
面对工具生态系统扩张,大型语言模型的工具选择能力因提示词膨胀而受限。RAG-MCP 通过检索增强生成技术实现动态工具选择,显著提升处理效率与准确率。本文深入剖析其技术原理与应用价值。
大型语言模型(LLMs)如 GPT-4、Claude 和 Llama 的发展标志着人工智能领域的重大突破。这些高级模型展现出卓越的文本生成、逻辑推理及编程能力。尽管技术先进,LLM 仍然面临训练数据固化和上下文窗口有限的基础性约束。为使这些模型能够有效应对实时变化的外部环境,配备外部工具接口成为必要的技术路径。
考虑 LLM 执行旅行规划的场景:它需要访问航班数据库、检索酒店可用性信息并可能查询目的地天气预报。若缺乏相应工具(如各类服务 API),即便模型具备出色的语言表达能力,也无法实现真正的功能性服务。而当模型能够调用这些工具时,其功能价值则得到质的提升。
此处,"函数调用"机制与模型上下文协议(Model Context Protocol, MCP)等标准化接口发挥关键作用。Anthropic 提出的 MCP 旨在建立连接 AI 系统与外部数据源及服务的通用标准。它实质上是一种通用适配器,使 LLM 能够与 Google Drive、Slack、GitHub、数据库等多种"工具"进行交互。
然而,随着可用工具生态系统的爆发式增长,一个新的技术挑战愈发凸显:LLM 如何从庞大且持续扩展的工具库中高效准确地选择最适合的工具?研究人员在《RAG-MCP:通过检索增强生成缓解 LLM 工具选择中的提示词膨胀》一文中针对性地解决了这一问题。
工具选择困境:提示词膨胀与决策效率
构建一个需要访问数十种工具的 AI 助手时,常规方法是将所有工具描述(功能定义与参数需求)直接包含在提示中传递给 LLM。
对于少量工具,这种方法运行效果良好。但当工具数量扩展至 50、100 甚至 1000 个时,系统面临以下挑战:
提示词膨胀: 工具描述累积消耗大量 token,占用 LLM 有限的上下文窗口。这导致实际用户查询、对话历史或复杂推理所能利用的空间减少。这种情况类似于在一个拥挤的会议室中,数百人同时提供信息,而真正需要关注的核心对话被淹没。
决策复杂性与计算开销: 即便上下文窗口能够扩展,要求 LLM 对数百个工具描述进行筛选和评估(尤其是功能重叠且差异微妙的情况)仍会导致效率问题。模型可能选择次优工具,甚至错误识别不存在的工具或 API。认知负担的增加显著降低整体性能。
这一问题可类比为:一位厨师(LLM)在一个巨大的厨具仓库(工具生态系统)中工作。若厨师每次需要特定工具时都必须听取仓库中所有物品的详细描述,工作效率将极为低下。实际需要的是一位知识渊博的助手,能够根据当前任务迅速定位并提供最适合的几种工具选项。
RAG-MCP 框架正是为解决这一问题而设计。
RAG-MCP:基于语义检索的工具选择框架
RAG-MCP 方法借鉴了知识密集型 NLP 任务中广泛应用的检索增强生成(Retrieval-Augmented Generation, RAG)技术原理。
传统 RAG 技术主要用于使 LLM 能够访问大型外部知识库(如维基百科)。与尝试将整个知识库加载至提示中不同,检索系统首先识别与用户查询最相关的文章或段落,然后仅将这些相关内容与查询一起提供给 LLM,从而生成更精确的回应。
RAG-MCP 应用相同的"检索后生成"原理,但检索目标从事实性知识转向了功能性工具描述。
其核心工作流程如下:
- 外部工具索引构建: 所有可用工具描述(MCP 函数模式、使用示例等)被存储在外部索引系统中,通常采用向量数据库实现。每个工具描述转换为数值向量表示(嵌入),以捕捉其语义特征。
- 查询时检索处理: 当用户发出查询(例如,"为我预订下周二前往伦敦的航班")时,专用检索器(可能是较小规模的 LLM 或语义搜索算法)首先分析查询意图,然后在工具索引中搜索语义相似度最高的前 k 个工具描述。
- 聚焦提示构建: 系统仅将筛选出的 k 个相关工具描述注入 LLM 提示中(或通过函数调用 API 提供)。这使 LLM 面对的选择空间显著缩小且更具针对性。
- LLM 执行决策: LLM 在经过过滤的上下文环境中进行决策并调用选定工具。

标准 MCP 方法(左)与 RAG-MCP(右)在推理过程中的对比图。RAG-MCP 引入检索步骤在 LLM 交互前选择相关工具 MCP,有效减轻信息过载问题。
该方法具备以下核心优势:
- 显著减少提示词规模: 通过仅包含少量相关工具,提示词膨胀问题得到明显缓解。研究数据显示实验中提示词 token 减少超过 50%。
- 降低认知复杂度: LLM 无需处理大量不相关选项,从而提高工具选择精确度,减少错误与幻觉可能性。
- 系统扩展性提升: 新工具可通过在外部数据库中简单索引其描述完成添加,无需对主要 LLM 进行重训练或大规模配置调整。
- 计算资源优化: 在某些系统架构中,工具注册可能意味着需要实例化或预初始化这些组件,消耗大量资源。RAG-MCP 可选择性地仅激活或准备检索到的工具,有效降低系统开销。
RAG-MCP 技术流程详解
RAG-MCP 的三阶段处理流程: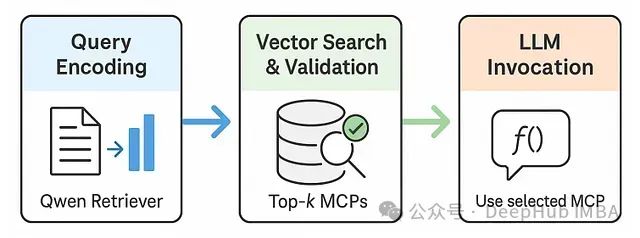
RAG-MCP 处理流程图。1. 用户任务编码;2. 检索器(如 Qwen-max)搜索 MCP 模式向量索引并验证候选项;3. LLM 仅接收经选择的 MCP 信息执行任务。
1. **任务输入编码与检索准备:** 用户自然语言查询首先被编码(使用如实验中采用的Qwen-max等LLM),然后传递至检索模块。
2. **MCP选择与验证:** 检索器对索引化的MCP模式执行语义搜索,并按相关度对候选工具进行排序。可选地,系统会执行验证步骤,为检索到的顶级MCP生成合成示例查询,在最终选择前评估其兼容性与响应能力。
3. **LLM任务执行:** 最后,仅将最优(或前几个)MCP的模式和参数传递给主LLM,通过其函数调用接口完成任务执行。工具发现过程与核心 LLM 生成功能的解耦是此框架的关键技术特点。这类似于专业图书管理员(检索器)在主研究员(LLM)利用资源解答复杂问题前,先定位出最相关的参考资料(工具)。
实验评估:MCP 压力测试与性能对比
为量化问题严重性及解决方案有效性,研究团队设计了专门的"MCP 压力测试"。
MCP 压力测试设计: 受"大海捞针"(NIAH)测试启发(该测试评估 LLM 在长文本中定位特定信息的能力),MCP 压力测试评估 LLM 在干扰工具数量增加情况下的工具选择能力。测试构造如下:
- 模型每次面对 N 个 MCP 模式:其中一个是 WebSearch 任务所需的"目标"工具,而 N-1 个为干扰工具。
- 实验中,N 值从 1 变化至 11,100,构成极端测试条件。
- 研究者测量选择准确率、任务成功率、token 使用量及处理延迟。
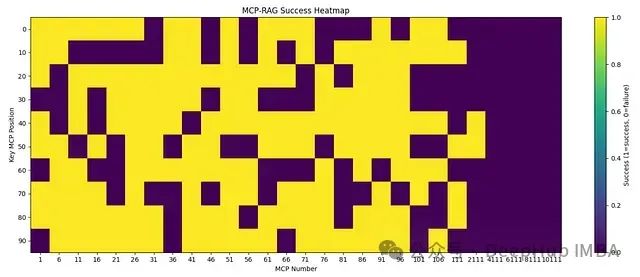
MCP 压力测试中 RAG-MCP 的成功率热图。黄色表示成功选择工具,紫色表示选择失败。尽管性能随 MCP 数量(可选工具数)急剧增加而下降,但 RAG-MCP 在小到中等规模工具池中保持高成功率,且与基准方法相比,即使在大量干扰项存在时也展现出更强的鲁棒性。
热图清晰展示了随 MCP 数量(x 轴上的"MCP Number")增加,成功率(黄色区域代表成功)呈现下降趋势,特别是当目标 MCP 位于长列表后部时。然而,数据同时证明即使在工具数量庞大的情况下,RAG-MCP 仍能取得成功,尤其是当相关工具具有显著特征或查询非常具体时。该测试定量验证了简单增加 LLM 可用工具数量的方法难以持续。
基准性能评估: 除压力测试外,研究者还在 MCPBench 的网络搜索子集上对 RAG-MCP 与两种基准方法进行了对比:
- 空白条件(朴素方法): LLM 一次性接收所有 N 个 MCP 描述并进行选择。
- 关键词匹配: 基于任务描述与 MCP 元数据的关键词匹配进行简单预过滤。
所有测试均使用
qwen-max-0125作为基础 LLM。
实验结果明确体现了 RAG-MCP 的优势:
基准性能比较表。RAG-MCP 在显著减少提示词 token 的同时实现最高准确率,相较于空白条件有明显提升。
如表格数据所示:
- 准确率指标: RAG-MCP 达到43.13%的工具选择准确率。虽然这一绝对值看似不高,但与关键词匹配(18.20%)和空白条件(13.62%)相比,是显著的提升。事实上,RAG-MCP 的准确率比朴素基线高出三倍多。
- 平均提示词 Token 消耗: RAG-MCP 将提示词 token 平均减少至1084.00。相比空白条件的2133.84token——接近减少了一半。这有效释放了宝贵的上下文窗口空间。
- 平均完成 Token 量: RAG-MCP 的完成 token 使用量(78.14)略高于关键词匹配(23.60),但显著低于空白条件(162.25)。研究者认为这是合理的资源分配,因为额外的完成 token 与更高准确率和更完善的推理/验证步骤相关。
这些实验数据有力证明了 RAG-MCP 在面对大量工具选择时缓解提示词膨胀并提升 LLM 决策能力的有效性。
技术深度剖析:RAG-MCP 内部机制
针对技术实现细节:
- 检索器实现: 采用"轻量级 LLM 基础的检索器(如 Qwen)"对用户任务描述进行编码,并对 MCP 索引执行语义搜索。这意味着检索器本身是一个 AI 模型,经训练理解查询语义,并将其与以向量嵌入形式存储的工具描述语义进行匹配。这些嵌入的质量及检索器识别工具功能细微差异的能力对 RAG-MCP 的性能至关重要。
- 验证机制: 可选的验证步骤提供了额外的质量保障。通过让 RAG-MCP 为检索到的 MCP 生成示例查询并测试其响应情况,系统能在主 LLM 调用工具前进行兼容性确认。这有助于过滤语义相似但实际不兼容或无响应的工具。
- 极端规模下的挑战: 压力测试表明,即使采用 RAG-MCP,在处理数千个工具时检索精度也可能下降。当"目标"工具与众多干扰项高度相似,或查询表述不够明确时,检索器可能面临困难。这指出了未来研究方向,可能涉及分层检索或更复杂的排序和验证机制。
- 基础 LLM 选择影响: 实验使用
qwen-max-0125作为执行任务的基础 LLM。RAG-MCP 的整体性能必然受该主要 LLM 能力的影响。更强大的基础 LLM 可能更擅长利用检索器提供的工具,即使检索结果不完全最优。 - 单一工具调用与扩展可能: 目前 RAG-MCP 主要关注选择和注入单个最佳 MCP 描述。未来研究可探索任务需要多个工具链式或组合使用的场景,以及检索器如何协助识别此类组合。
RAG-MCP 的技术意义与应用前景
RAG-MCP 框架不仅具有学术价值,更解决了 AI 助手和自主代理发展面临的核心瓶颈。随着我们期望 LLM 在动态环境中执行日益复杂的任务,其高效利用多样化外部工具的能力变得尤为关键。
- 增强 AI 代理能力: 支持复杂 AI 代理无缝切换网络搜索、数据库查询、生产力应用交互、智能设备控制等多种功能。RAG-MCP 为这些代理提供了可扩展的工具管理机制。
- 优化开发者体验: 对于构建 LLM 驱动应用的开发者,工具集成管理可能迅速变得复杂。RAG-MCP 提供更结构化和可扩展的方法,降低开发成本并提高工具使用的可靠性。
- 扩展专业工具可访问性: 通过使 LLM 更容易发现和使用专业 API 与服务,RAG-MCP 有助于拓展以往需要专业知识才能使用的功能访问渠道。
- 促进技术标准化: 虽然 MCP 提供了工具定义标准,RAG-MCP 则提供工具发现与选择的模式。随着 LLM 生态系统成熟,此类标准化模式日益重要。
研究者强调,"RAG-MCP 为构建可扩展、可靠的 LLM 代理奠定了'黄金核心',使其能够精确高效地利用大量外部服务。"
总结
RAG-MCP 为日益严峻的 LLM 工具过载挑战提供了一个技术上可行的解决方案。主要结论包括:
1. 问题定义: 通过提示词填充方式提供大量工具会导致提示词膨胀、准确率下降和决策效率降低。
2. 技术方案: RAG-MCP 利用检索增强方法动态识别并仅向 LLM 提供与查询最相关的工具。
3. 性能优势: 显著减少提示词 token 使用(实验中降低超过 50%);与朴素基线相比工具选择准确率提高三倍以上;维持良好扩展性,支持便捷添加新工具;减轻 LLM 认知负担,提升决策质量。
未来研究方向:
- 完善极端规模下的检索: 探索分层索引或自适应检索策略,用于处理拥有数万种工具的场景。
- 多工具工作流: 使 RAG-MCP 能够帮助选择和协调工具序列或组合,以处理复杂任务。
- 真实世界代理部署: 在实际部署的 AI 代理系统中测试和加强 RAG-MCP。
发展真正具备综合能力的 AI 代理的技术路径仍在不断演进。RAG-MCP 等框架作为关键技术基础,提供了管理 LLM 不断扩展能力所需的架构支持。通过分离工具发现的复杂性,RAG-MCP 使 LLM 能够专注于其核心优势:以更高效、更复杂的方式进行推理、规划和与外部世界交互。
论文:
https://avoid.overfit.cn/post/d8f3234d0c054ac79c8e26602a08846a

