在 Java 开发面试中,经常会被问到 Spring IOC 是什么,让谈谈自己的理解。在工作开发中,如果能够理解 Spring IOC 设计模式的话,对排...

作为一名应用系统开发人员,为什么要关注数据内部的存储和检索呢?首先,你不太可能从头开始实现一套自己的存储引擎,往往需要从众多现...
Java平台设计的重点是安全性。在其核心,java语言本身是类型安全的并且提供了垃圾自动回收,这使其增加了应用程序代码的健壮性。安全的...
Apache Kafka是一个分布式流式平台。流平台有三个关键的能力:发布和订阅记录流,类似于消息队列或企业消息传递系统。使用容错耐用的方...
方法1: {代码...} 这种方法需要的时间比较长方法2: {代码...} 找到general_log的文件执行 {代码...} 发现也将大小释放了,比上一个快...
在使用Kylin的时候,最重要的一步就是创建cube的模型定义,即指定度量和维度以及一些附加信息,然后对cube进行build,当然我们也可以根...

今天,随着移动互联网、物联网、AI等技术的快速兴起,数据成为了所有这些技术背后最重要,也是最有价值的“资产”。如何从数据中获得有价...

Hbase的客户端有原生java客户端,Hbase Shell,Thrift,Rest,Mapreduce,WebUI等等。

多线程一直是工作或面试过程中的高频知识点,今天给大家分享一下使用 ThreadPoolTaskExecutor 来自定义线程池和实现异步调用多线程。
在 QCon 北京 2019 大会上,赵云讲师做了《苏宁 OLAP 引擎发展之路》主题演讲,主要内容如下。

今天我们来看一下淘宝、美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图。通...
2、含定时方法的类上添加注解:@Component,该注解将定时任务类纳入 spring bean 管理。

MapReduce详细工作流程之Map阶段如上图所示首先有一个200M的待处理文件切片:在客户端提交之前,根据参数配置,进行任务规划,将文件按1...

说起应用分层,大部分人都会认为这个不是很简单嘛 就controller,service, mapper三层。看起来简单,很多人其实并没有把他们职责划分开...

Hbase的表结构设计与关系型数据库有很多不同,主要是Hbase有Rowkey和列族、timestamp这几个全新的概念,如何设计表结构就非常的重要。
Hbase最核心但也是最难理解的就是数据模型,由于与传统的关系型数据库不同,虽然Hbase也有表(Table),也有行(Row)和列(Column),...
hadoop2.7.2 MapReduce Job提交源码及切片源码分析首先从waitForCompletion函数进入

分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
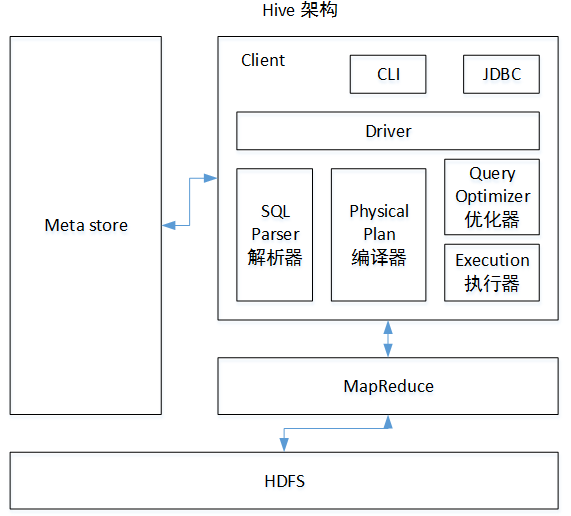
用户接口:ClientCLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)