解功能可解析数据可视化表示及其语义;数学方程识别能力支持将复杂公式转换为结构化格式。值得特别注意的是,该模型在提取代码、表格、图形和方程等复杂文档元素方面展现了卓越性能,这使其能够有效处理具有复杂结构的专业文档。
训练与数据集
SmolDocling 的开发团队充分利用了现有数据集资源,并针对数据不足的领域创建了专用数据集并开源发布。在模型训练过程中,研究人员应用了数据增强技术,并专门准备了特定数据集以增强模型对代码列表、数学方程和图形的理解能力。这种综合的数据策略显著提升了模型在多类型文档处理中的性能表现。
核心技术特性
SmolDocling 在多方面展现了技术创新,使其区别于其他文档理解模型:
阅读顺序保留机制:对于富含表格和图形等元素的内容,文档内的阅读顺序至关重要。SmolDocling 通过专门设计的算法保留了这种语义完整性,确保了信息解析的连贯性。
整体处理方法:与将转换问题分解为子任务的传统系统不同,SmolDocling 提供了端到端的综合解决方案,克服了系统适应性和泛化能力的限制。
位置感知技术:该模型采用边界框编码方式保留页面布局信息,实现了文档空间结构的精确表示。
性能评估
SmolDocling 在 DocLayNet 数据集上进行了全面评估,采用编辑距离、F1 分数、精确率、召回率、BLEU 和 METEOR 等多种评价指标。测试结果表明其在文本准确性方面表现卓越。下表展示了其与其他模型的性能对比: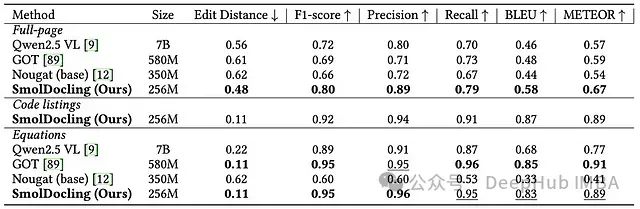
基于 DocLayNet 的评估结果显示,SmolDocling 模型在整页文档转换方面达到了最低的编辑距离(0.48)和最高的 F1 分数(0.80)。在精确率、召回率、BLEU 和 METEOR 等指标上,SmolDocling 同样优于其他对比模型。
在专项任务评估中,SmolDocling 在代码列表处理方面取得了显著成果,编辑距离为 0.11,F1 分数达 0.92。在方程识别任务中,其性能与 GOT 模型相当,编辑距离为 0.11,F1 分数为 0.95,精确率达 0.96。
尤为值得关注的是,与参数量显著更大的模型(如 7B 参数的 Qwen2.5 VL)相比,SmolDocling 仍然取得了更优的评估结果。这充分证明了其架构设计的有效性以及 DocTags 格式在结构化文档识别任务中的技术优势。
SmolDocling 应用
以下代码示例展示了 SmolDocling 的实际应用实现。需要特别注意的是,确保 PIL 库版本为最新,以避免潜在的兼容性问题。
# /// 脚本
# requires-python = ">=3.12" # 需要 Python 版本 >= 3.12
# dependencies = [ # 依赖项
# "docling-core",
# "mlx-vlm",
# "pillow",
# ]
# ///
fromioimportBytesIO
frompathlibimportPath
fromurllib.parseimporturlparse
importrequests
fromPILimportImage
fromdocling_core.types.docimportImageRefMode
fromdocling_core.types.doc.documentimportDocTagsDocument, DoclingDocument
frommlx_vlmimportload, generate
frommlx_vlm.prompt_utilsimportapply_chat_template
frommlx_vlm.utilsimportload_config, stream_generate
## 设置
SHOW_IN_BROWSER=True # 将输出导出为 HTML 并在 Web 浏览器中打开。
## 加载模型
model_path="ds4sd/SmolDocling-256M-preview-mlx-bf16"
model, processor=load(model_path)
config=load_config(model_path)
## 准备输入
prompt="Convert this page to docling."
image="sample.png"
# 加载图像资源
ifurlparse(image).scheme!="": # 它是一个 URL
response=requests.get(image, stream=True, timeout=10)
response.raise_for_status()
pil_image=Image.open(BytesIO(response.content))
else:
pil_image=Image.open(image)
# 应用聊天模板
formatted_prompt=apply_chat_template(processor, config, prompt, num_images=1)
## 生成输出
print("DocTags: \n\n")
output=""
fortokeninstream_generate(
model, processor, formatted_prompt, [image], max_tokens=4096, verbose=False
):
output+=token.text
print(token.text, end="")
if"</doctag>"intoken.text:
break
print("\n\n")
# 填充文档
doctags_doc=DocTagsDocument.from_doctags_and_image_pairs([output], [pil_image])
# 创建一个 docling 文档
doc=DoclingDocument(name="SampleDocument")
doc.load_from_doctags(doctags_doc)
## 导出为任何格式
# Markdown
print("Markdown: \n\n")
print(doc.export_to_markdown())
# HTML
ifSHOW_IN_BROWSER:
importwebbrowser
out_path=Path("./output.html")
doc.save_as_html(out_path, image_mode=ImageRefMode.EMBEDDED)
webbrowser.open(f"file:///{str(out_path.resolve())}")此代码实现了完整的图像内容分析流程,并通过 DocTags 生成结构化表示。代码主要执行以下技术步骤:
- 导入必要库:引入了请求处理、图像处理和文档生成所需的核心组件。
- 初始化模型配置:加载预训练的 SmolDocling 模型及其配置参数。
- 准备输入数据:设置处理提示和目标图像路径。
- 图像处理:实现了 URL 和本地文件两种图像加载方式。
- 应用提示模板:将用户提示格式化为符合模型要求的输入格式。
- 生成 DocTags 输出:通过流式生成方式逐步构建结构化文档表示。
- 构建文档对象:将生成的 DocTags 与原始图像关联,创建完整的文档对象。
- 多格式导出:提供了 Markdown 和 HTML 两种导出选项,支持文档的多场景应用。
以下是一个实际文档处理示例:
SmolDocling 的处理结果如下: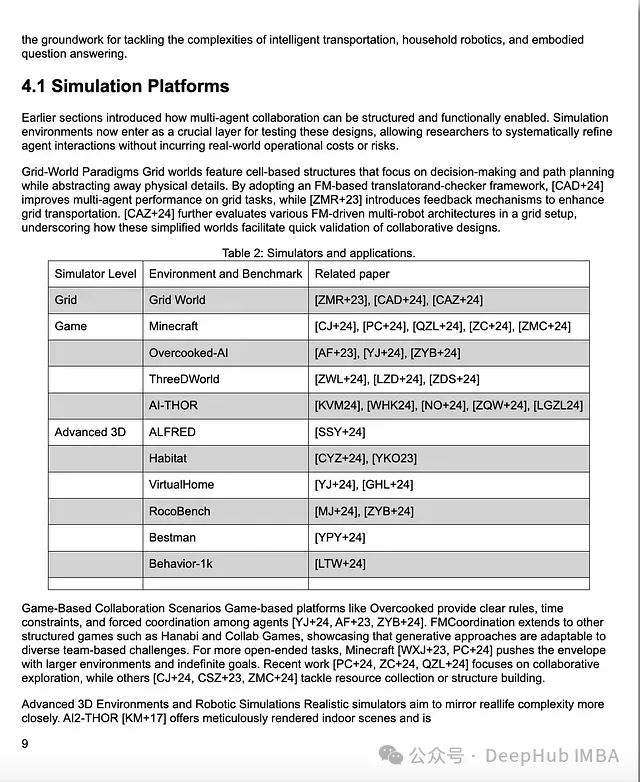
从表格处理效果来看,模型表现相当出色。尽管原始文档中的模拟器级别值采用居中对齐方式导致了轻微的数据偏移,但整体表格结构得到了准确保留,充分展示了模型的结构化数据处理能力。
总结
SmolDocling 作为文档处理领域的技术创新,以其紧凑的参数规模和卓越的性能表现树立了新的标准。通过采用 DocTags 格式和端到端架构设计,该模型能够高精度地表示文档的内容和结构特征。在资源受限环境或需要高可扩展性的应用场景中,SmolDocling 提供了显著的技术优势。
性能评估结果证明,SmolDocling 在整页文档转换、代码列表分析和方程识别等多项任务中均展现出优异性能。即使与参数量远大于其的模型相比,SmolDocling 仍能取得具有竞争力的结果,这充分证明了其模型设计理念和 DocTags 格式的技术有效性。
在数字化转型加速的背景下,采用 SmolDocling 这类轻量高效的文档处理模型,将通过平衡性能与资源消耗,为文档处理系统的广泛应用提供可靠的技术支持。
论文
https://avoid.overfit.cn/post/2f7f3de5f71e4ab6932231b0e6d261ff

