
在大模型与高性能计算深度融合的当下,充分释放GPU硬件算力已成为推动技术进步的关键环节。为探索GPU性能优化的前沿技术,培养高水平计算人才,达坦科技在2025年11月份举办 “GPU性能优化比赛” ,现正式启动赛事报名工作。
本次大赛聚焦GPU计算性能瓶颈突破,旨在为开发者提供一个交流技术与展示创新能力的平台。参赛者将基于由西安超算中心提供的高性能GPU计算环境,对特定计算任务进行深度优化,挑战极致性能。
我们诚邀国内外高校学生或有兴趣的开发者共同探索GPU性能优化的技术边界,为推动产业发展贡献智慧与力量。
一、赛事概览
赛事名称:GPU性能优化比赛
主办方:达坦科技
参赛对象:面向开发者、高校学生及所有对GPU高性能计算感兴趣的团队与个人。
赛事形式:在线开发与评审
报名链接:
https://v.wjx.cn/vm/mHsM4yC.aspx#
二、背景介绍
在人工智能、科学计算、大数据分析等领域,GPU已成为不可或缺的算力引擎。其强大的并行处理能力能够将复杂任务的计算时间从数周缩短至数小时。然而,拥有强大的GPU硬件并不等同于获得了其100%的性能。
在实际应用中,由于算法设计、内存访问、并行策略、软件栈调用等方面的瓶颈,GPU的利用率常常远低于理论峰值。一个未经优化的程序,可能只能发挥出GPU 10%-30%的潜力。这意味着巨大的算力浪费和资源闲置。GPU性能优化,就是通过一系列技术手段,消除这些瓶颈,让每一块计算单元都高效运转,从而将硬件的潜力挖掘到极致。 这不仅关乎计算速度,更直接影响到科研的迭代周期、AI模型的训练成本以及工业应用的实时性。
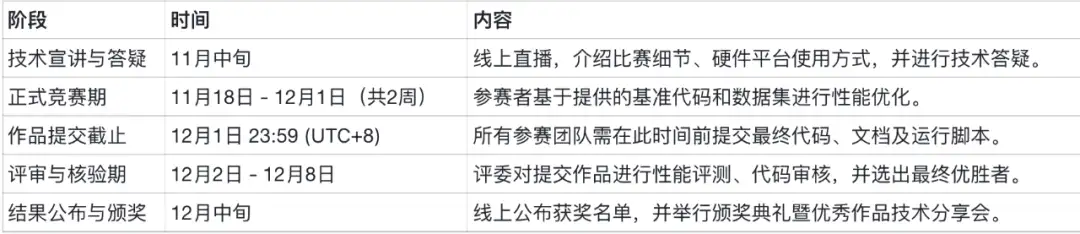
三、赛事日程安排
本次黑客松总时长约2周,具体日程安排如下:
四、赛题介绍
随着大模型的迅速发展,GPU硬件也在飞速迭代,每年都会有大量老一代GPU被新一代GPU所取代。因此,一个不容忽视的问题出现了:被淘汰的GPU成为了数据中心里的“存量算力”,如何通过算法优化,让这些存量算力发挥余热呢?
本次比赛要求参赛选手在主办方提供的算力受限硬件加速卡上,对推理场景中的低秩矩阵向量乘(例如GEMV)进行
优化。加速卡具有如下特性:
- 兼容AMD ROCm生态,熟悉CUDA编程的同学可以零成本迁移到AMD ROCm。
- 不可使用Tensor Core硬件加速单元,只能使用朴素CUDA Core。
- FP32算力 10TFLOPS, FP16算力20TFLOPS,显存带宽1TB/s
具体题目要求为:
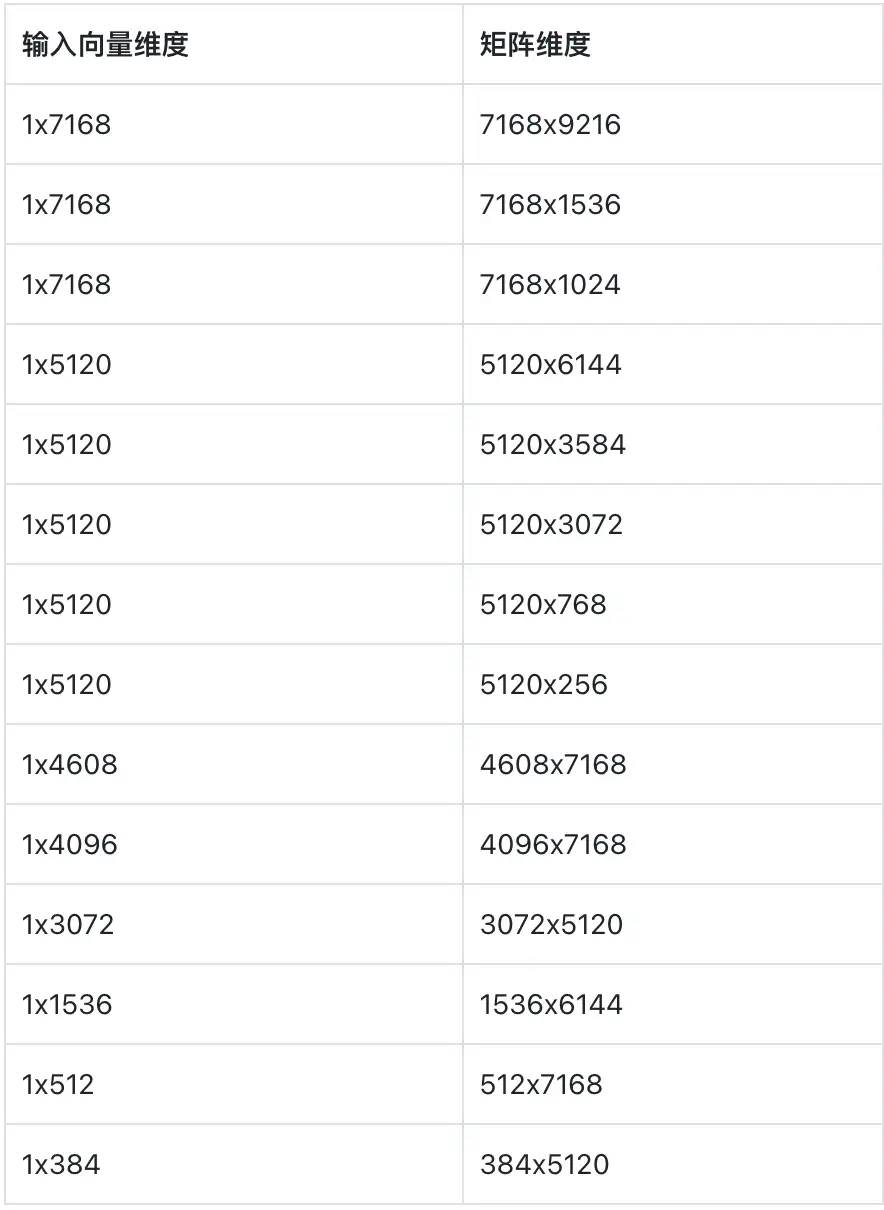
编写可以对矩阵向量乘法进行计算的核函数,输入向量为fp16格式,矩阵参数采用w4a16量化形式,选手可在参数加载过程中对参数在显存中的排布方式进行调整。输出结果精度要求atol和rtol均满足1e-2。计算核函数需要支持以下尺寸的GEMV运算,可以针对不同的计算尺寸设计不同的计算核函数,也可以实现一个统一的计算核函数。
需要支持的GEMV矩阵尺寸:
五、评估标准
本次比赛采用独立开发,自主测评+一次性提交评判的方式,对参赛选手的作品进行评测。举办方为参赛选手提供加速卡环境,选手各自进行开发与测试。本次比赛不设置动态排名榜,参赛选手各自创建私有github仓库并对举办方开通访问权限,在比赛截止时间前的最后一次github commit被视作最终提交代码。
举办方将以profiling工具输出的kernel执行时间作为评判标准,将上述不同尺寸GEMV计算的总耗时进行累加,按照所有kernel执行时间的长短进行排名。
六、奖项设置
我们准备了丰厚的奖金与荣誉,以表彰优秀的参赛者:
- 冠军(1名):奖金1000美金
- 亚军(1名):奖金700美金
- 季军(1名):奖金400美金
此外,我们还将为表现突出的参赛者提供宝贵的实习机会,助力同学们的未来发展。
性能优化的道路没有终点,但每一个瓶颈的突破,都值得最热烈的欢呼。
报名通道已经正式开启,让我们一同,以代码为刃,挑战算力的极限!
报名链接:
https://v.wjx.cn/vm/mHsM4yC.aspx#

达坦科技始终致力于打造高性能AI+Cloud基础设施平台,积极推动AI应用的落地。达坦科技通过软硬件深度融合的方式,提供AI推理引擎和高性能网络,为AI应用提供弹性、便利、经济的基础设施服务,以此满足不同行业客户对AI+Cloud的需求。
公众号:达坦科技DatenLord
DatenLord官网:
https://datenlord.github.io/zh-cn/
知乎账号:
https://www.zhihu.com/org/da-tan-ke-ji
B站:
https://space.bilibili.com/2017027518
如果您有兴趣加入达坦科技Rust前沿技术交流群、硬件敏捷开发和验证方法学讨论群或AI Infra交流群,请添加小助手微信:DatenLord_Tech

